Training data quality and curation is the discipline of building datasets a model can actually learn from: cleaning and transforming raw records, attaching correct labels, expanding the data where it is thin, and removing the duplicates that quietly distort it. The theme spans the whole dataset lifecycle, and this page maps the reading order through it — which practice solves which problem, and where the practices blur into each other.
A model cannot be better than the data it learned from; in practice, teams move accuracy more often by fixing datasets than by swapping models.
Every curation lever cuts both ways: cleaning can erase minority signal, augmentation can corrupt labels, deduplication can shrink diversity.
Labels are usually the most expensive artifact in the pipeline — the core and advanced tiers are largely about spending that budget well.
Two foundations, three core practices, one advanced strategy: read them in that order.
Why training data quality matters for engineers moving into AI
For a software engineer, the hardest adjustment is that data bugs do not throw. A malformed join fails loudly in code; a mislabeled or leaky training set trains without complaint and ships a model that is confidently wrong. That is why the data-centric AI movement treats the dataset, not the model, as the main engineering surface — as the case studies of teams that boosted models by fixing data, not models show, architectures are increasingly a commodity while curated data is where results actually move.
Architectures are becoming a commodity; curated data is where results move.
Start here: what data quality is and how preprocessing shapes it
Two foundations carry everything else in this theme, and neither requires a line of model code to understand.
With these two, you can judge any dataset that crosses your desk. The next tier is about changing one.
The core curation practices: labeling, augmenting, and deduplicating
This is the layer where teams spend real money, and where the production decisions live. Each practice changes the dataset in a different direction — adding ground truth, adding variation, or removing repetition.
Run these three well and the bottleneck moves: the question stops being “how do we label data” and becomes “which data is worth labeling at all”. That question has its own tier.
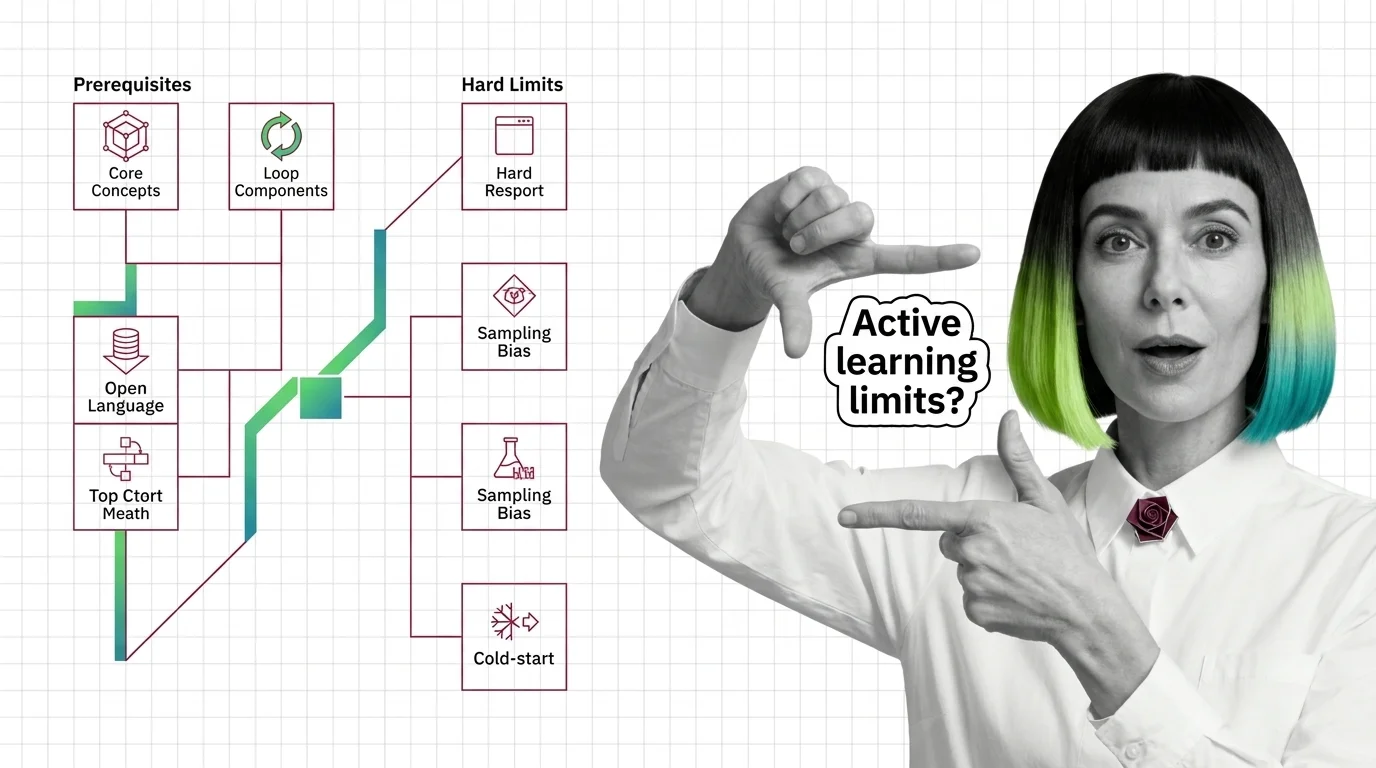
Advanced curation: active learning and spending the labeling budget
The costliest confusion in this theme is treating the practices as interchangeable “data cleanup”. They act on the dataset in different directions, and picking the wrong one burns the budget the right one needed.
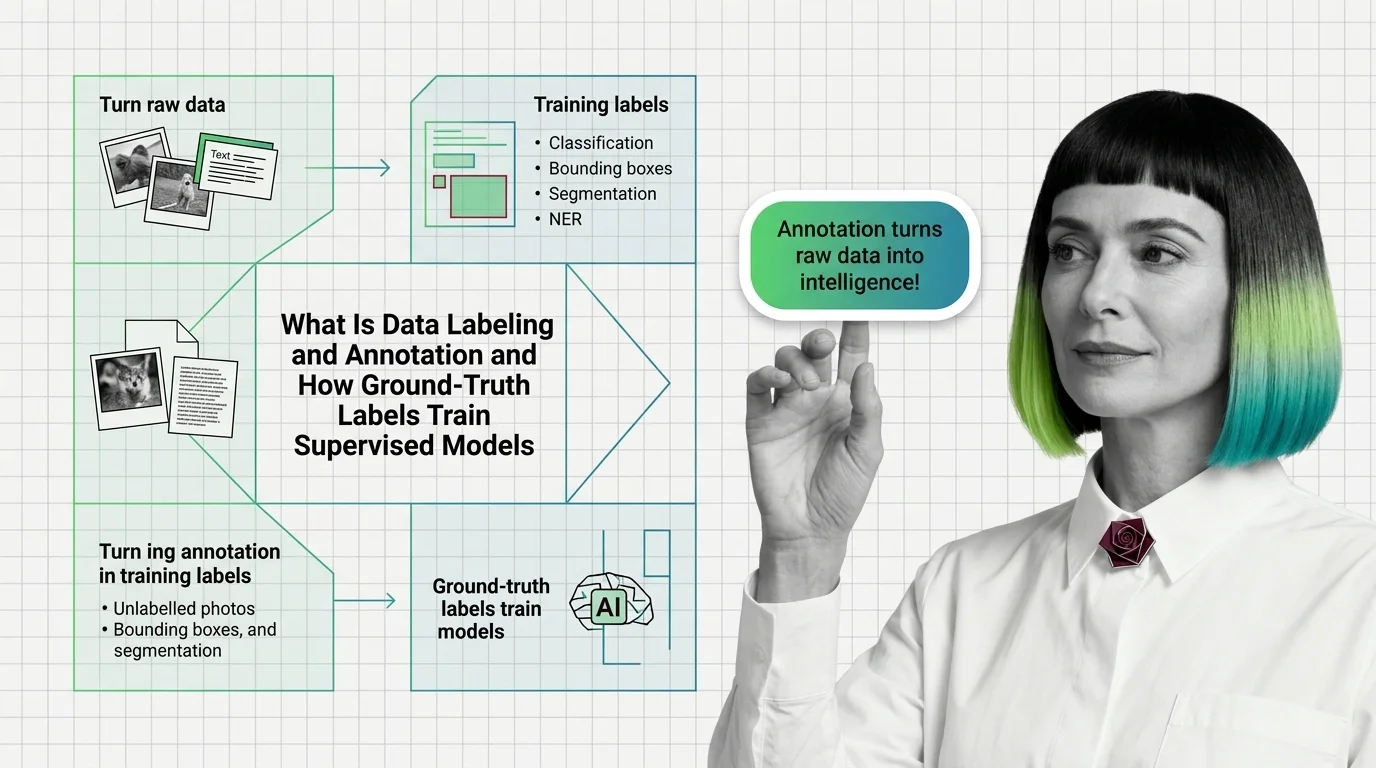
Labeling
Augmentation
Deduplication
Active learning
What it changes
Adds ground truth to samples
Adds variation to existing samples
Removes repetition
Targets which samples get labeled
Dataset size
Unchanged (now annotated)
Grows
Shrinks
Grows selectively
Best when
Supervised task, unlabeled data on hand
Labeled data is scarce but representative
Large web-scraped or merged corpora
Annotation budget is the constraint
Main cost
Annotator time and QA
Compute, plus label-corruption risk
Risk of discarding rare valid samples
Loop complexity: retrain, re-query, re-label
Failure mode
Noisy or inconsistent labels
Distribution shift from unrealistic transforms
Lost diversity, false-positive merges
Sampling bias compounding over rounds
Three finer distinctions trip readers just as often:
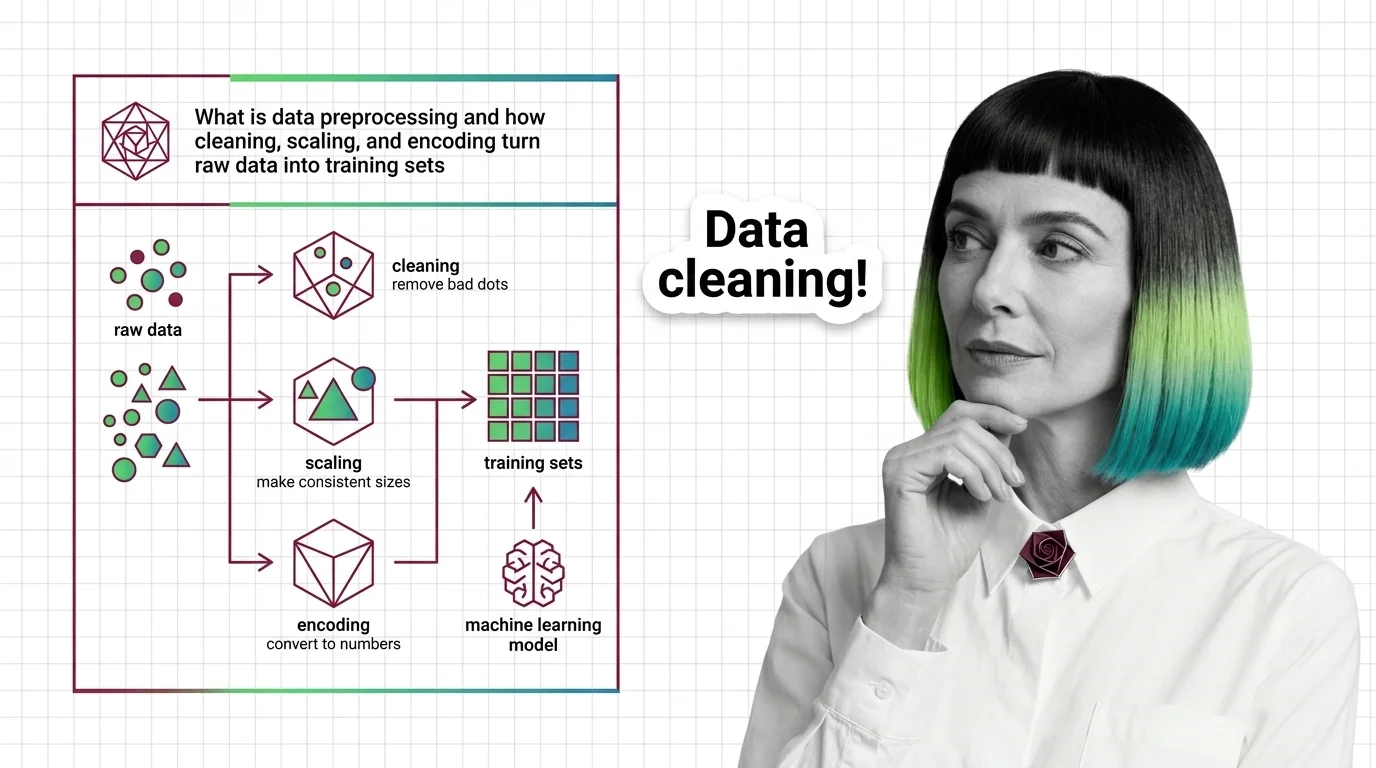
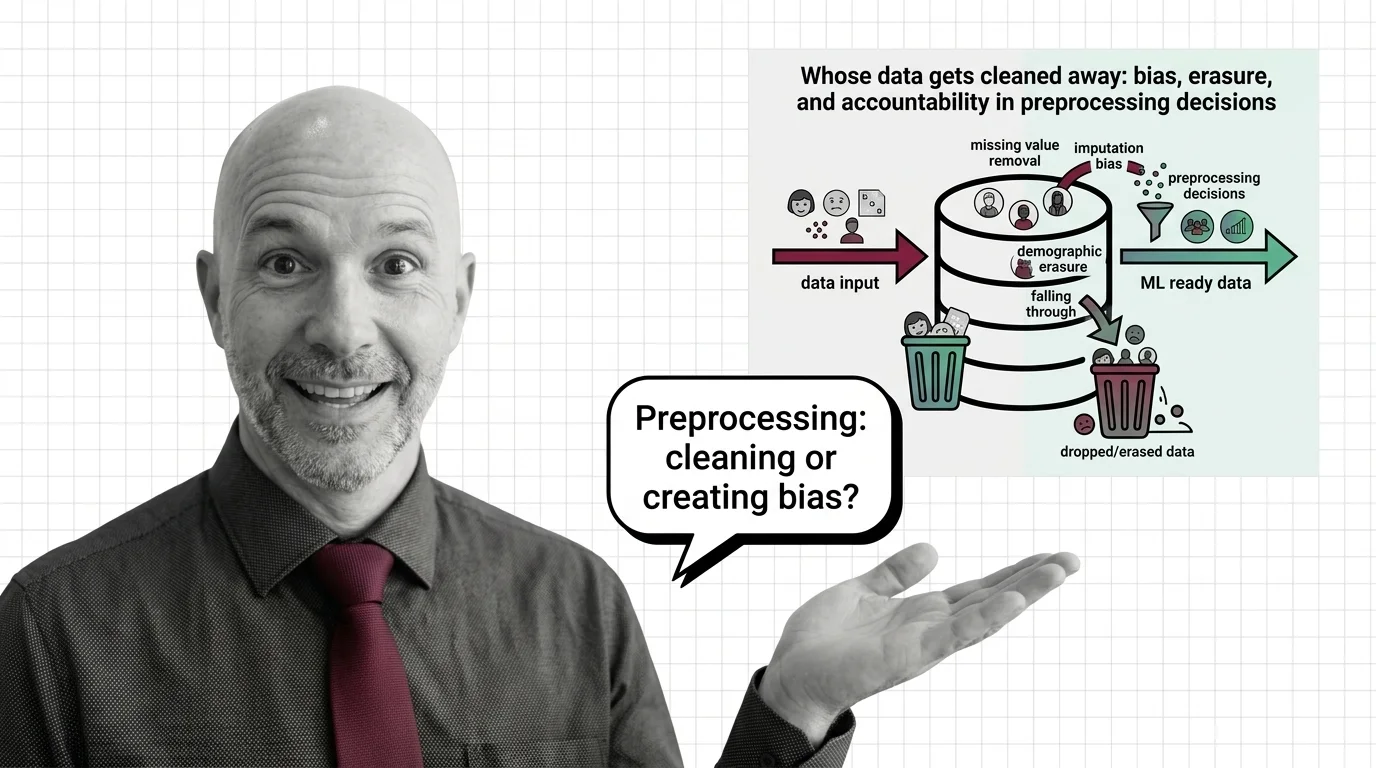
Preprocessing vs curation.Preprocessing makes data consumable — formats, scales, encodings — while quality work makes it correct. A perfectly preprocessed dataset can still be full of wrong labels; the two stages are sequential, not synonymous.
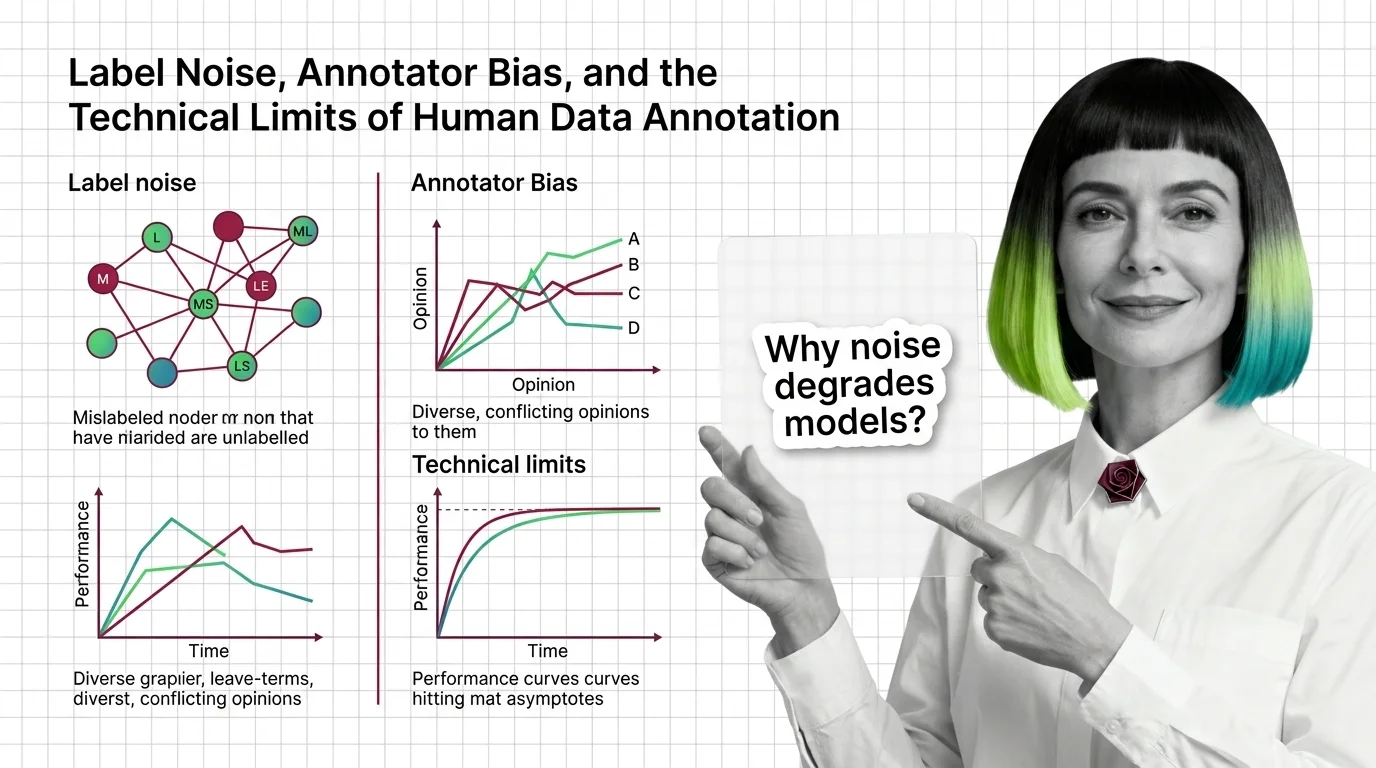
Label noise vs annotator bias. Noise is random disagreement you can measure and average away; bias is systematic skew that agreement metrics alone will not surface. The technical limits of human annotation separates the two, and whose data counts follows the consequences into the models that ship.
Cleaning up vs cleaning away. Every filtering rule embeds a judgment about what “bad data” is — whose data gets cleaned away shows how routine preprocessing decisions quietly become editorial ones.
Common questions
Q: Where should I start when a model seems data-limited rather than model-limited?
A: Diagnose before curating: check for label noise, class imbalance, and distribution shift first, because each points to a different tier of this theme — relabeling, rebalancing through augmentation, or re-collecting. Fixing the wrong one burns budget without moving accuracy.
Q: Should I label more data or augment what I already have?
A: Augment when your labeled set is representative but small; label when whole regions of the input space are missing, since no transform invents unseen classes. When augmentation helps and when it hurts gives the decision criteria — augmenting a biased set only multiplies the bias.
Q: Do I need active learning, or is random sampling enough?
A: Random sampling is enough while labeling stays cheap relative to dataset size; active learning pays off once annotation is the binding constraint and your labeling pipeline is already stable. Before active learning lists the prerequisites that decide whether the loop’s complexity is worth it.
Q: Why does my model memorize instead of generalizing, even on a large dataset?
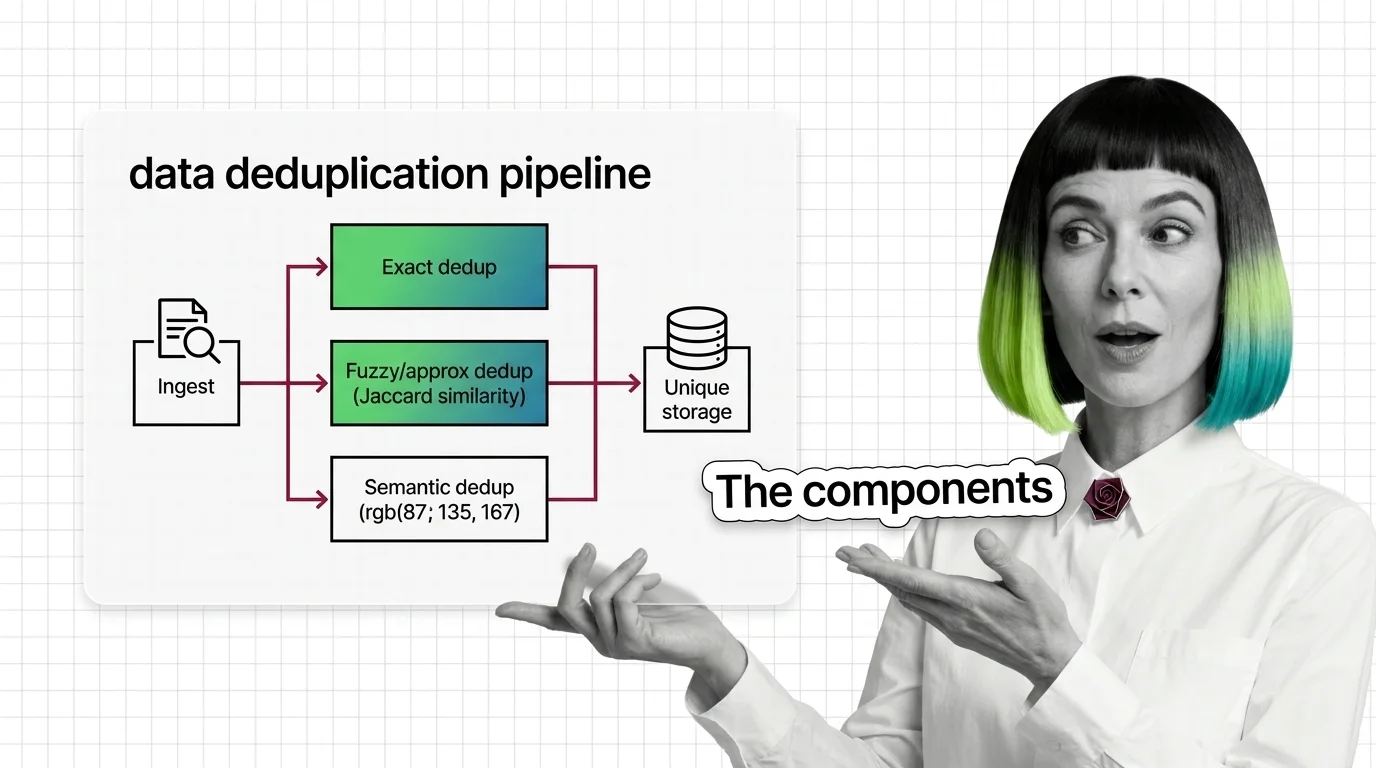
A: Size is not diversity: web-scraped corpora are dense with near-duplicates, and repeated samples teach a model to recite rather than generalize. Run near-duplicate detection before blaming the architecture — MinHash LSH deduplication is the standard first pass at corpus scale.
Q: When is a labeling project ready to scale beyond one annotator?
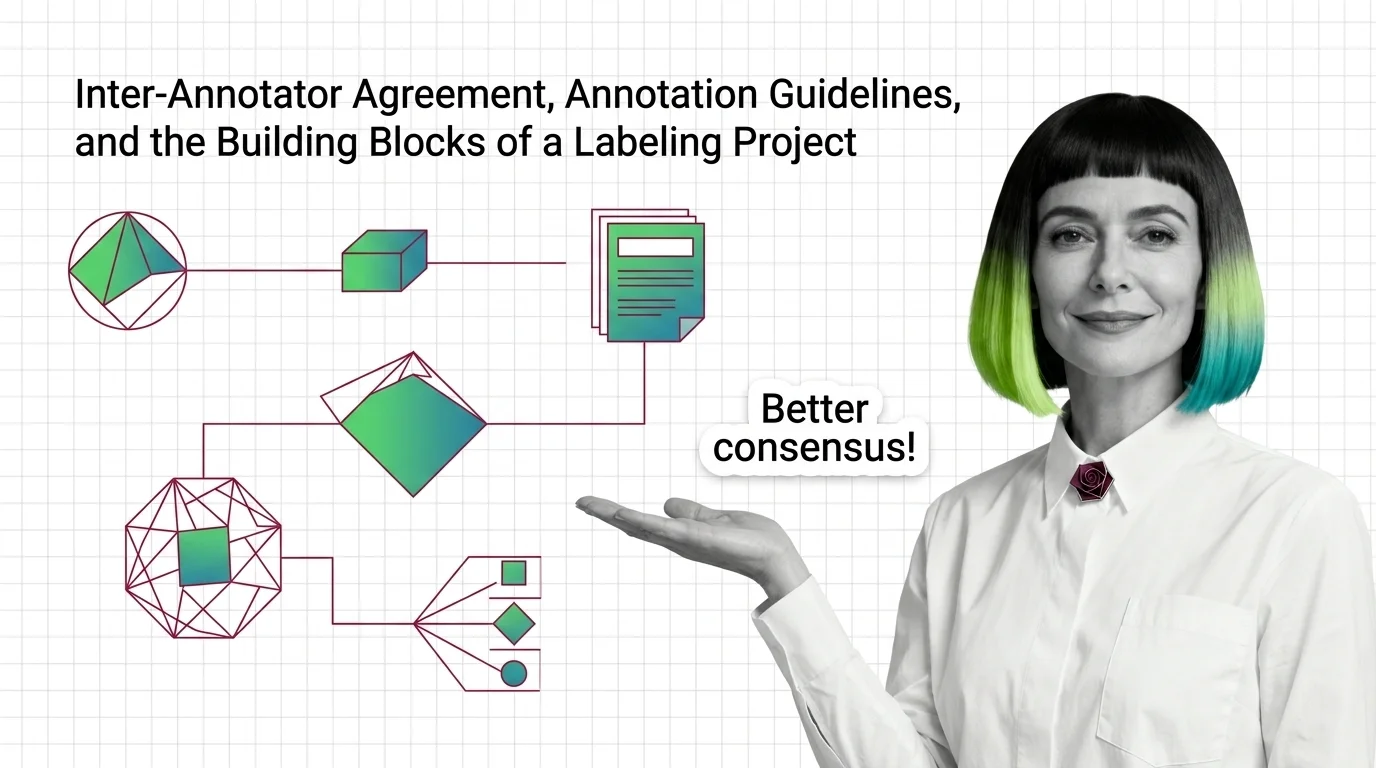
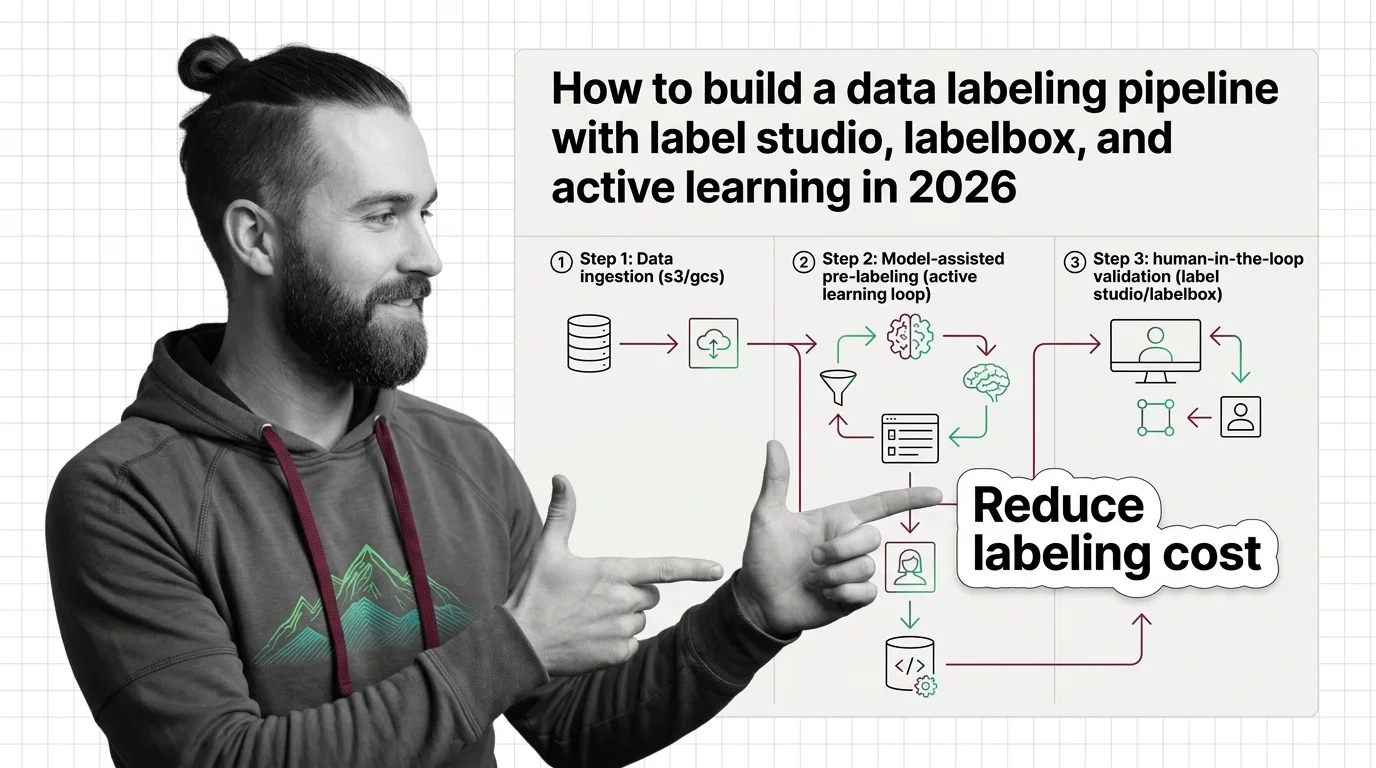
A: When the guidelines are written down and agreement is measured — not before. Inter-annotator agreement and annotation guidelines covers that instrumentation; without it, adding annotators multiplies inconsistency instead of throughput, and the resulting noise downstream looks like a model problem.
Split data into train and test sets before preprocessing to prevent data leakage. Fitting scalers on the full dataset inflates accuracy and fails in production.
Data leakage occurs when information unavailable at prediction time enters training, inflating validation accuracy while production performance collapses.
Data preprocessing cleans, scales, and encodes raw data into model-ready features. Fitting transformers before the train-test split causes data leakage.
Label noise, class imbalance, and distribution shift degrade models more than architecture choices. Understand all three before curating training data.
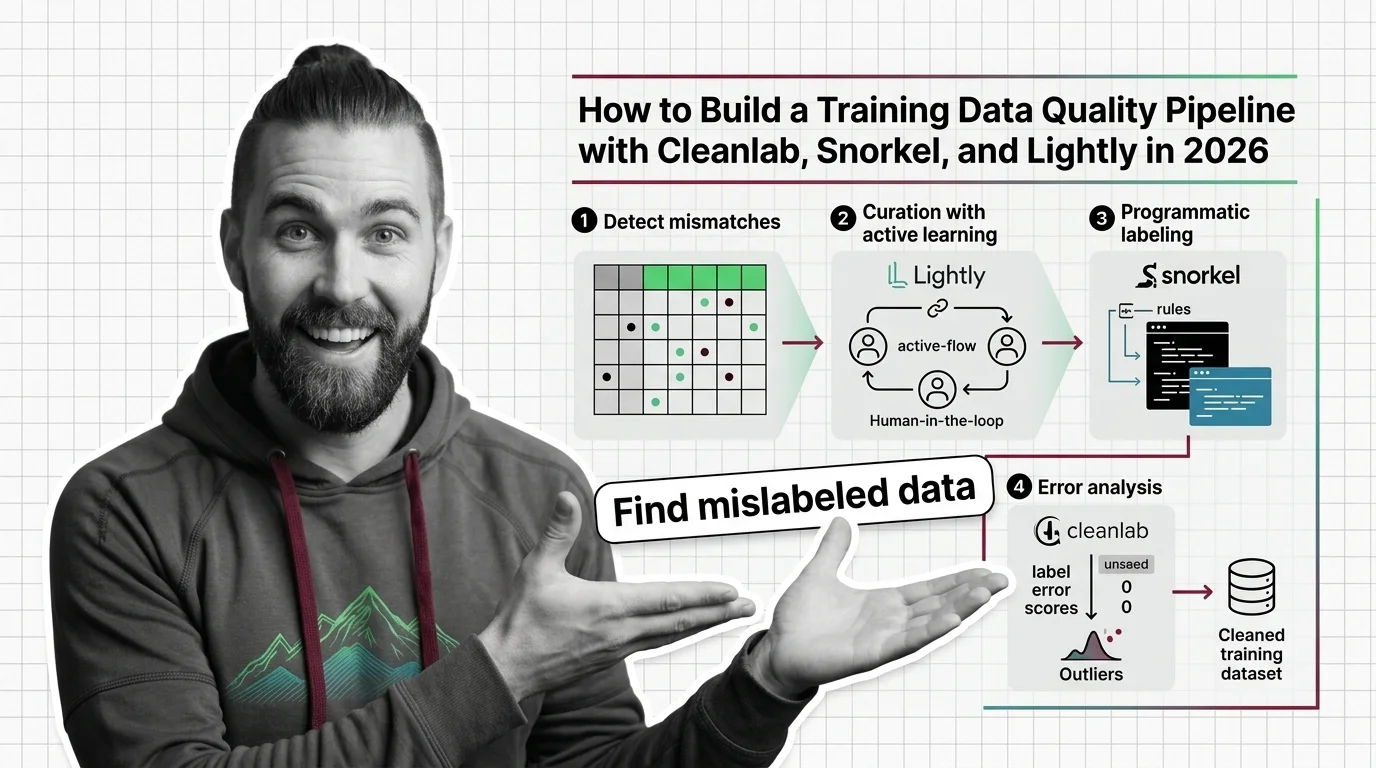
Training data quality is the systematic engineering of label correctness, deduplication, and provenance — it sets the ceiling on what any model can learn.
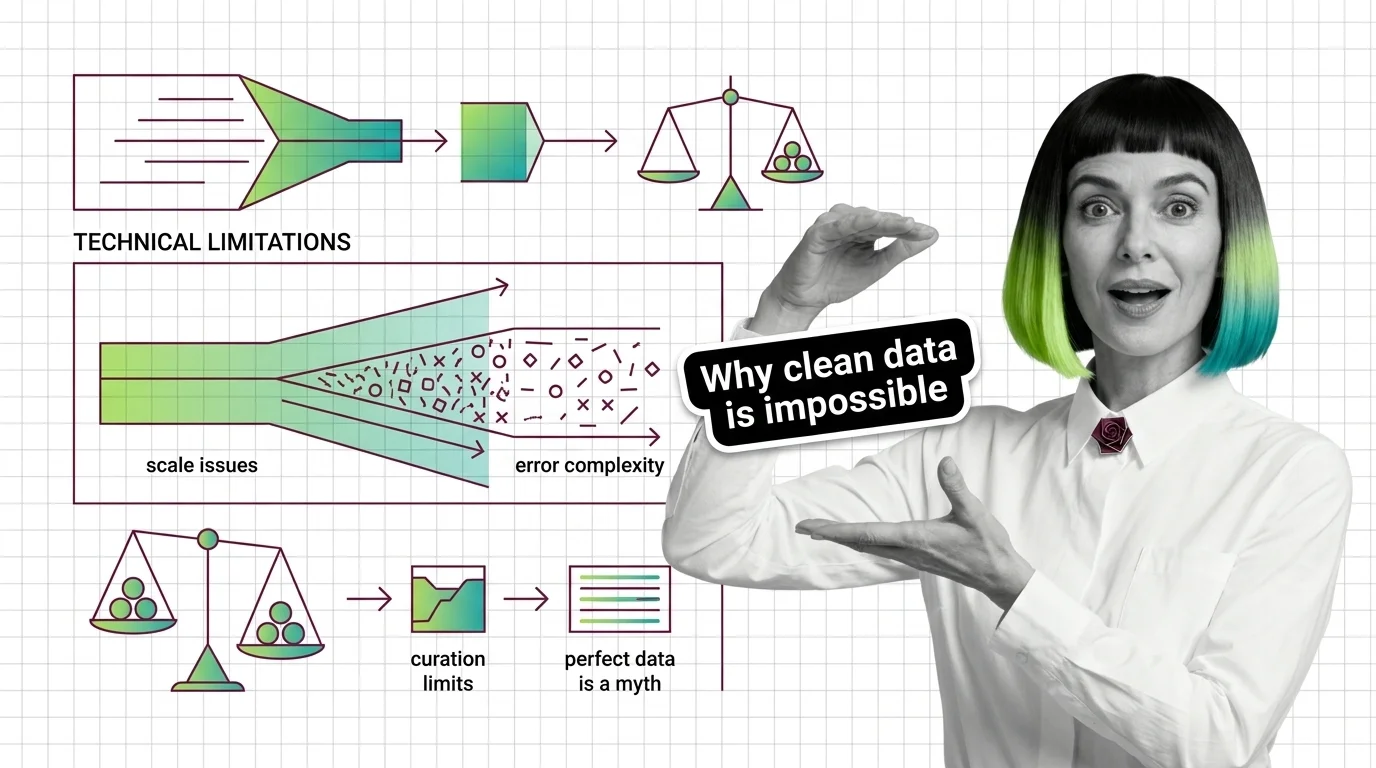
Cleaning training data at scale hits hard limits: label errors average 3.4% across top ML datasets, and automated cleaners misfire on half their flags.
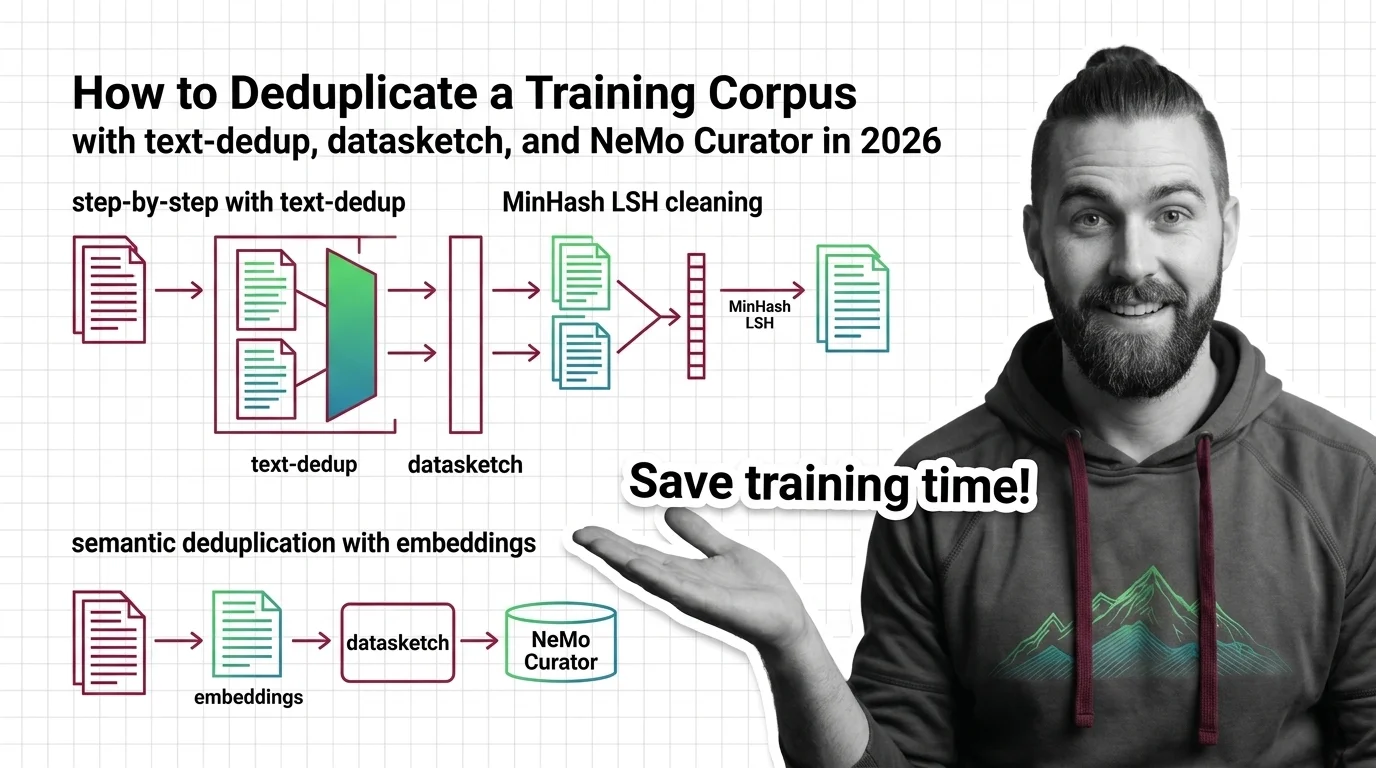
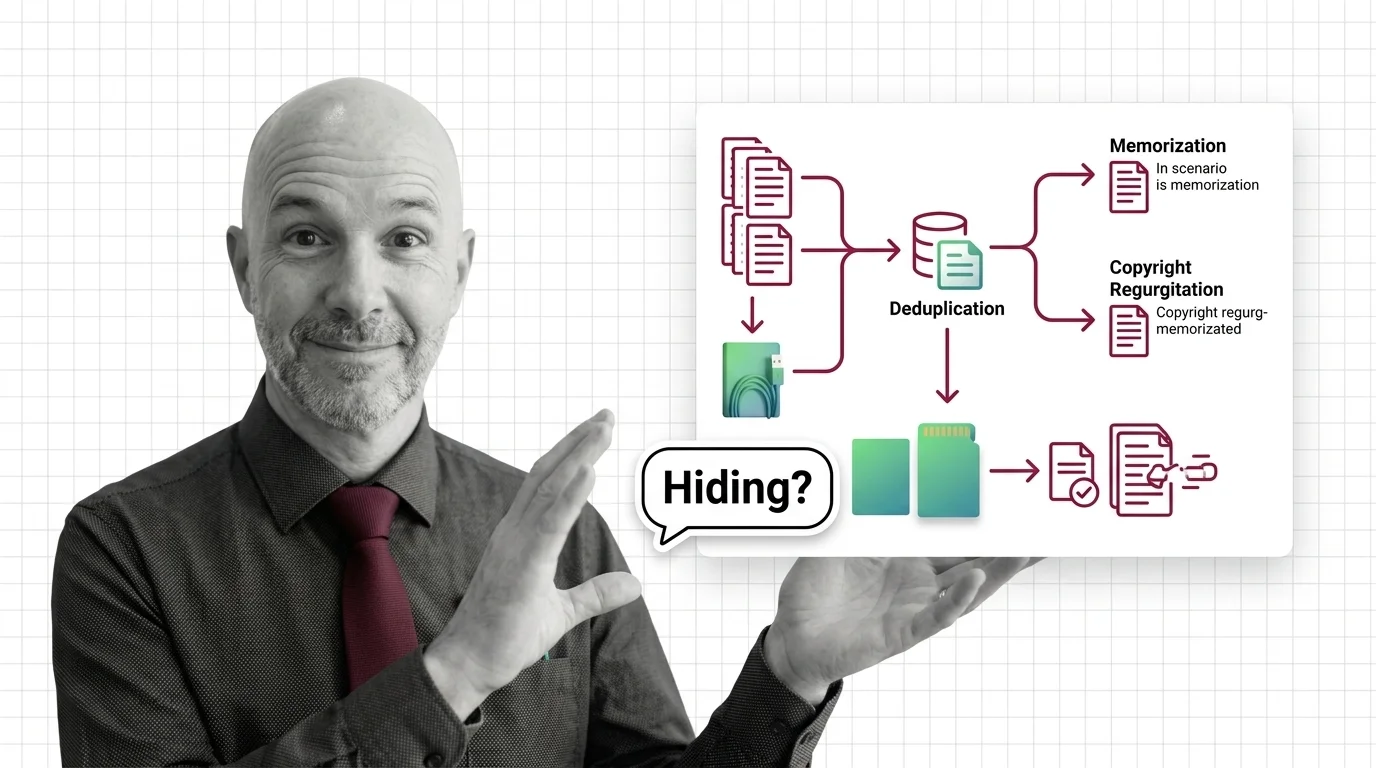
Data deduplication runs in three tiers: exact (hashing), fuzzy (MinHash+LSH), and semantic (embeddings). SemDeDup removed ~50% of web data with minimal loss.
Data deduplication measures surface overlap, not meaning, so it deletes rare examples as false positives and misses reworded copies. Here are the limits.
Label noise averages an estimated 3.4% across major ML test sets, distorting supervised model accuracy and even flipping benchmark leaderboard rankings.
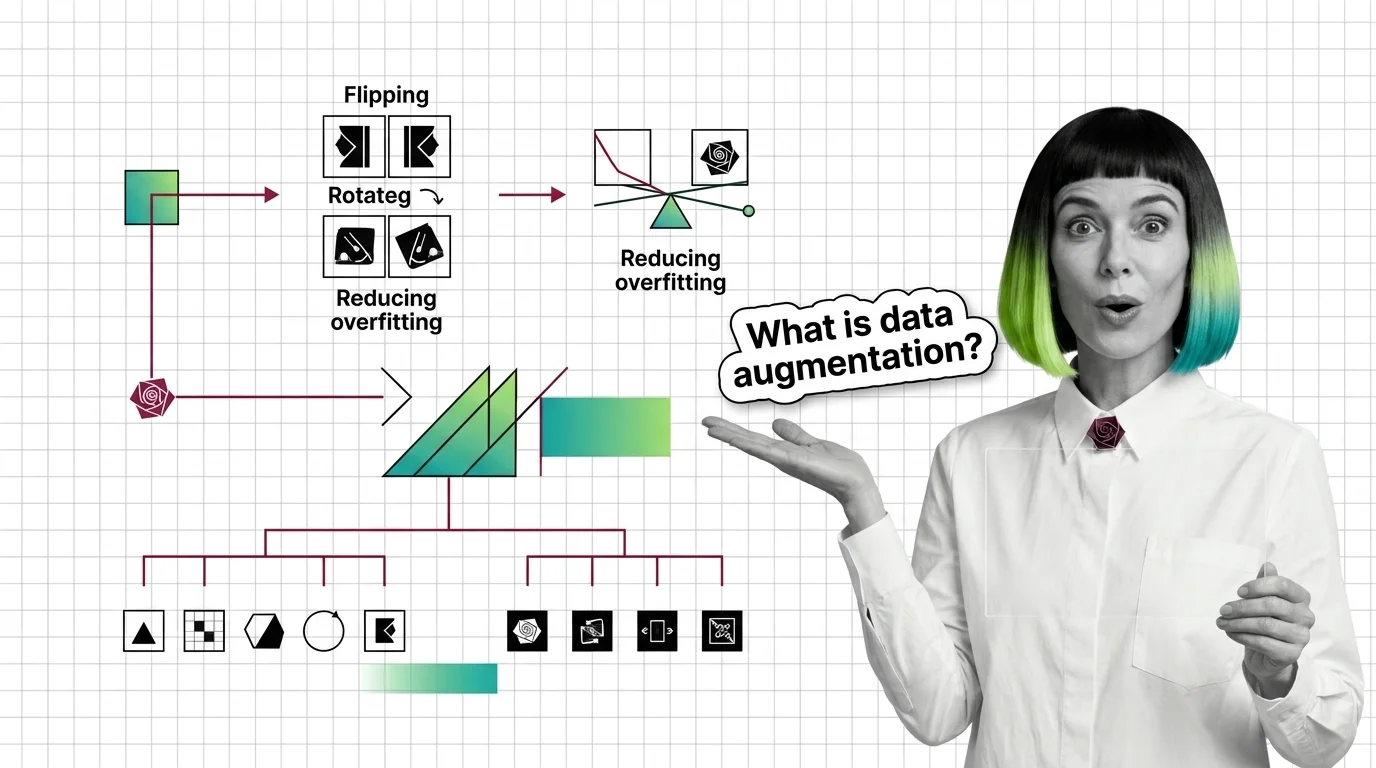
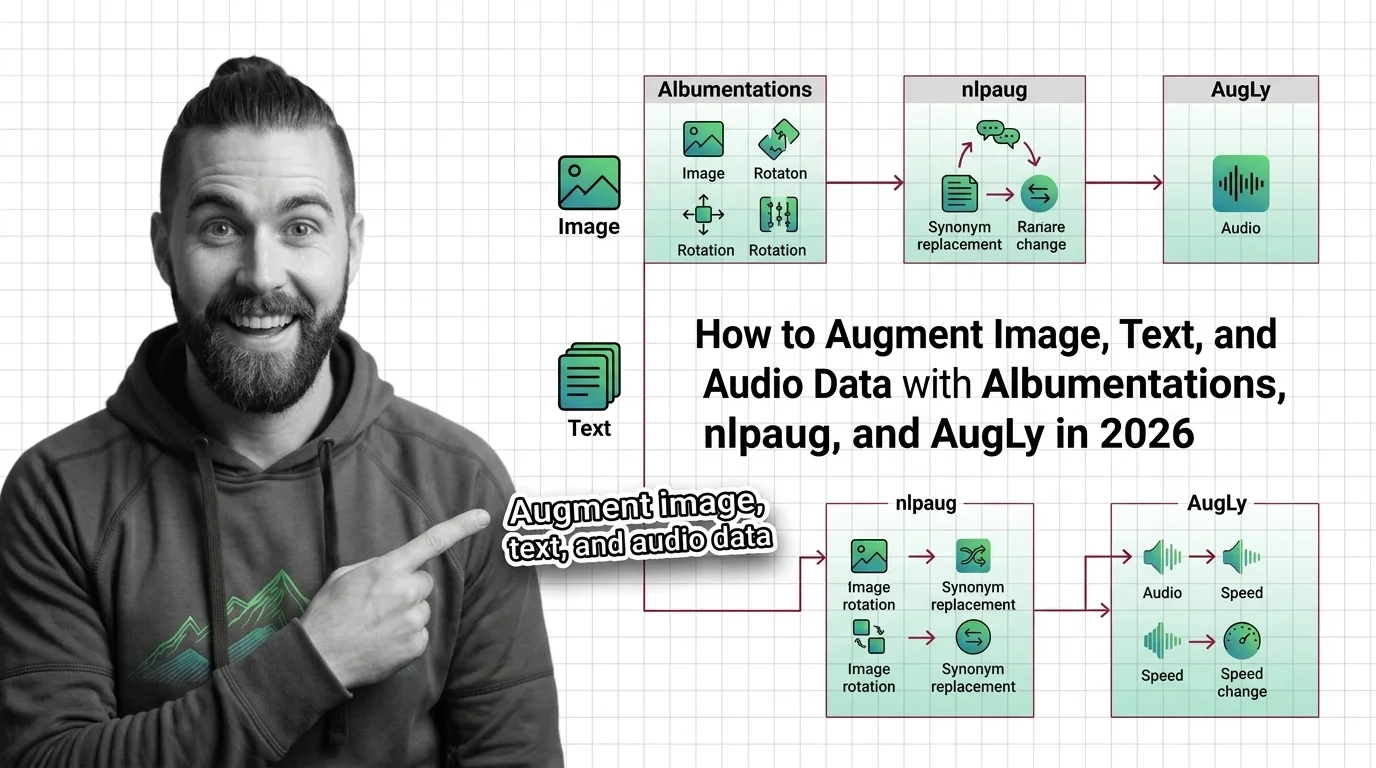
Data augmentation expands training data by transforming existing samples—rotations, mixup, masking—to reduce overfitting without collecting anything new.
Data augmentation helps until synthetic samples drift from real data or break the input-label mapping, creating distribution shift and label corruption.
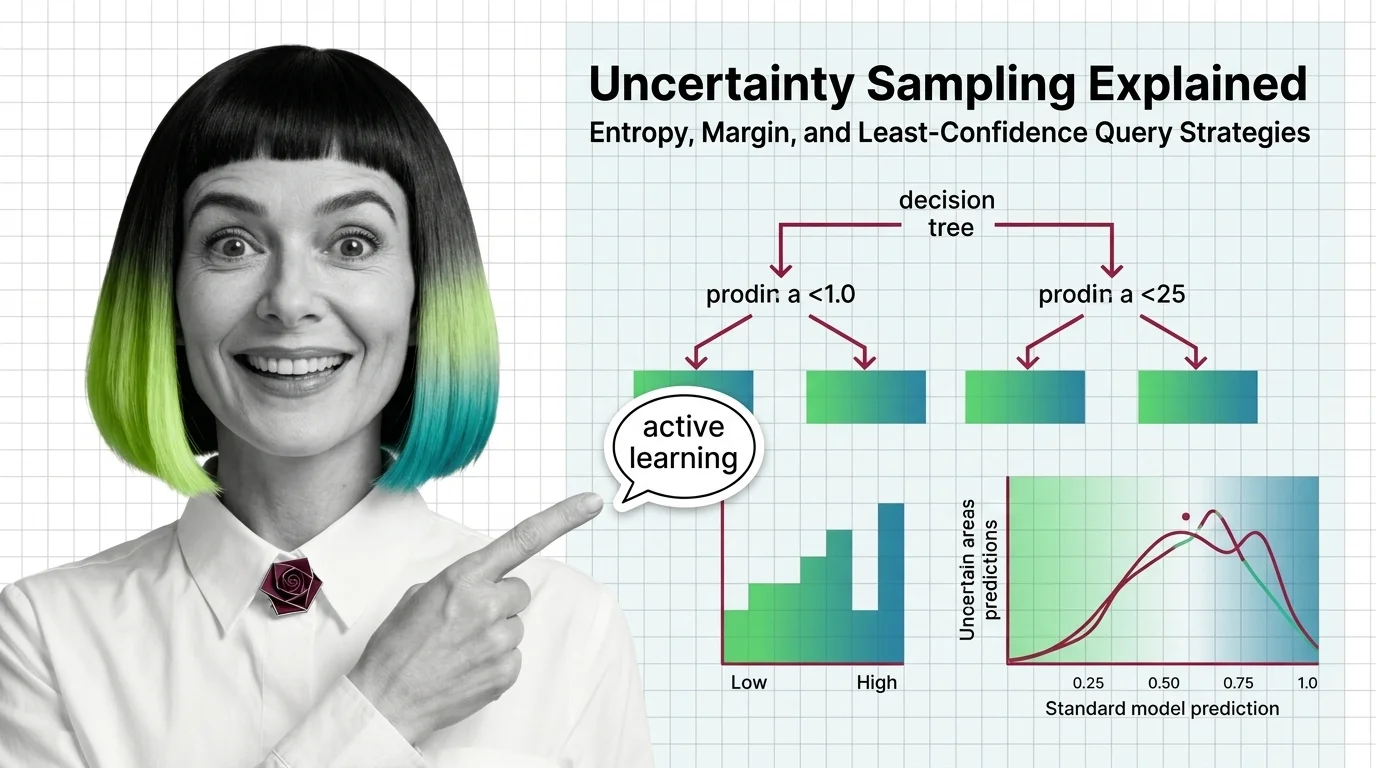
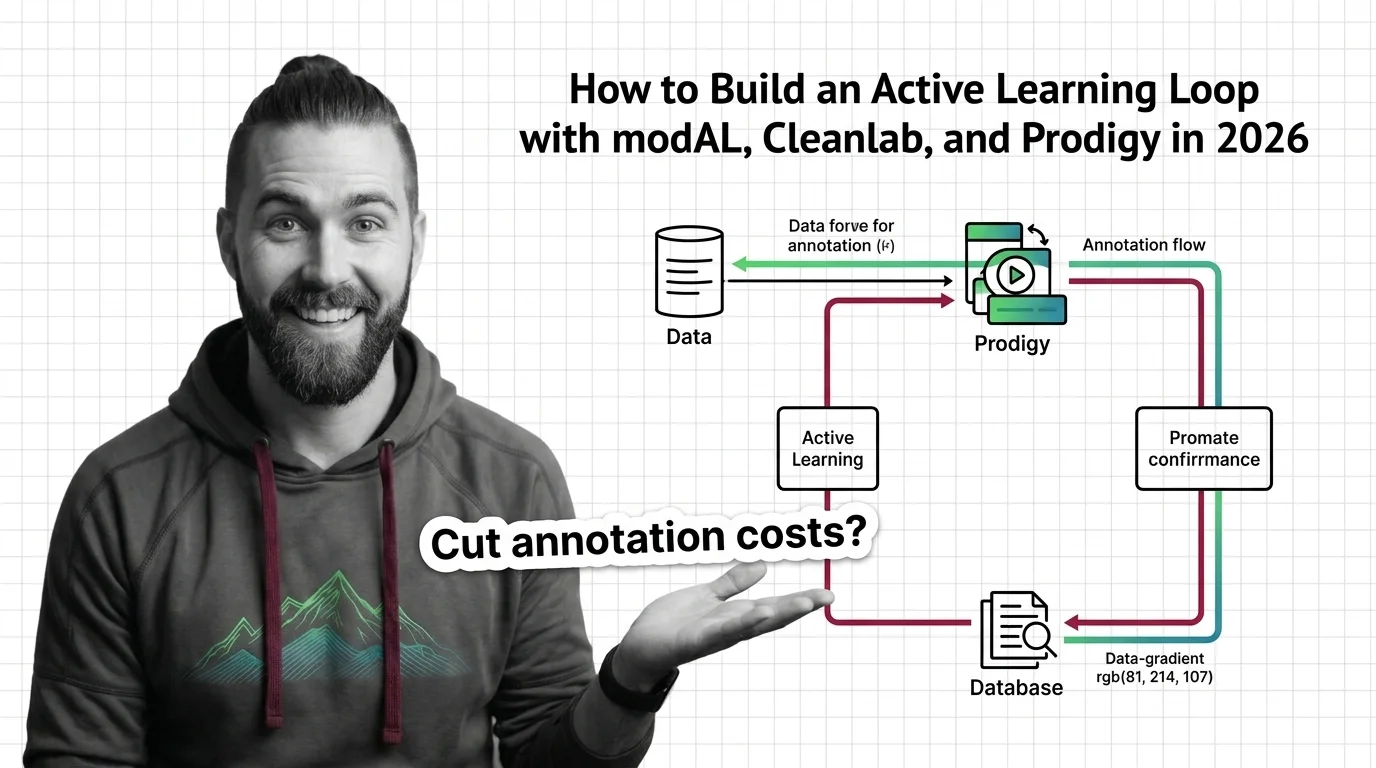
Uncertainty sampling is an active-learning strategy that labels the data a model is least confident about — via entropy, margin, or least-confidence scores.
Active learning lets a model query only the most informative unlabeled samples to label, hitting target accuracy with far fewer labels than random sampling.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
scikit-learn pipelines stop data leakage by fitting transformers on training data only. ColumnTransformer routes numeric and categorical columns separately.
Deduplicating a training corpus with MinHash LSH and semantic embeddings cuts memorized-text emission roughly 10x. A tool-by-scale spec guide for 2026.
Data-prep tooling consolidates on Apache Arrow in 2026: pandas 3.0, Polars, and RAPIDS cuDF interoperate zero-copy. Leakage-safe pipelines are now default.
Data augmentation is splitting in 2026: vision keeps mixup and CutMix, text shifts to LLM synthetic data. Model collapse caps how far synthetic can go.
Meta's ~$14.3B stake in Scale AI split the data-labeling market: rivals like Surge, Mercor, and Snorkel absorbed the customer exodus heading into 2026.
Training data bias gets amplified by models, not just reflected. The EU AI Act mandates documented data provenance and bias mitigation from August 2026.
Data labeling depends on workers earning roughly $1.32–$2/hour to filter traumatic content, while annotator bias quietly shapes what AI treats as truth.
Active learning lets models choose which data humans label. Whether it amplifies or curbs dataset bias depends on the query strategy and the source of bias.