Transformer Internals for Developers: What Maps, What Breaks
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where determinism breaks, and what to read next.
Transformer internals are the mechanisms that make modern language models work — attention, positional encoding, and encoder-decoder designs that replaced recurrent networks in 2017.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
An attention mechanism is a neural network component that lets a model dynamically focus on the most relevant parts of …
Decoder-only architecture is a transformer design where a single decoder stack generates output tokens one at a time, …
Encoder-decoder architecture is a neural network design pattern where an encoder network compresses an input sequence …
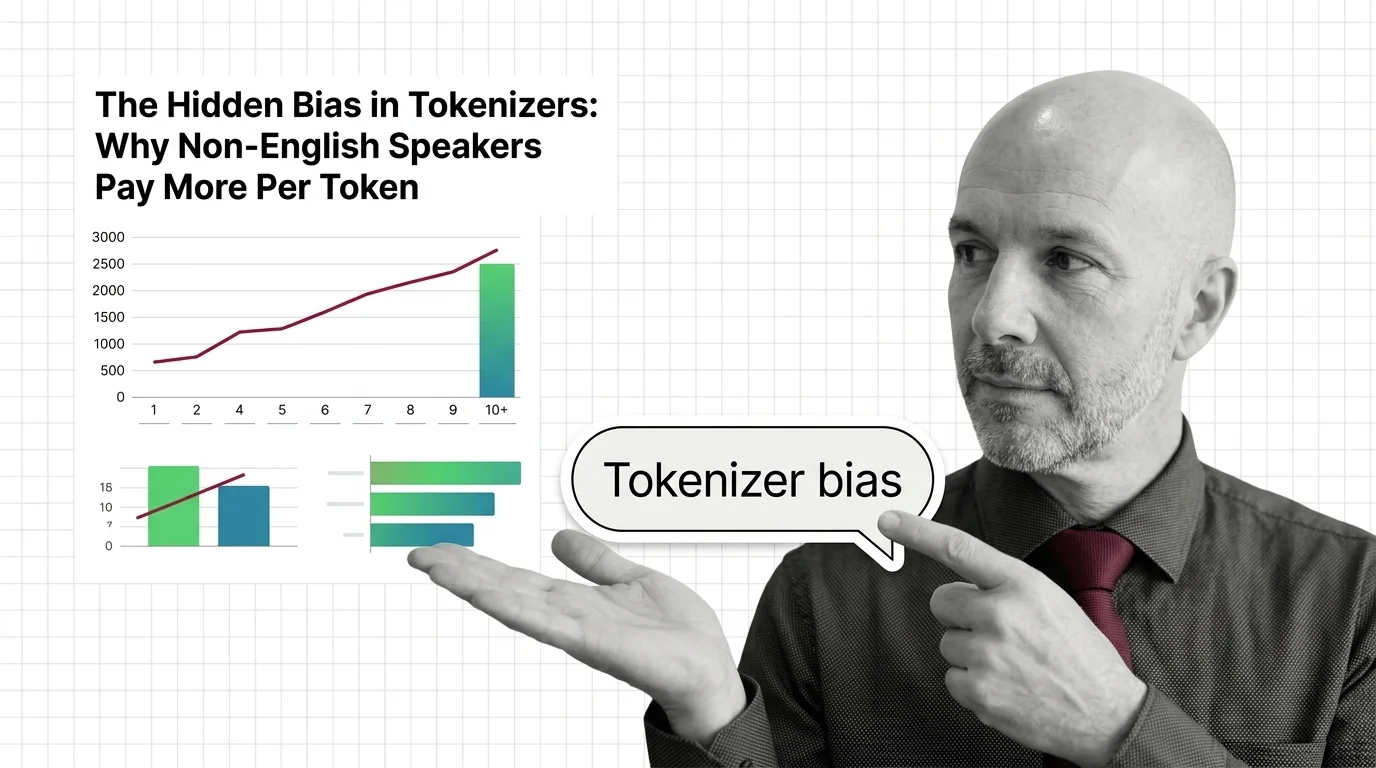
Tokenizer architecture is the subsystem that converts raw text into numeric tokens a language model can process. It …
The transformer architecture is a neural network design that uses self-attention to process all parts of an input …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Mar 23, 2026
Concepts covered
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where determinism breaks, and what to read next.
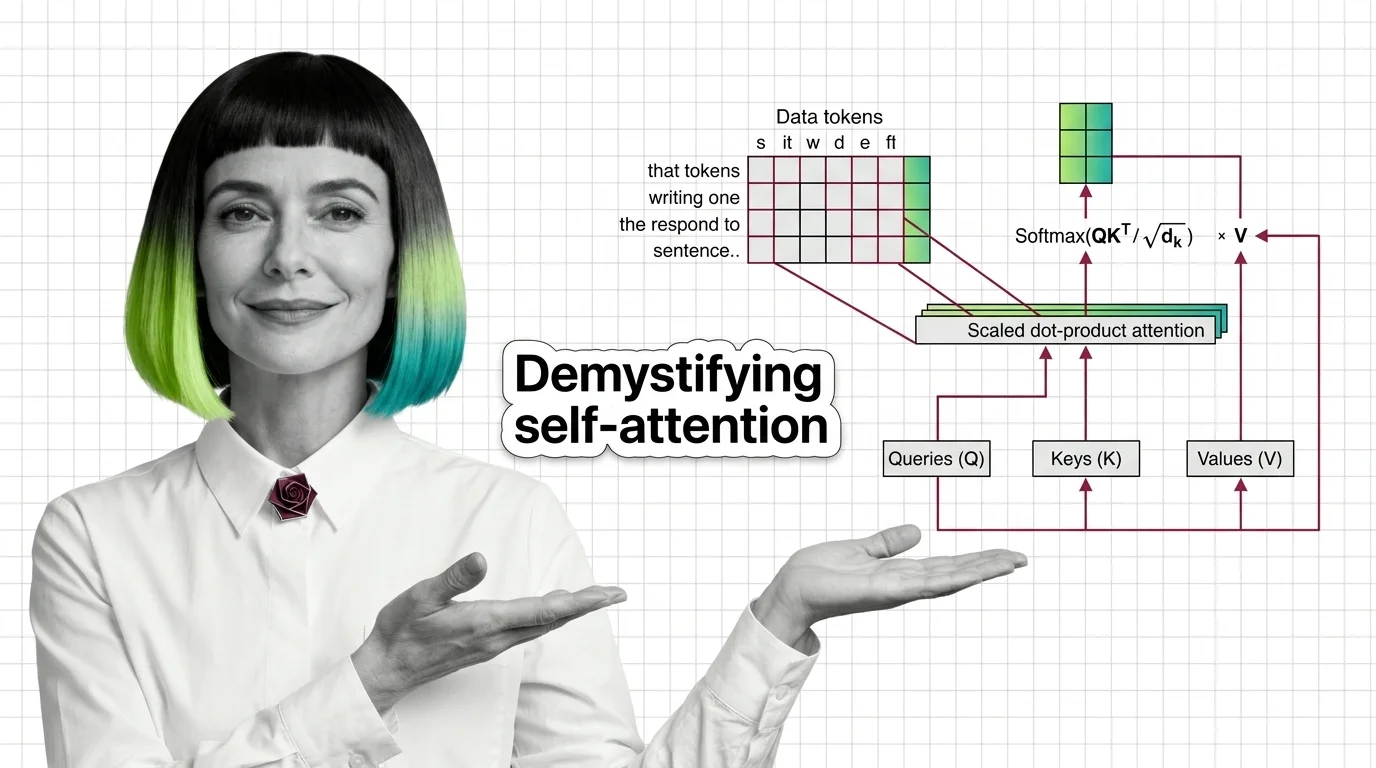
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute the focus behind every transformer output.
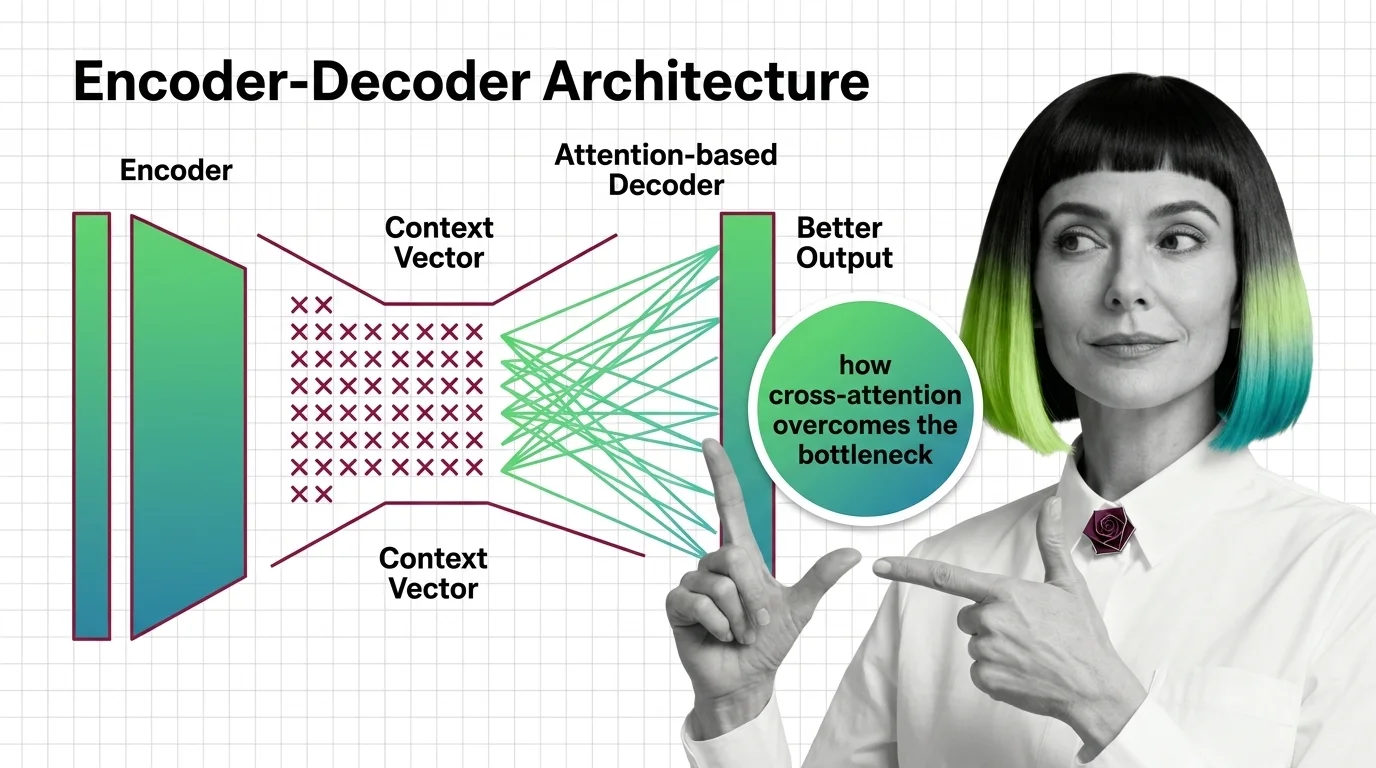
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with selective access to every encoder position.

BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — and what is emerging to fix it.
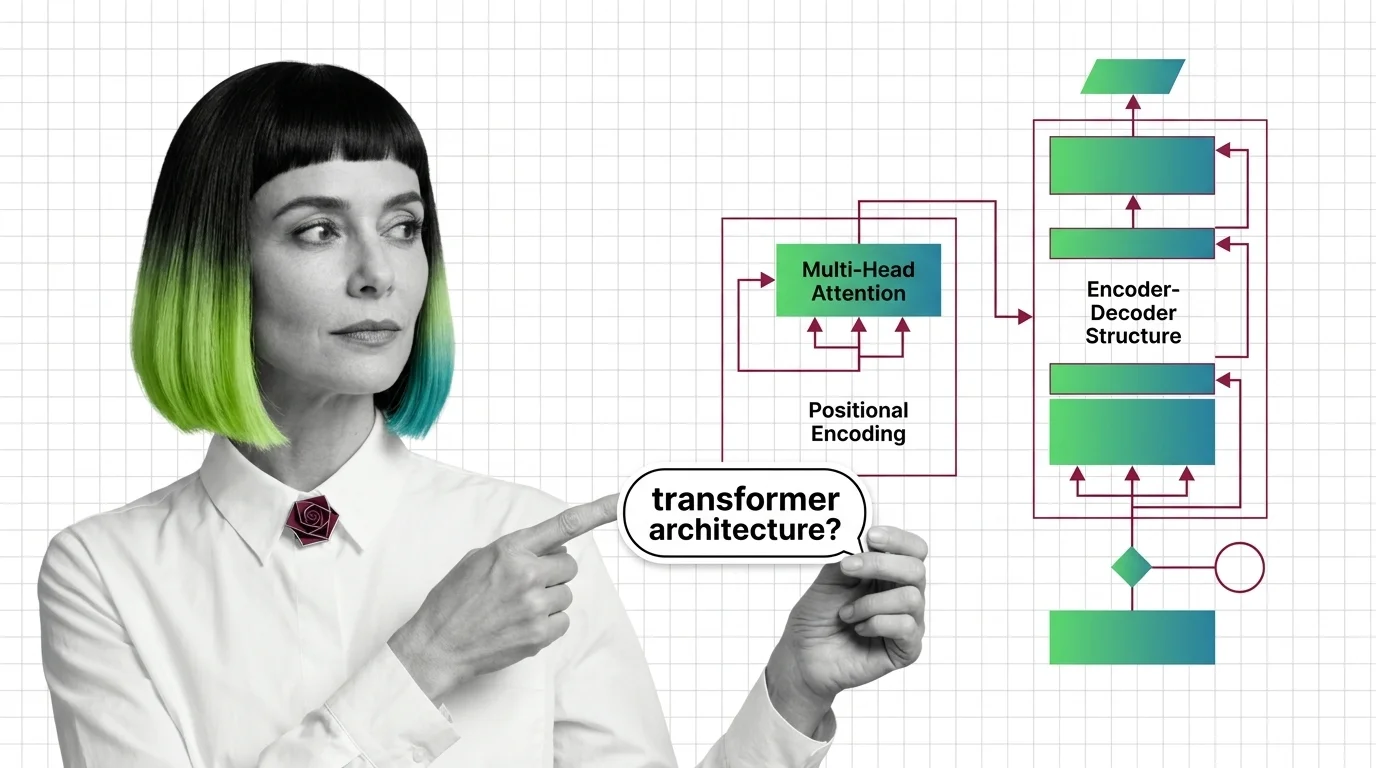
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, explained from geometry to implementation.
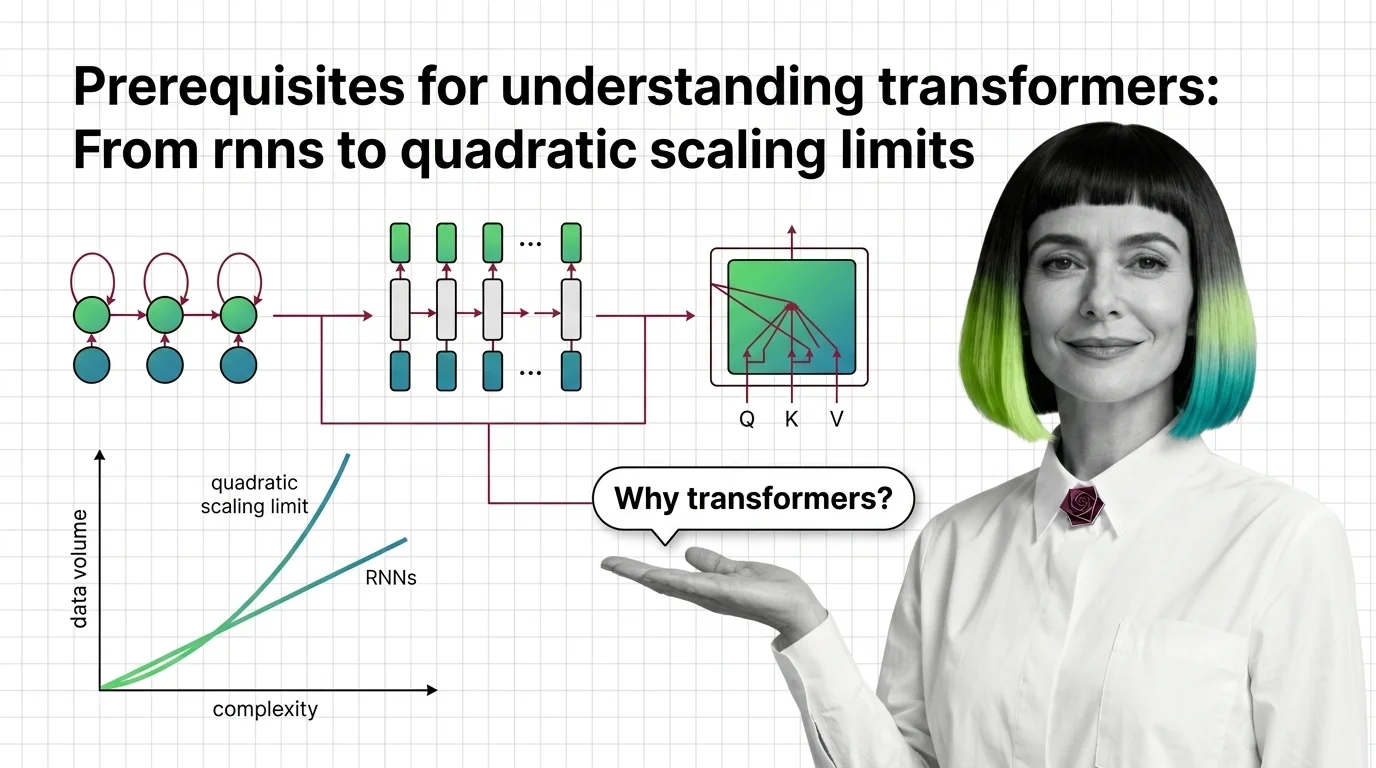
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these trade-offs predict for long-context language models.
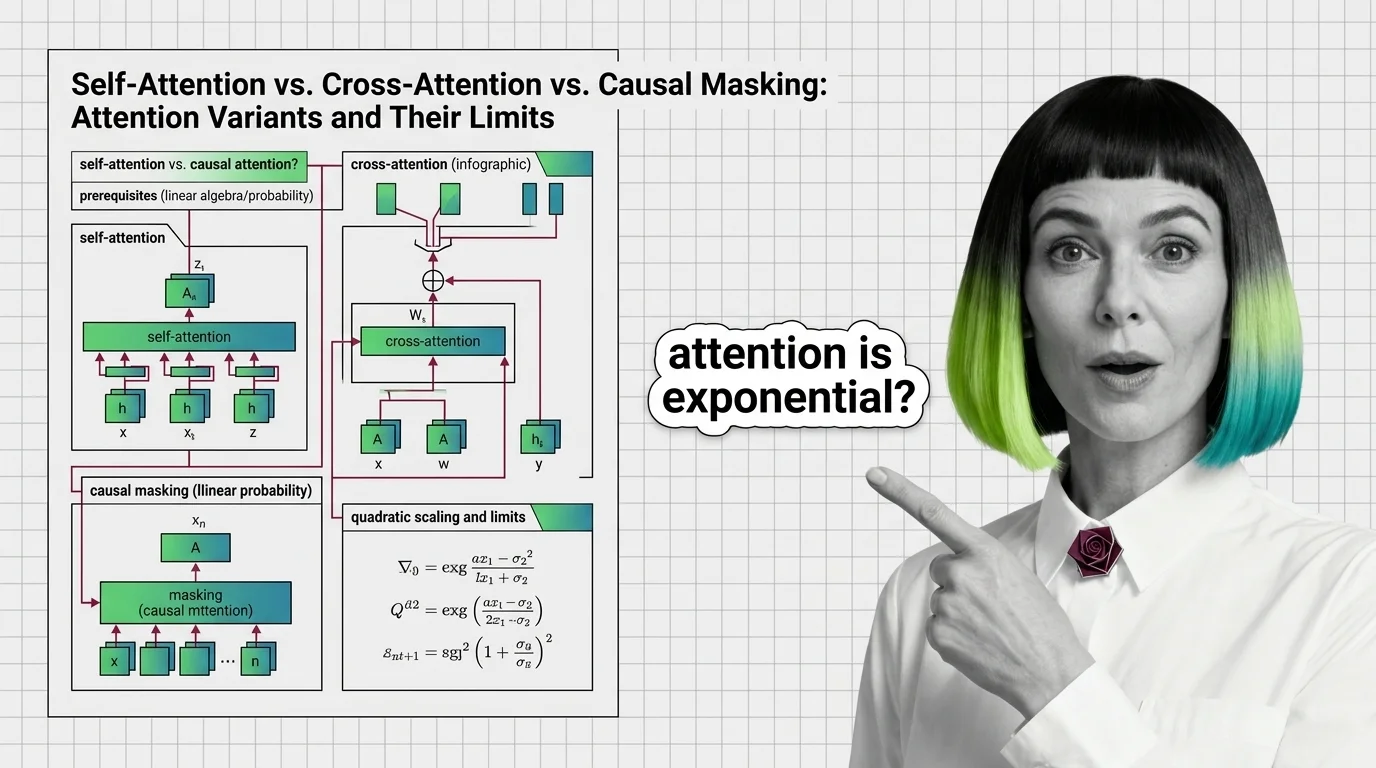
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, trade-offs, and the quadratic scaling wall.

Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive generation produce text one token at a time.
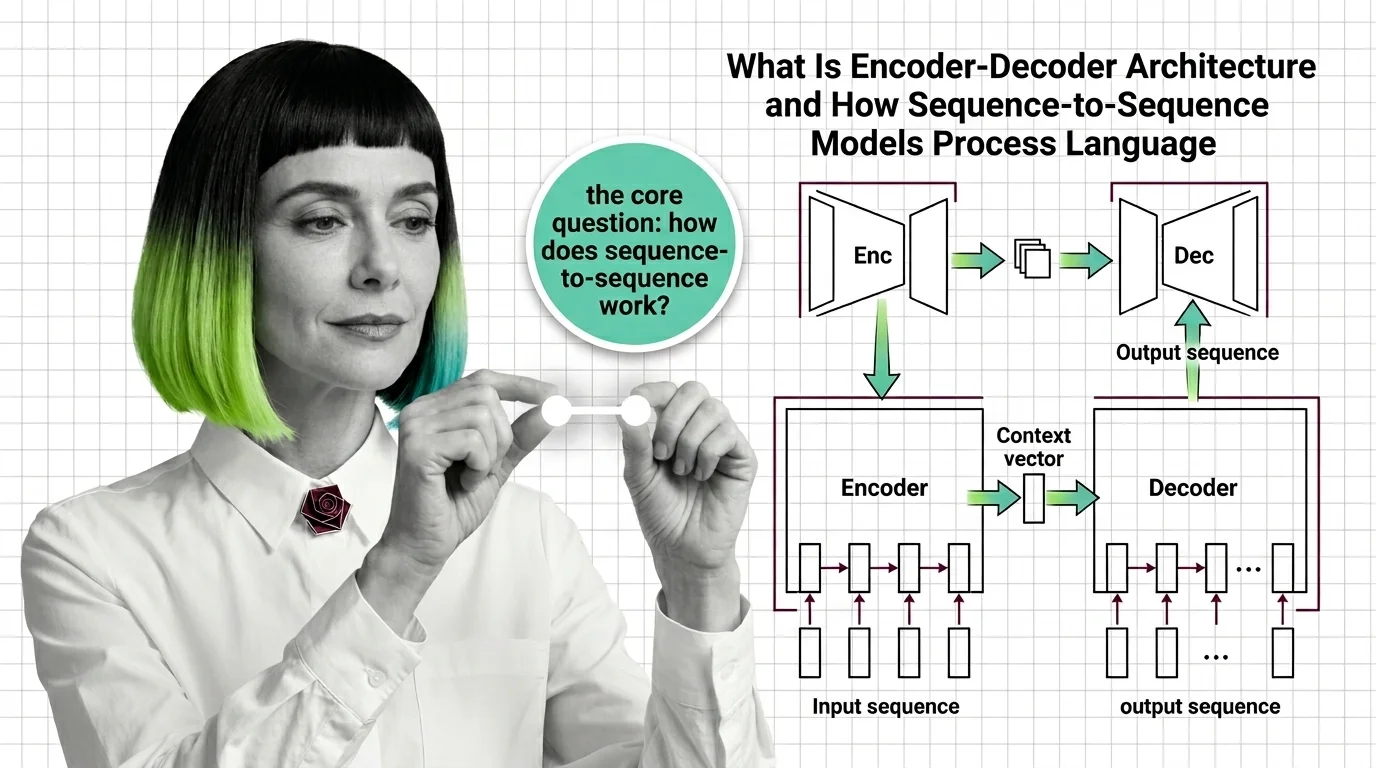
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq works and why attention changed everything.
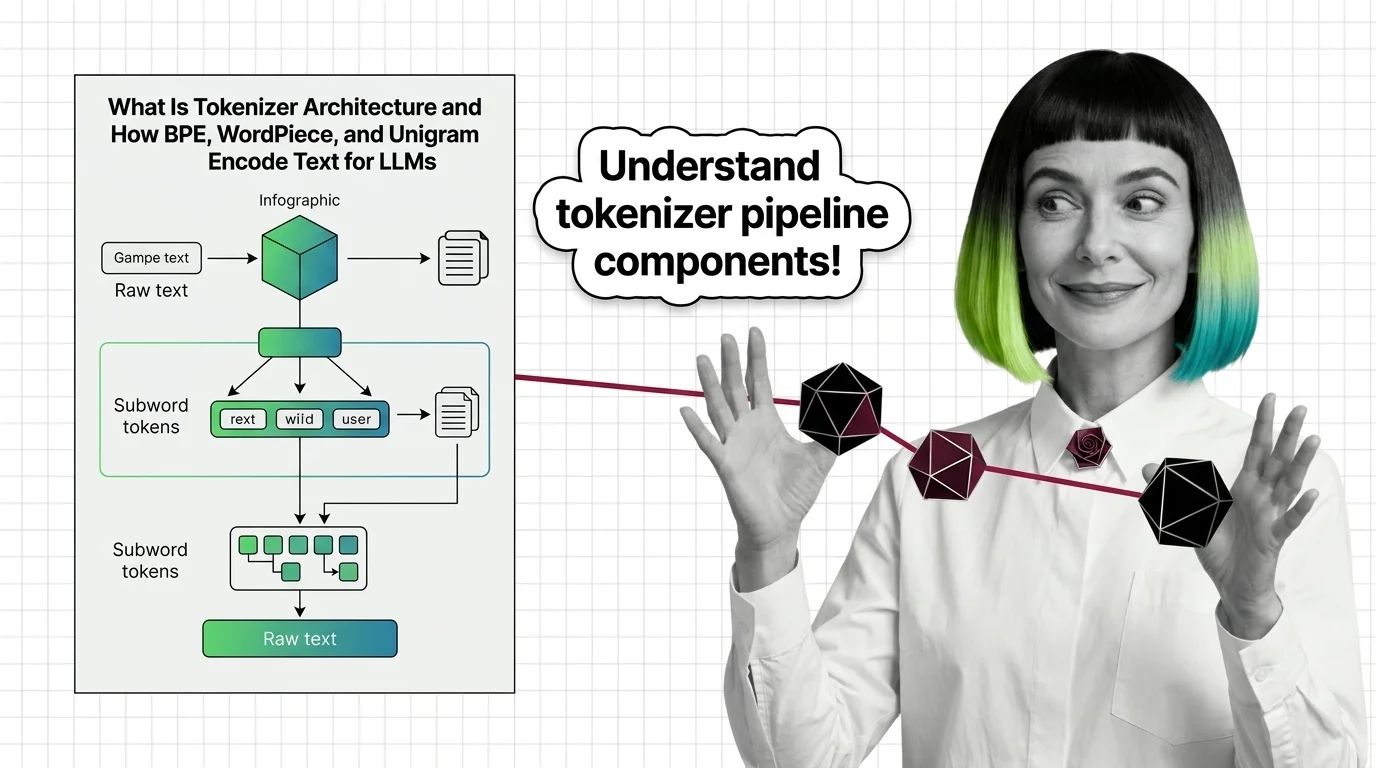
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword tokens before attention ever fires.
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE extensions beat encoder-decoder design.
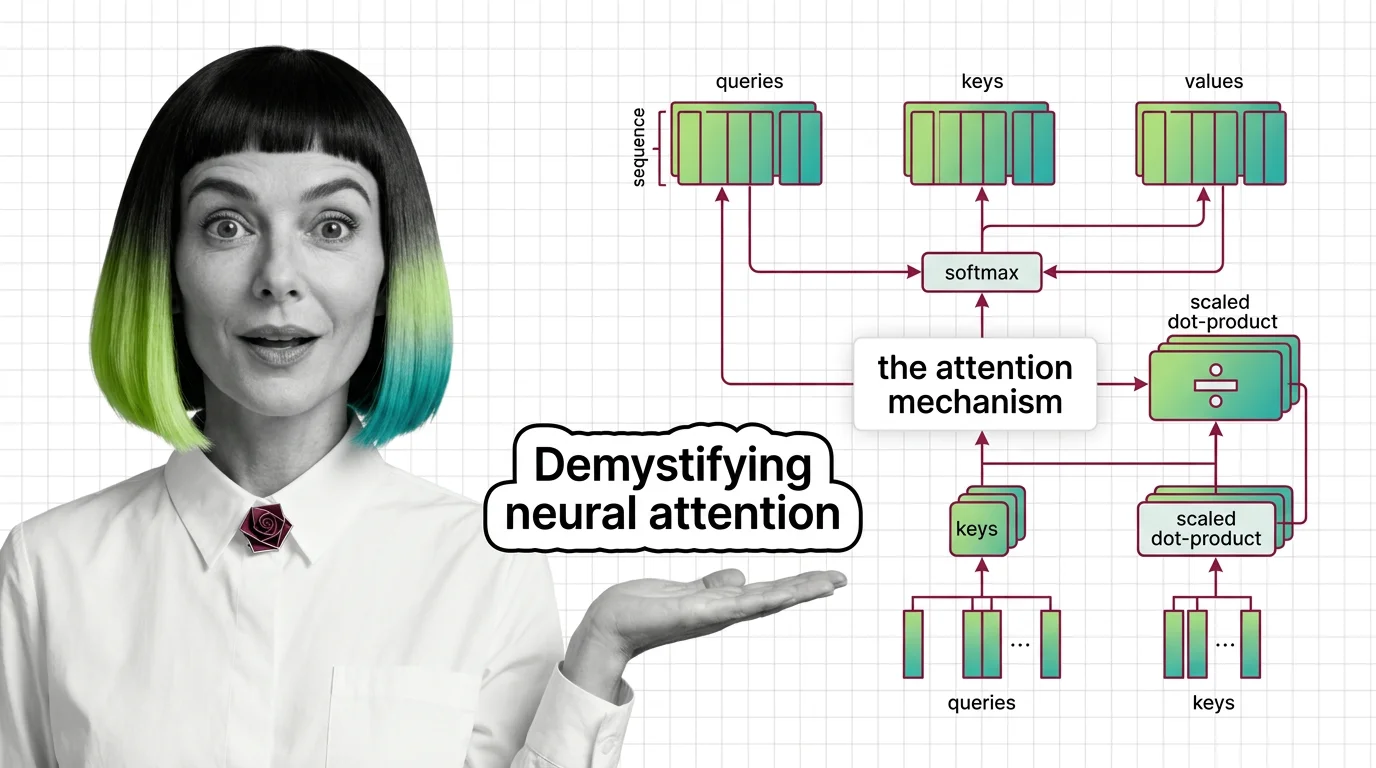
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and scaling factor significance.
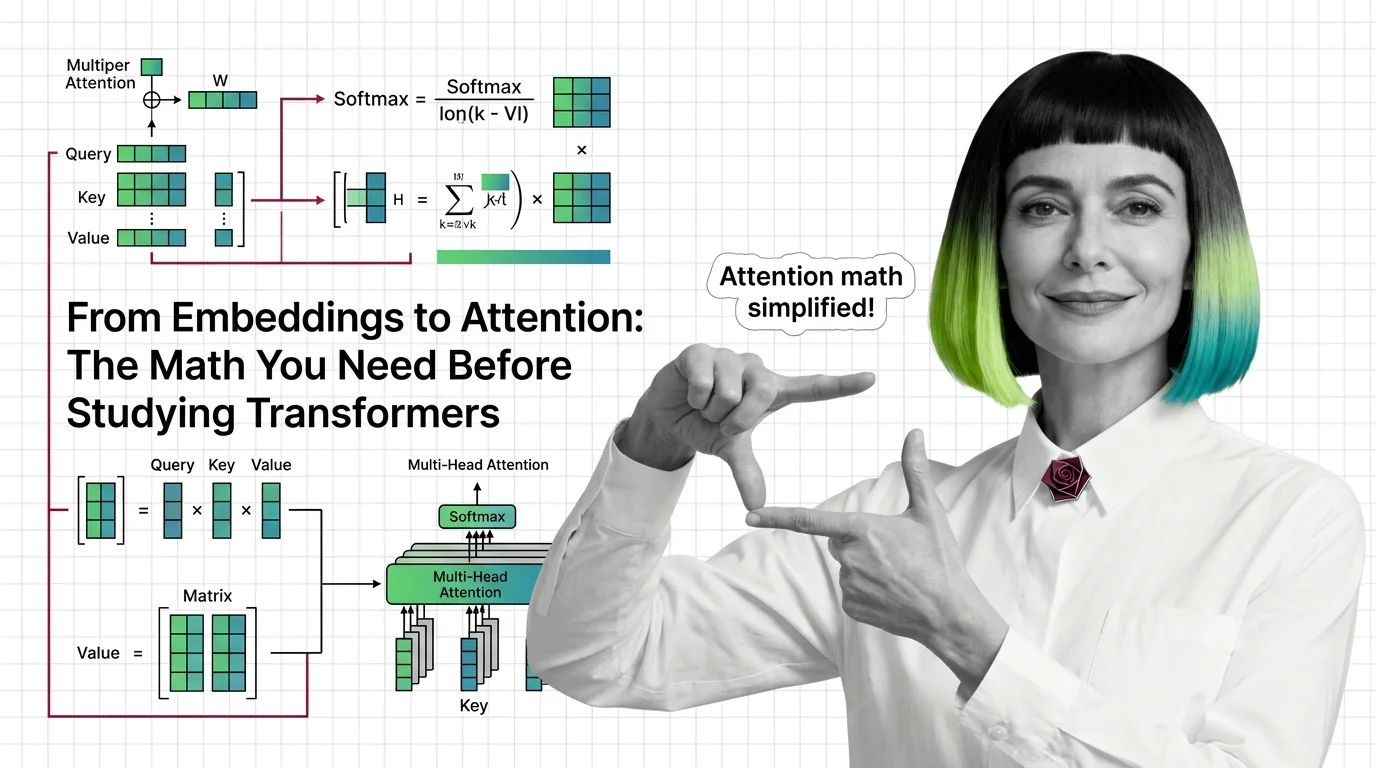
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before tackling transformer architecture.
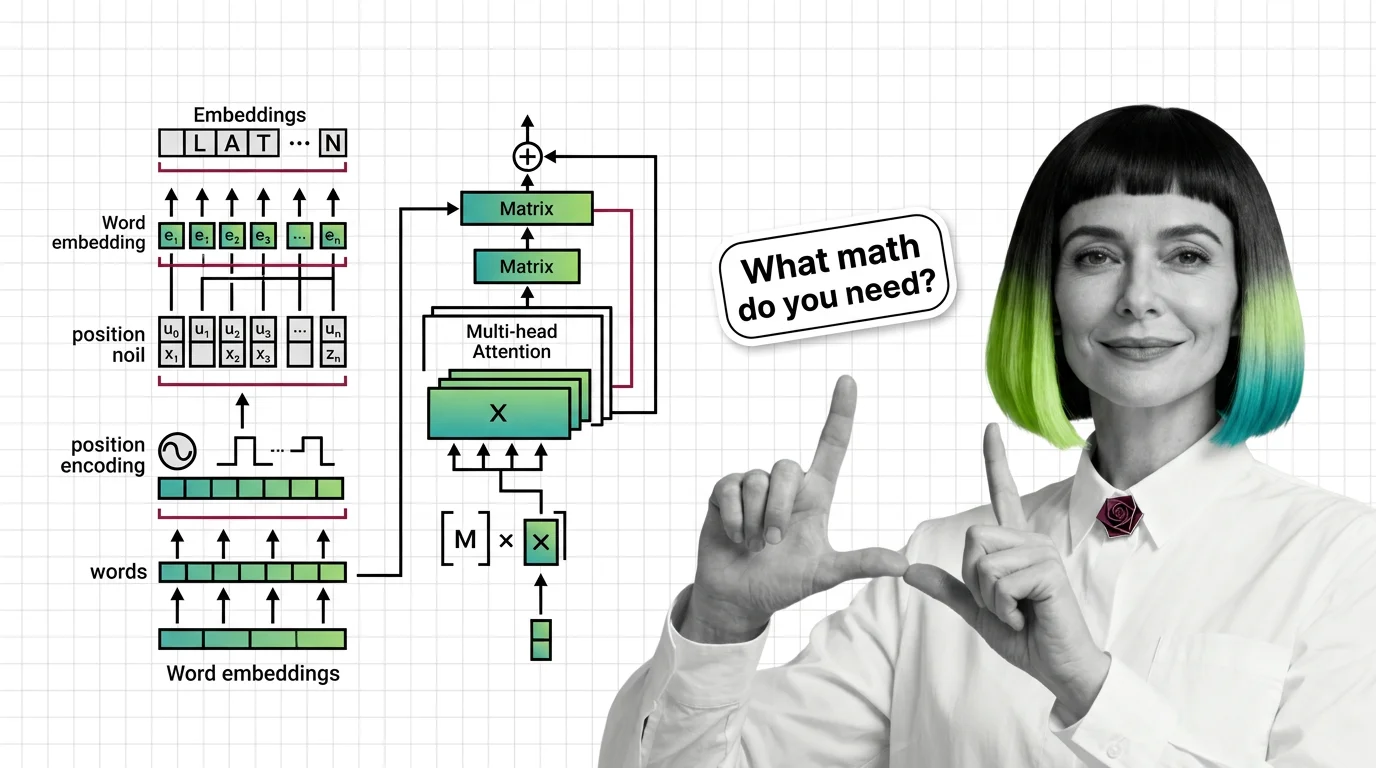
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention explained with the precision engineers actually need.
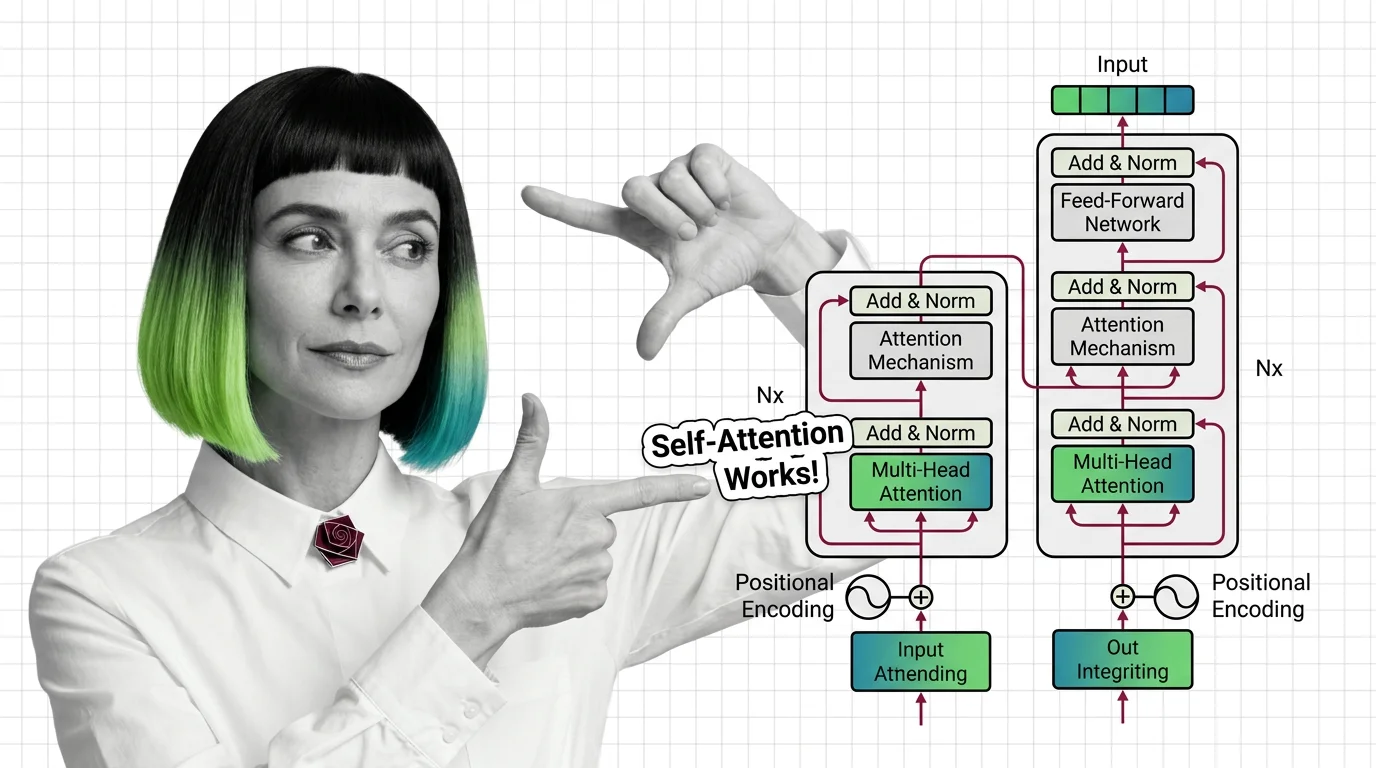
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why multi-head attention matters, and where the math breaks down.
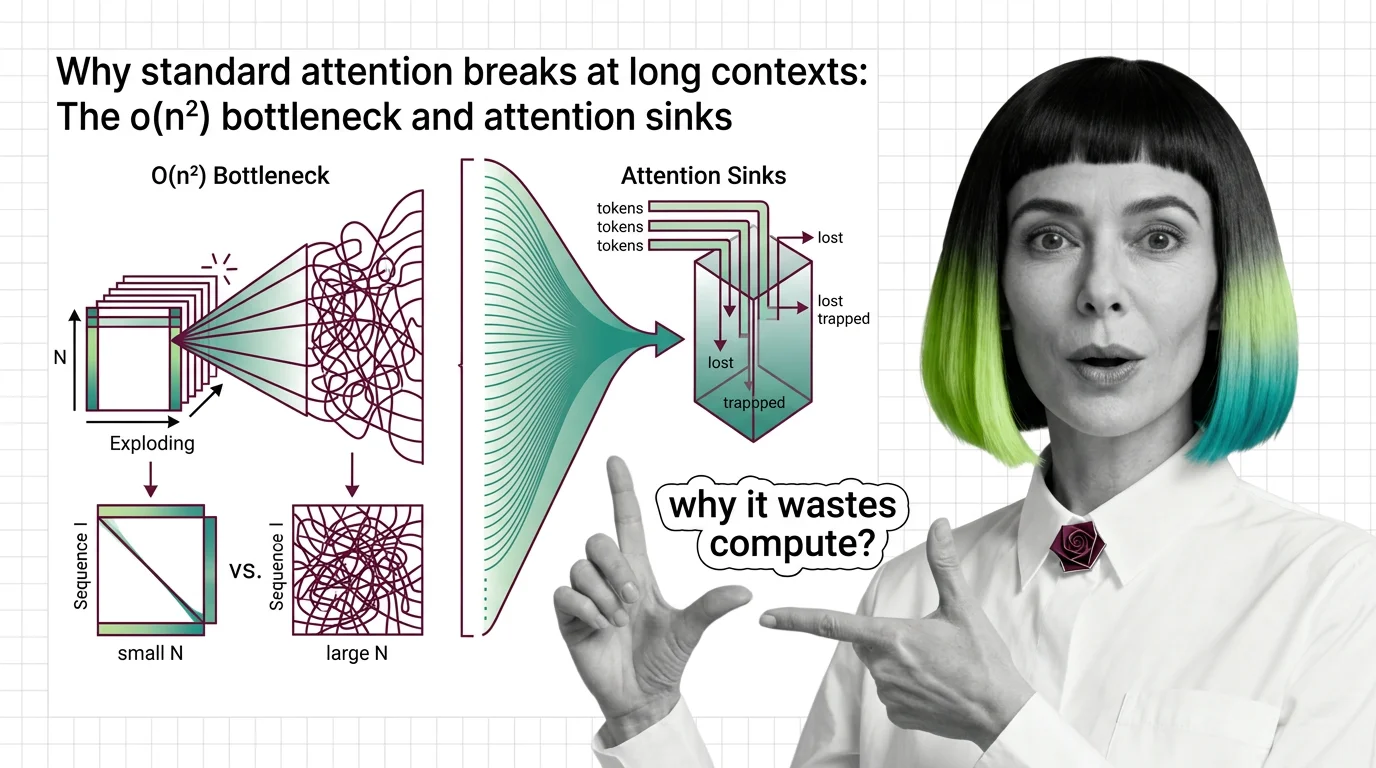
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention sinks waste, and where fixes stand.
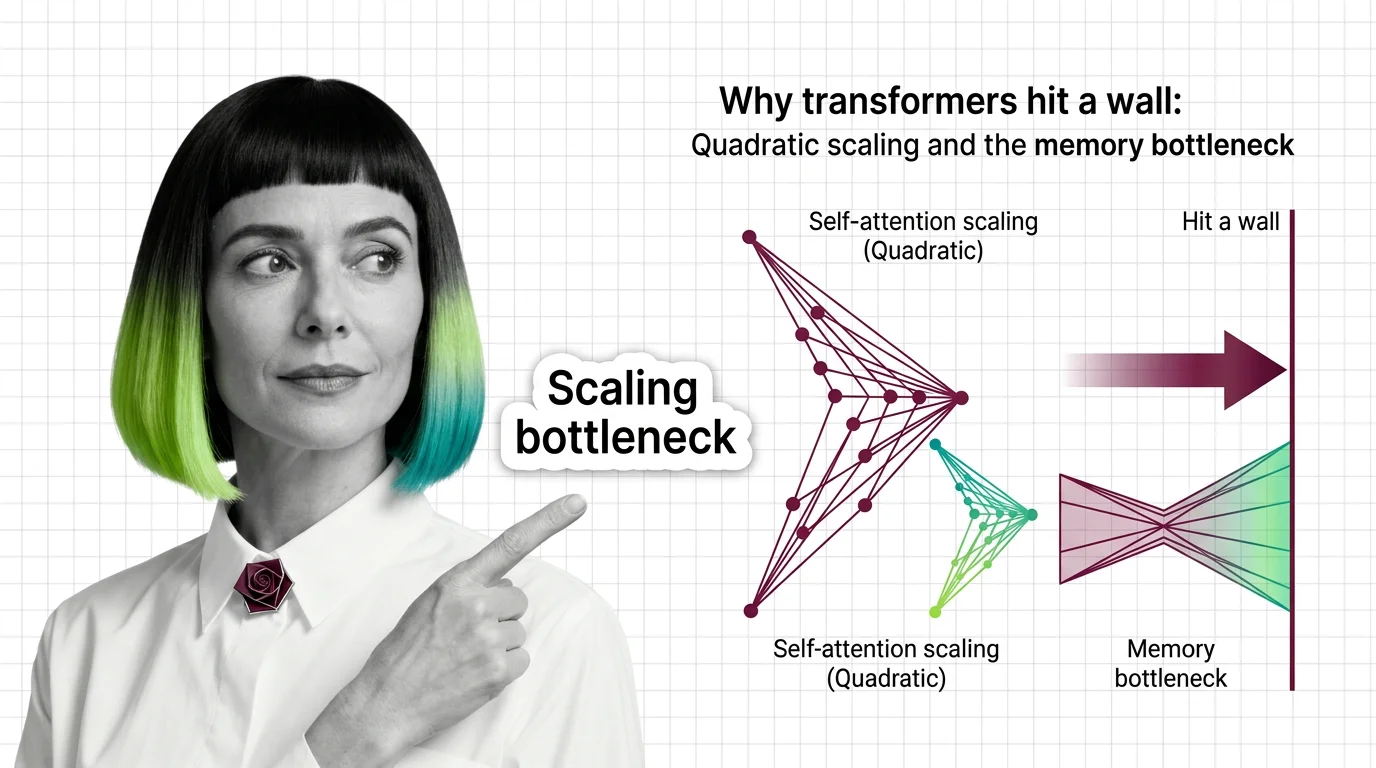
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, and what FlashAttention and SSMs actually fix.