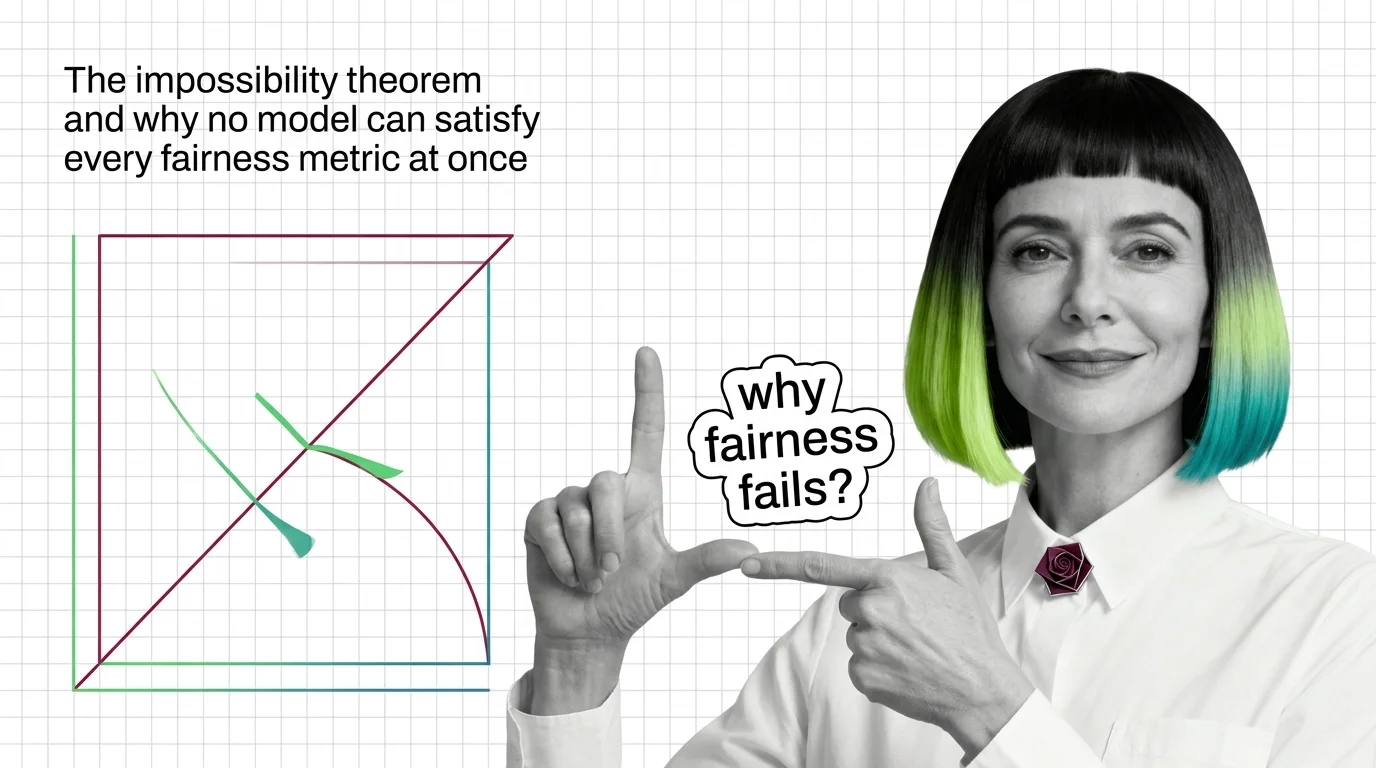
The Impossibility Theorem and Why No Model Can Satisfy Every Fairness Metric at Once
When group base rates differ, no algorithm satisfies calibration, equal error rates, and demographic parity at once. Learn the math behind fairness trade-offs.
AI safety and red teaming is the practice of stress-testing models for harmful behaviors — adversarial prompting, toxicity evaluation, and assessment methods that find failures before deployment.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
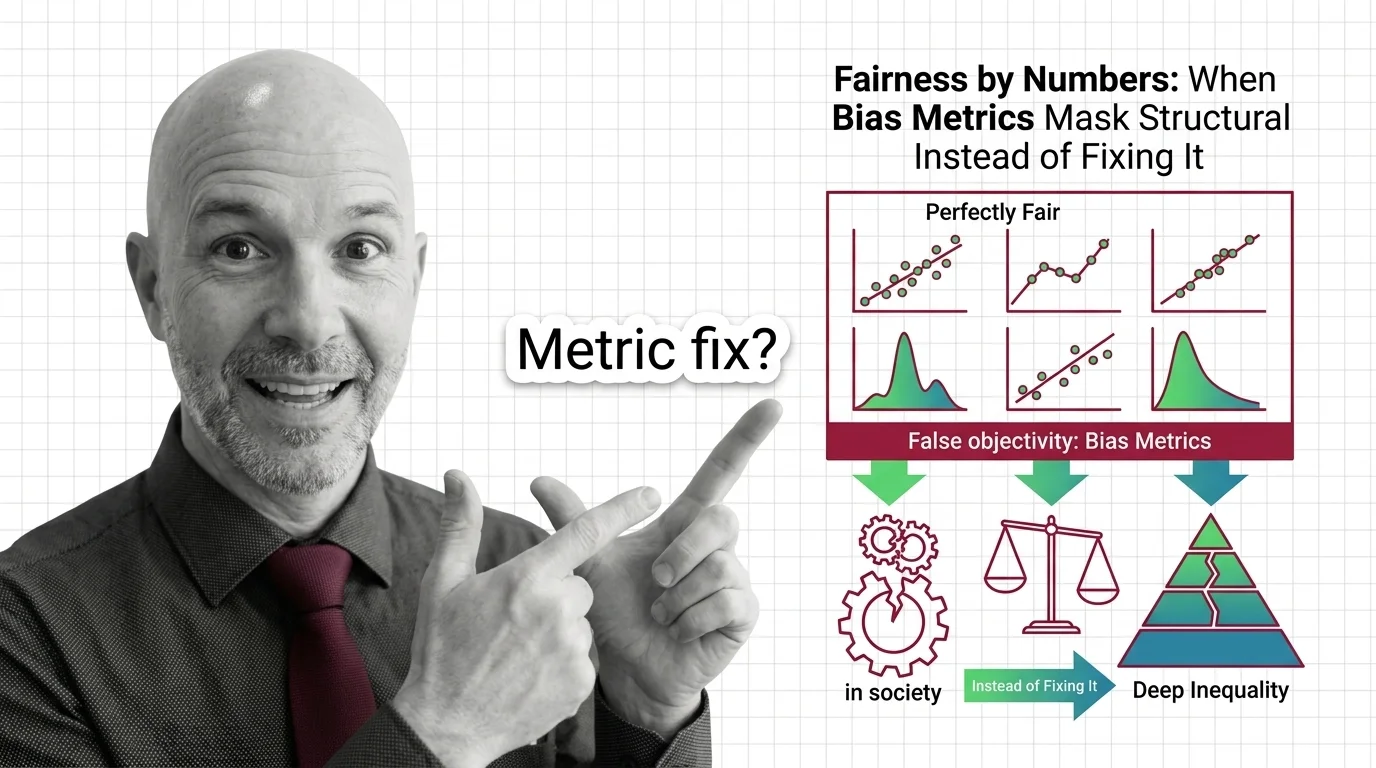
Bias and fairness metrics are quantitative measures used to detect, quantify, and report systematic disparities in …
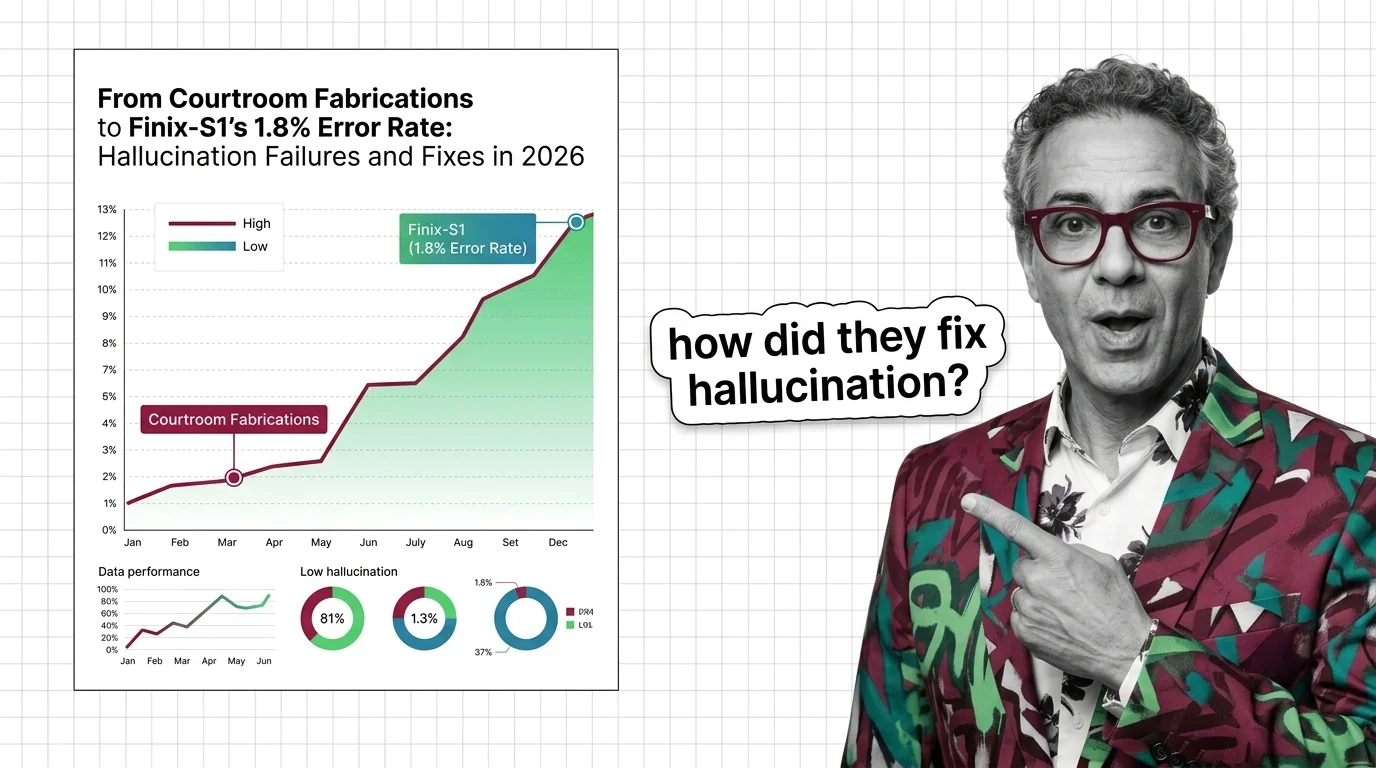
Hallucination is what happens when a large language model generates text that sounds confident and coherent but is …
Red teaming for AI is adversarial testing where humans or automated systems deliberately probe an AI model to find …
Toxicity and safety evaluation encompasses the metrics, datasets, and frameworks used to measure whether AI systems …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Mar 28, 2026
Concepts covered
When group base rates differ, no algorithm satisfies calibration, equal error rates, and demographic parity at once. Learn the math behind fairness trade-offs.
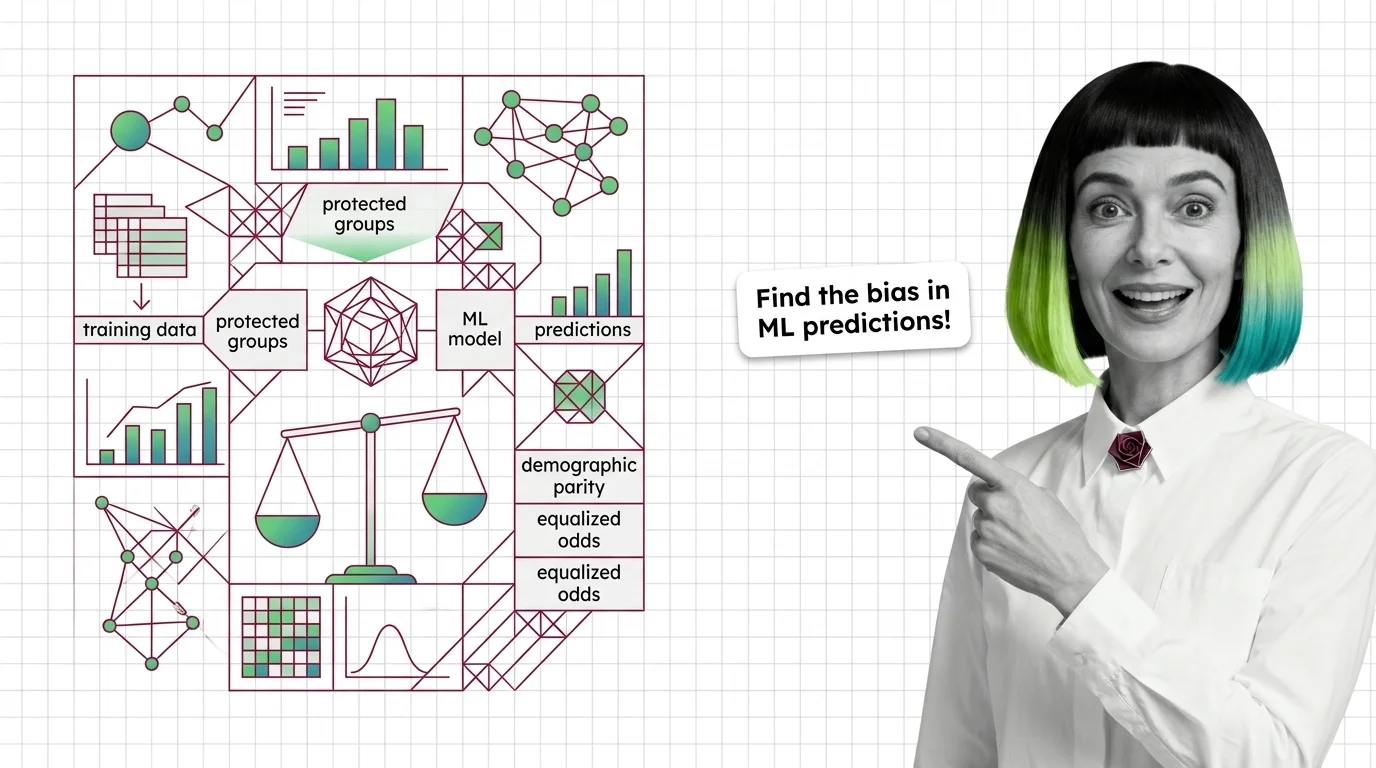
Fairness metrics test whether ML models discriminate by group. Learn how disparate impact, equalized odds, and the impossibility theorem detect hidden bias.

HarmBench, ToxiGen, and MLCommons AILuminate define how AI safety is measured. Learn the datasets, classifiers, and taxonomies behind modern toxicity evaluation.
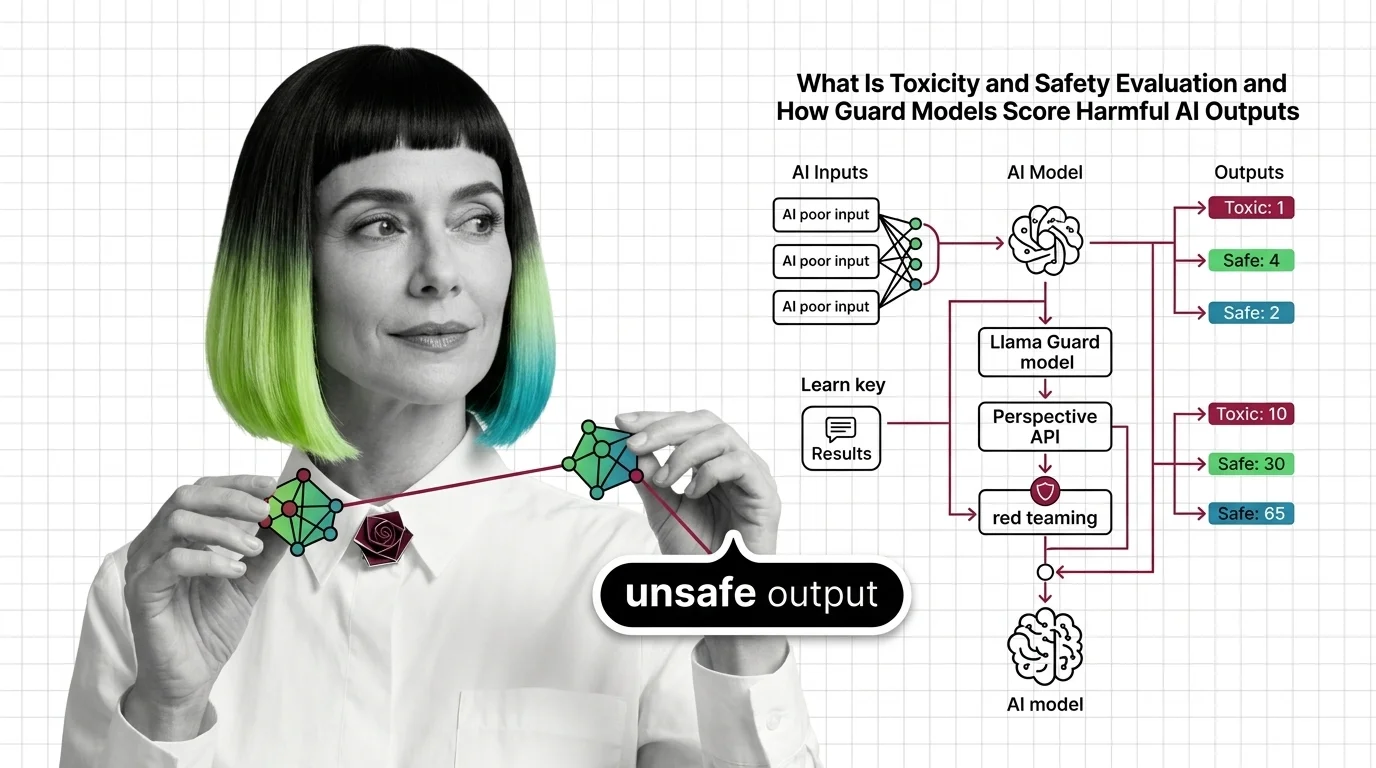
Toxicity and safety evaluation scores AI outputs for harm using classifiers and red teaming. Learn how guard models detect toxic content and where they fail.
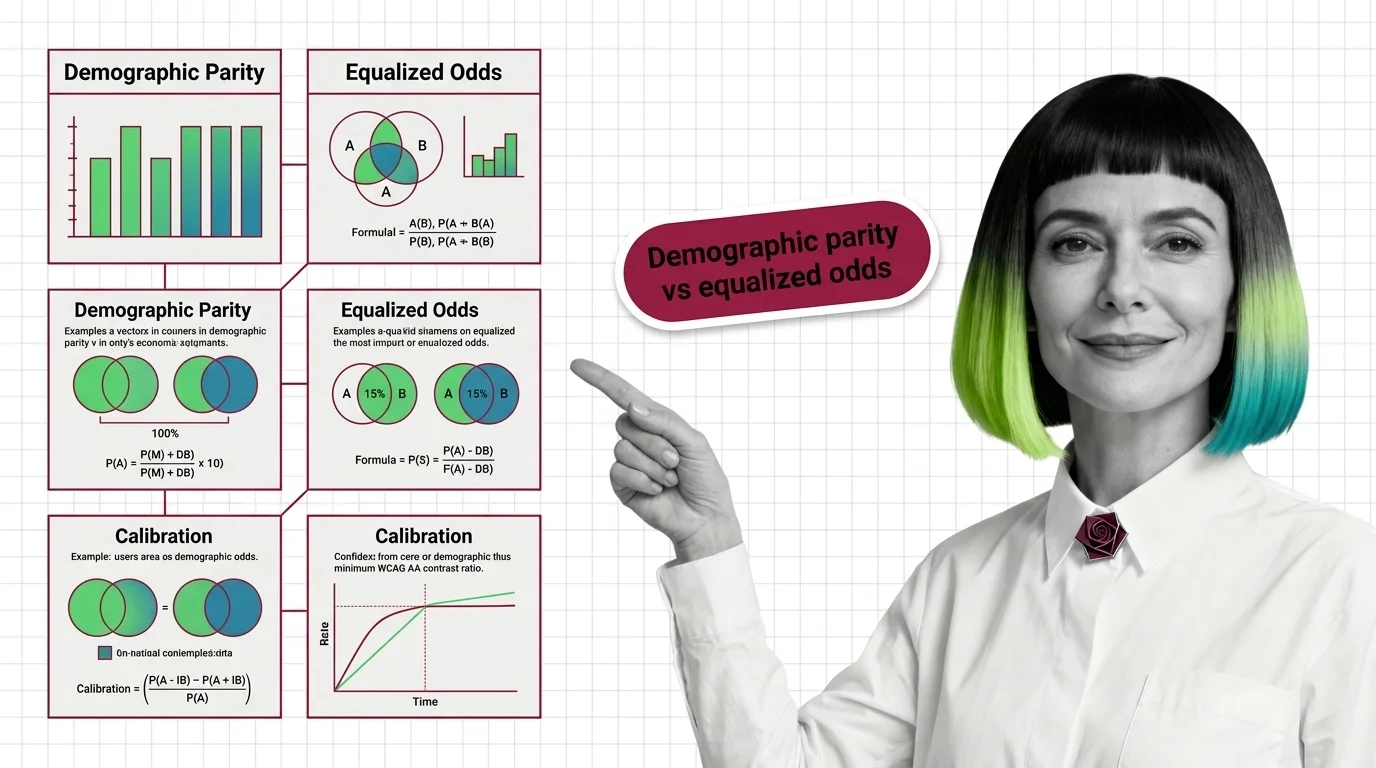
Demographic parity, equalized odds, and calibration define fairness differently and cannot all be satisfied at once. Learn what that trade-off means.
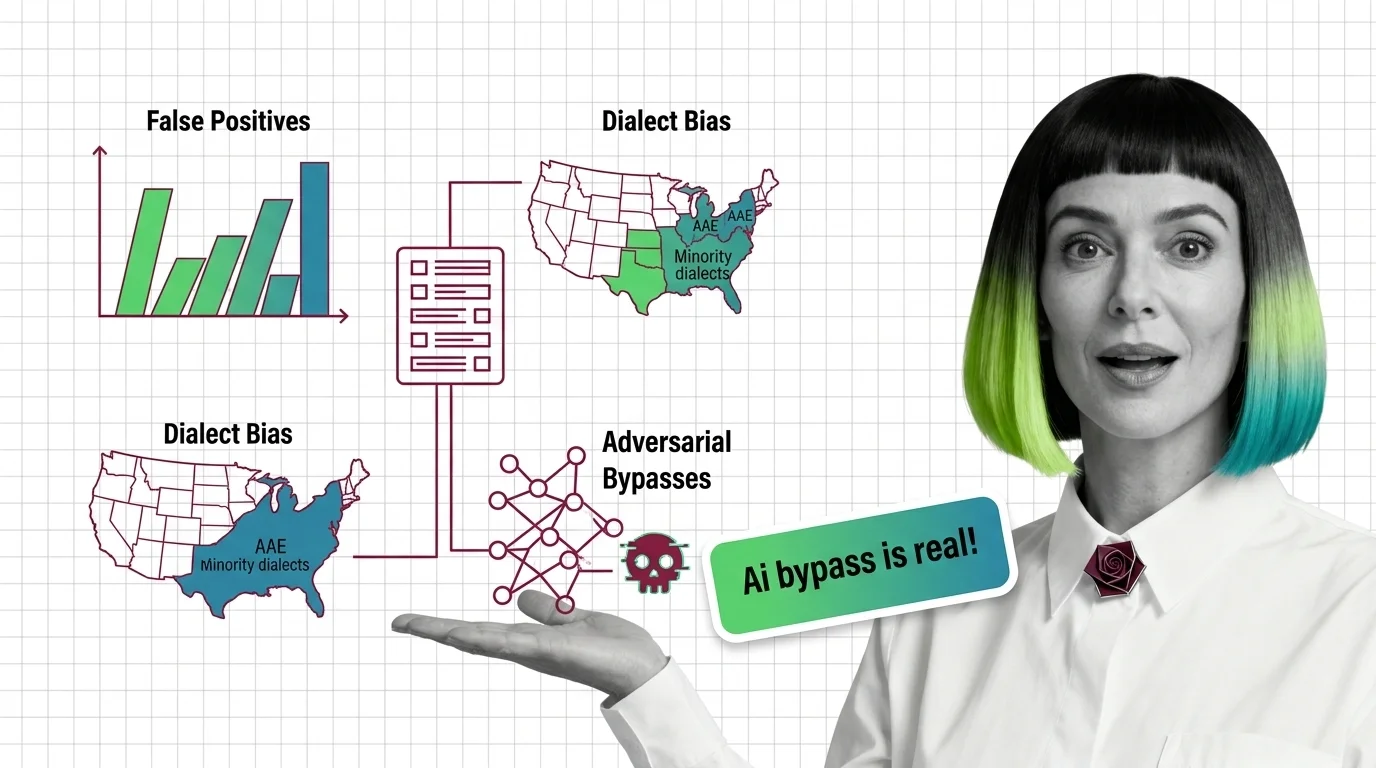
Toxicity classifiers over-flag minority dialects and miss adversarial attacks. Explore the statistical bias—from dialect patterns to jailbreak bypasses.

OWASP LLM Top 10 and MITRE ATLAS give red teams structured attack categories. Learn how these frameworks turn AI security testing from guesswork into coverage.
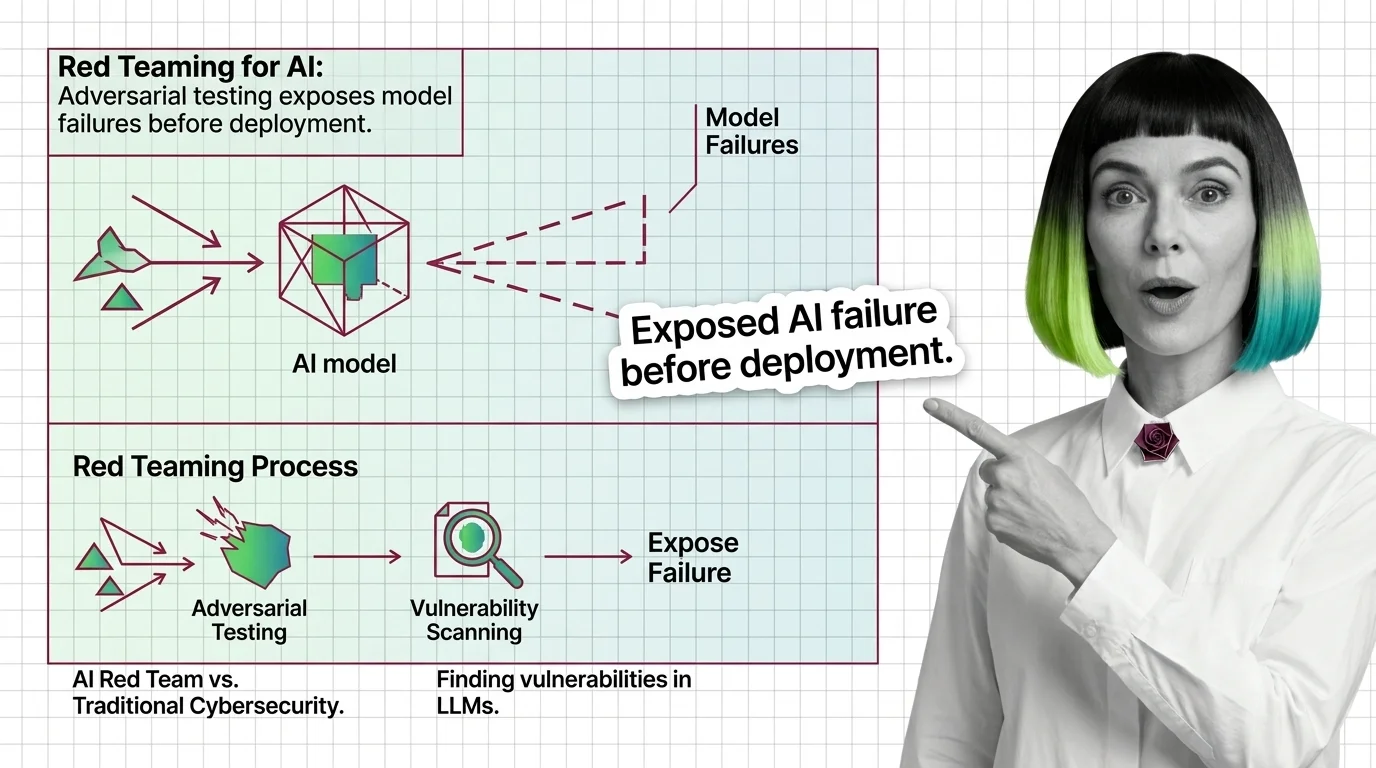
Red teaming uses adversarial testing to reveal AI vulnerabilities. Discover what it catches, mechanics, and why it outperforms traditional security approaches.
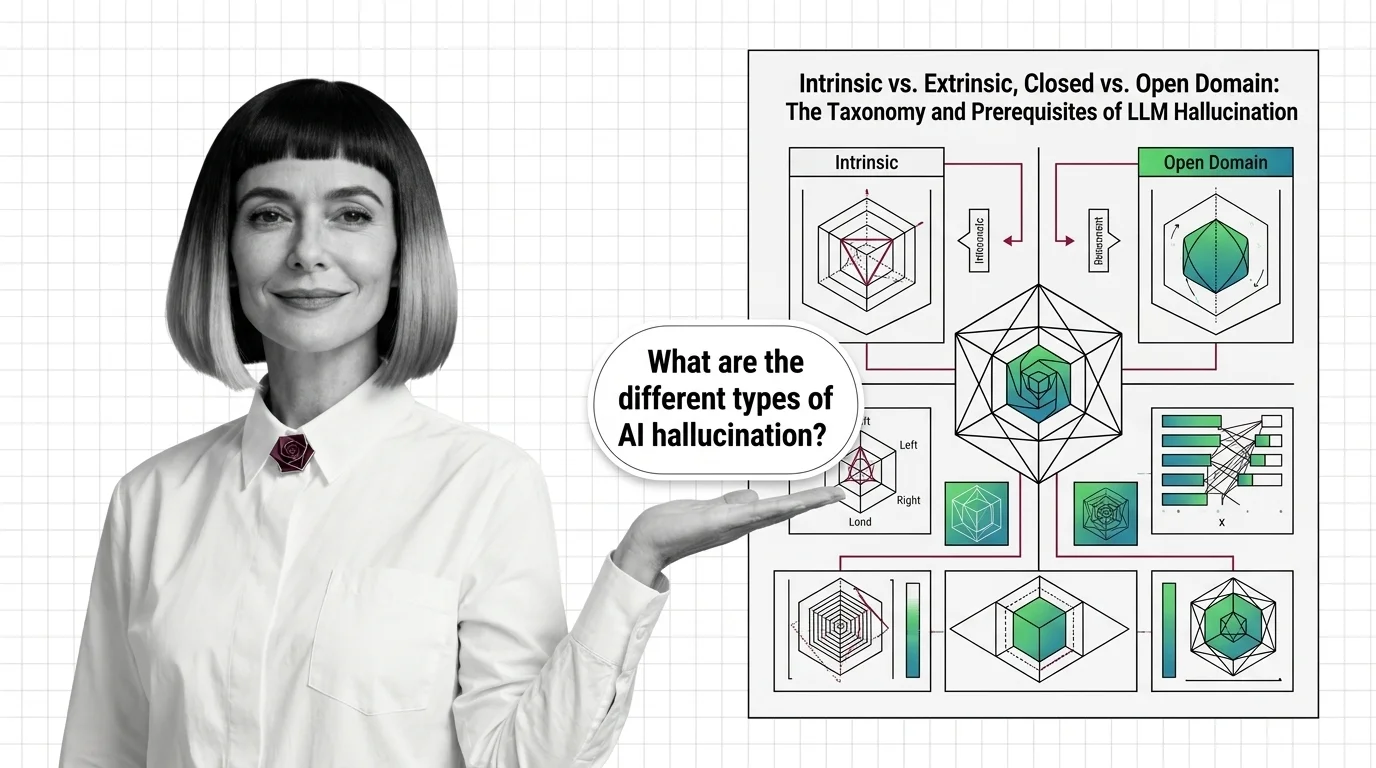
LLM hallucination isn't one problem — it's four. Learn the intrinsic vs. extrinsic taxonomy, the domain split, and the prerequisites that reframe the field.

AI hallucinations aren't bugs — they emerge from how next-token prediction works. Learn why LLMs produce confident falsehoods and what limits current fixes.
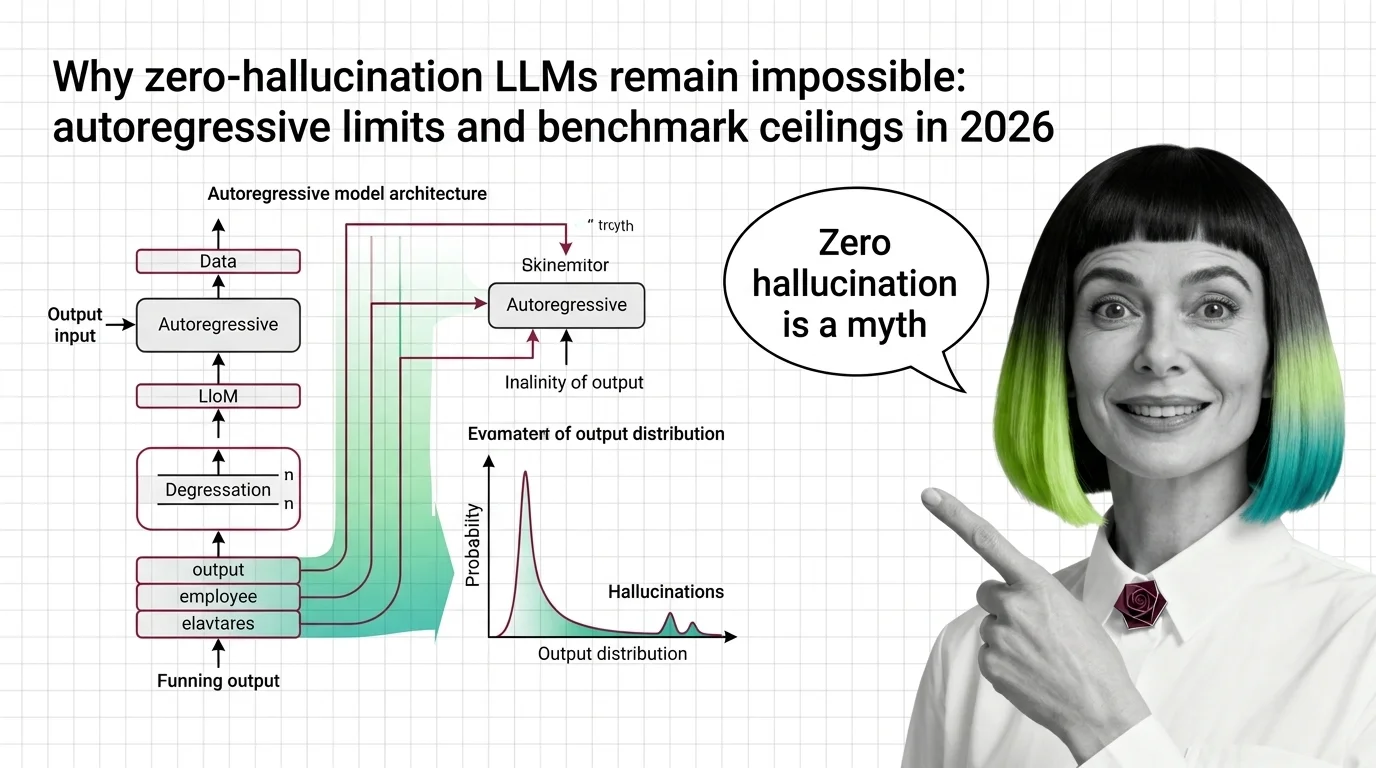
LLM hallucination is mathematically inevitable. Explore the autoregressive limits, benchmark ceilings, and why zero-hallucination LLMs remain impossible in 2026.
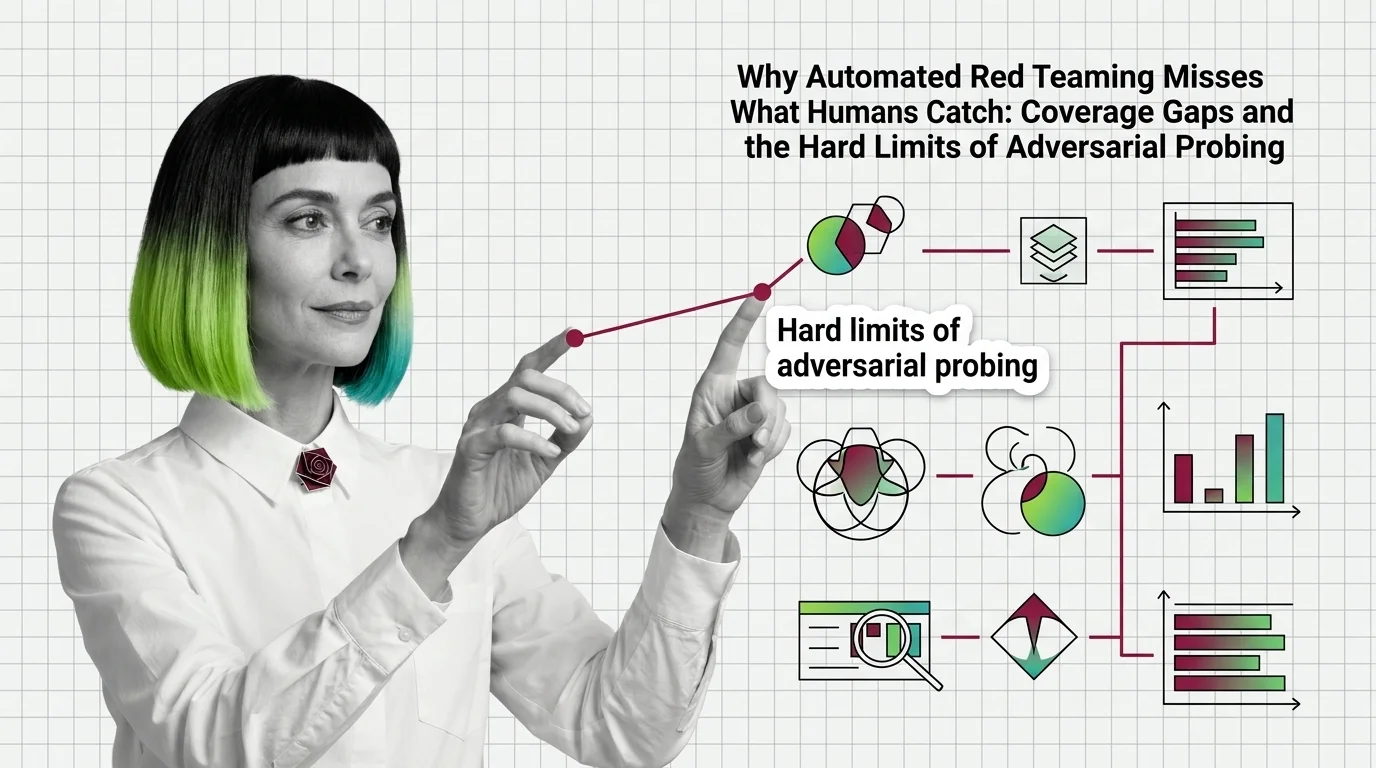
Automated red teaming outperforms human testing but misses critical failures. Coverage gaps explain why automated testing remains fundamentally incomplete.