Beyond Transformers for Developers: What Maps and What Breaks
A bridge for developers hitting MoE, state space, and multimodal anomalies in 2026. Which software instincts still work, and which predict the wrong failures.
Emerging architecture alternatives to transformers for processing long sequences efficiently, including state-space models and mixture-of-experts.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
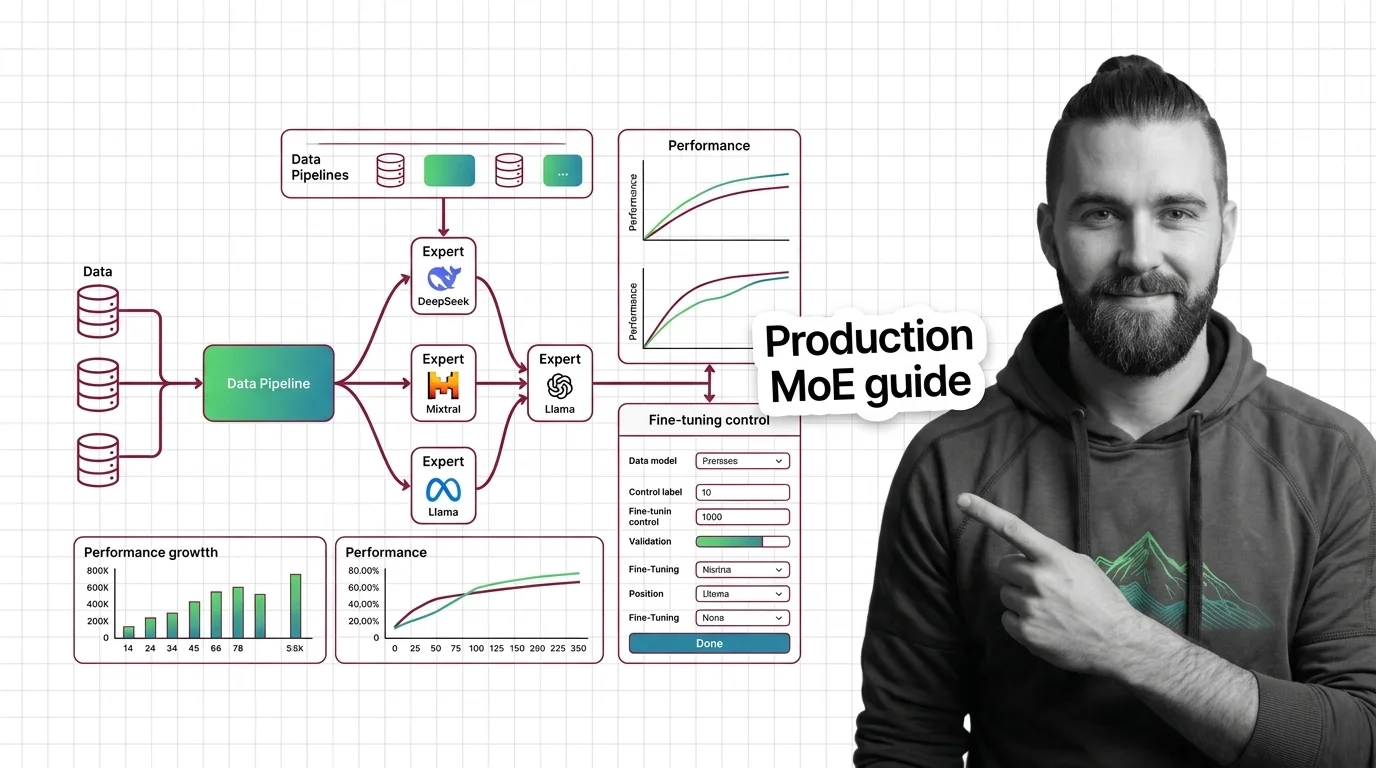
Mixture of Experts is a neural network architecture that splits computation across multiple specialized sub-networks …
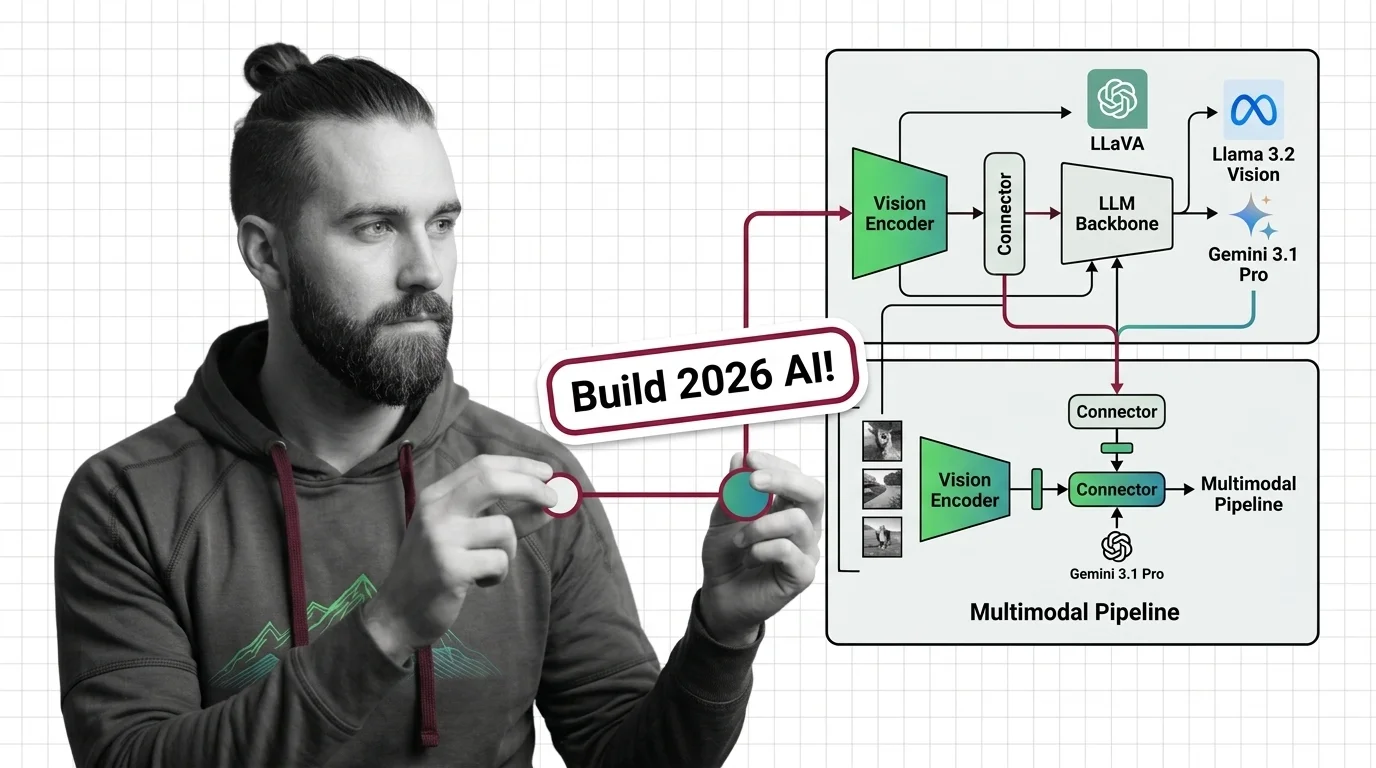
Multimodal architecture describes AI model designs that process and generate across multiple data types at once — text, …
A State Space Model is a neural network architecture that processes sequences by maintaining a compressed hidden state …
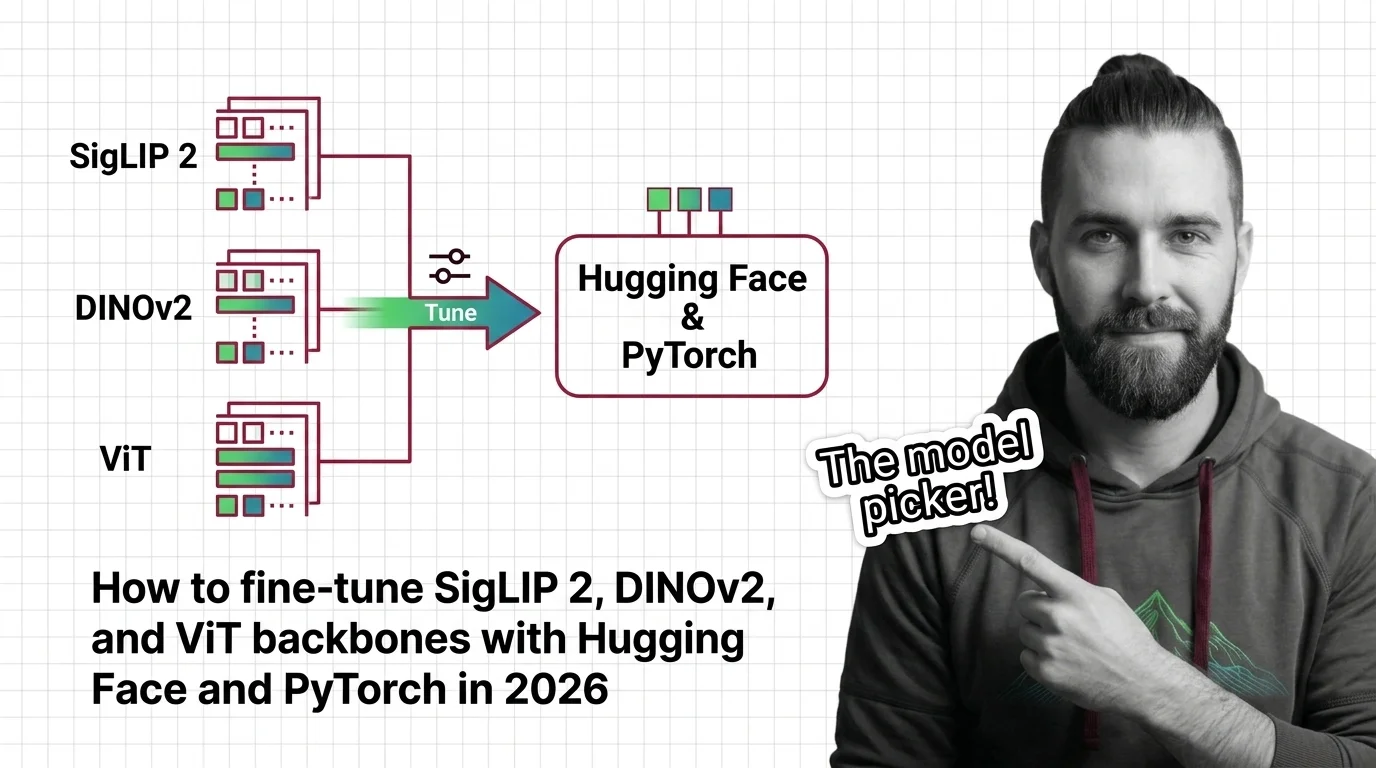
A vision transformer is a deep learning architecture that applies the transformer model, originally designed for text, …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Apr 21, 2026
Concepts covered
A bridge for developers hitting MoE, state space, and multimodal anomalies in 2026. Which software instincts still work, and which predict the wrong failures.
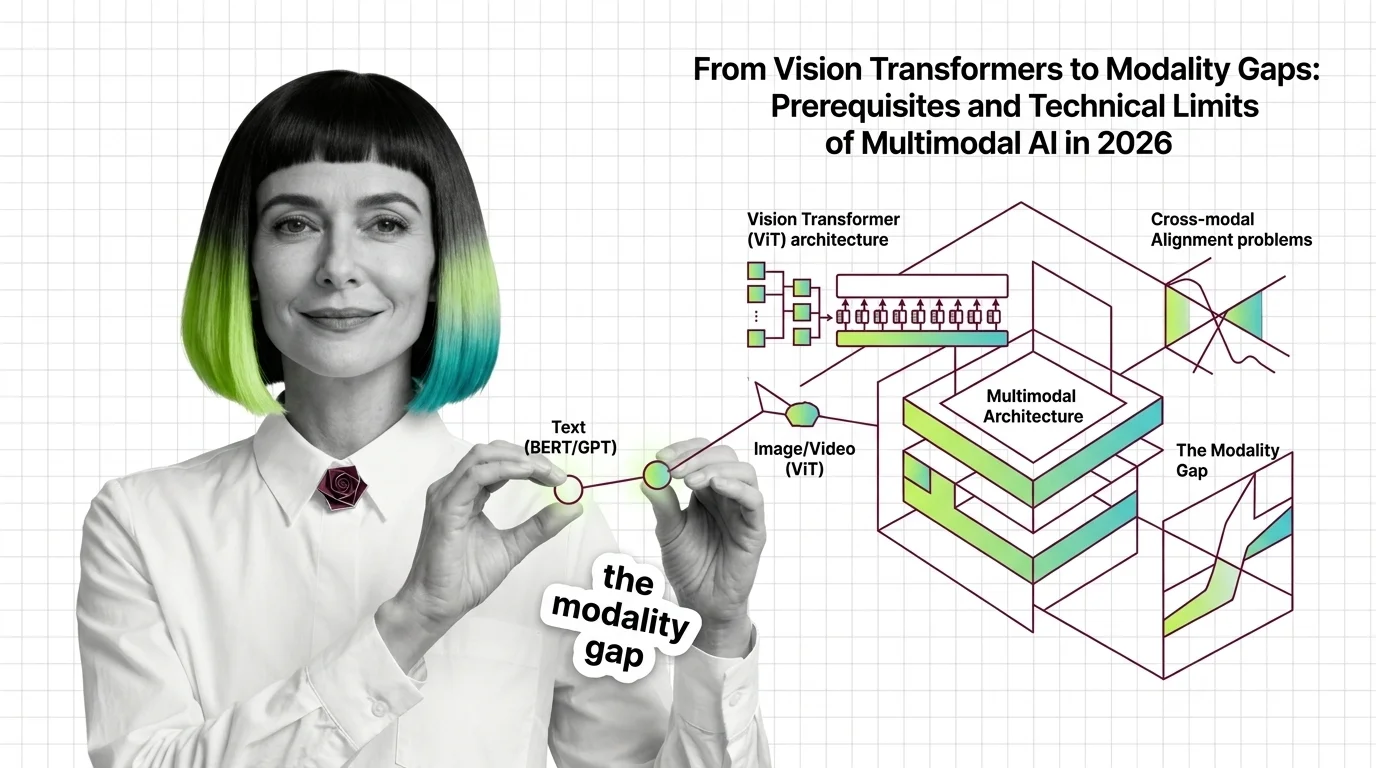
Before multimodal AI works, vision transformers, modality gaps, and grounding decay define its limits. The mechanics of why 2026 models still hallucinate.
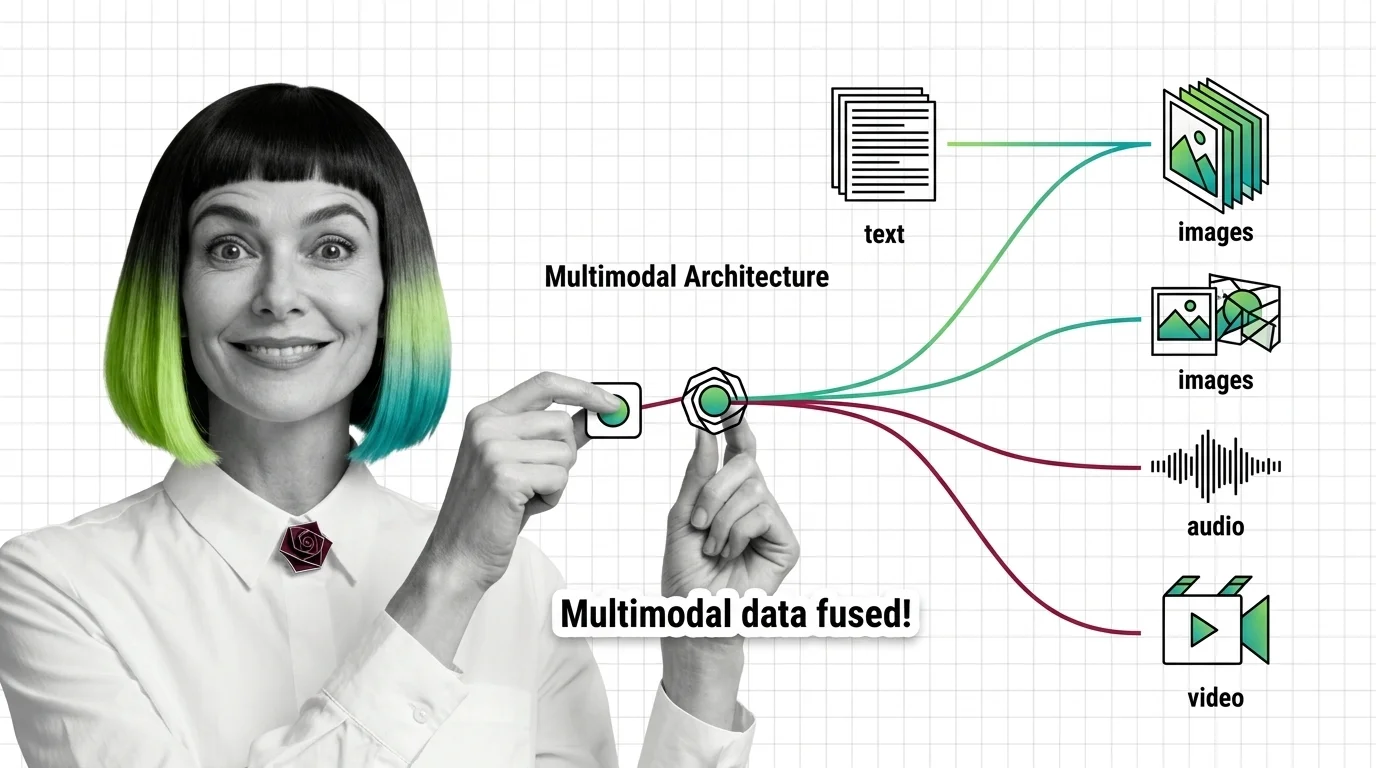
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the encoder-connector-backbone trick.
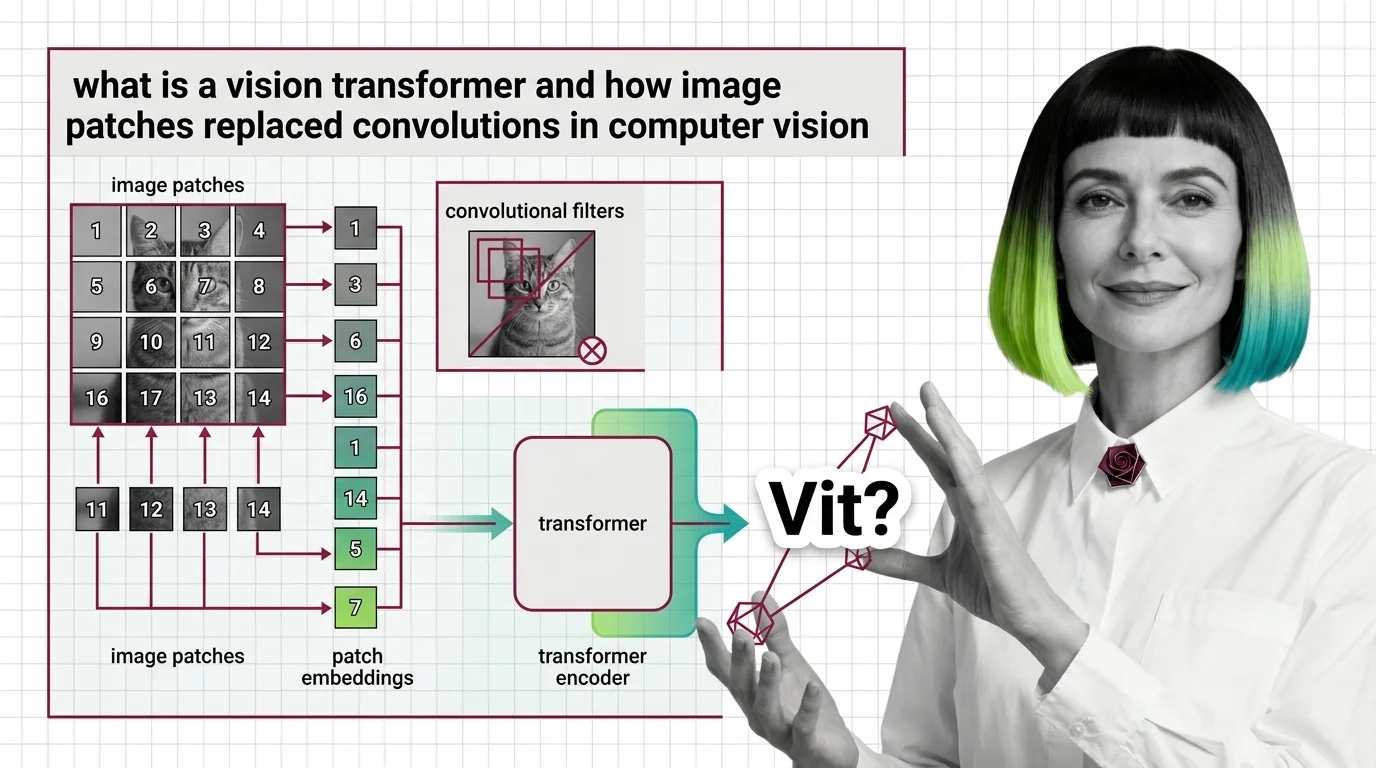
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and position embeddings replaced convolution.
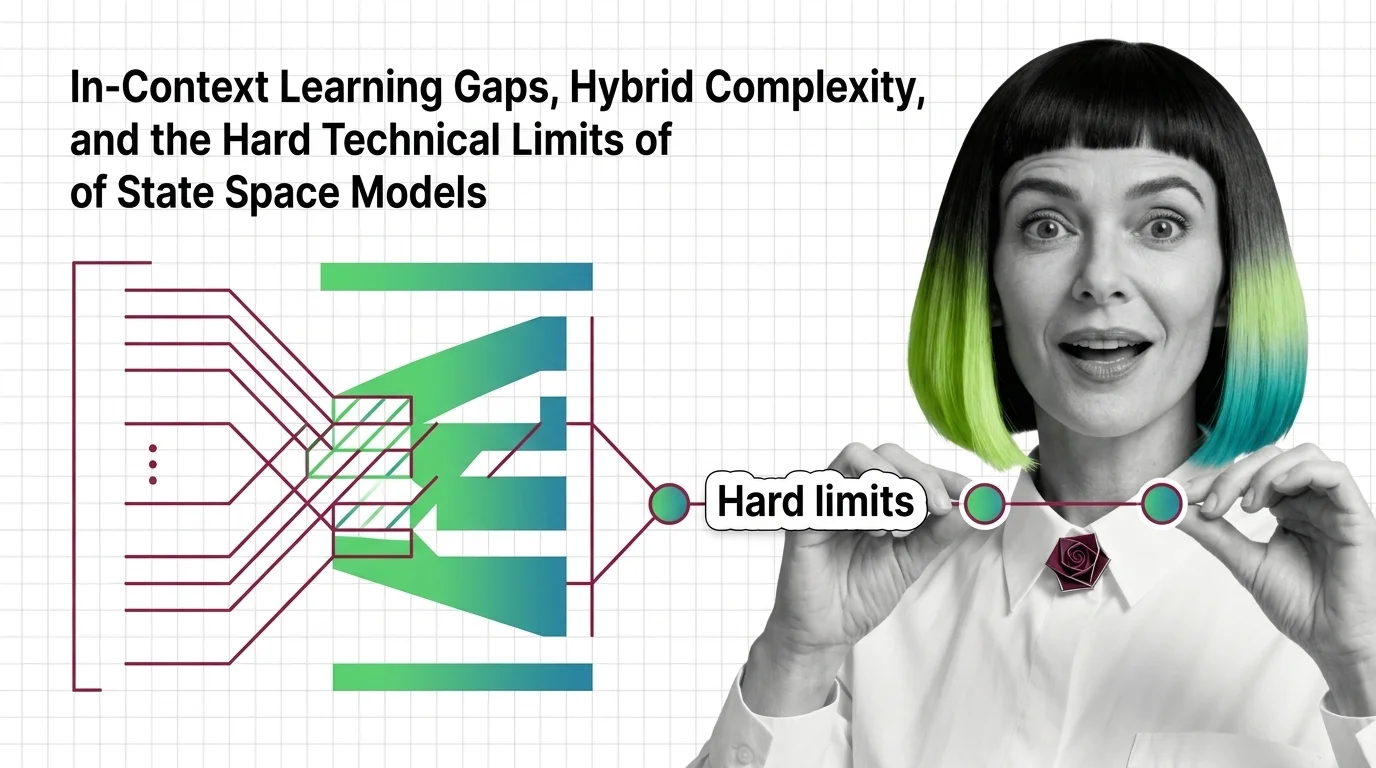
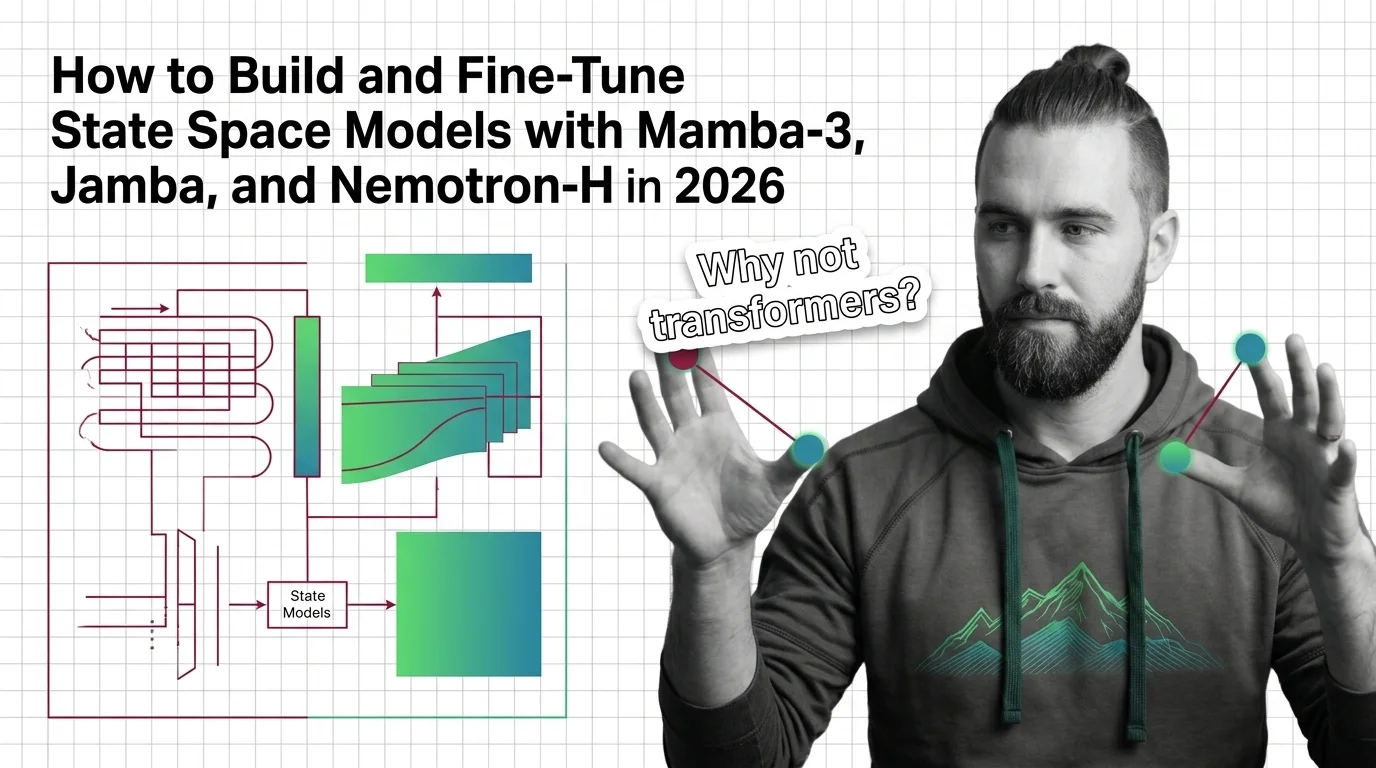
State space models trade recall for speed. Learn why pure Mamba breaks on in-context tasks and how hybrid SSM-attention models pay the compression bill.
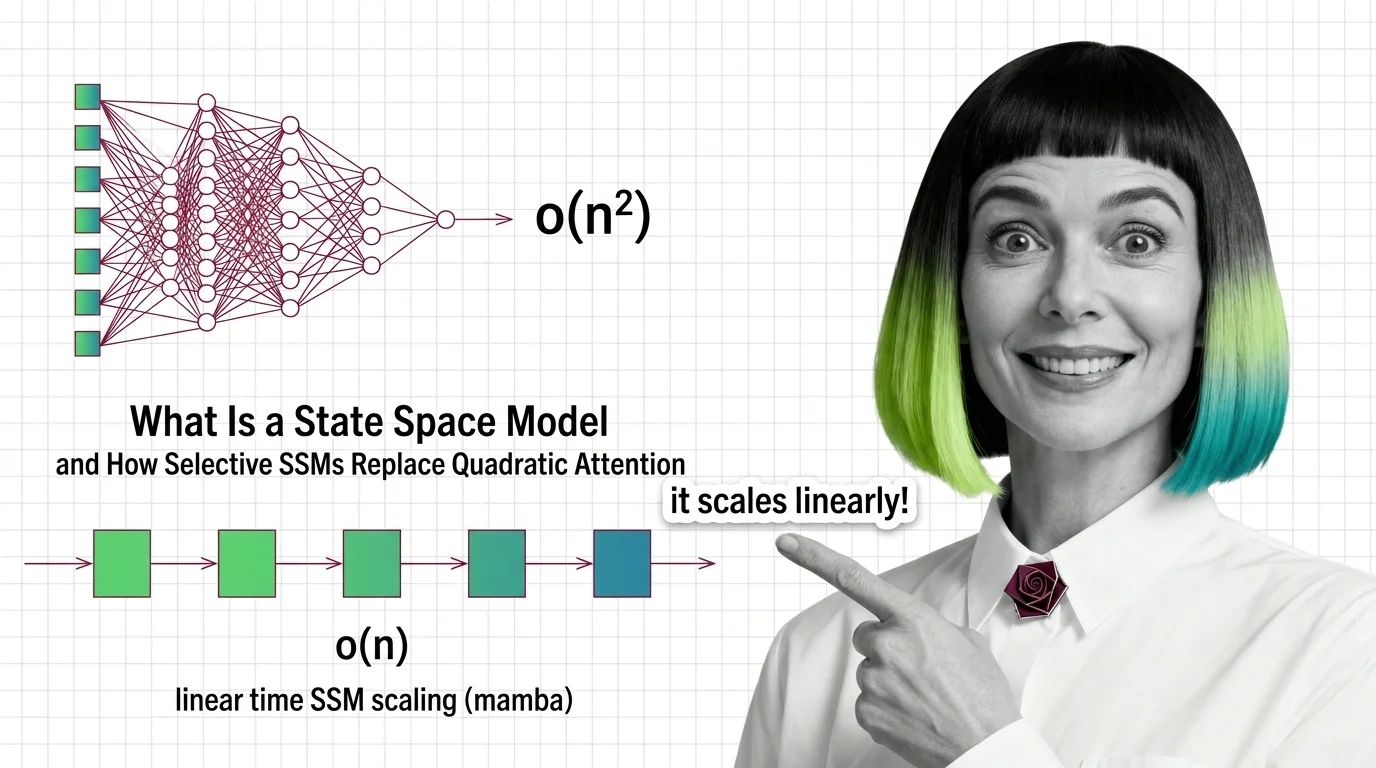
State space models trade quadratic attention for linear recurrence. See how Mamba's selection works and why long-context models run hybrid in 2026.
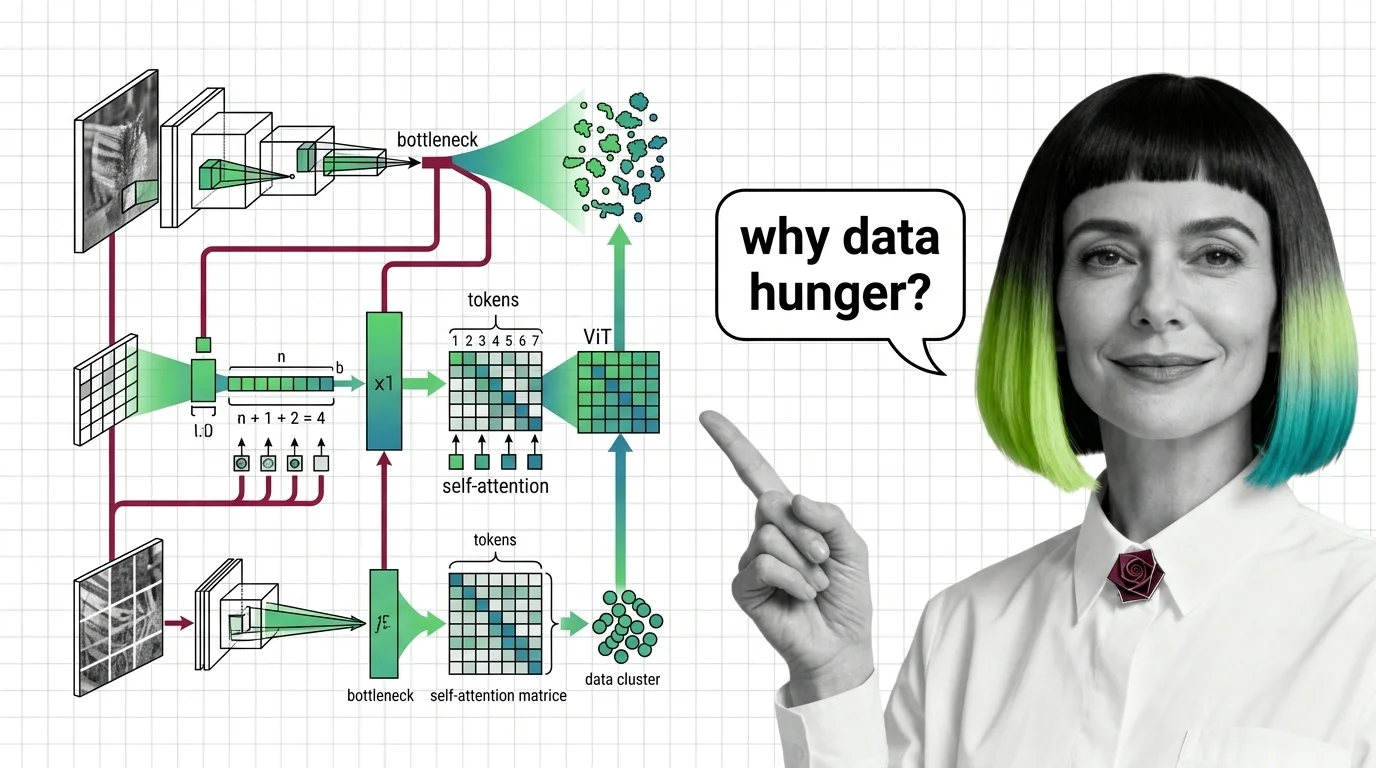
Vision Transformers drop CNN priors for learned attention — a trade that changes everything. Learn the prerequisites, CNN mappings, and hard limits of ViT.
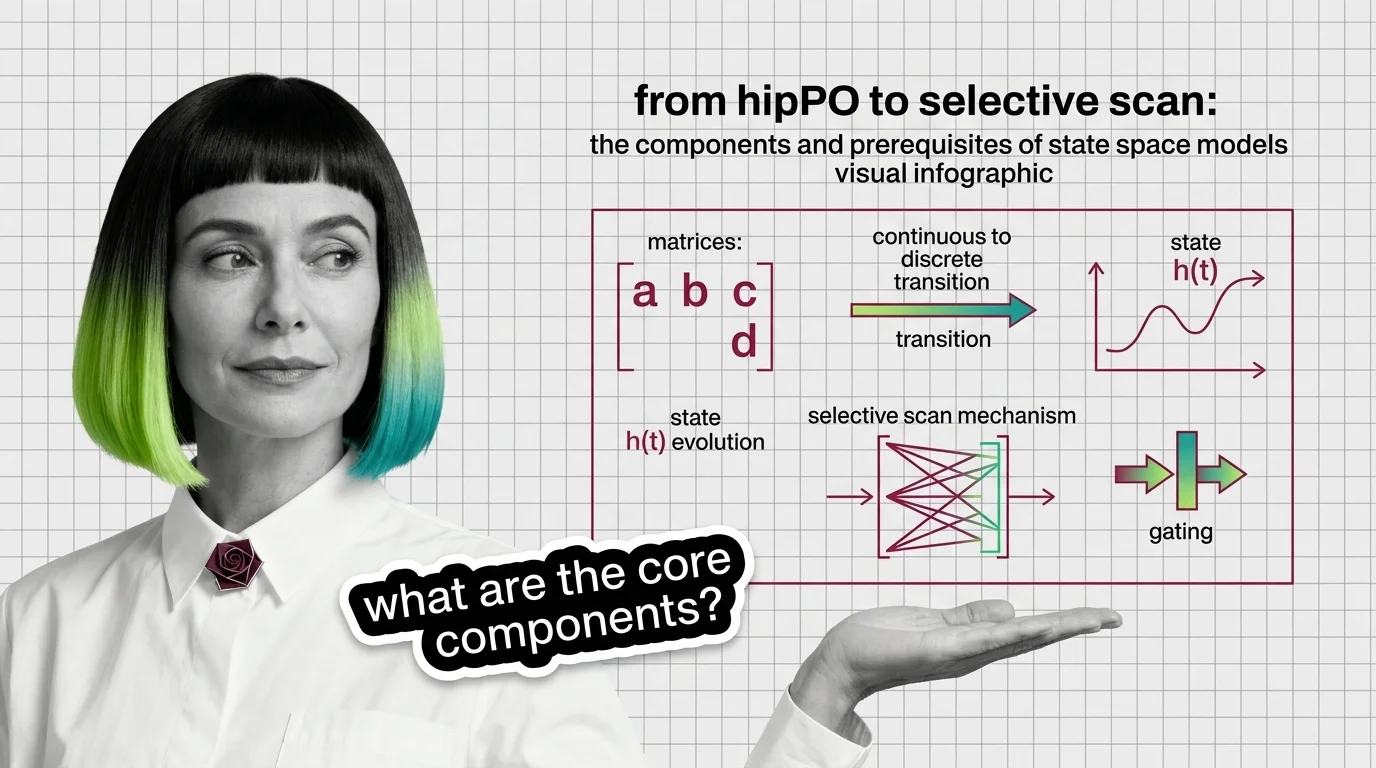
State space models rebuilt recurrence on new math. Trace the components — HiPPO, S4, selective scan, gating — and the prerequisites that make SSMs click.
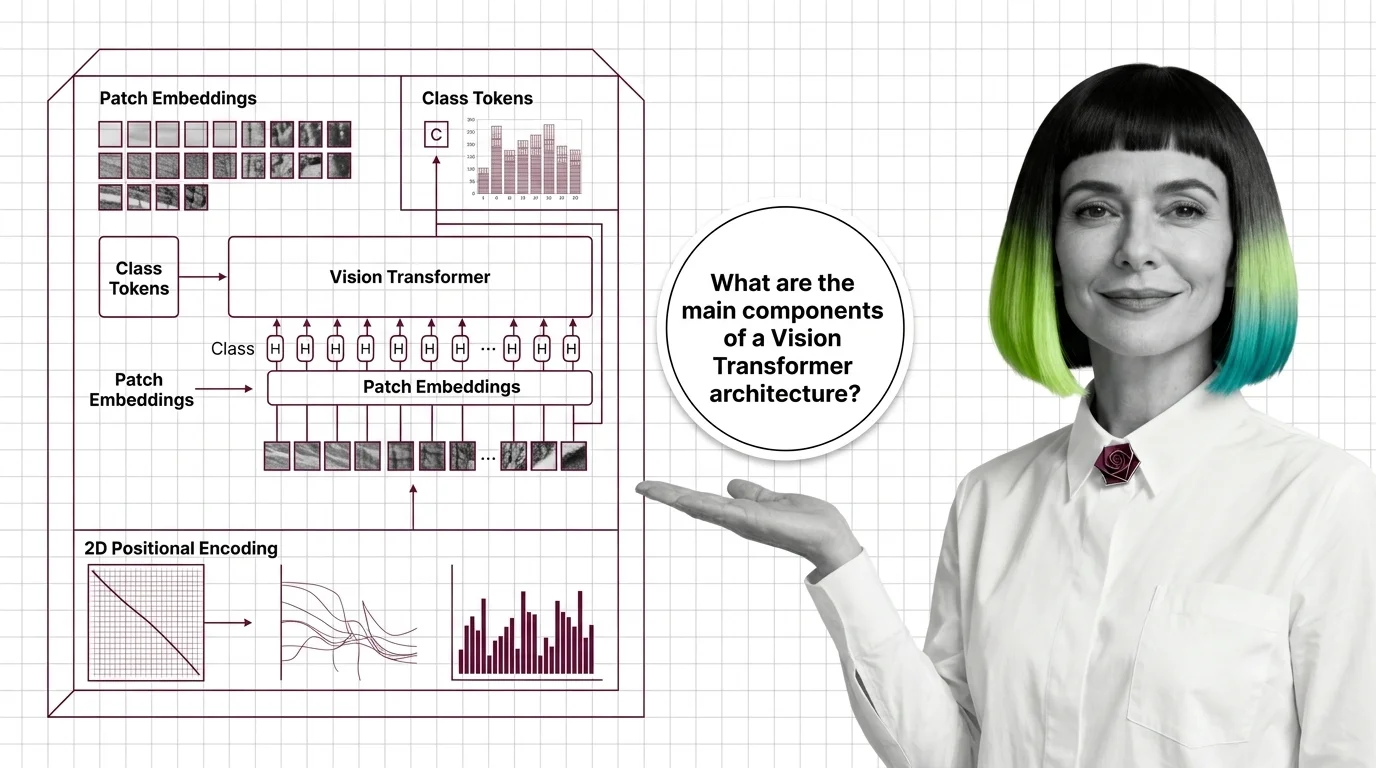
How Vision Transformers turn images into token sequences — inside patch embeddings, the CLS token, and the shift from 1D to modern 2D positional encoding.

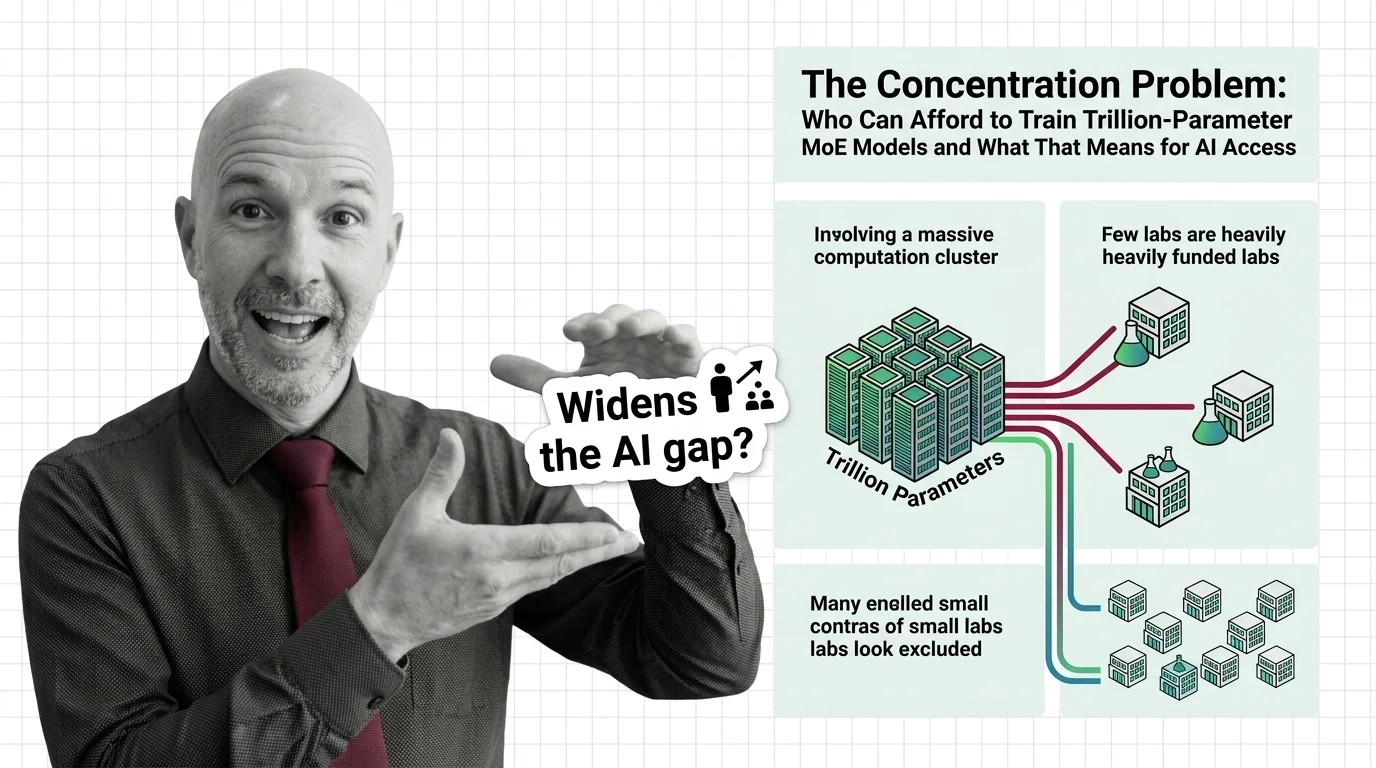
MoE models promise scale at fractional compute cost. Understand routing collapse, memory tradeoffs, and communication overhead — the hard engineering limits.
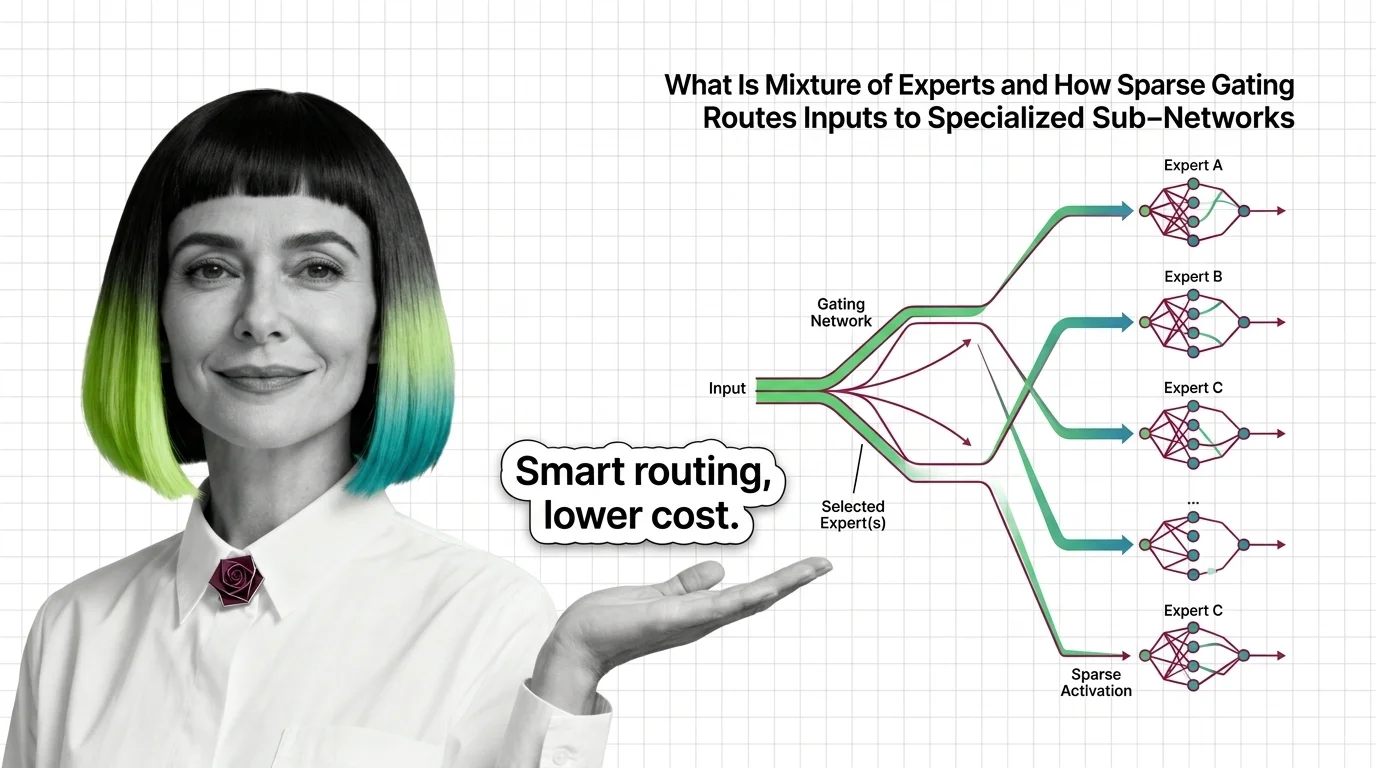
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter models practical and efficient.
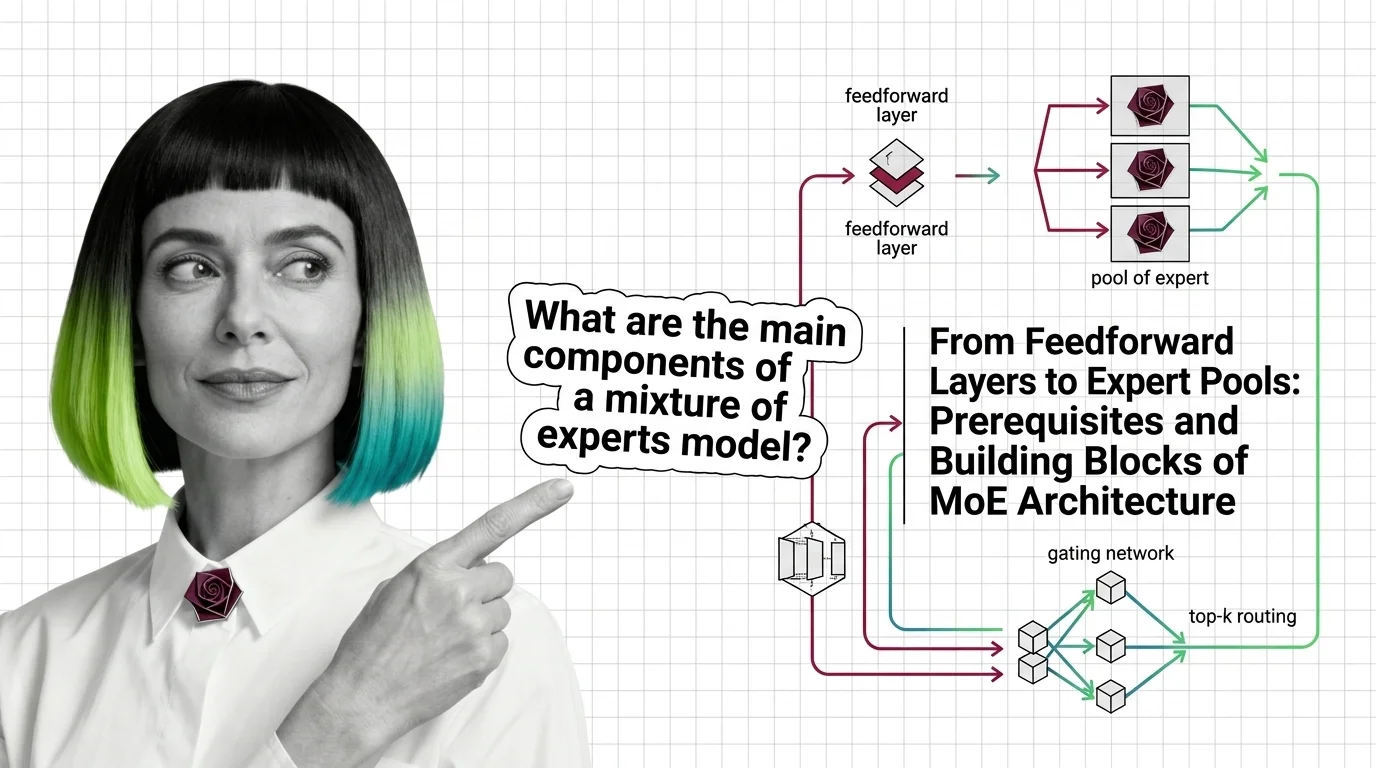
Mixture of experts replaces one feedforward layer with many expert networks and a router. Learn how MoE gating and routing enable trillion-parameter models.