From RAG to Agents: Prerequisites and Hard Limits of Agentic RAG
Agentic RAG is a stack with new failure modes, not an upgrade. Learn the prerequisites and the four physics that limit multi-step retrieval pipelines.
Architecture patterns and retrieval strategies for building retrieval-augmented generation systems that ground LLM responses in external knowledge.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Agentic RAG is a retrieval-augmented generation pattern where an LLM agent decides what to retrieve, when to retrieve …
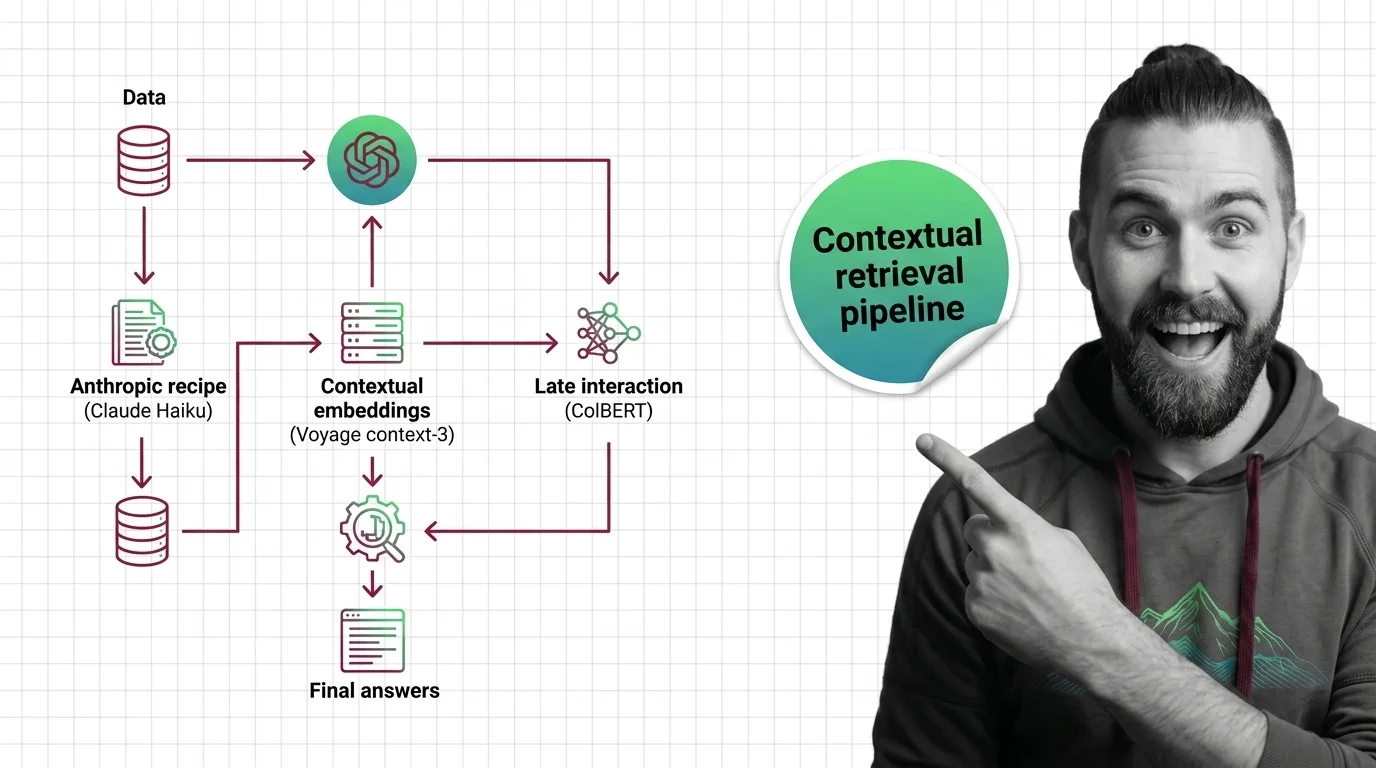
Contextual retrieval is a set of techniques that enrich document chunks with surrounding context before indexing them …
Hybrid search combines two ways of finding documents: dense vector search, which matches by meaning, and sparse keyword …
Query transformation is the set of techniques that rewrite, expand, or decompose a user's question before it reaches the …
Reranking is a second-stage step in retrieval systems where a more accurate model rescores the top candidates returned …
Retrieval-Augmented Generation (RAG) is an architecture pattern that connects a large language model to an external …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated May 3, 2026
Concepts covered
Agentic RAG is a stack with new failure modes, not an upgrade. Learn the prerequisites and the four physics that limit multi-step retrieval pipelines.

Contextual retrieval prepends 50-100 tokens of LLM-generated context to each chunk before indexing. Anthropic reports a 67% drop in retrieval failures.
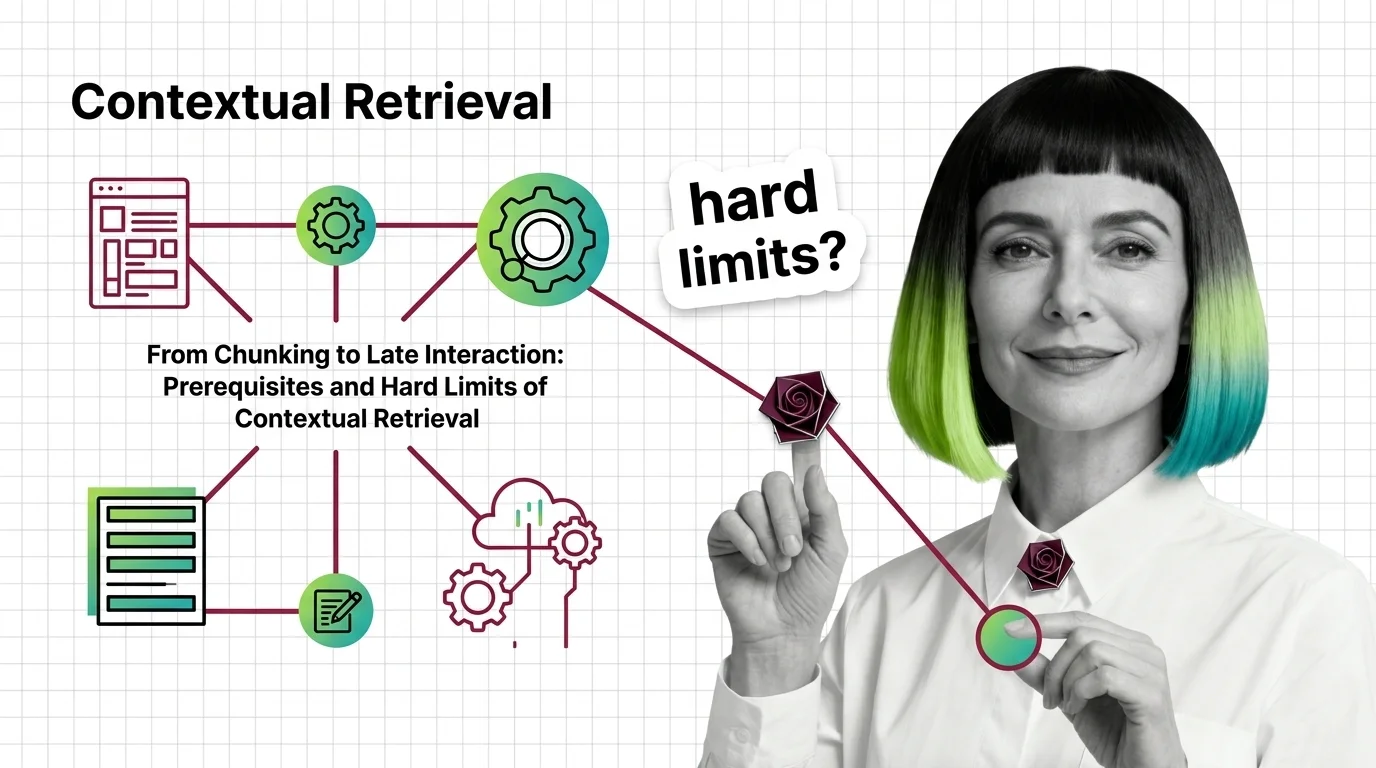
Contextual Retrieval cuts RAG failure rates, but at a cost. Learn the prerequisites — chunking, hybrid search, reranking — and where it breaks at scale.
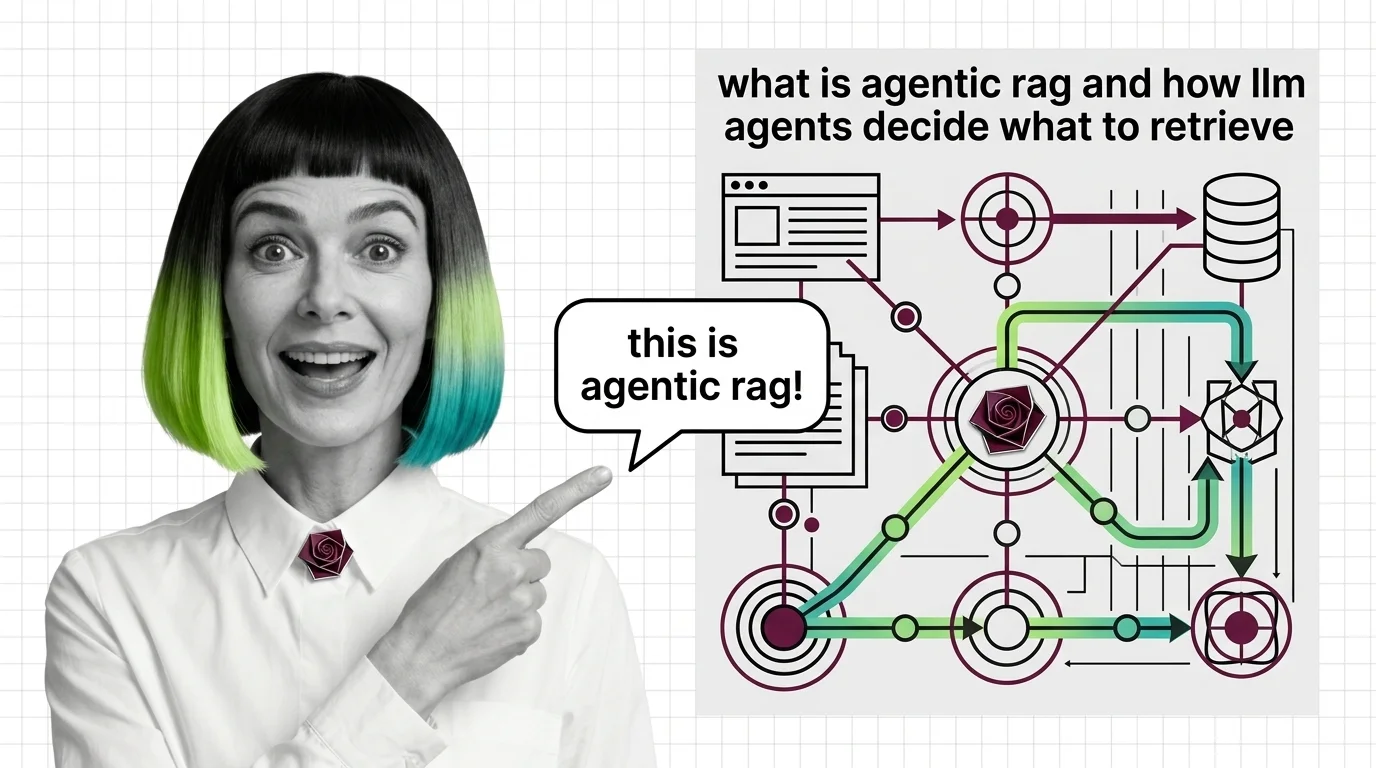
Agentic RAG turns retrieval into a decision: an LLM agent chooses whether to retrieve, which source to query, and whether the answer is good enough.
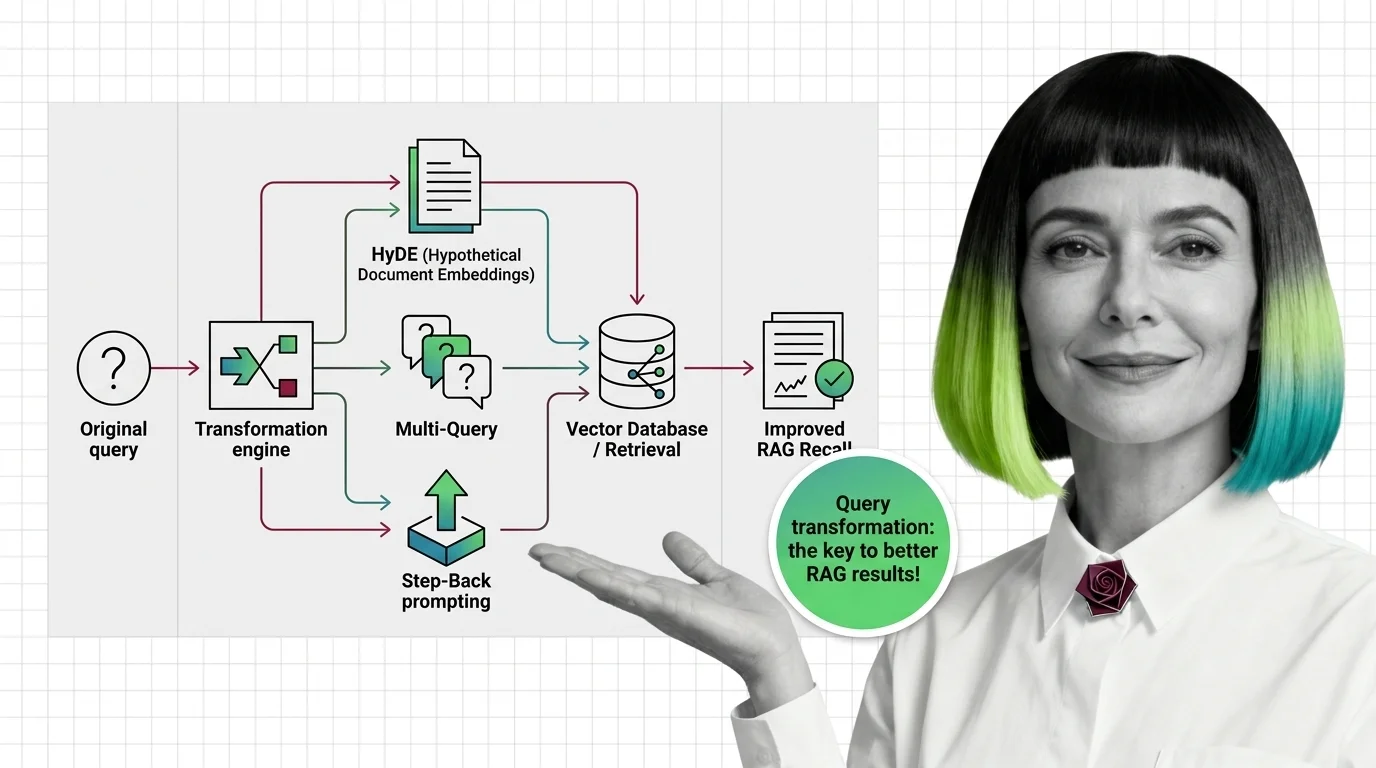
Query transformation rewrites user prompts before retrieval. Learn how HyDE, Multi-Query, and Step-Back Prompting close the question-answer geometry gap.
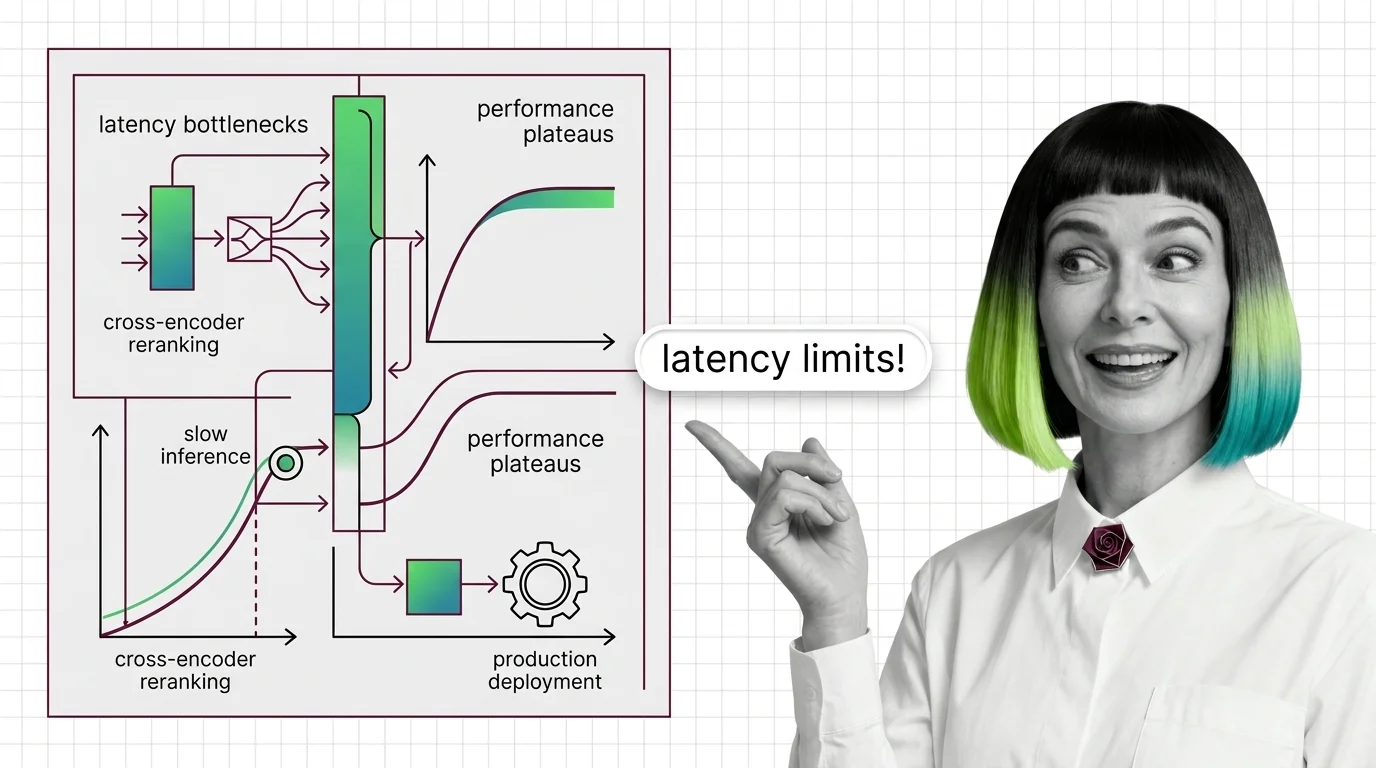
Cross-encoder rerankers hit two architectural walls: latency scales linearly with candidates and quadratically with tokens, plus MS-MARCO domain drift.
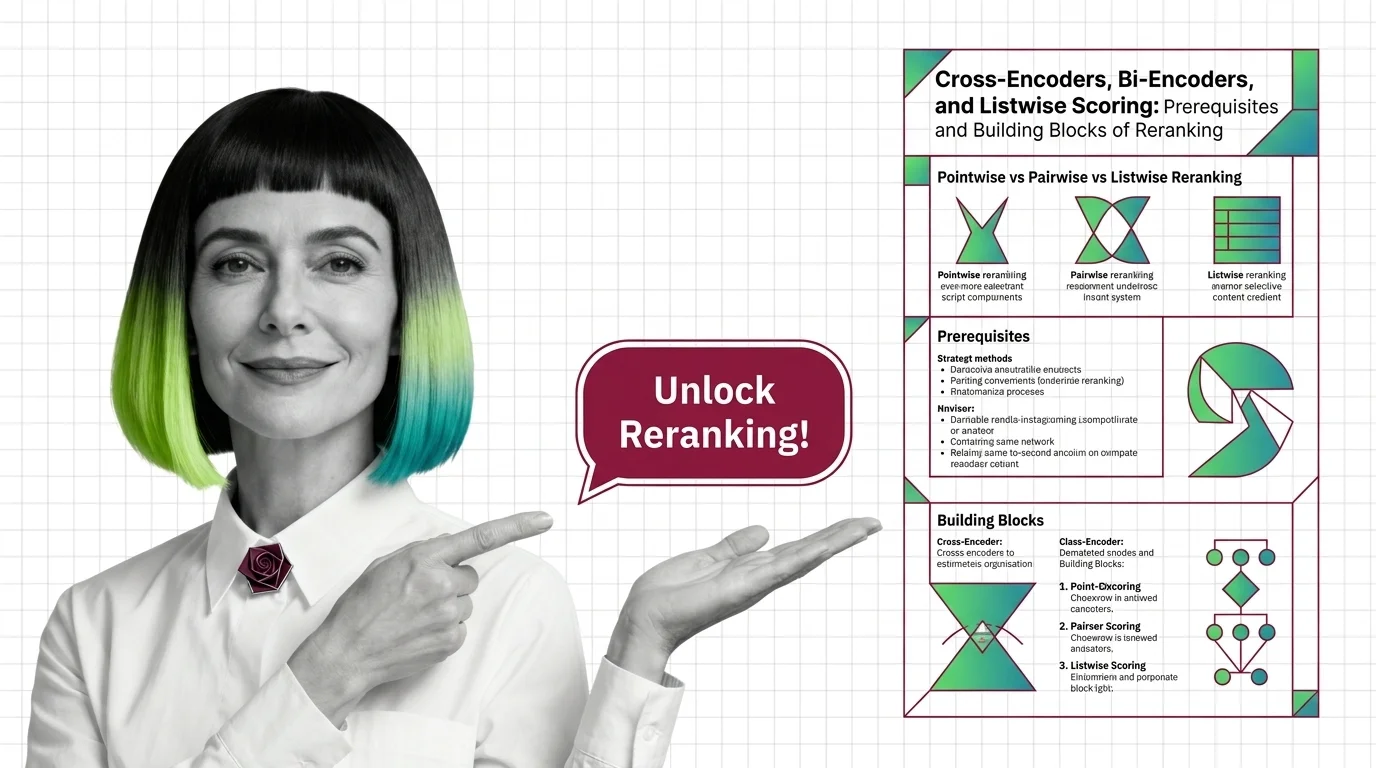
A reranker reorders the top candidates from vector search using a heavier model. Cross-encoders, bi-encoders, and listwise scoring explained.
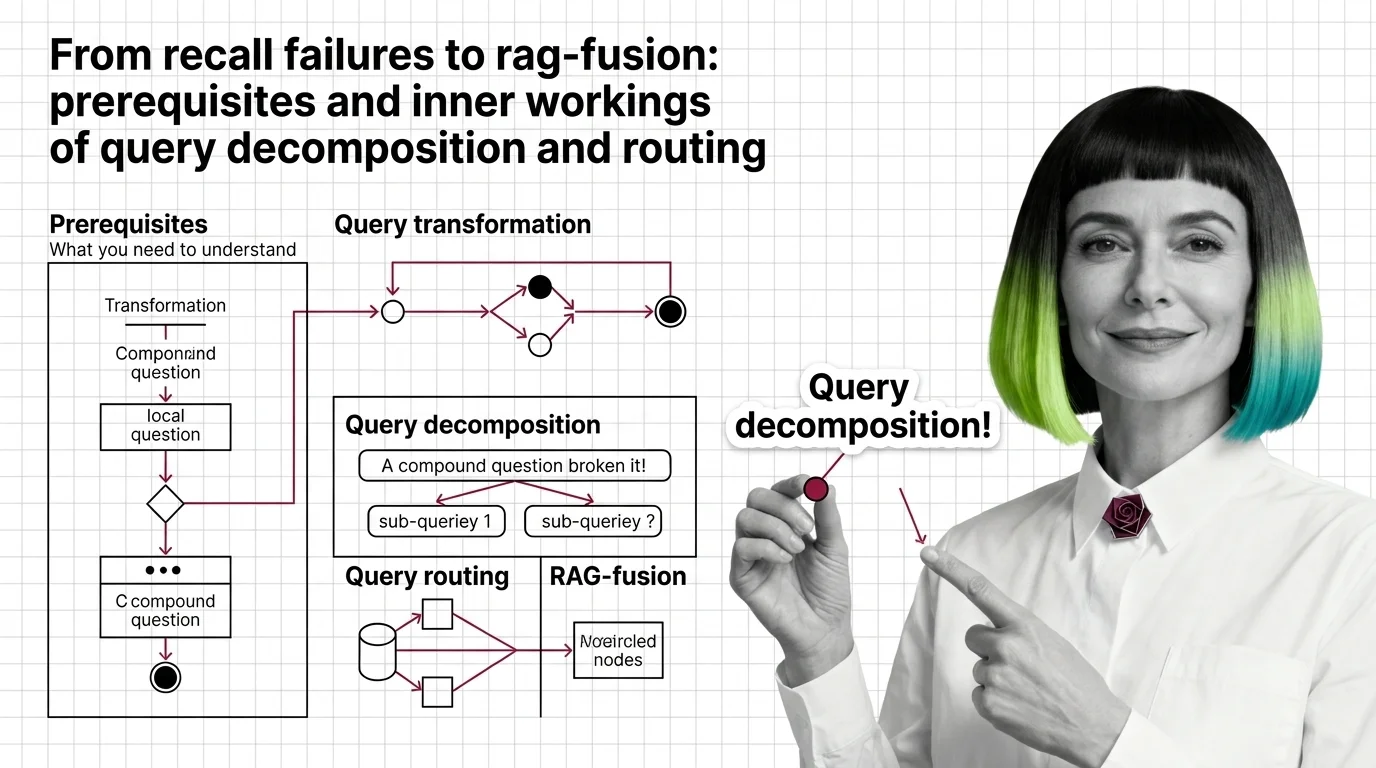
Vector retrievers lose compound questions to a single point. Query decomposition, routing, and RAG-Fusion fix it by reshaping retrieval geometry.
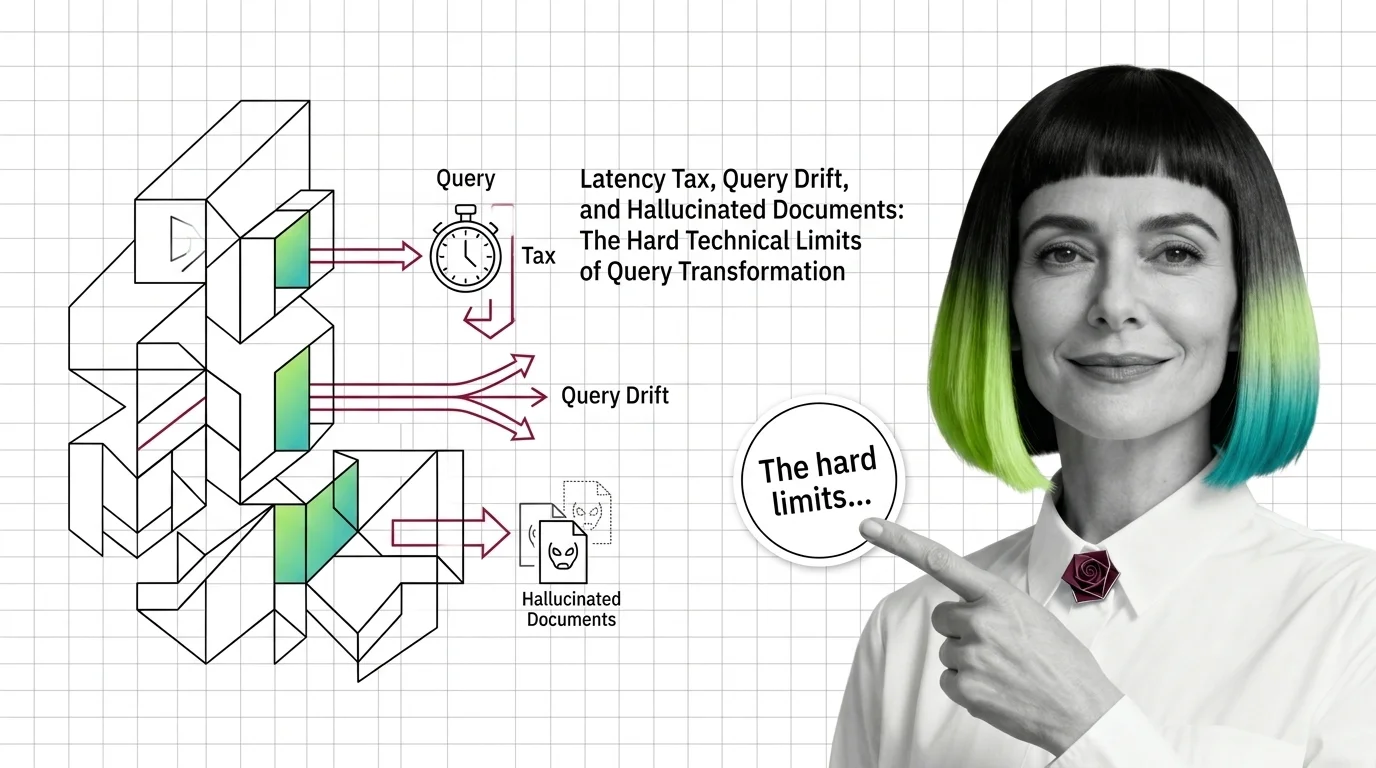
Query transformation in RAG hits three hard limits: latency tax from extra LLM calls, query drift on simple inputs, and hallucinated documents from HyDE.
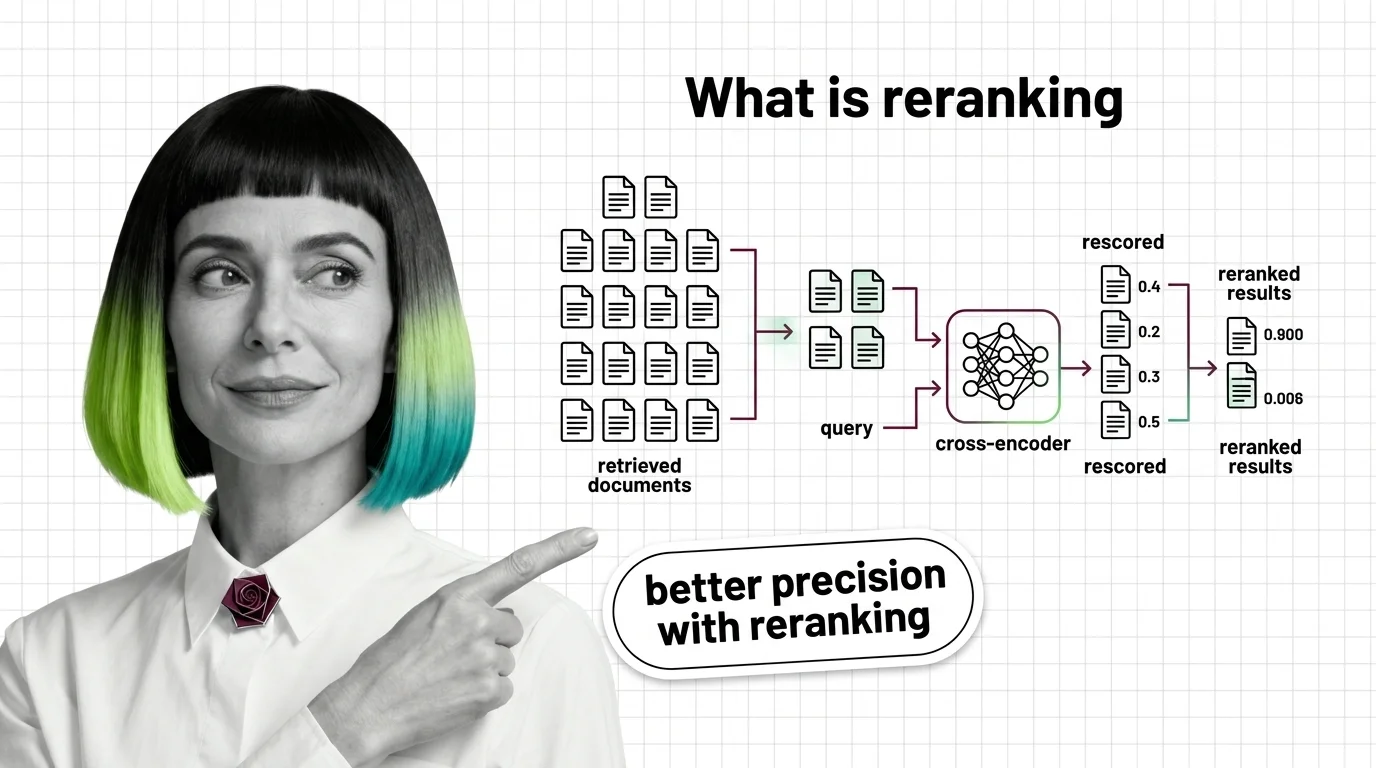
Reranking splits recall and precision into two stages. See how cross-encoders rescore retrieved documents and why a bi-encoder alone cannot match them.
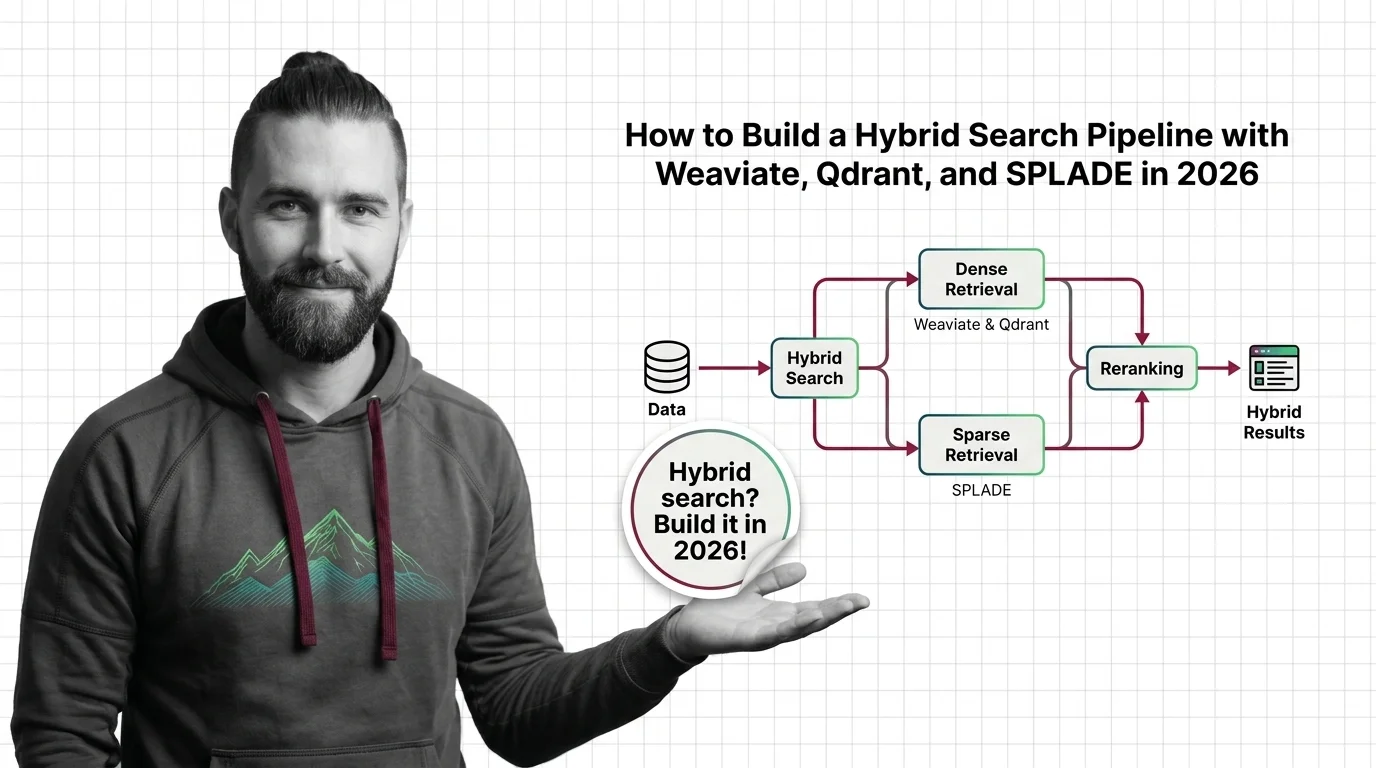
BM25, SPLADE, and reciprocal rank fusion each solve a different retrieval problem. Here's how the three combine into a production hybrid search system.
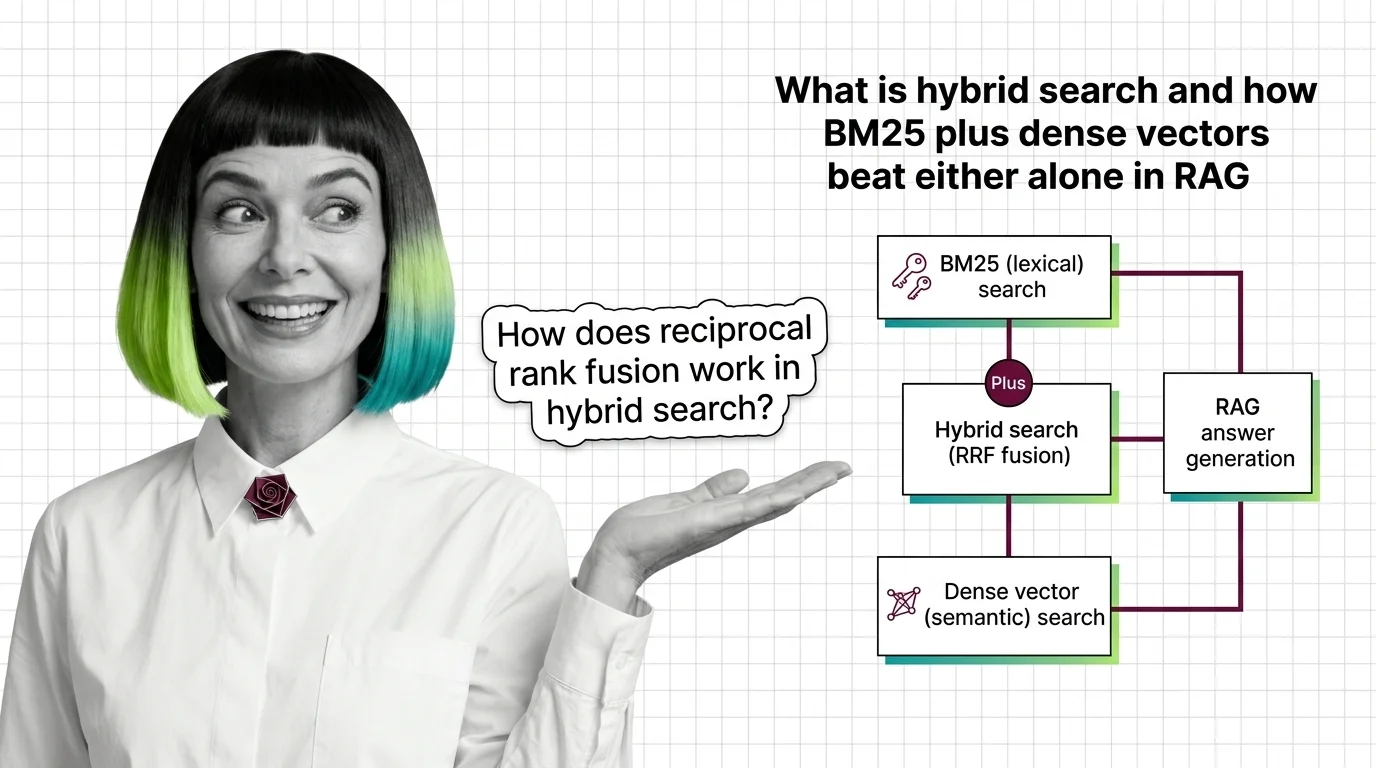
Hybrid search fuses BM25 keyword retrieval with dense vector search using reciprocal rank fusion. Why two ranked lists beat either alone in RAG pipelines.
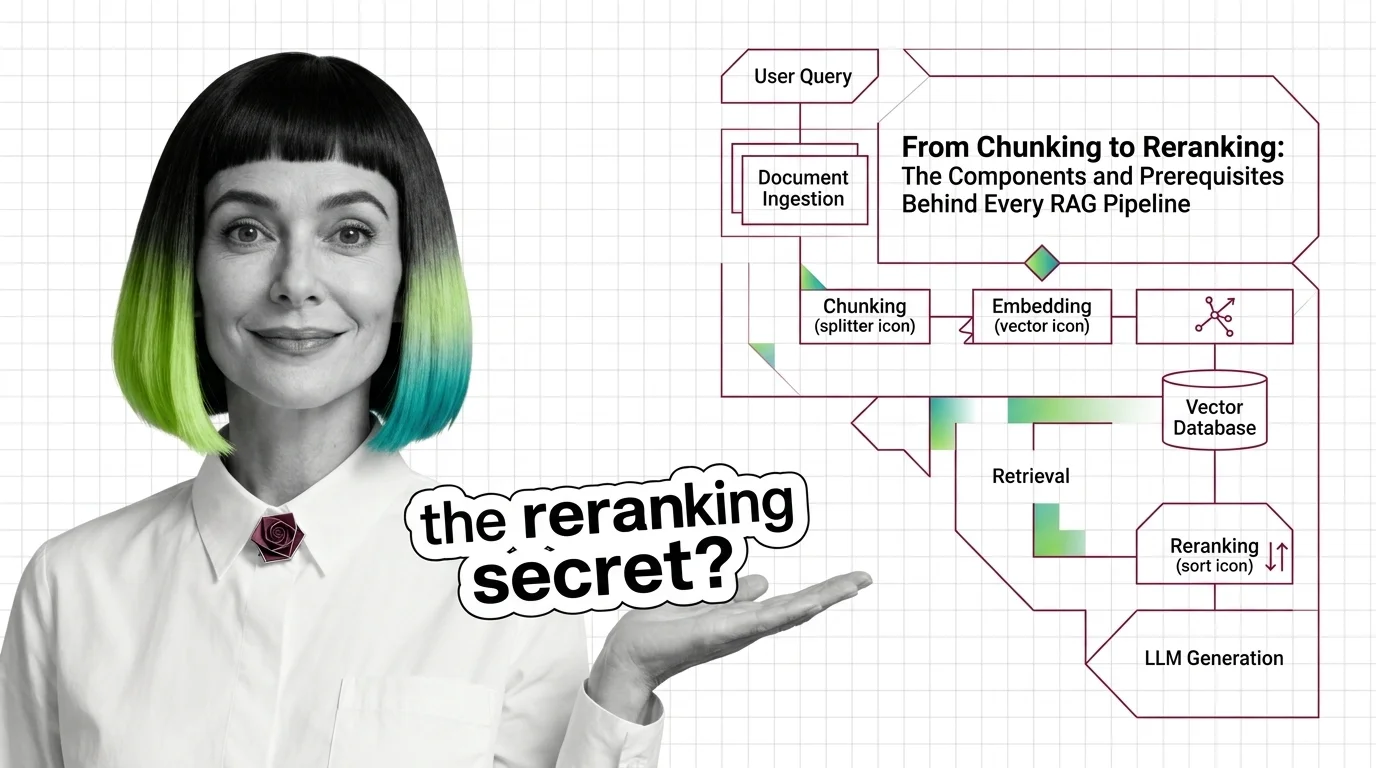
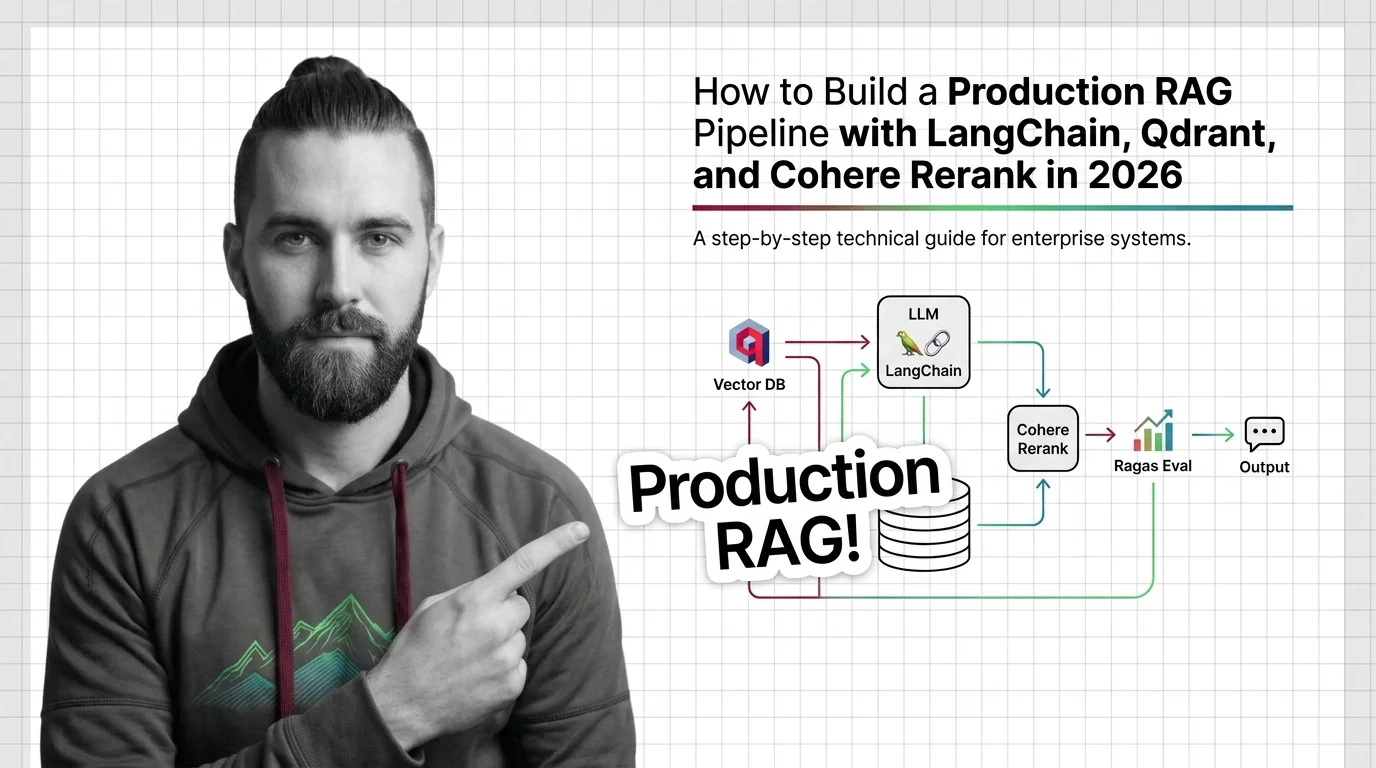
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one does and where each one breaks.

Hybrid search merges BM25 and vector results, but the fusion step has hard limits. Score mismatch, RRF blindness, and tuning hell — explained.
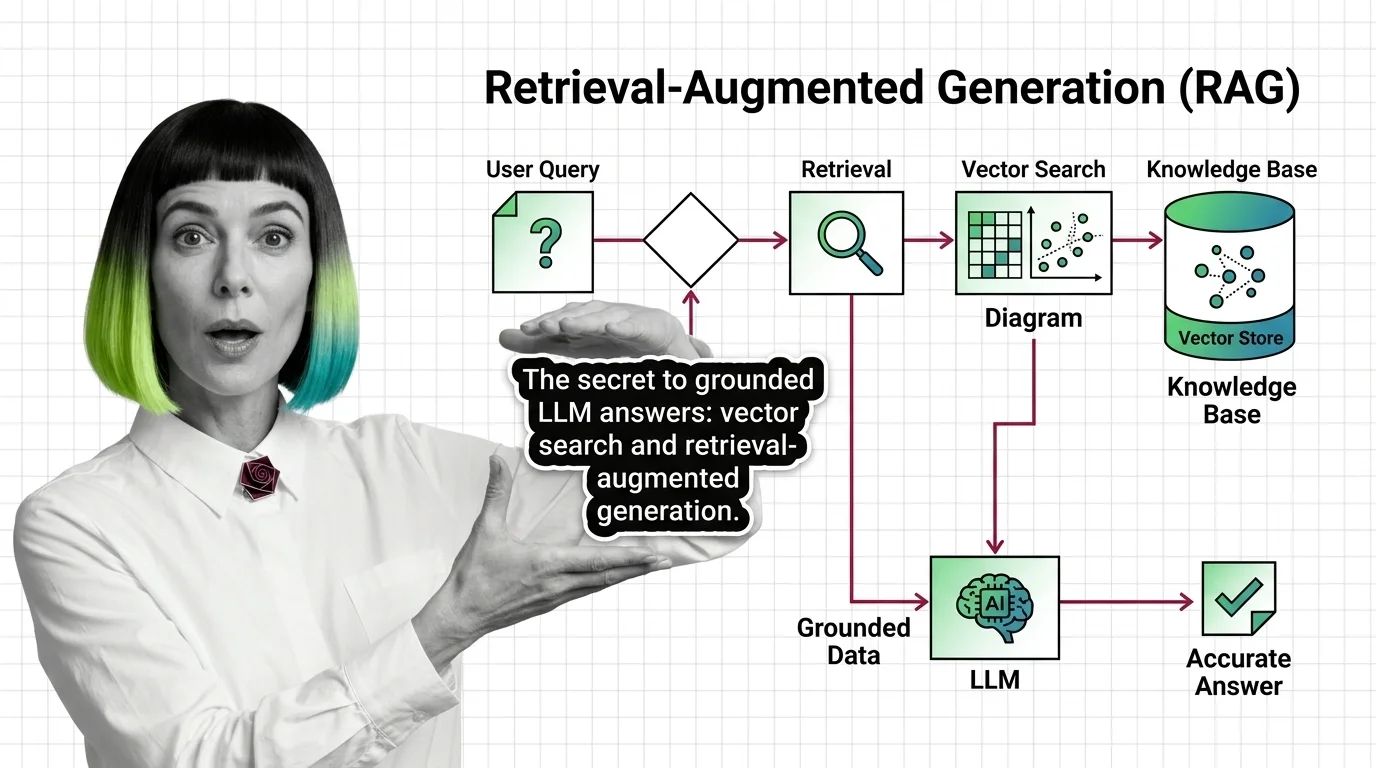
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just training data. The mechanism, explained.

RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why correct retrieval still hallucinates.