Top-K, Top-P, Min-P, and Beam Search: Every LLM Sampling Method Compared
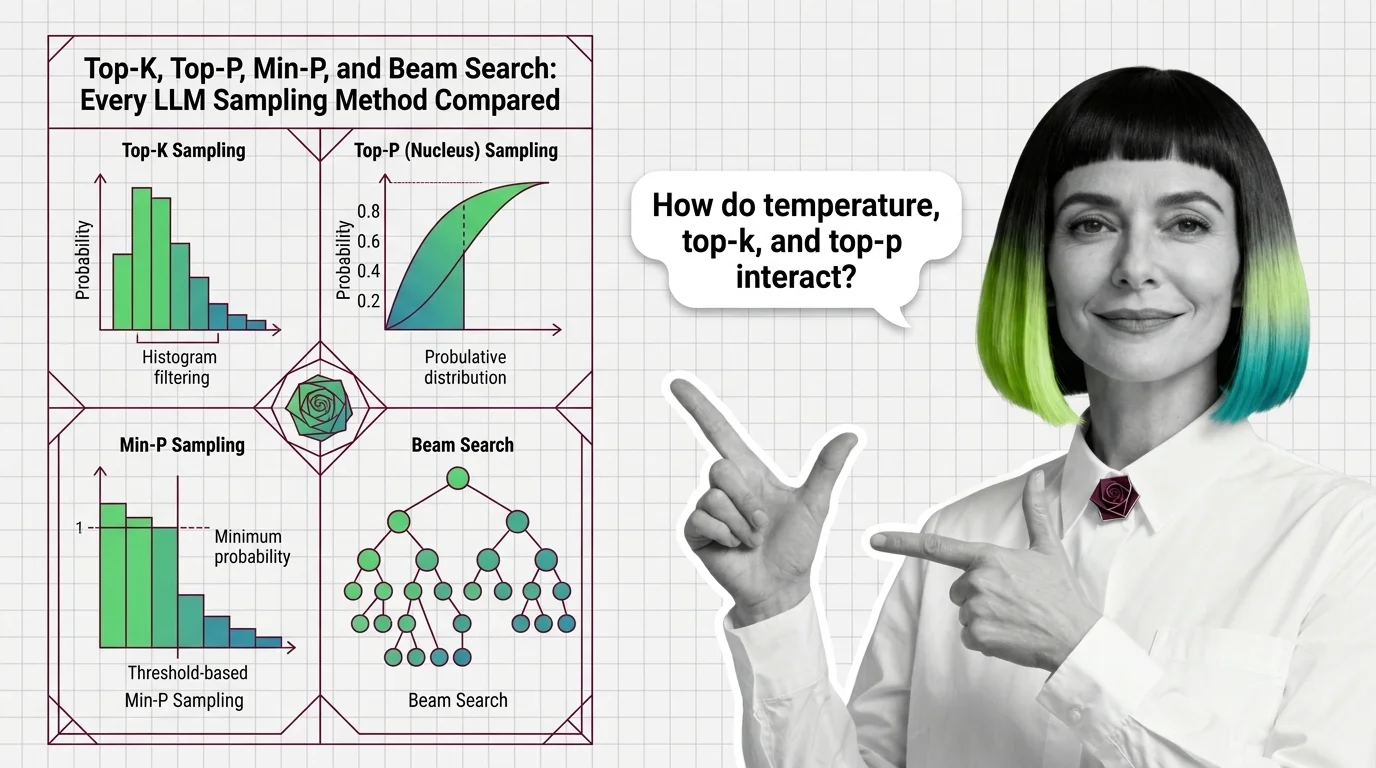
Table of Contents
ELI5
LLMs produce a probability for every possible next word. Sampling methods decide which probabilities survive. Top-K keeps a fixed number. Top-P keeps a cumulative threshold. Min-P scales with confidence. Beam search explores multiple paths at once.
Run the same prompt through the same model twice. Identical weights, identical context, identical system message. One response is crisp and precise; the other wanders into poetic tangents. Most developers blame “randomness” and move on. The real explanation is geometric — the shape of the probability distribution at each token position determines what the sampler can see, and different sampling methods carve that distribution into fundamentally different shapes.
From Logits to the Sampling Floor
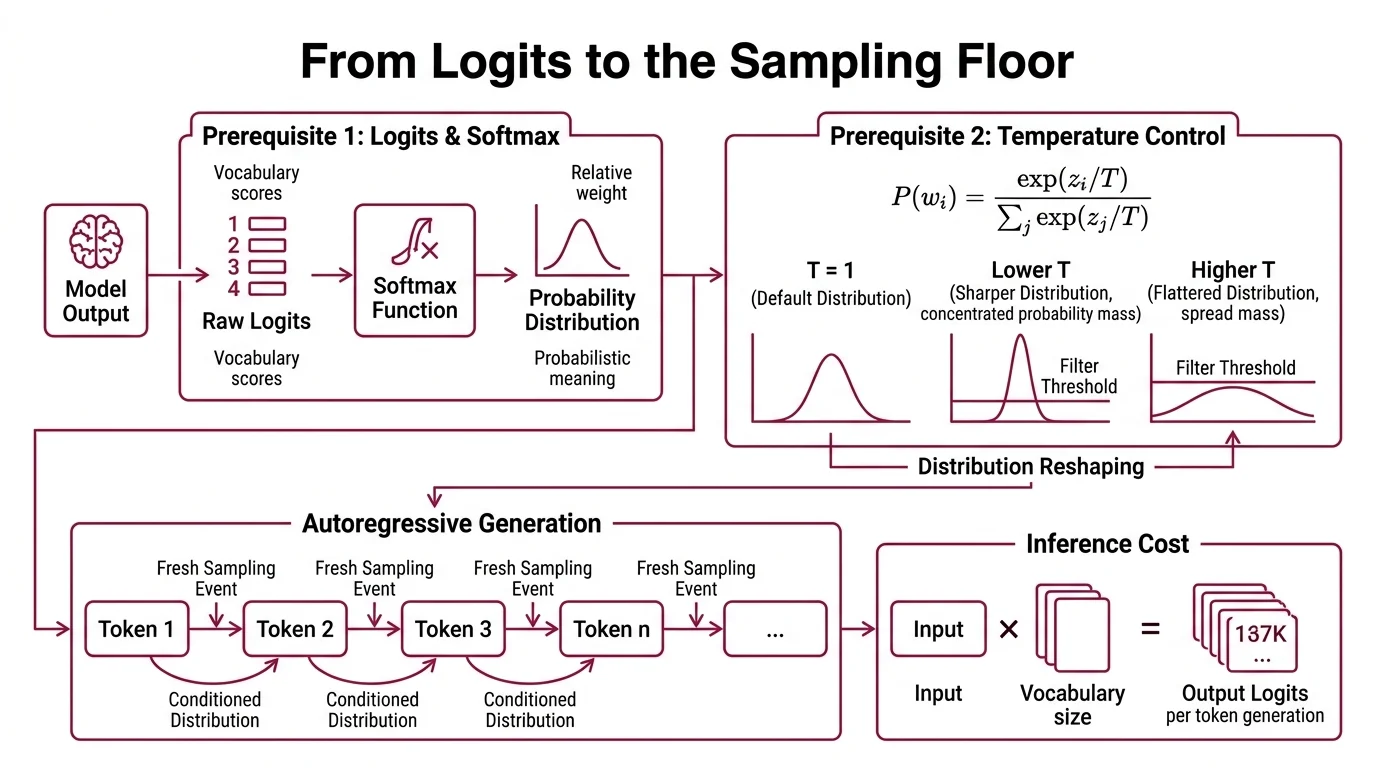
Before any sampling method can operate, three things must happen in sequence — and confusing their order is the most common source of parameter-tuning frustration. Understanding these prerequisites separately, before they interact inside a sampling pipeline, is the difference between informed tuning and superstition.
What do you need to understand about softmax, logits, and autoregressive generation before learning LLM sampling?
A language model’s final layer produces raw scores called logits: one number per token in the vocabulary. These scores carry relative weight but no probabilistic meaning yet. To convert them into a proper probability distribution, the model applies Softmax — an exponential normalization that maps every score into the range (0, 1) while preserving rank order.
Here is where Temperature And Sampling enters. The temperature parameter T divides each logit before softmax: P(w_i) = exp(z_i / T) / Sum_j exp(z_j / T). When T = 1, you get the model’s default distribution. Lower T sharpens it — concentrating probability mass on the top candidates. Higher T flattens it — spreading mass across unlikely tokens. Temperature reshapes everything downstream. The same top_p = 0.9 threshold will capture a different set of tokens at T = 0.3 than at T = 1.5, not because the filter changed, but because the distribution it received was already a different shape.
The second prerequisite is Autoregressive Generation: the model generates one token at a time, each conditioned on all preceding tokens. There is no sentence-level plan. No paragraph-level optimization. Each token is a fresh sampling event from a fresh distribution. Every method discussed here operates at this single-token granularity — shaping the distribution from which exactly one token gets drawn.
The third prerequisite is cost. Inference with a 128,000-token vocabulary produces 128,000 logits per step. Sampling methods are not just quality filters; they are computational shortcuts that reduce the candidate space before the random draw. For frameworks managing Continuous Batching across thousands of concurrent requests, the difference between efficient pruning and brute-force evaluation determines whether the system serves or stalls.
Four Filters, Four Geometries
Each sampling method answers the same question — which tokens are allowed? — but the geometry of the answer differs in ways that matter more than the default values suggest. The evolution from static to dynamic to confidence-scaled filtering tracks a single insight: the right cutoff depends on how certain the model is.
What are the differences between top-k, top-p, min-p, and beam search sampling methods?
Top-K is the oldest and simplest: keep the K highest-probability tokens, discard everything else, renormalize. Proposed in 2018 for neural story generation, it remains widespread across APIs and frameworks. The limitation is that K is static. Set K = 50, and the model retains 50 candidates whether the distribution is peaked — one token sitting at 0.92 probability — or flat, with mass smeared across hundreds of alternatives. In a confident distribution, 49 of those 50 candidates contribute almost nothing. In an uncertain distribution, 50 is not nearly enough.
Top P Sampling — nucleus sampling — makes the cutoff dynamic. Instead of a fixed token count, it keeps the smallest set of tokens whose cumulative probability reaches a threshold p. When the model is confident, the nucleus might contain three tokens. When it is uncertain, it might contain three hundred. This adaptation to distribution shape largely eliminated the repetitive, looping text that plagued early neural generation — the “degeneration” problem that gave the original paper its name (Holtzman et al.).
Min P Sampling pushes the dynamic principle one step further. Any token whose probability falls below min_p multiplied by the probability of the top token gets discarded. The threshold scales with model confidence automatically (Nguyen et al.). High confidence means only tokens close to the leader survive. Low confidence opens the gate wider. Tested across Mistral and Llama 3 families on GPQA, GSM8K, and AlpacaEval creative writing, min-p matched or exceeded top-p on both reasoning and creative writing benchmarks (Nguyen et al.). Recommended starting values sit around 0.05 to 0.1 for general use, though these come from limited published benchmarks and the optimal setting is model- and task-dependent (Thoughtworks).
Beam Search is the outlier. It does not sample at all. Instead, it maintains B parallel hypotheses and extends each at every step, keeping only the B highest-scoring complete sequences. The result is deterministic and globally optimized — but computationally expensive and prone to producing bland, high-probability text that lacks the variability human readers expect. Beam search remains relevant for structured-output tasks and machine translation, with trie-based efficiency improvements appearing in 2025, but it is rarely exposed in commercial LLM chat APIs.
| Method | Candidate Selection | Adapts to Confidence? | Deterministic? |
|---|---|---|---|
| Top-K | Fixed count (K tokens) | No | No |
| Top-P | Cumulative probability >= p | Yes | No |
| Min-P | Individual prob >= min_p x P(top) | Yes (scales with top token) | No |
| Beam Search | B parallel hypotheses | N/A | Yes |
The Execution Order That Changes Everything
When you set temperature, top_k, and top_p in the same API call, they do not operate in parallel. They execute in sequence — and the sequence varies by provider. This is the detail that most documentation buries or omits entirely.
How do temperature, top-k, and top-p interact when combined in a single API call?
Gemini’s API is the most explicit: top_k filters first, then top_p filters second, then temperature applies for final selection (Google Docs). This means top_k pre-screens the distribution before top_p ever sees it. A generous top_k = 100 barely touches a peaked distribution — but a restrictive top_k = 5 forces top_p to operate on an already-narrow candidate set, potentially making the p threshold irrelevant.
Not all providers are this transparent.
OpenAI exposes temperature (0-2) and top_p but no top_k and no min_p (OpenAI Docs). Their documentation recommends altering one parameter, not both — without specifying whether the two interact multiplicatively or sequentially. Anthropic exposes temperature (0-1, default 1.0), top_k, and top_p, but no min_p (Anthropic Docs). Notably, Anthropic’s documentation states that temperature = 0 is still not fully deterministic — a subtlety that matters for reproducibility-critical applications.
| Provider | temperature | top_k | top_p | min_p | beam search |
|---|---|---|---|---|---|
| OpenAI | 0-2 | – | yes | – | – |
| Anthropic | 0-1 (default 1.0) | yes | yes | – | – |
| Gemini | 0-2 (default 1.0) | yes | yes (default 0.95) | – | – |
| vLLM | yes | yes | yes | yes | yes |
Where does min_p fit? As of 2026, no commercial API exposes it. Min-p is native to the open-source stack: llama.cpp, vLLM, HuggingFace Transformers, Ollama, ExLlamaV2, and others. Among power users of these frameworks, the emerging preference is temperature paired with min_p as a two-parameter setup — simpler than the three-knob stack and more adaptive than any single static filter.
For Quantization-compressed models running locally, practitioners report that min_p at 0.05 compensates for the distribution distortion that quantization introduces — though this remains community practice, not a peer-reviewed finding.
What Your Parameter Choices Actually Predict
Once you see the sampling pipeline as a series of geometric transformations on a probability distribution, the failure modes become predictable.
If you raise temperature without tightening your sampling filter, the flattened distribution admits tokens that were previously below the cutoff — increasing diversity but also incoherence. If you use top_k on a model that frequently produces peaked distributions, most of your K candidates contribute negligible probability mass; you are carrying dead weight through the pipeline. If you combine top_p with a low temperature, the nucleus shrinks to a handful of tokens and the output becomes near-deterministic regardless of the p value you chose.
Not a tuning problem. A pipeline-order problem.
Rule of thumb: Choose one adaptive filter (top-p or min-p), pair it with temperature, and leave it alone. Adding top-k on top of top_p rarely improves output quality — it introduces a second constraint that fights the first.
When it breaks: Min-p inherits its threshold from the top token’s probability, so adversarial or distribution-shifted inputs that produce a confidently wrong top token cause min-p to narrow the candidate set around exactly the wrong answer. The filter trusts model confidence, and model confidence can be miscalibrated.
The Data Says
Sampling methods are geometric operations on a probability distribution, executed in a provider-specific sequence. The field has moved from static truncation (top-k, 2018) through dynamic nucleus sampling (top-p, 2020) to confidence-scaled filtering (min-p, 2025) — and the open-source ecosystem adopted min-p faster than commercial APIs have. Understanding the pipeline order matters more than memorizing default values, because the same parameter produces different results depending on what reshaped the distribution before it arrived.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors