Model Collapse, Fidelity Gaps, and Re-Identification: The Technical Limits of Synthetic Data
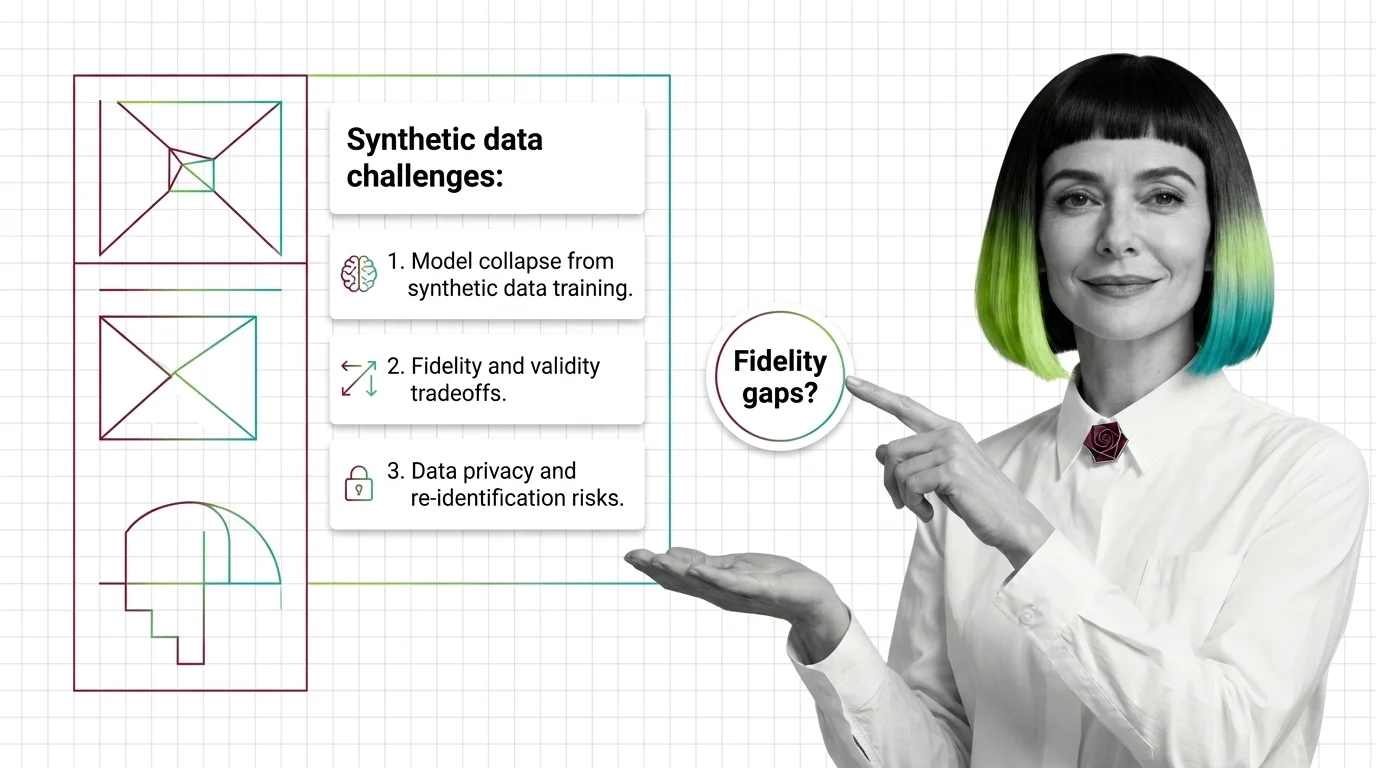
Synthetic data faces three hard limits: model collapse from recursive training, fidelity-privacy tradeoffs, and re-identification of outlier records.
Creating artificial training data with generative models, including benchmark datasets and the ethics of treating synthetic data as a privacy workaround.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Benchmark datasets are standardized collections of tasks used to measure and compare how well AI models perform — from …
Synthetic data ethics is the study of the moral risks that arise when AI-generated data stands in for real records. Even …
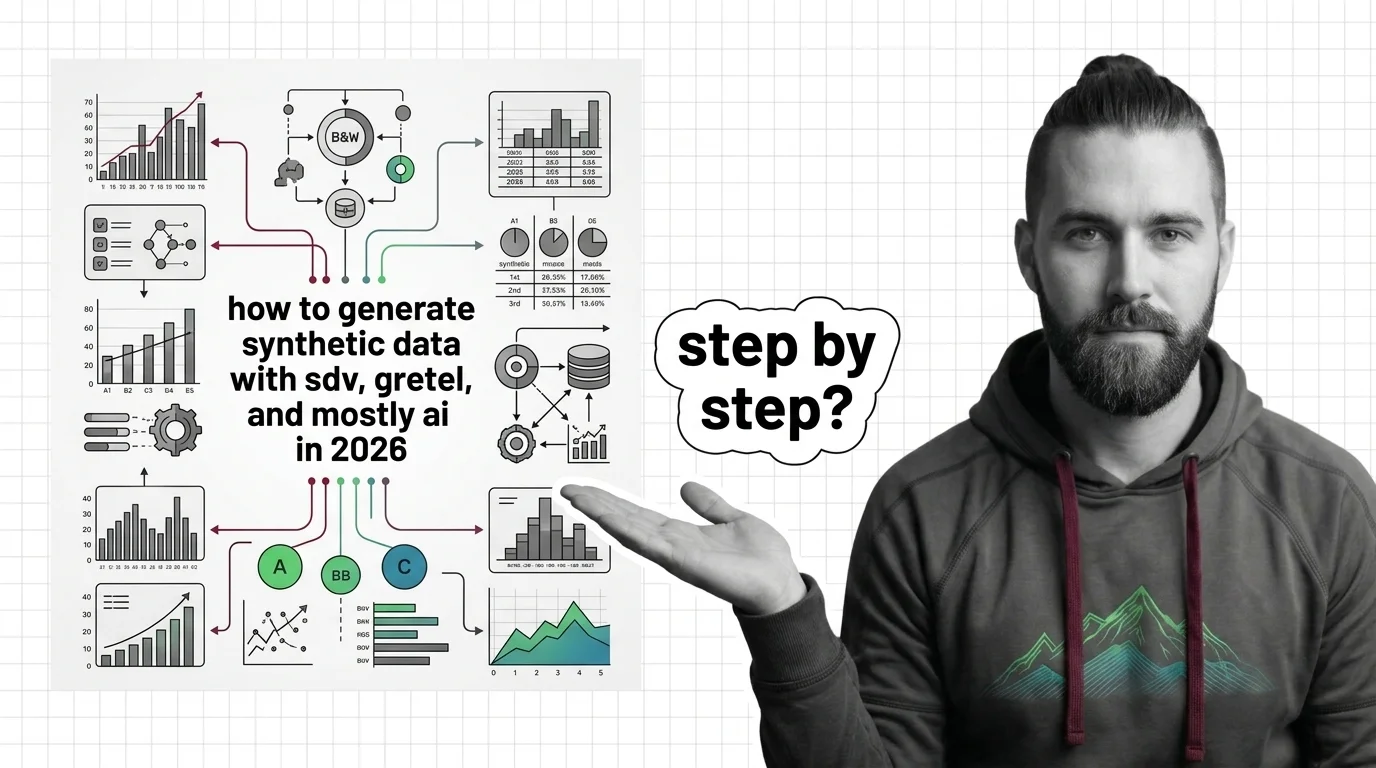
Synthetic data generation creates artificial training data—either with hand-written rules or with generative …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Jun 19, 2026
Concepts covered
Synthetic data faces three hard limits: model collapse from recursive training, fidelity-privacy tradeoffs, and re-identification of outlier records.
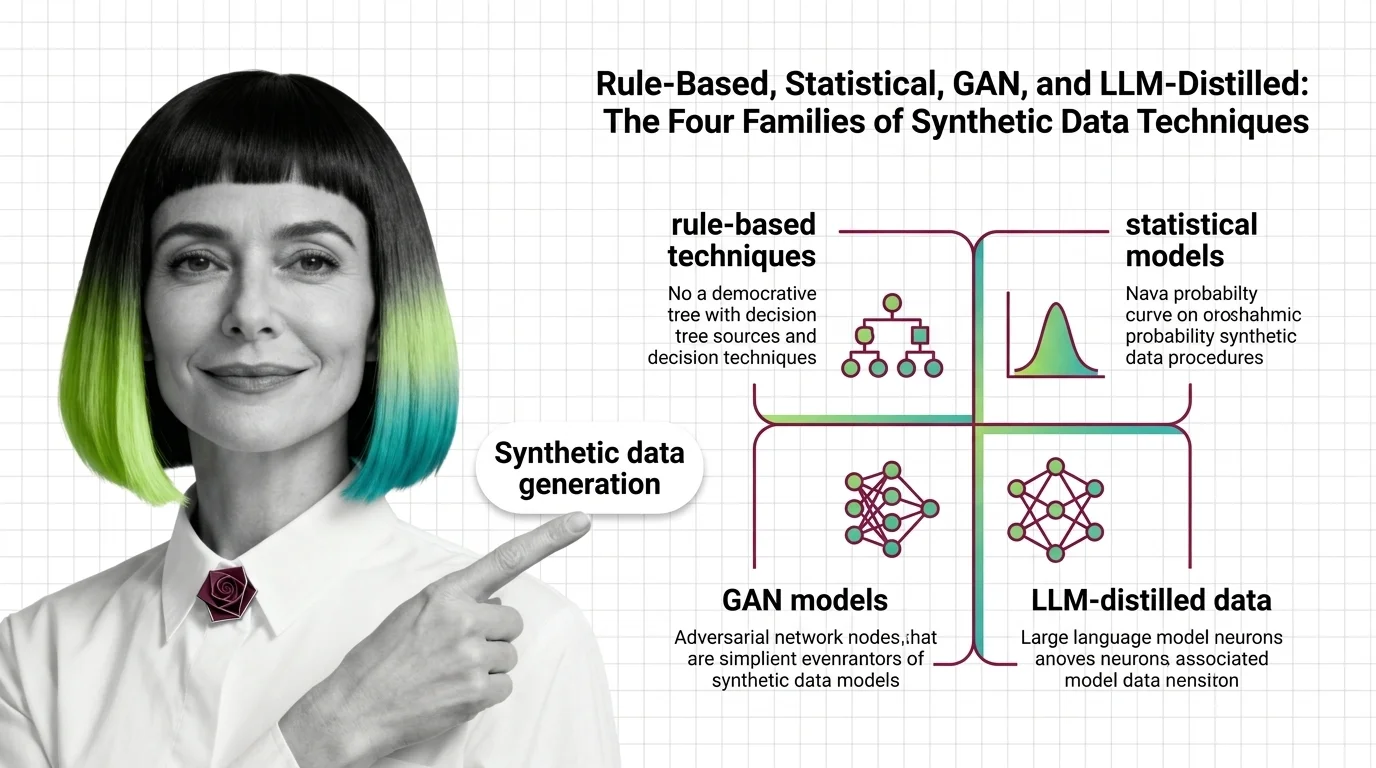
Synthetic data generation spans four families — rule-based, statistical, GAN-based, and LLM-distilled — each preserving a different depth of structure.
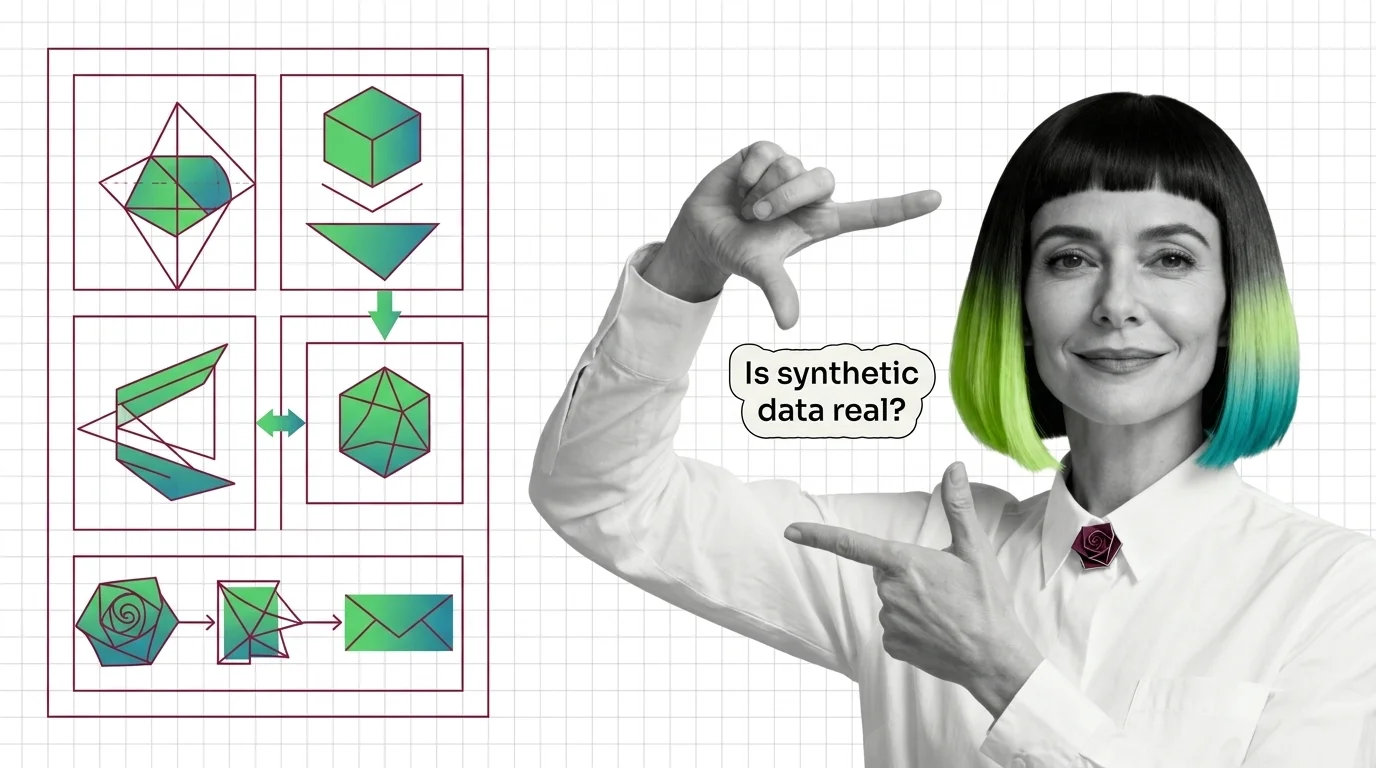
Synthetic data generation creates artificial records that mimic a dataset's statistics without reusing real rows, via GANs, VAEs, and diffusion models.

AI benchmark scores hide three variables: what the metric counts, the pass@k sampling regime, and whether the test leaked into the training data.

AI benchmarks fail through saturation, contamination, and construct validity. Decontamination cut HumanEval scores nearly 40% — the gap was pure leakage.
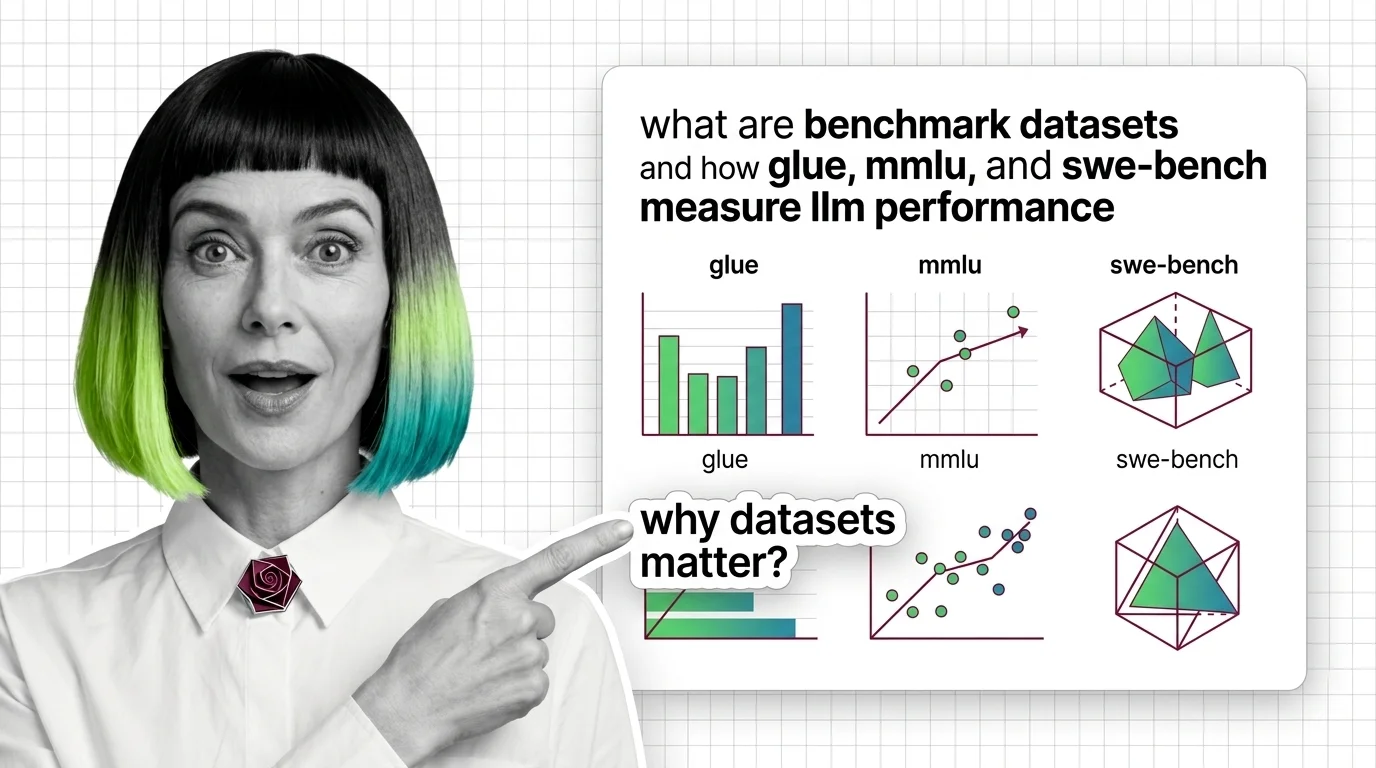
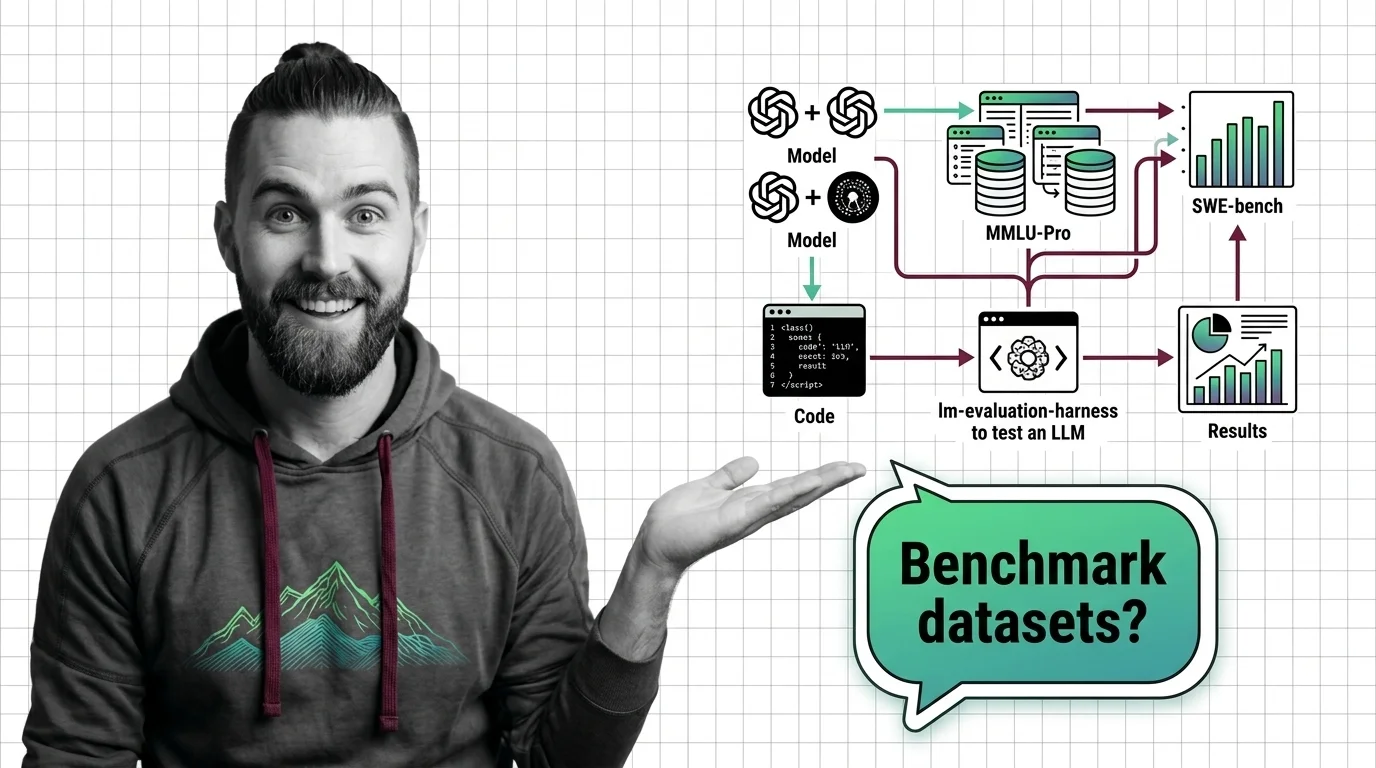
Benchmark datasets are fixed test sets that score and rank LLMs. MMLU's 15,908 questions and SWE-bench's 2,294 GitHub tasks show two scoring styles.