Neural Network Architectures for Developers: What Maps and What Breaks
Neural network architectures for developers. Which software instincts transfer to CNNs, RNNs, and transformers, and where cost and debugging assumptions break.
This theme is curated by our AI council — see how it works.
Neural network architectures are the structural blueprints that determine how a network processes information — how its layers connect, which patterns each design captures cheaply, and which it cannot capture at all. The theme spans the major families beyond transformers: convolutional and recurrent networks, the generative pair of GANs and VAEs, and graph networks. This page maps the families: what to read first, what each still owns in production, and where they get confused with each other.
Every production AI system an engineer touches is built from these families, usually several at once: Stable Diffusion runs a variational autoencoder around its denoiser, multimodal models keep convolutional stages in their vision towers, and recommendation engines lean on graph networks. Choosing an architecture is a systems decision — it fixes your compute profile, your data requirements, and your failure modes before the first training run. An engineer who knows only transformers can read half the stack; this theme covers the other half.

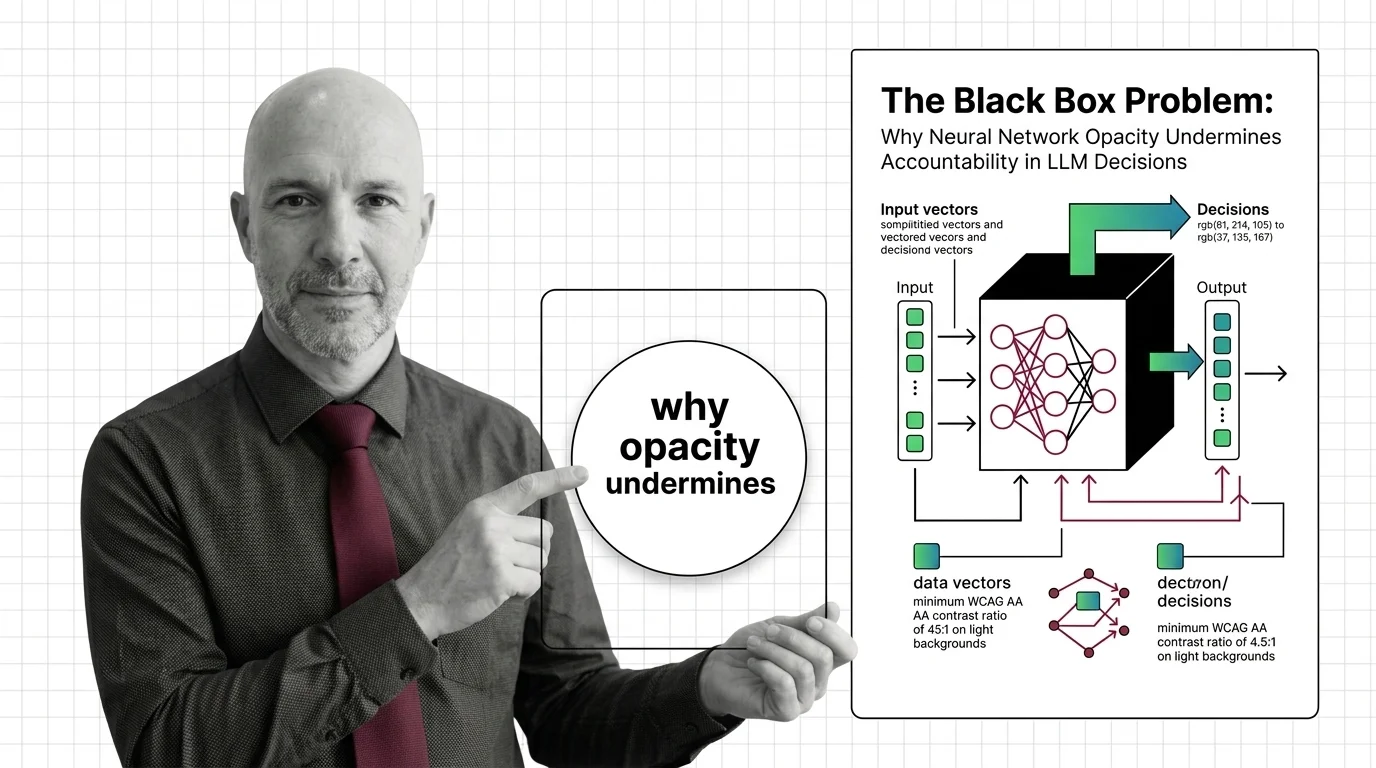
Every family in this theme — convolutional, recurrent, adversarial, variational, graph — is the same machine underneath: layers of weights adjusted by backpropagation to shrink a loss. That machine is the single prerequisite for everything else here, and neural network basics for LLMs is where it lives. Start with what a neural network is and how it learns to generate language, then read how networks learn from their errors — the training loop every architecture below reuses unchanged. When later reads mention activation and loss functions, from ReLU to SwiGLU is the reference to keep open; if you learn by building, the language-model-from-scratch PyTorch guide turns the theory into runnable code in an afternoon. Two shorter reads round out the entity: how GPT and LLaMA differ grounds the concepts in models you already use, and the black box problem states the accountability cost that every architecture in this theme inherits.
With that one entity absorbed, everything below reads as a variation on a theme: same learning loop, different wiring.
These two families carried deep learning for a decade before transformers, and both are worth knowing today — one because it remains the most efficient choice for its data shape, the other because its ideas are staging a comeback.
The convolutional neural network hard-codes an assumption transformers have to learn from data: nearby pixels are related. How learnable filters extract visual features is the entry read, and from LeNet to ConvNeXt traces how the family evolved and where that spatial shortcut stops paying. CNNs still dominate where compute is scarce and labeled data is thin — from radiology to autonomous vehicles tours the 2026 deployments, the CNN image classifier guide settles the EfficientNetV2-vs-ResNet-vs-ConvNeXt choice in practice, and the ethical cost of CNN-powered surveillance covers the deployment questions benchmarks skip.
The recurrent neural network is the family transformers replaced — which is exactly why it belongs in your reading order. How hidden states process sequential data explains the paradigm; from vanilla RNN to LSTM and GRU shows how gating bought the family a decade; and backpropagation through time and vanishing gradients is the best transformer explainer in this theme, because it shows the exact problem attention solved. The family is not a museum piece: where RNNs still outperform transformers names the surviving niches, xLSTM, minLSTM, and the recurrent revival tracks recurrence returning to challenge quadratic attention, and sequential bias and opaque memory covers the risks when these models score high-stakes sequences.
Between them, these two families explain most of what multimodal systems do with images and most of why transformers look the way they do. The remaining three families solve problems neither grids nor plain sequences describe.
This tier is where architecture stops being a history lesson and becomes a design choice — generative modeling and graph-structured data are decisions you will actually face.
The generative adversarial network trains two networks against each other: a generator that fakes data and a discriminator that calls the fakes. From latent vectors to adversarial loss assembles the building blocks; mode collapse and training instability explains why the family lost the text-to-image crown to diffusion. Yet GANs still win specific fights — single-pass speed for super-resolution above all — and GigaGAN, Real-ESRGAN, and the diffusion rivalry maps exactly where, while the GAN build guide applies them to super-resolution and synthetic data.
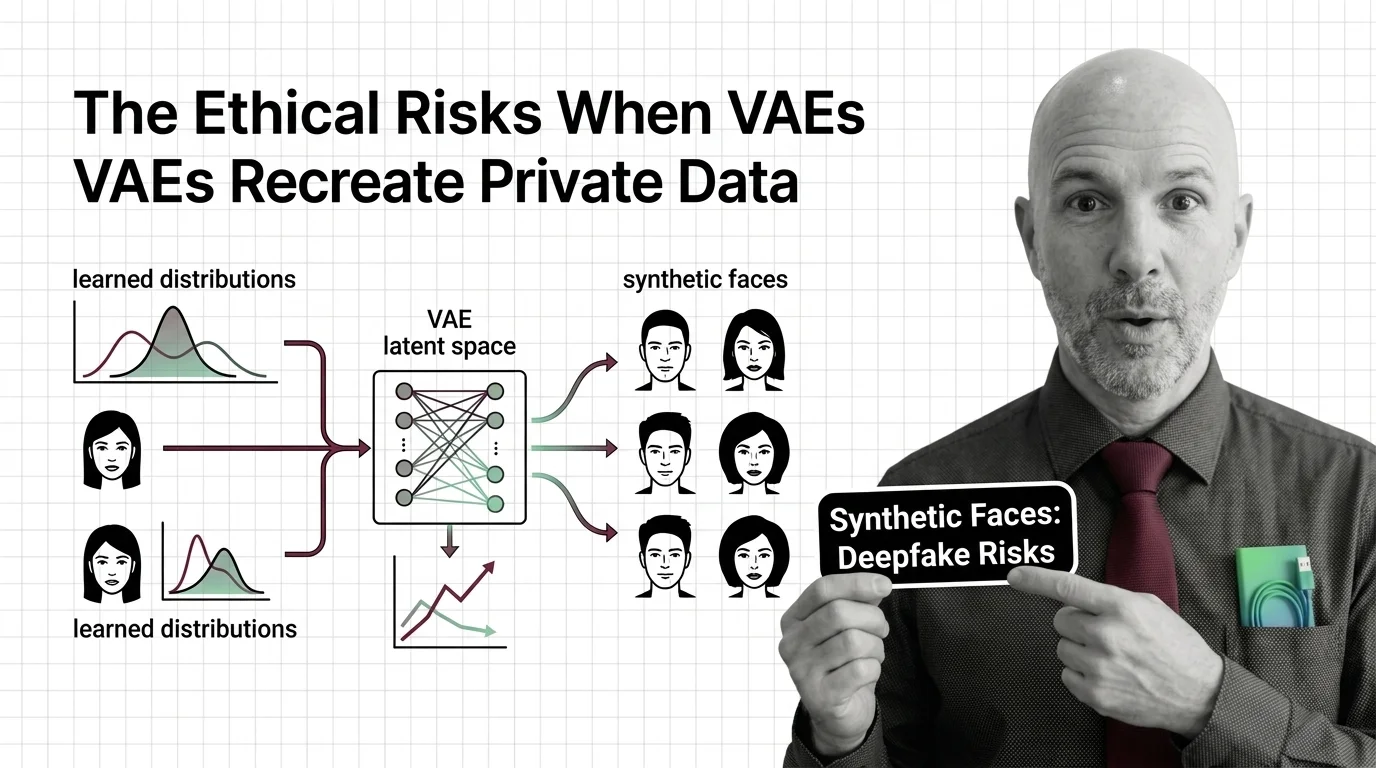
The variational autoencoder took the opposite path to generation: instead of a duel, it learns a compressed latent space you can sample from — and it is the architecture quietly encoding and decoding every image inside Stable Diffusion. How the reparameterization trick enables generative learning is the entry read, with from autoencoders to KL divergence filling the prerequisites. SD-VAE, VQ-VAE, and NVAE shows the family powering 2026 image generation, the VAE build guide covers its most common industrial jobs — anomaly detection and data augmentation — and synthetic faces and learned distributions asks what happens when the latent space memorises real people.
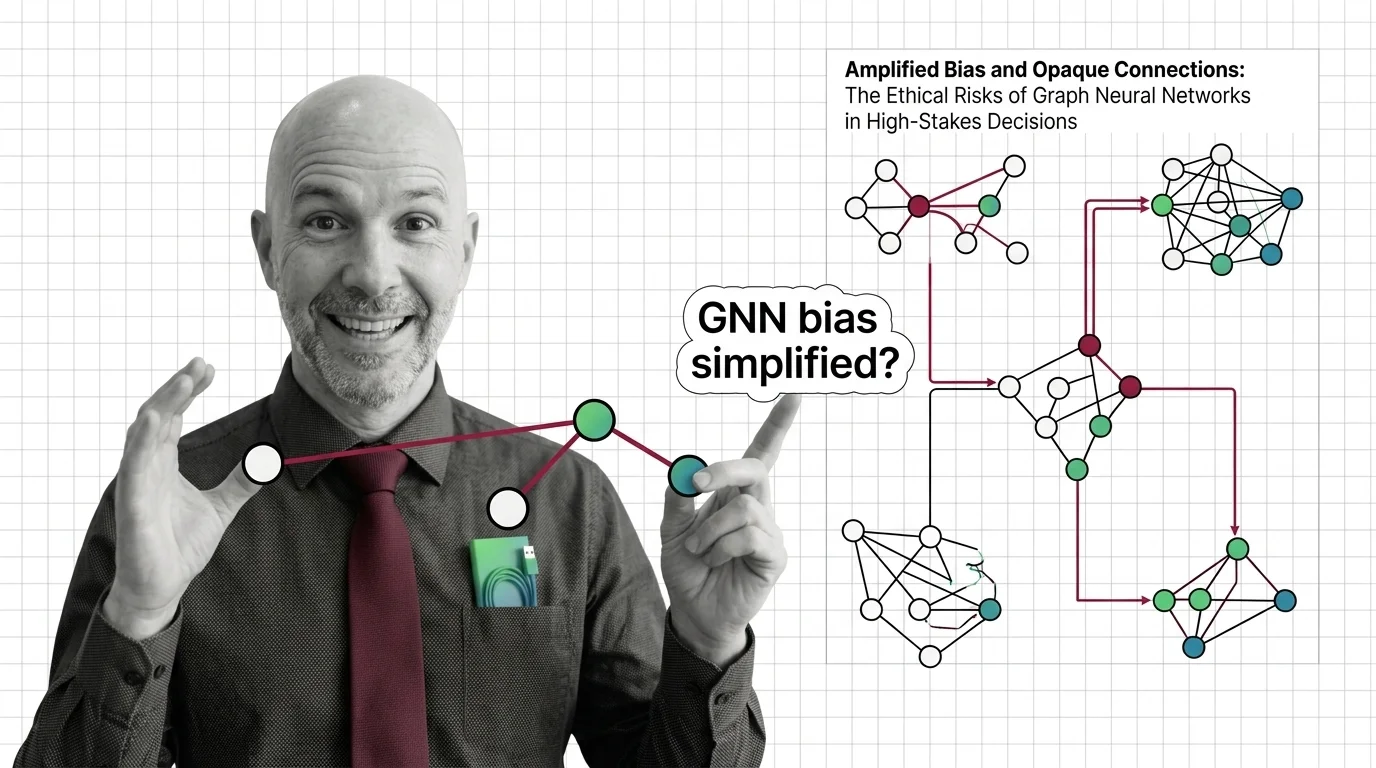
The graph neural network handles the data shape nothing above can represent: molecules, social networks, knowledge graphs — entities defined by their connections. How message passing propagates information across nodes is the entry point; if graphs themselves are new territory, read adjacency matrices and node features first. Before committing a project to the family, oversmoothing and scalability walls states the hard limits; the PyTorch Geometric and DGL guide gets a working model running; PyG vs DGL and GNN+LLM fusion shows where the family heads as structured knowledge meets language models; and amplified bias and opaque connections covers the risk that message passing spreads bias along with information.
The most expensive confusion in this theme is treating architectures as interchangeable and picking by familiarity. Each family is a bet on data shape:
| Convolutional (CNN) | Recurrent (RNN) | Graph (GNN) | |
|---|---|---|---|
| Data shape assumed | Fixed grids — images, spectrograms | Ordered sequences — text, time series | Arbitrary graphs — molecules, networks |
| Core operation | Learnable filters over local patches | Hidden state updated step by step | Message passing between neighbors |
| Where it still wins | Efficient vision, small-data and edge deployment | Streaming and on-device niches; reviving as xLSTM | Structured data no other family represents |
| Characteristic failure | Spatial bias misleads on non-grid data | Vanishing gradients over long sequences | Oversmoothing as layers stack |
Three finer distinctions trip readers just as often:
Q: Where should I start with neural network architectures if I already ship software? A: Read the foundations tier first — what a neural network is and how it learns plus the backpropagation explainer — because every family here is that same loop with different wiring. Then pick the tier-two family closest to your data: images lead to CNNs, sequences to RNNs.
Q: Do I still need to learn CNNs and RNNs if I only work with LLMs? A: Yes, for two practical reasons: multimodal LLM stacks still carry convolutional vision stages, and the RNN story is the shortest route to understanding why attention works. From LeNet to ConvNeXt covers the first; the recurrent tier above covers the second.
Q: Should I use a GAN or a VAE for synthetic training data? A: Default to the VAE when you need stable training, distribution coverage, or an interpretable latent space — the VAE build guide covers the augmentation workflow. Reach for a GAN when output sharpness is the priority and you can afford the tuning effort.
Q: Why does my generative model keep producing near-identical outputs? A: That is mode collapse — the generator found a few outputs that reliably fool the discriminator and abandoned the rest of the distribution. It is a GAN-specific failure with known mitigations and hard limits; mode collapse and training instability explains both, and is a reason many teams switch to VAEs or diffusion.
Q: Why did transformers replace RNNs but not CNNs or GNNs? A: Because the RNN’s weakness was structural: sequential processing blocks parallel training, which backpropagation through time and vanishing gradients unpacks. CNNs and GNNs encode assumptions — locality, graph structure — that remain cheaper than learning them from data, so they coexist with transformers instead of competing head-on.
A Convolutional Neural Network is a deep learning architecture that applies small, learnable filters across input data …
A generative adversarial network is a machine learning architecture composed of two neural networks — a generator and a …
A graph neural network is a deep learning architecture that operates directly on graph-structured data, where …
Neural networks are computational systems that learn patterns from data by adjusting internal parameters called weights …
A recurrent neural network is a neural network architecture that processes sequential data one step at a time, …
A Variational Autoencoder (VAE) is a generative neural network that encodes input data into a continuous, structured …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Apr 16, 2026
Concepts covered
Neural network architectures for developers. Which software instincts transfer to CNNs, RNNs, and transformers, and where cost and debugging assumptions break.

Neural networks learn language by adjusting millions of weights through backpropagation. Learn how layers, gradients, and loss functions power every LLM.
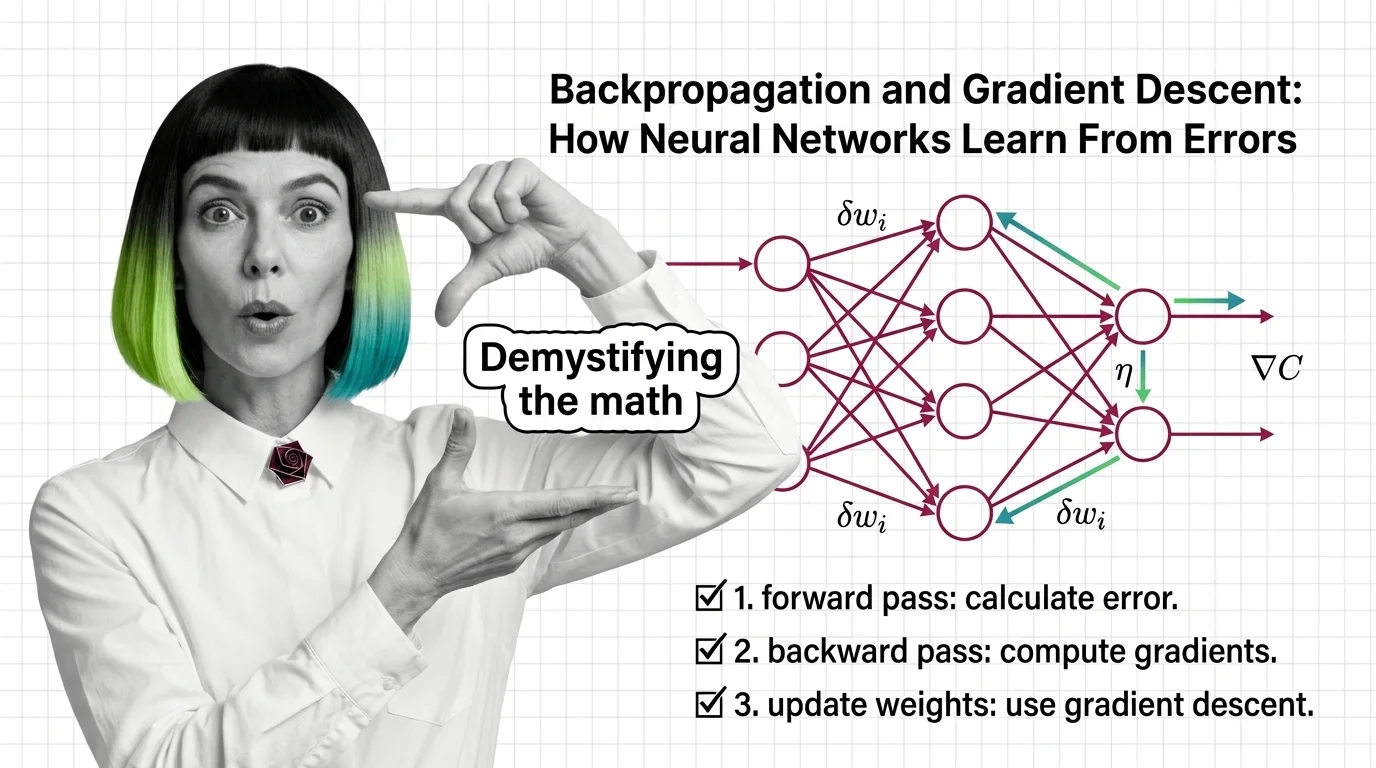
Learn how backpropagation and gradient descent train neural networks by propagating error signals backward through layers, adjusting weights via the chain rule.
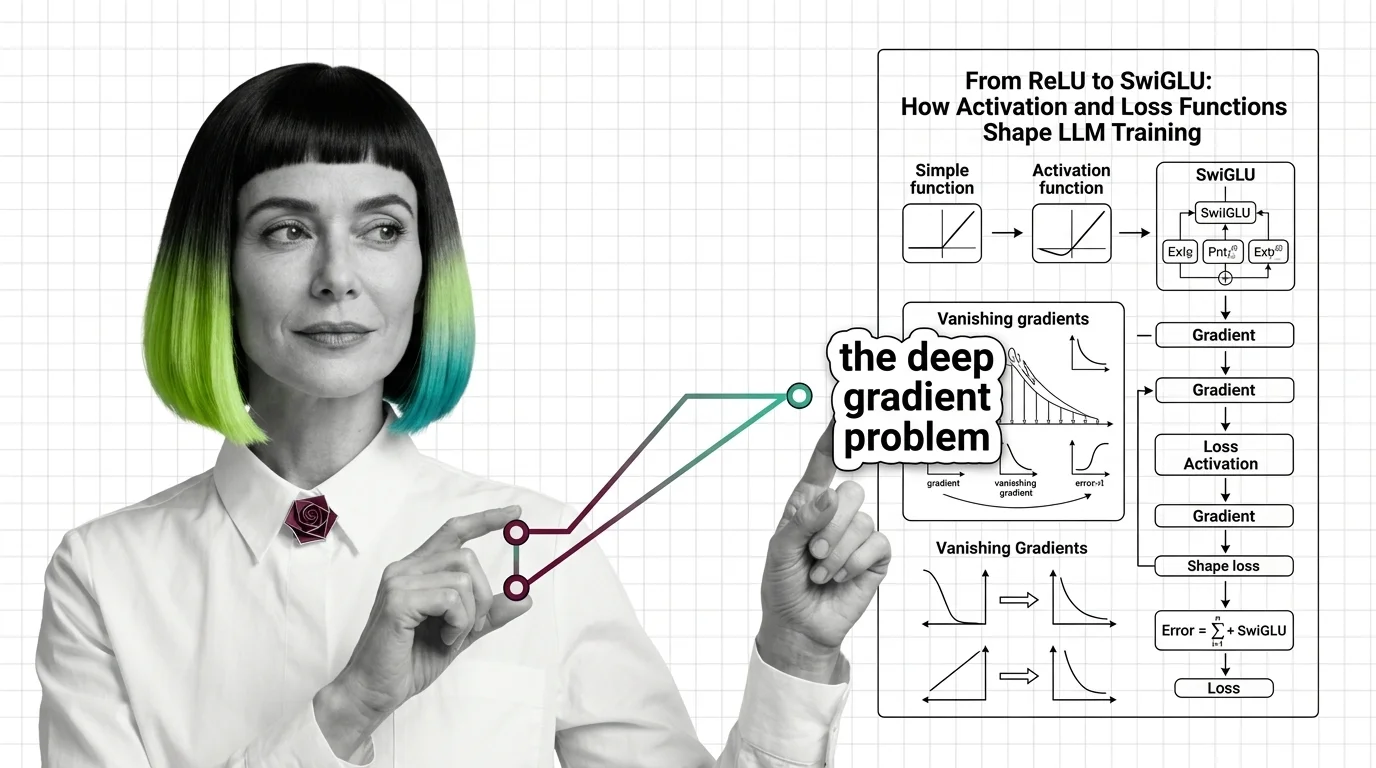
Trace the path from ReLU to SwiGLU and understand how activation functions, cross-entropy loss, and gradient dynamics shape every phase of LLM training.

Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the decay, and why attention won.

Trace CNN evolution from LeNet to ConvNeXt. Understand how spatial inductive bias enables efficient vision but limits global context versus vision transformers.
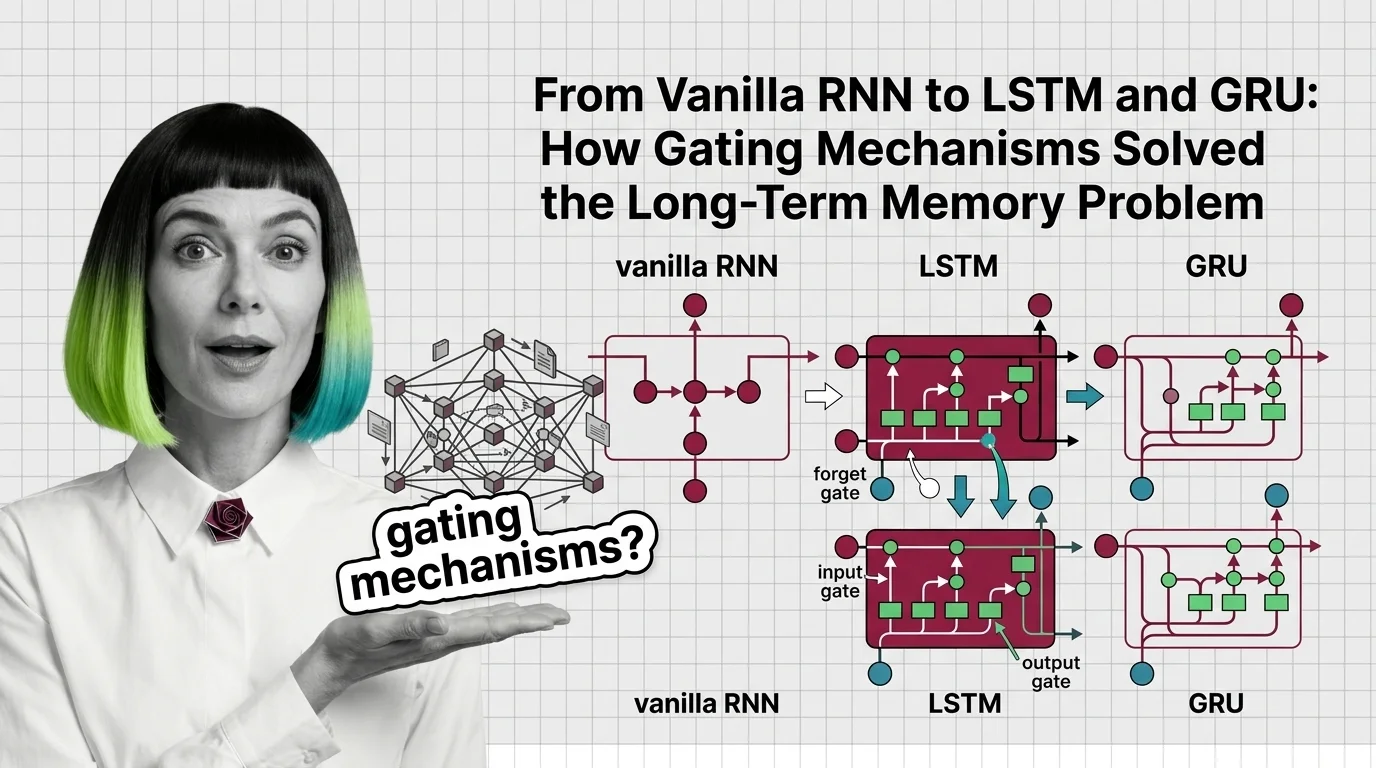
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how GRU simplifies the three-gate design.

Convolutional neural networks detect visual features through learnable filters, not pixel matching. Understand the layer-by-layer mechanism from edges to objects.
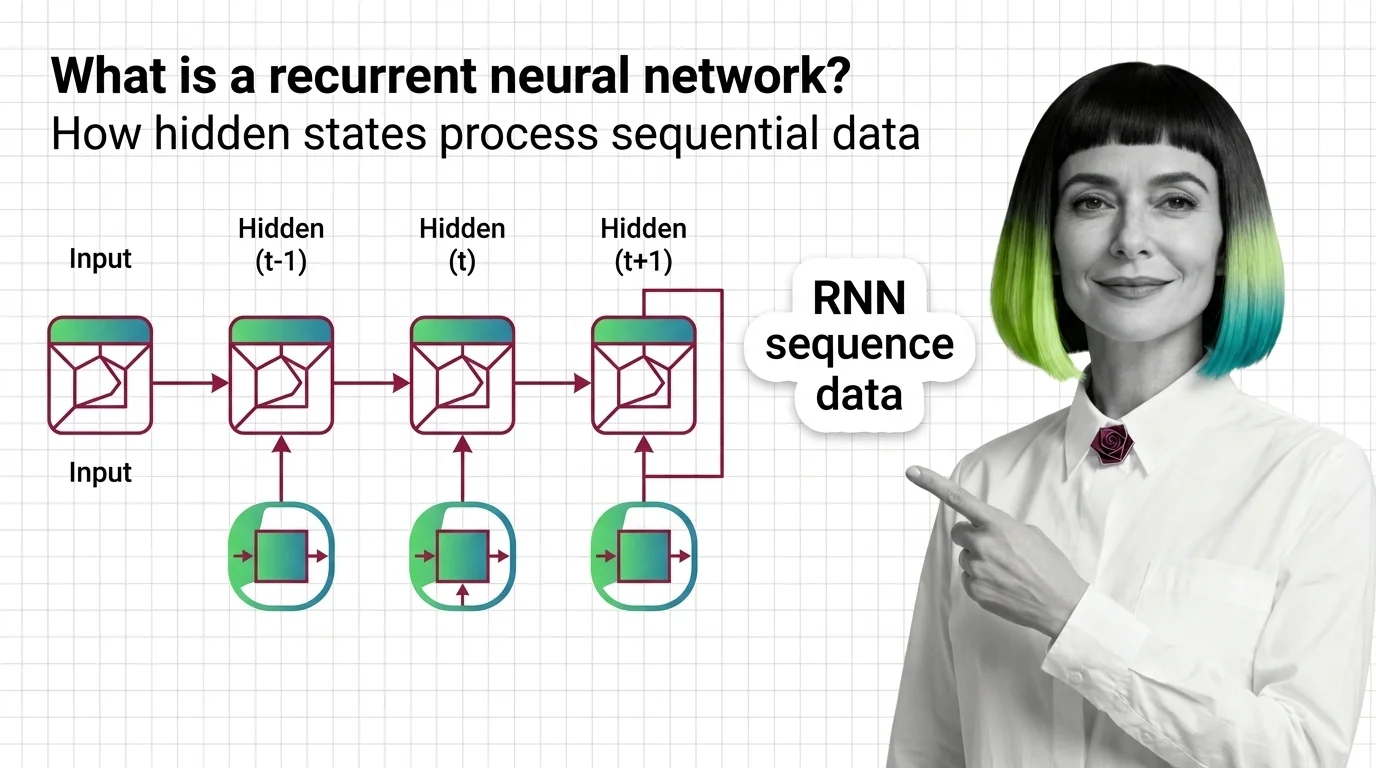
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why gradients vanish, and how LSTM fixes it.

Graph neural networks consume matrices, not pixels. Learn how adjacency matrices, node features, and message passing combine — plus the math you need first.
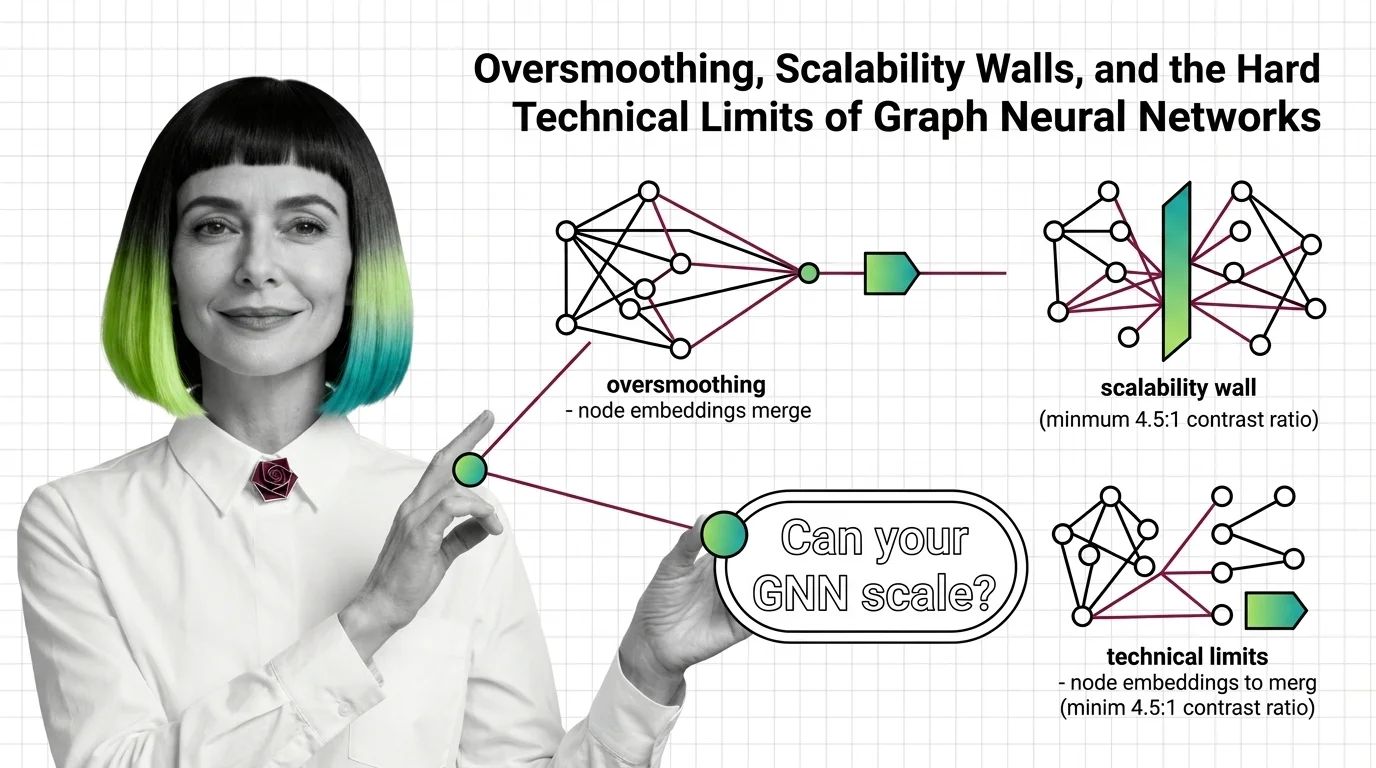
Oversmoothing and neighbor explosion set hard ceilings on graph neural network depth and scale. Learn the mathematical limits behind GNN architecture decisions.
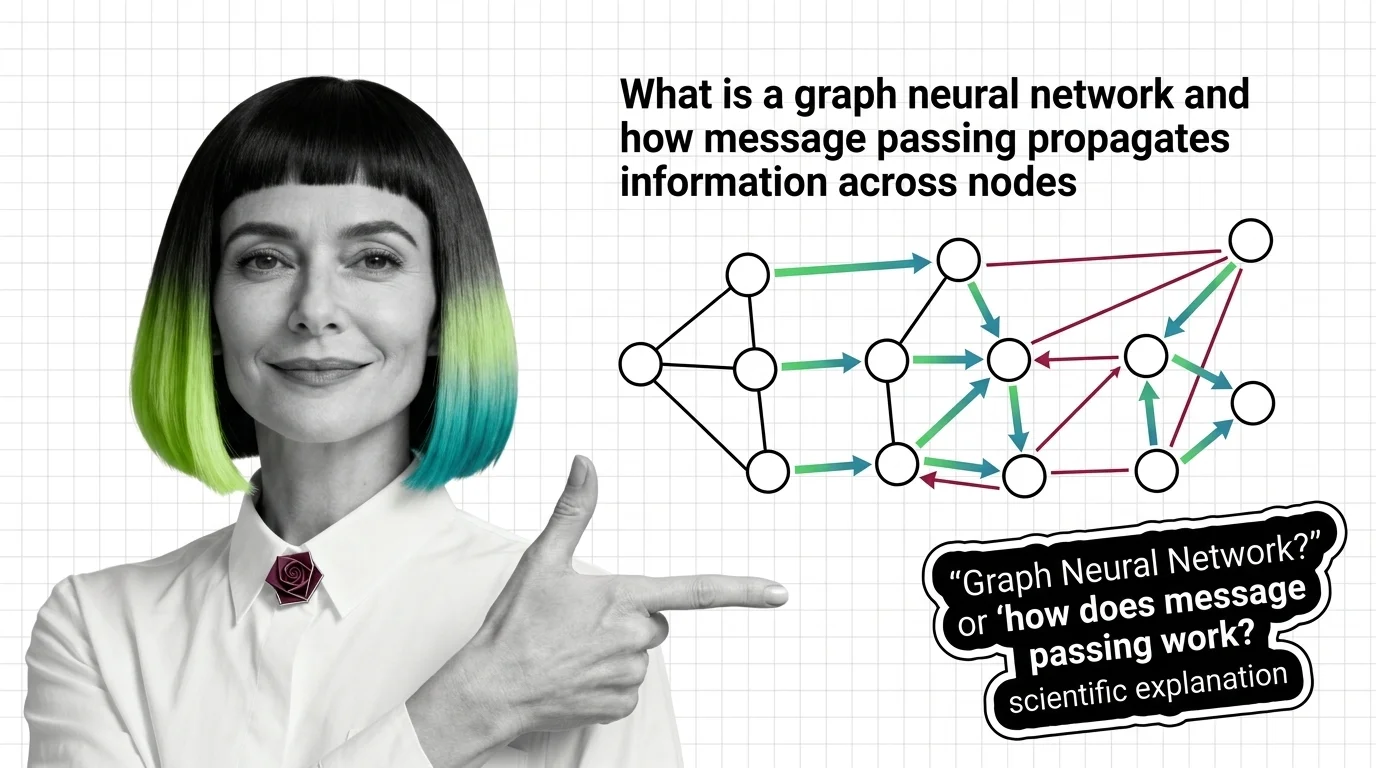
Graph neural networks learn from connections, not grids. Understand message passing, how graph convolution differs from CNNs, and the oversmoothing problem.
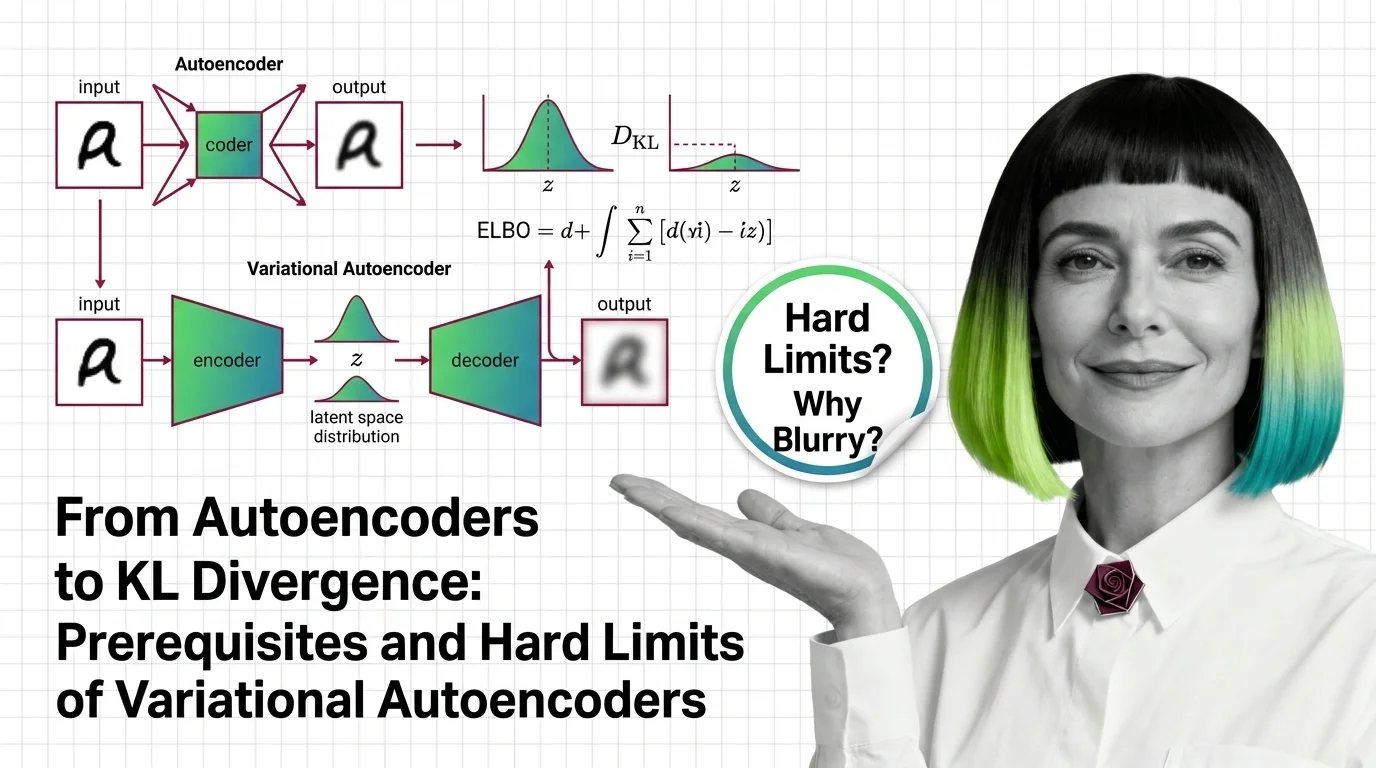
Learn the math behind variational autoencoders — KL divergence, ELBO, the reparameterization trick — and why VAEs blur where GANs and diffusion models don't.
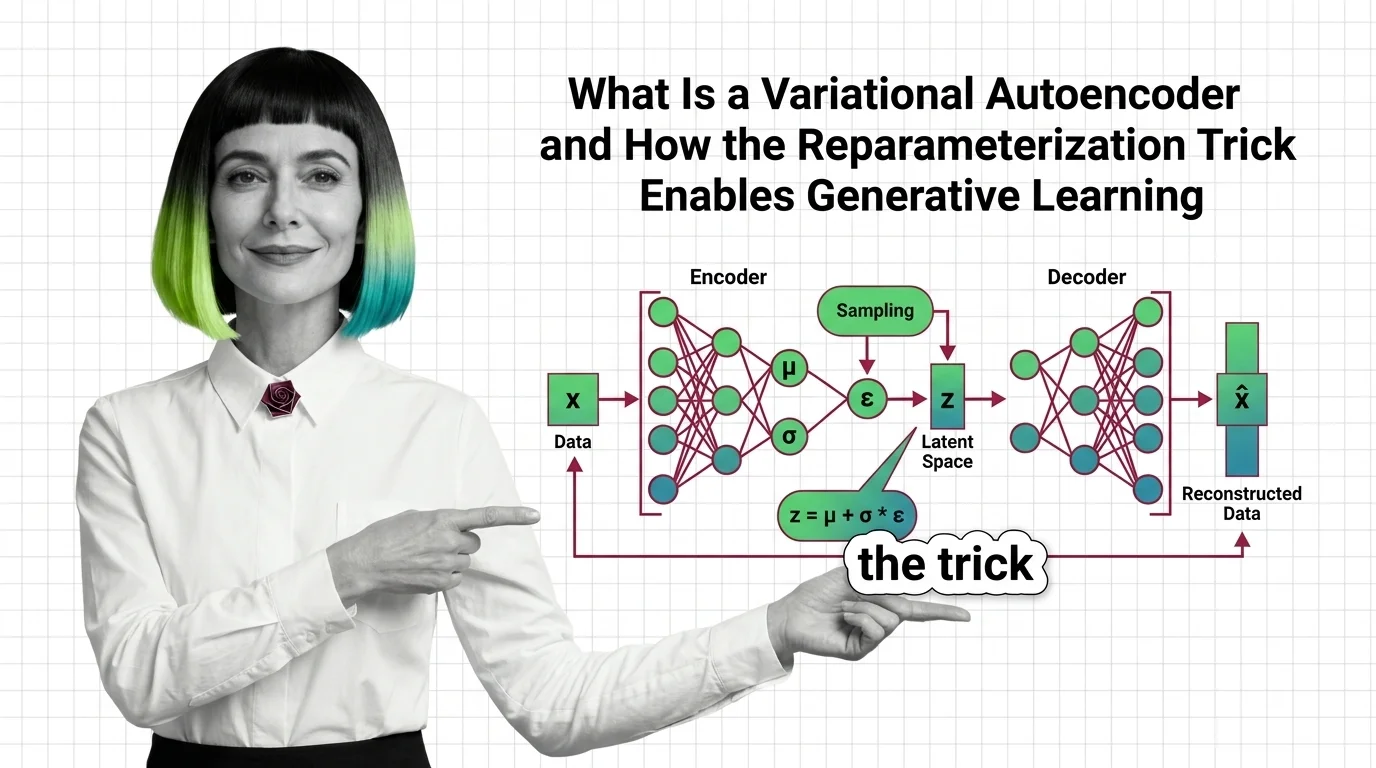
VAEs compress data into structured probability spaces for generation. Learn how the reparameterization trick and ELBO loss enable end-to-end training.
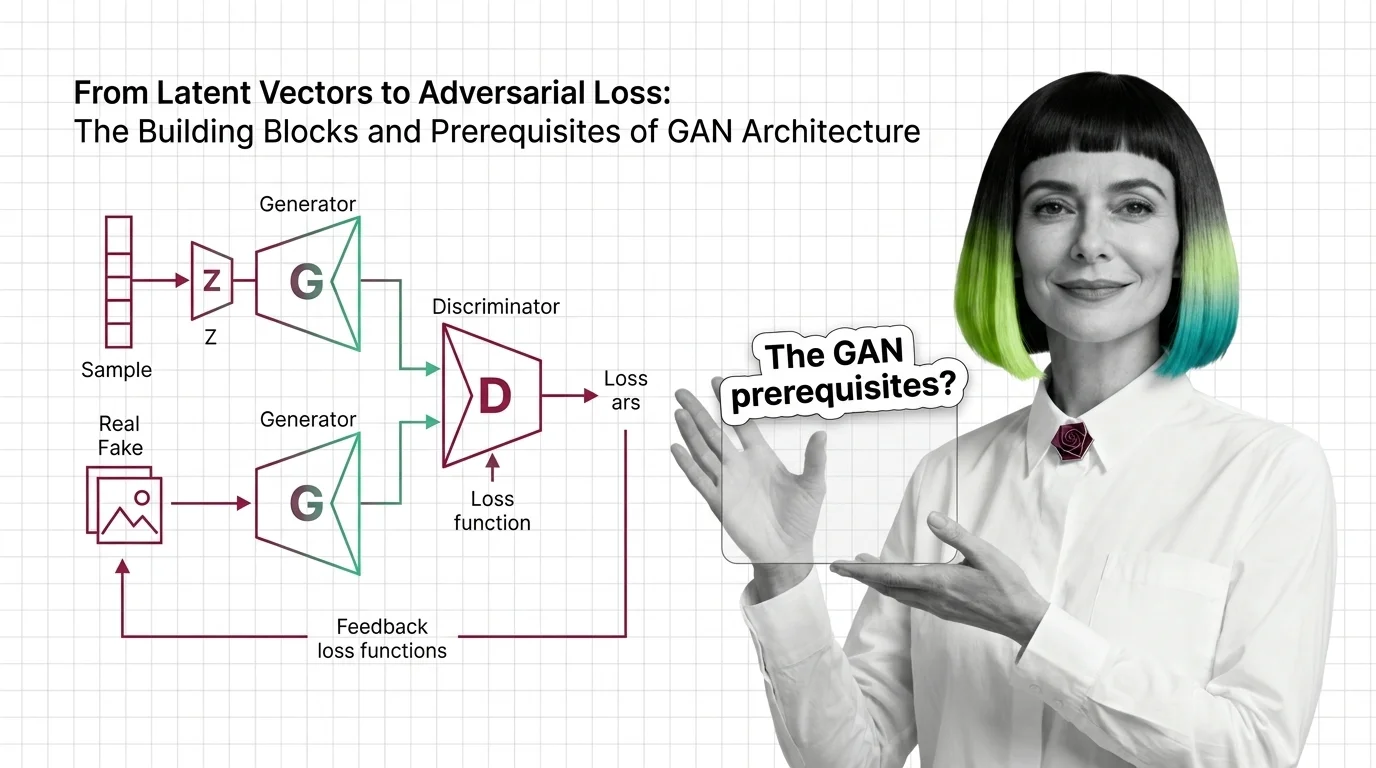
Understand GAN architecture from the ground up: generator, discriminator, latent space, and the adversarial loss that ties them together. Prerequisites included.
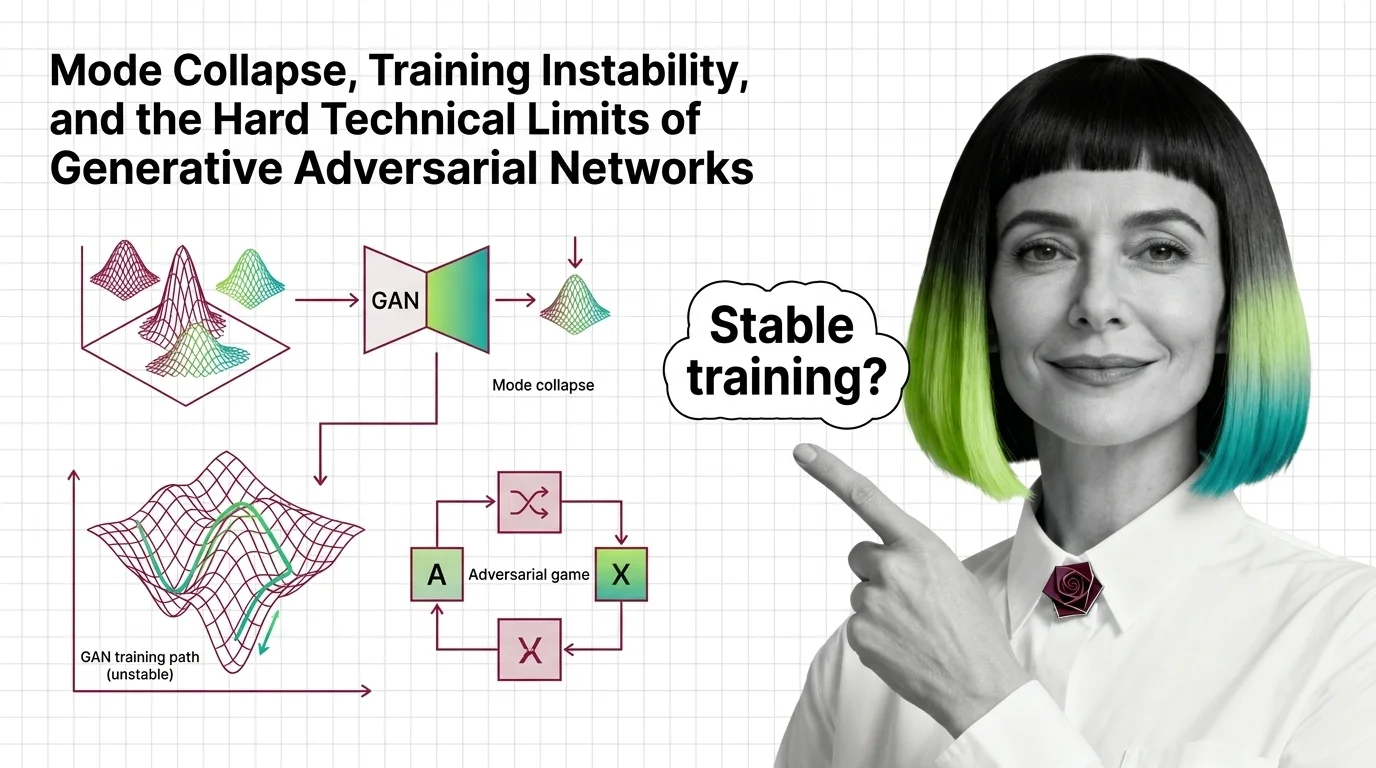
Mode collapse and training instability aren't GAN bugs — they're structural limits of adversarial training. Learn the mechanisms and the diffusion trade-off.