Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
Measuring AI model and LLM output quality — classification metrics, benchmark suites and contamination, LLM-as-a-judge, human evaluation, and ELO/arena leaderboards.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
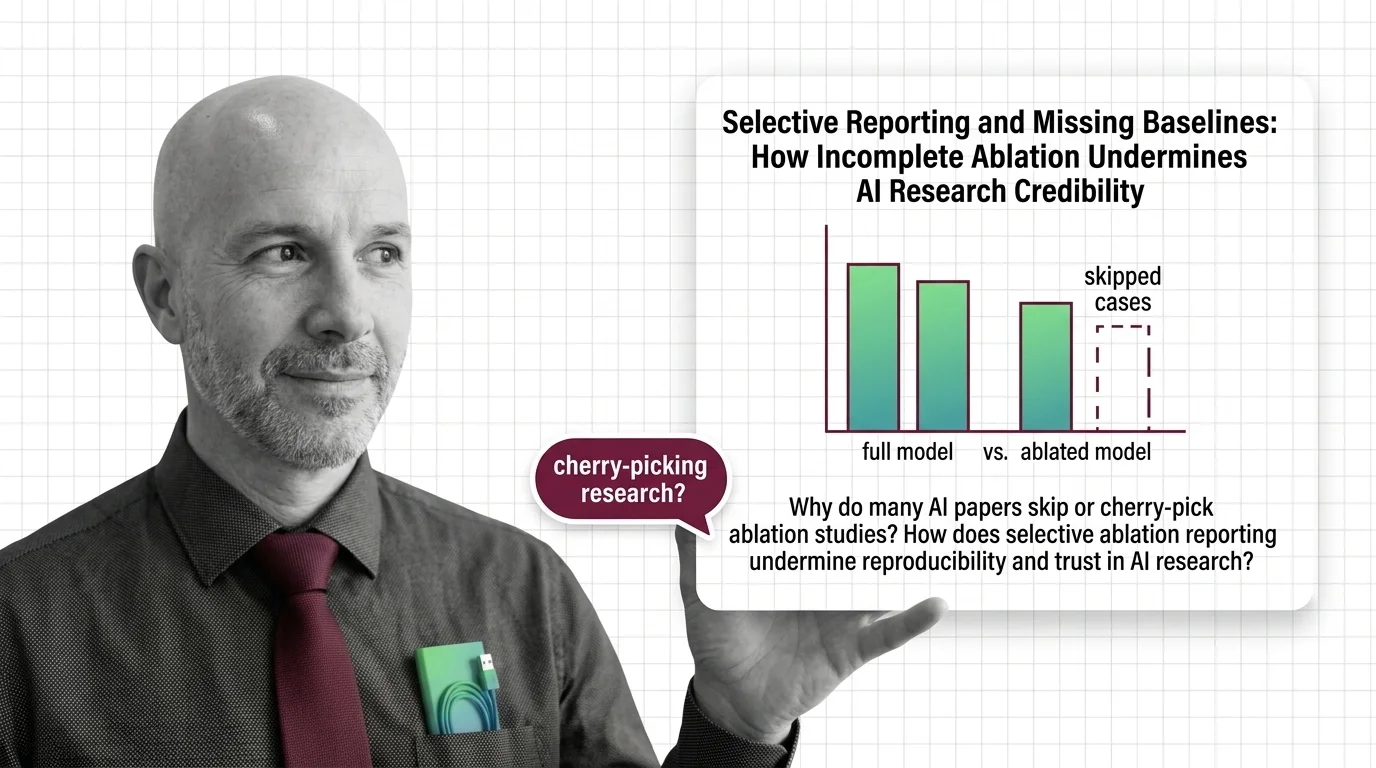
An ablation study is a systematic method for understanding why an AI system works by selectively removing or disabling …
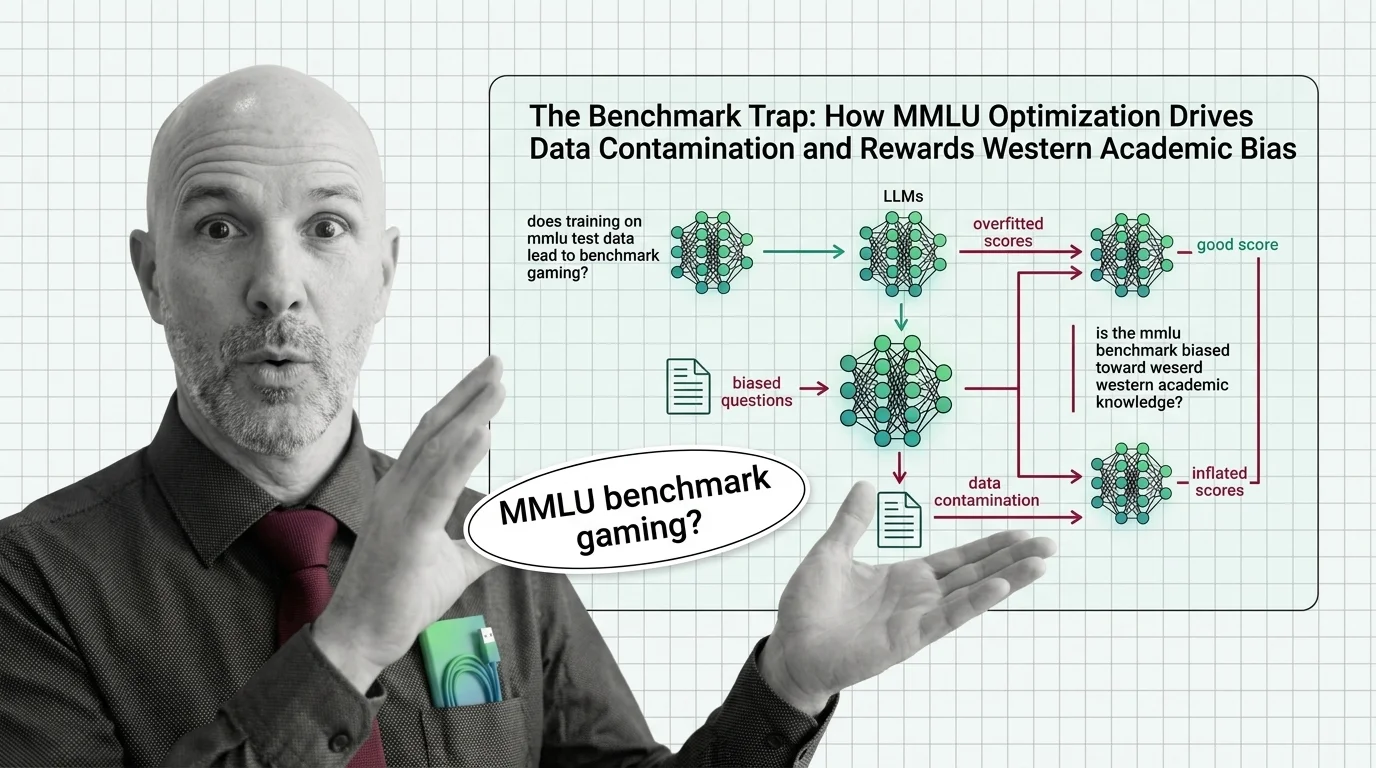
Benchmark contamination occurs when test data from evaluation benchmarks leaks into a model's training corpus, …
A confusion matrix is a table that summarizes how well a classification model performs by breaking predictions into four …
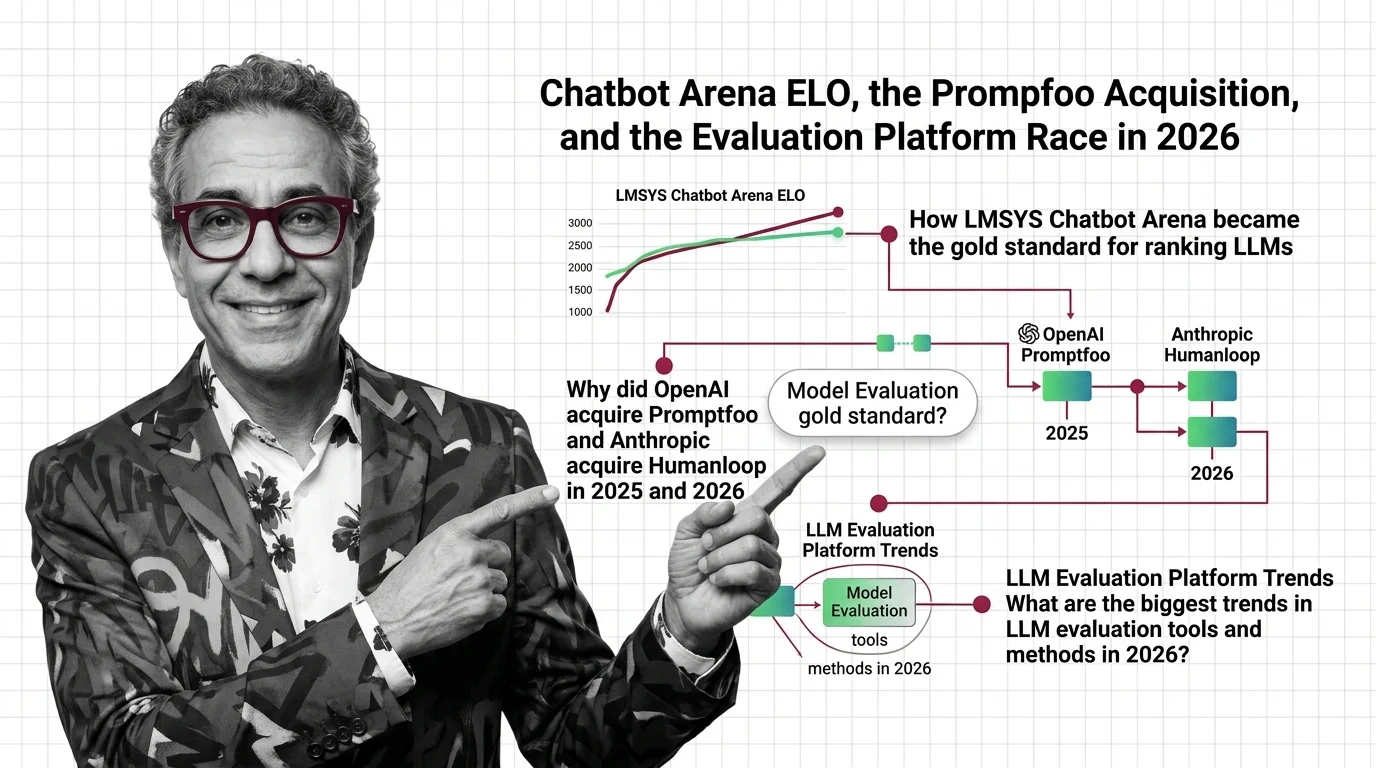
ELO Rating for LLMs adapts the chess ELO ranking system to evaluate language models through pairwise human preference …
An evaluation harness is a standardized software framework that runs language models through curated suites of …
Human evaluation for AI encompasses structured methodologies for trained human raters to assess model output quality …
LLM-as-a-Judge is a method where one large language model evaluates the output of another, scoring responses for …
MMLU (Massive Multitask Language Understanding) is a benchmark that evaluates large language models across dozens of …
Model evaluation is the process of measuring how well a large language model performs using benchmarks, human judgment, …
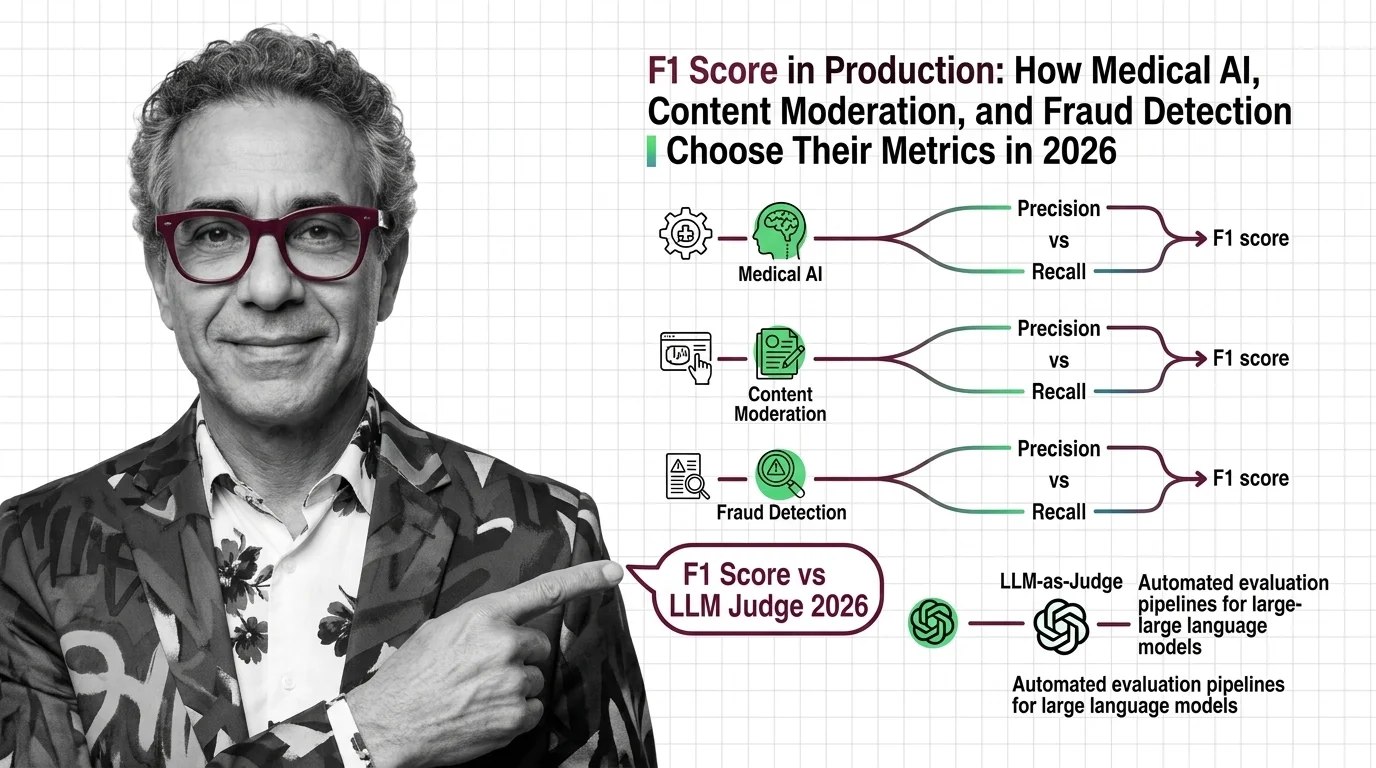
Precision, recall, and F1 score are classification metrics used to evaluate machine learning models. Precision measures …
SWE-bench is a benchmark that tests AI coding agents on real bugs and feature requests pulled from popular open-source …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Jun 24, 2026
Concepts covered
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
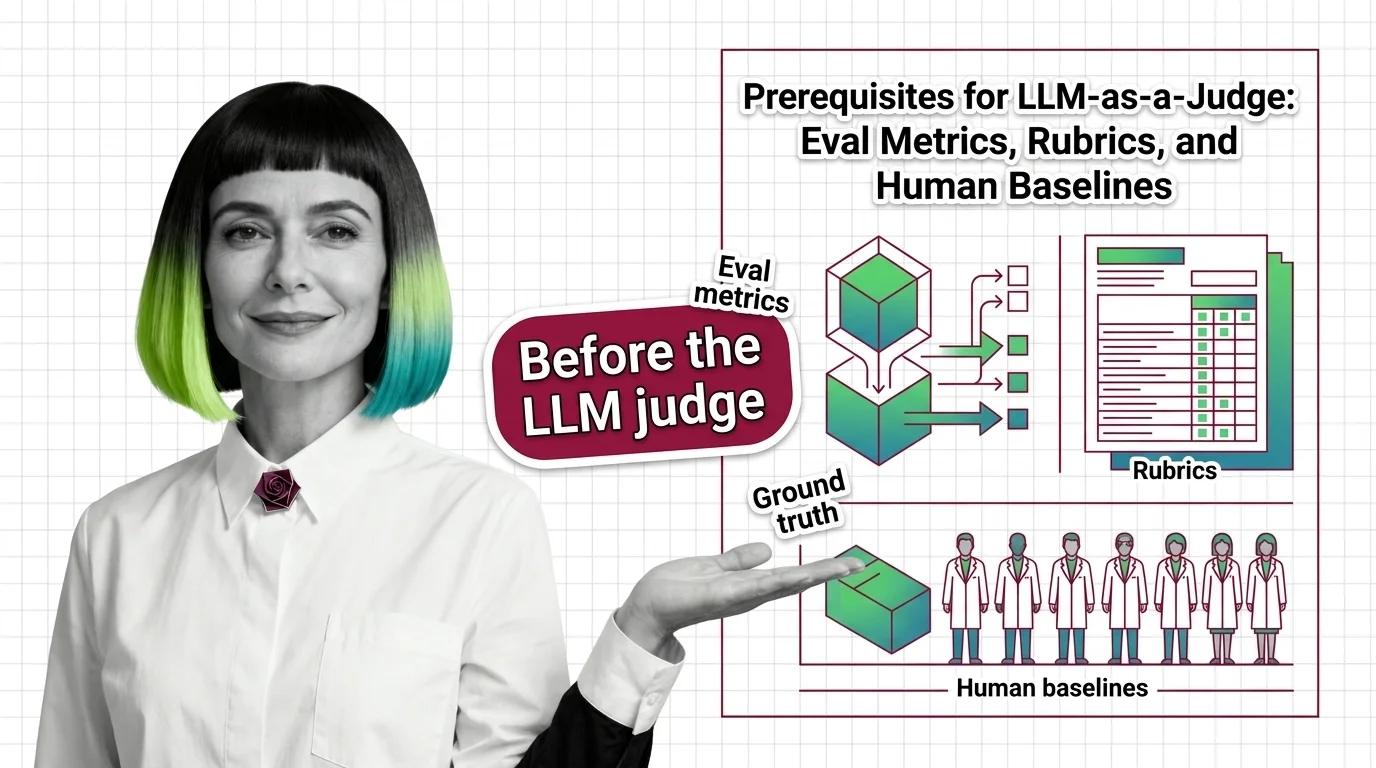
An LLM-as-a-judge is only as reliable as its scaffolding: ground-truth labels, rubrics, and a human baseline. GPT-4 judges hit 80%+ agreement on MT-Bench.

LLM-as-a-judge uses one model to grade another's output via pointwise, pairwise, or rubric scoring. Fast, but prone to position and self-preference bias.

Same model, same benchmark, different scores. Understand why evaluation harnesses diverge and how benchmark contamination undermines LLM leaderboard trust.
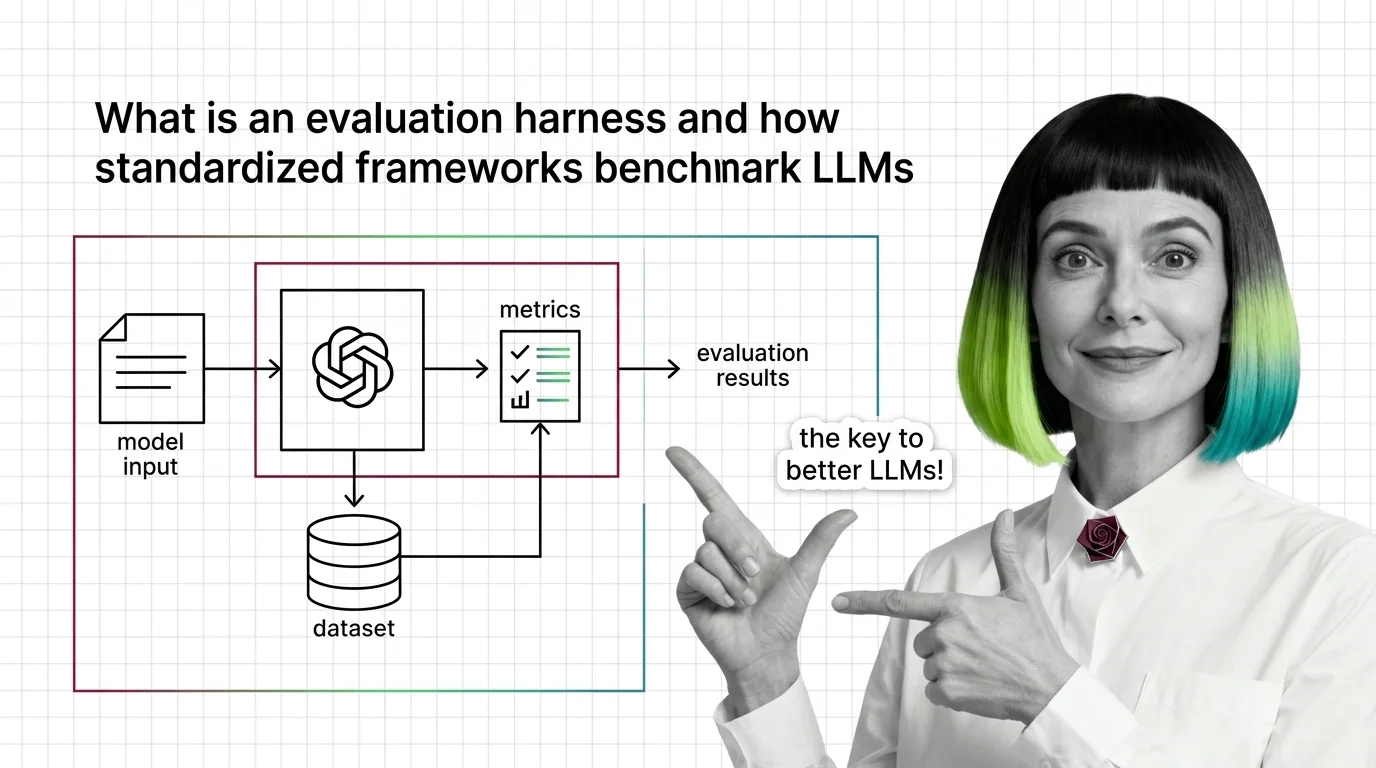
Evaluation harnesses standardize LLM benchmarking by fixing prompts, scoring, and conditions. Learn how the pipeline works and why reproducible scores matter.

Benchmark contamination and overfitting look identical in scores. Understand what n-gram overlap, deduplication, and scale reveal about detection limits.
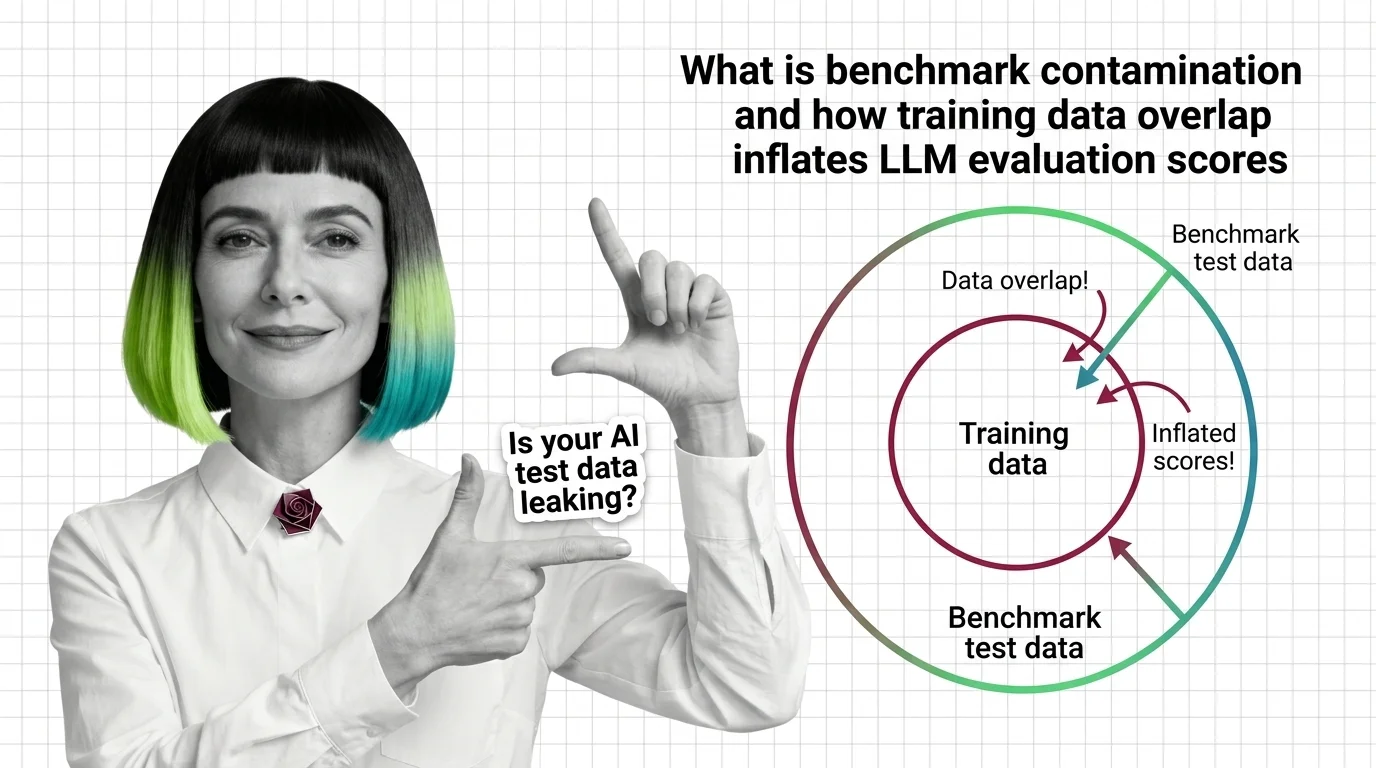
Benchmark contamination inflates LLM scores when training data overlaps with test sets. Learn how data leaks in and why memorization mimics true generalization.
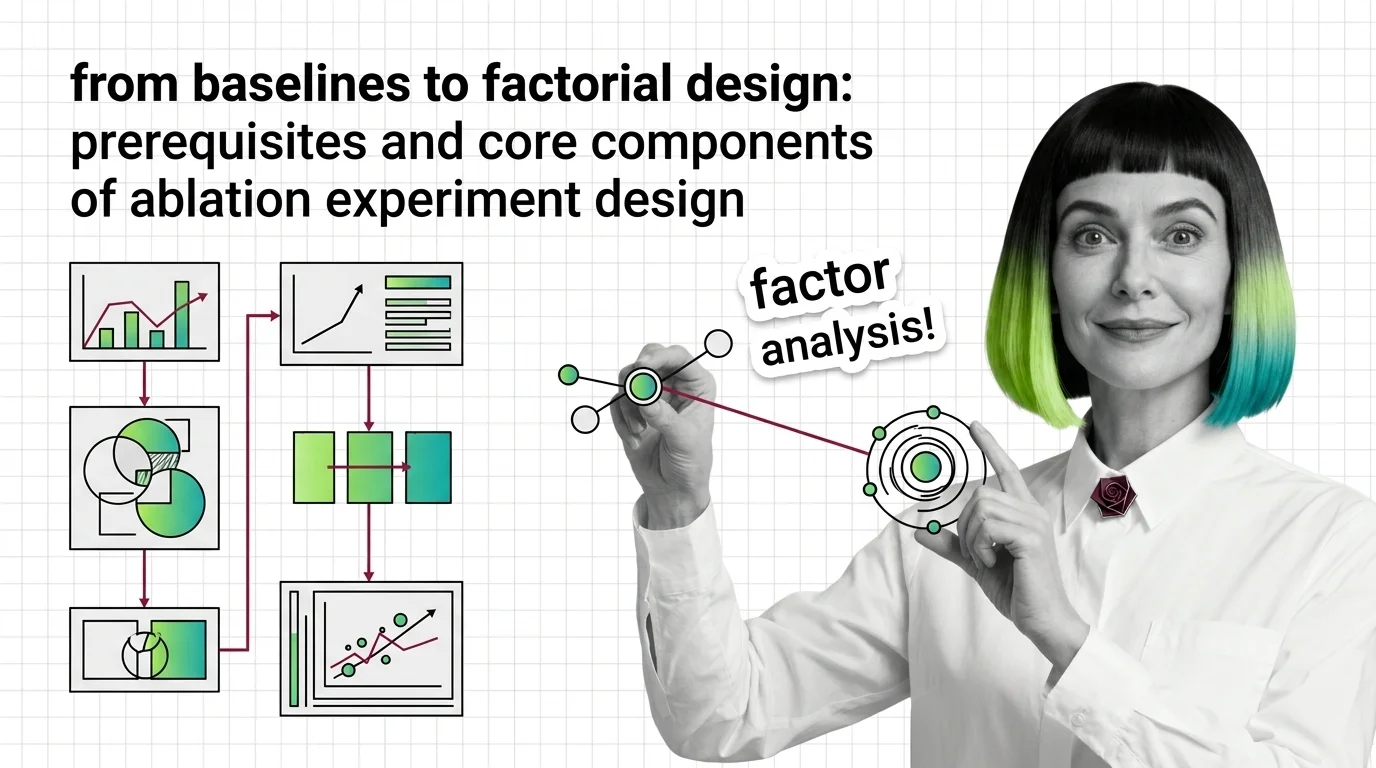
Ablation studies reveal which components matter, but only with the right baselines, controls, and statistical methods. The full experiment design, dissected.

Confusion matrices hide failures under class imbalance. Learn how normalization direction changes what you see and why MCC outperforms accuracy on skewed datasets.
Ablation studies hit a wall at scale: combinatorial explosion and non-additive interactions make exhaustive testing of billion-parameter models impossible.
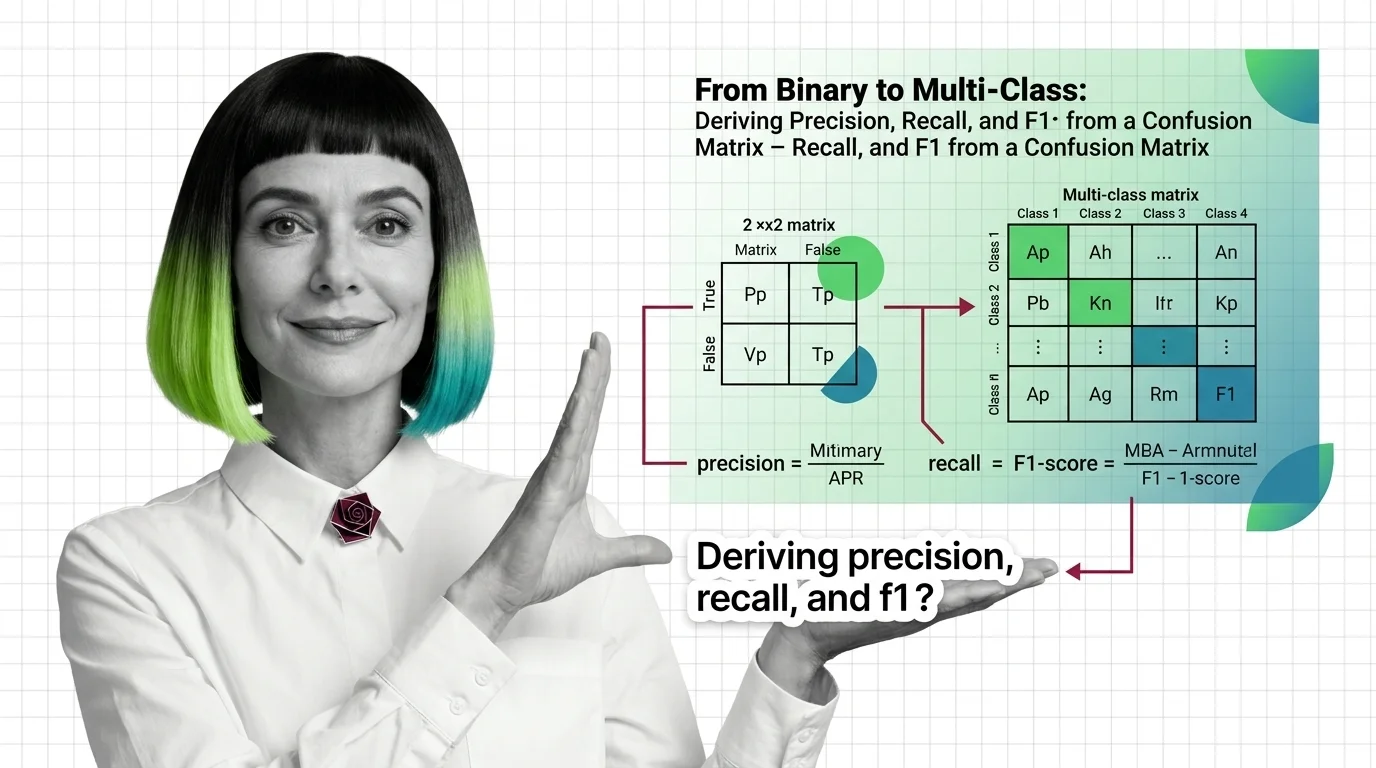
The confusion matrix scales from four binary cells to N² in multi-class problems. What the diagonal and margins record for each class.
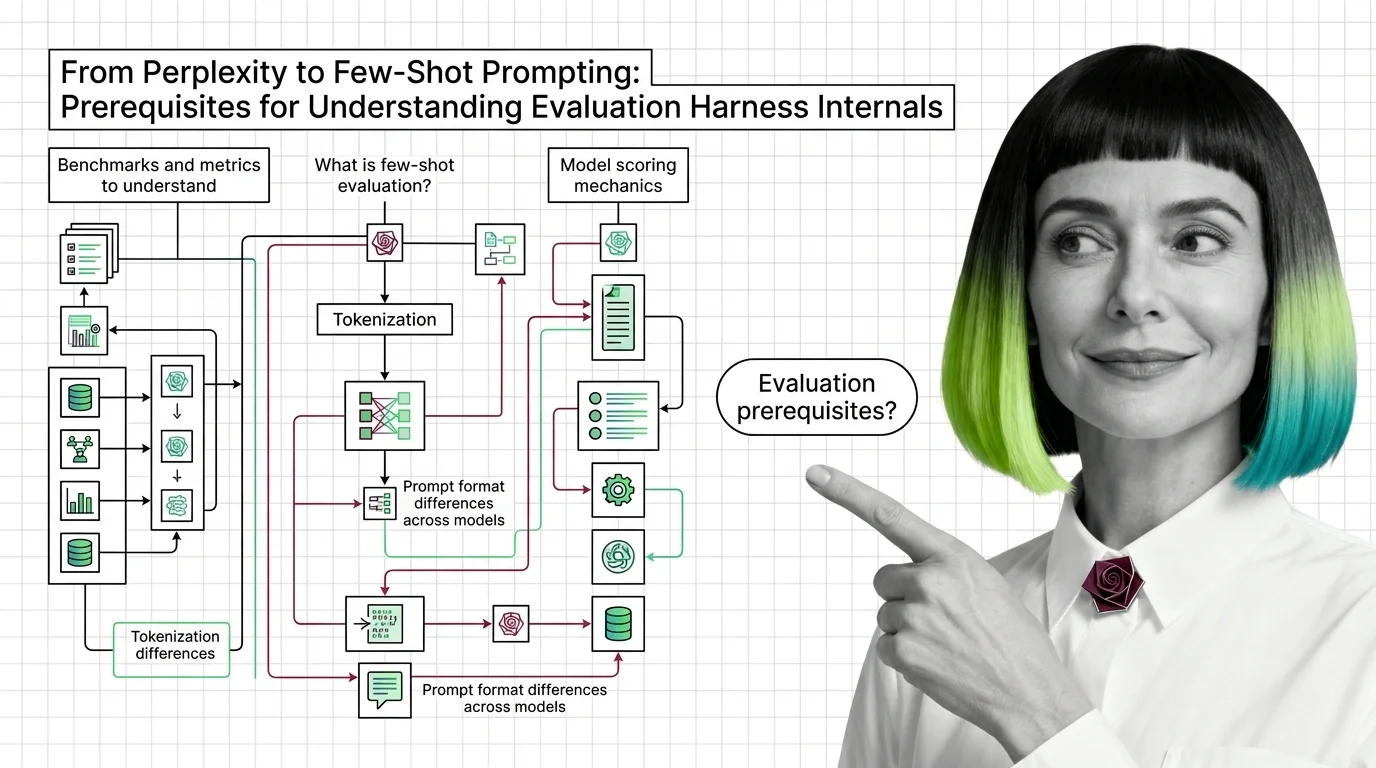
Evaluation harness scores depend on perplexity, few-shot prompting, and tokenization most teams skip. Learn the prerequisites behind meaningful benchmarks.

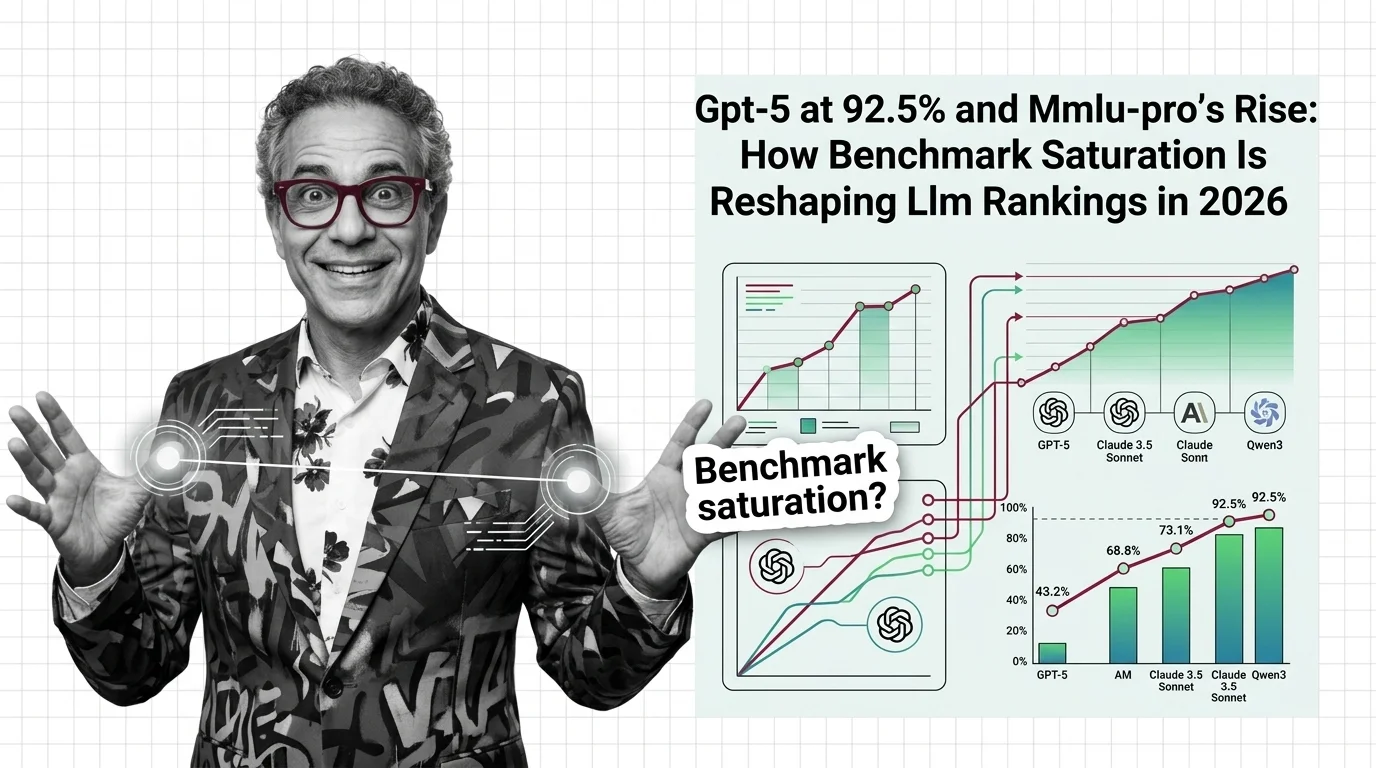
MMLU's 6.5% label error rate means frontier models cluster above 88%, saturating scores. Score saturation explains why MMLU-Pro redesigns LLM evaluation.

A confusion matrix reveals exactly where classifiers fail. Understand true positives, false negatives, and why accuracy alone misleads on imbalanced data.
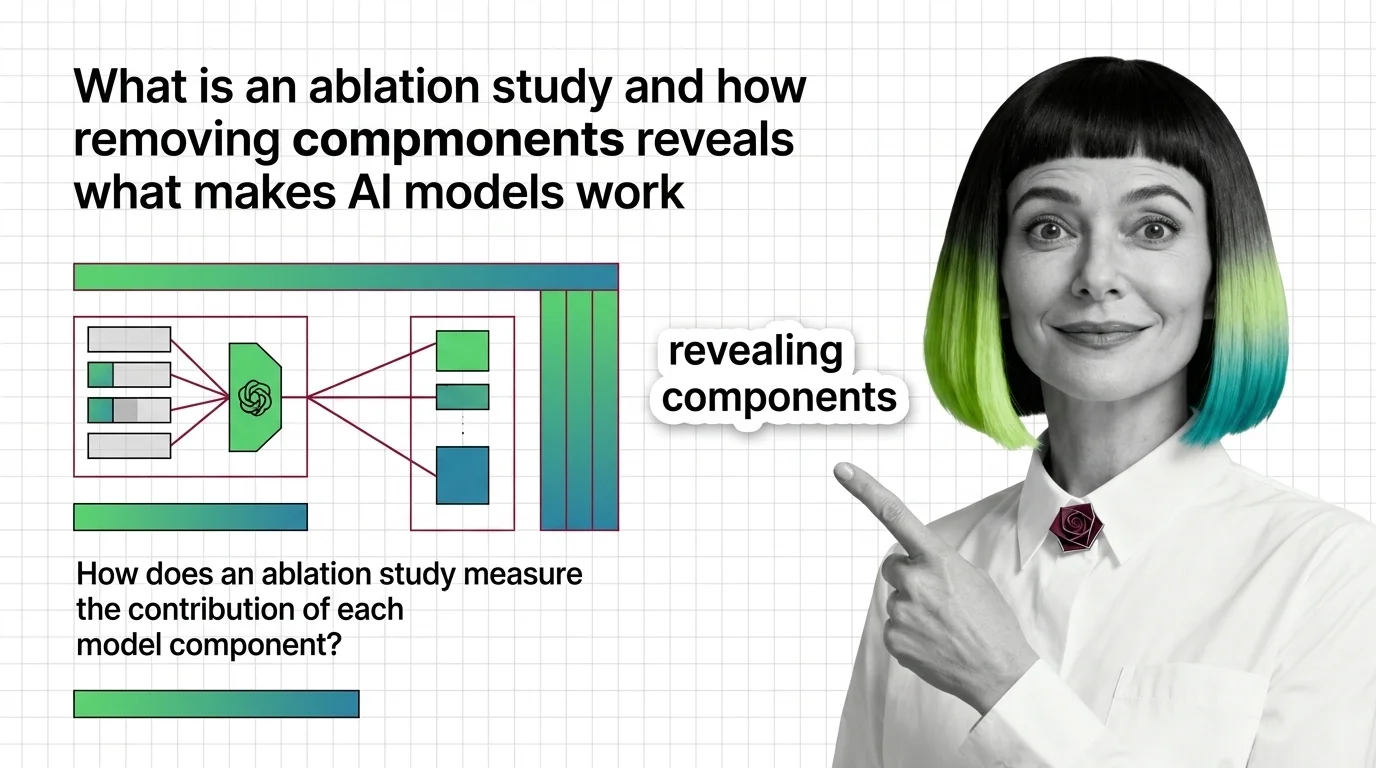
Ablation studies reveal what each model component does by removing it. Learn the experimental design and failure modes behind this core ML evaluation method.
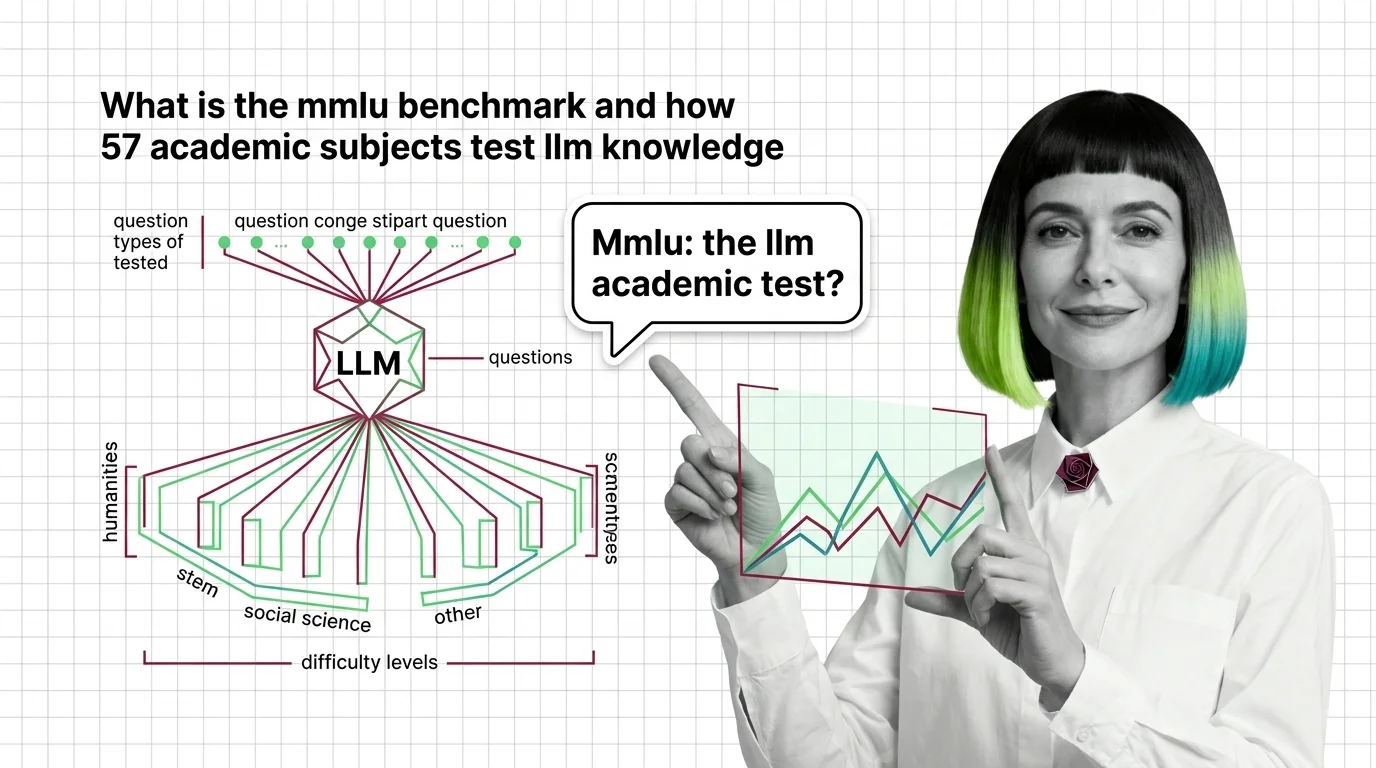
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, and why top models have outgrown it.

Precision, recall, and F1 score measure what accuracy hides. Learn how true positives, confusion matrices, and macro averaging reveal classifier performance.
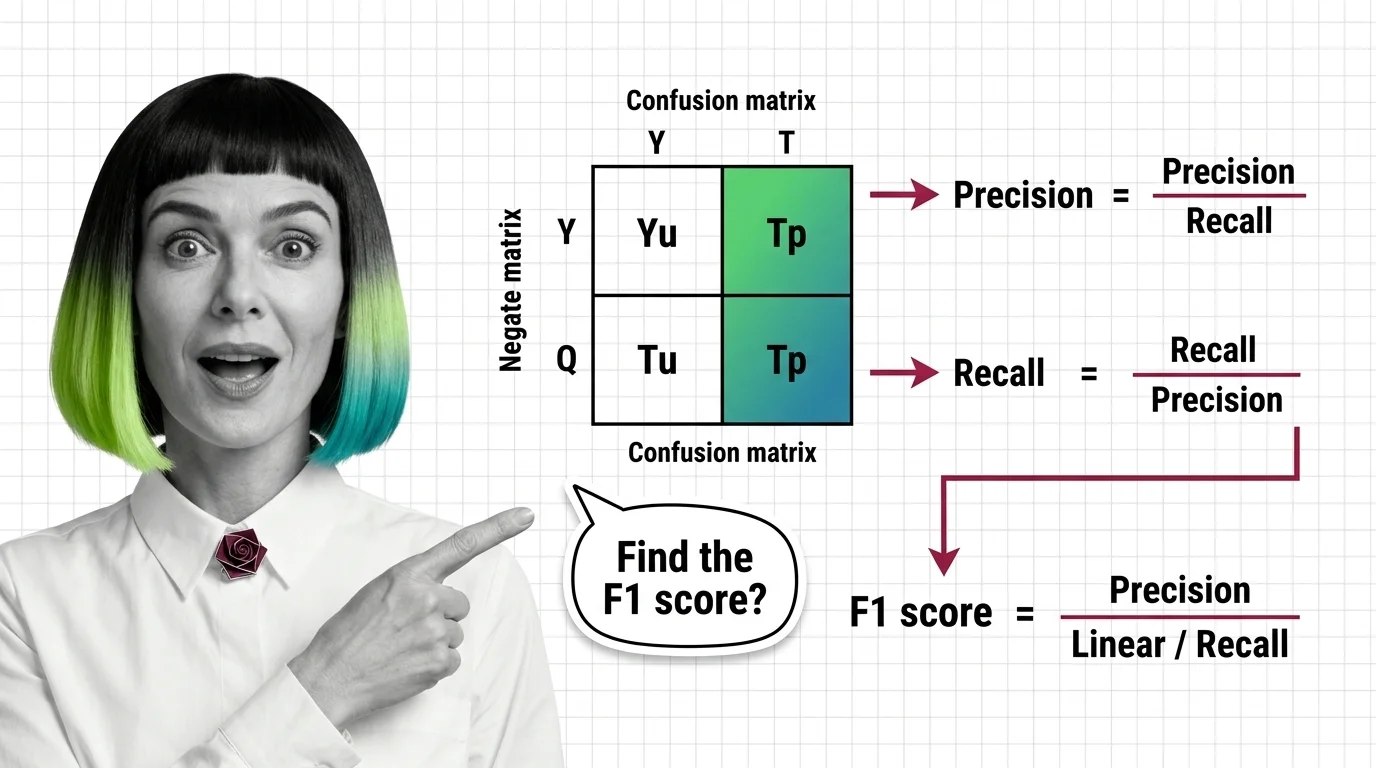
What accuracy won't show: precision, recall, and F1 score expose true classifier performance. The confusion matrix explains why the harmonic mean matters.

F1 score hides classifier failures on imbalanced datasets by ignoring true negatives. Learn why MCC and PR-AUC reveal problems that harmonic averaging conceals.

Benchmark contamination inflates LLM scores while real-world performance lags. Learn why metric gaming and saturated tests are breaking model evaluation in 2026.

Perplexity, BLEU, ROUGE, and Elo measure fundamentally different properties of language models. Learn when each metric applies, where they diverge, and what they hide.

Model evaluation combines benchmarks, automated metrics, and human judgment to measure LLM quality. Learn why high scores mislead and what the math underneath reveals.