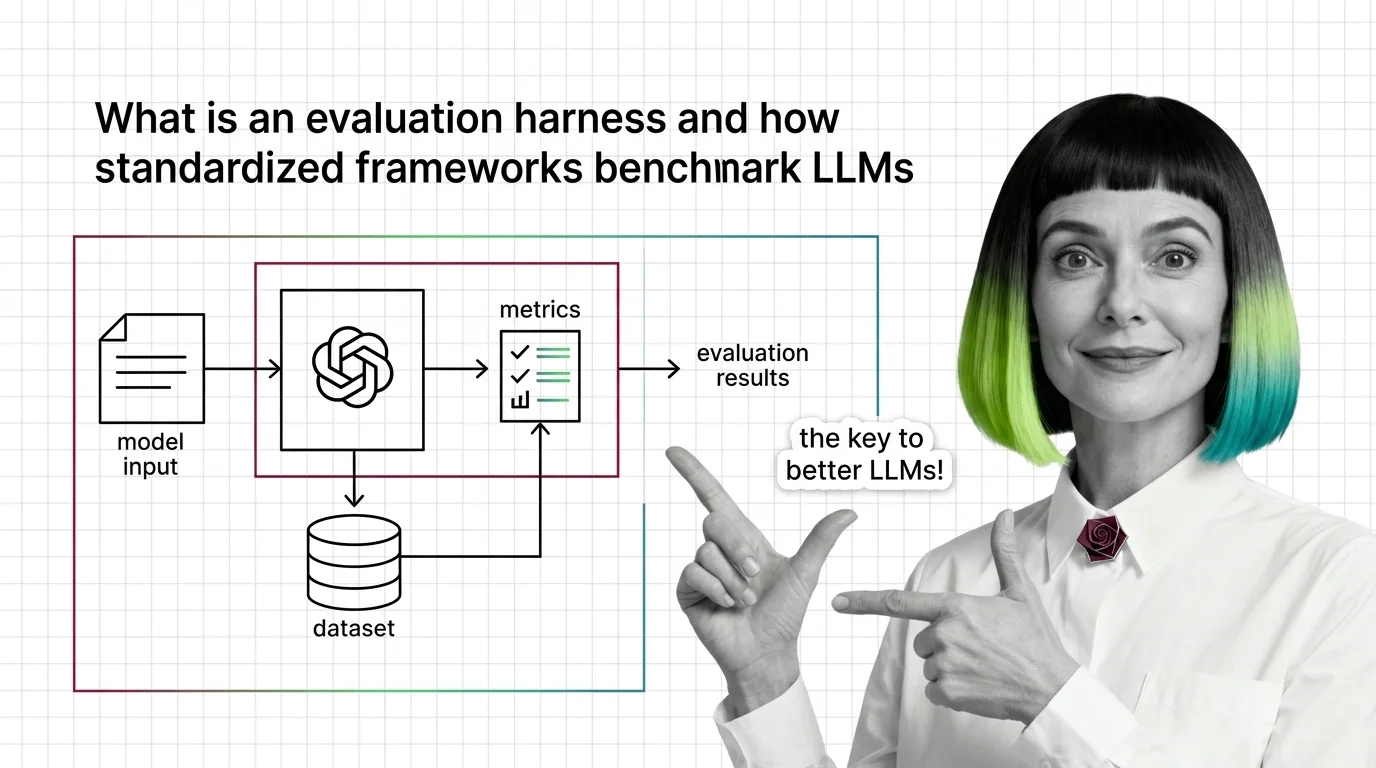
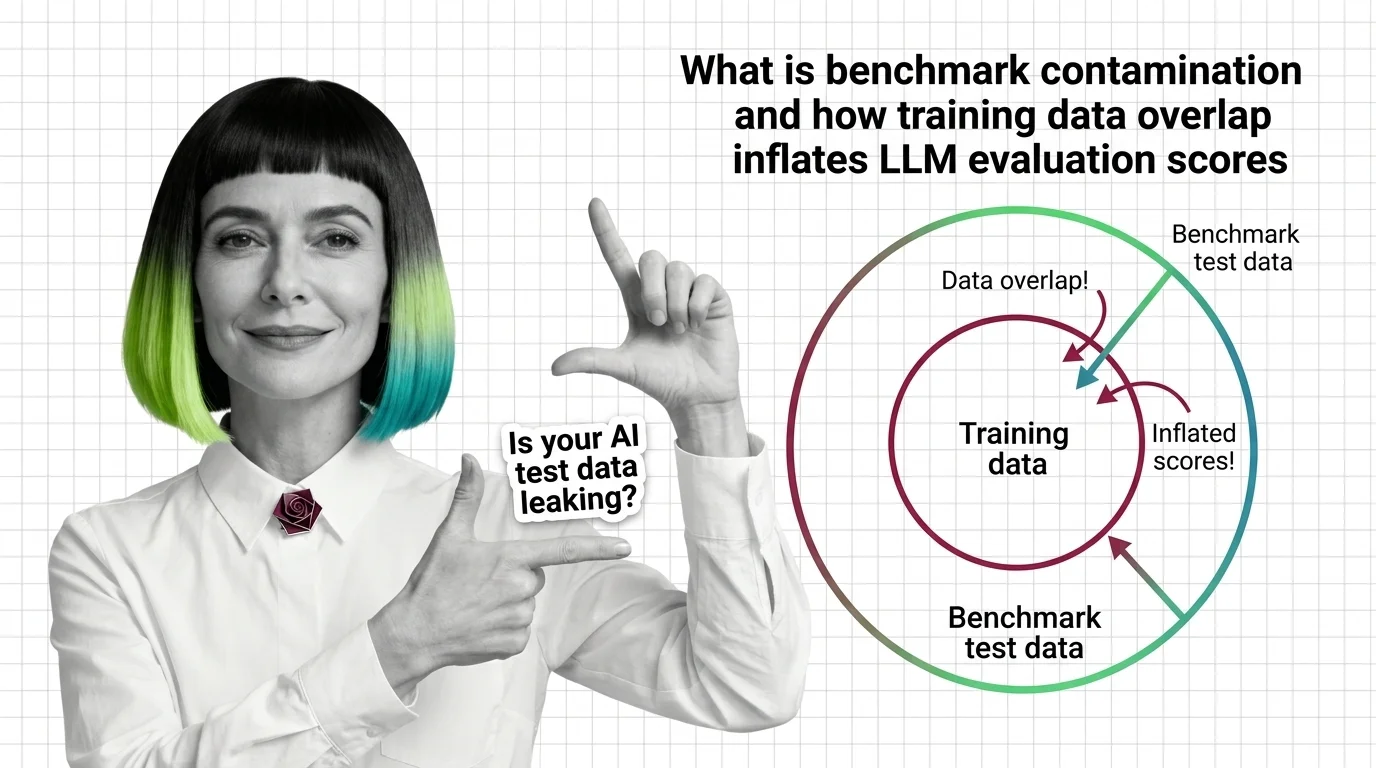
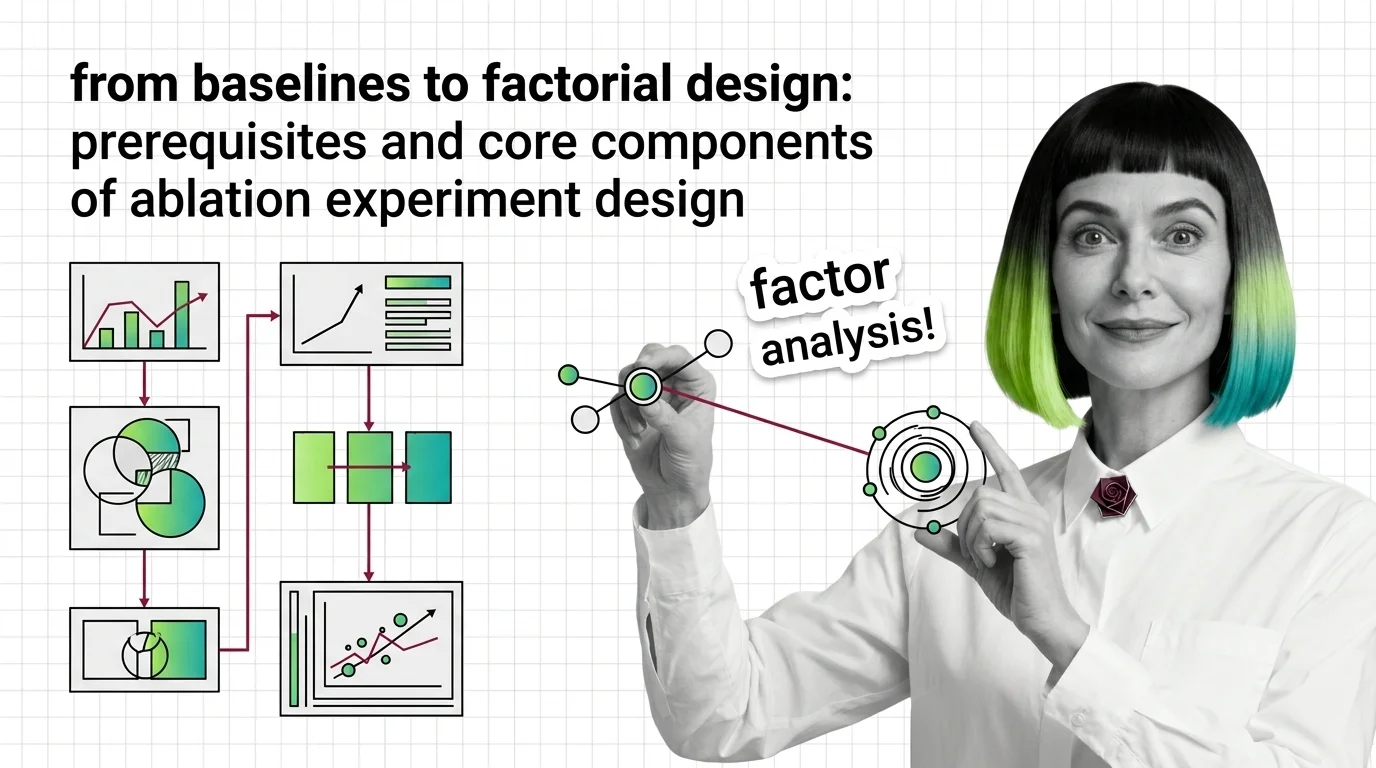
Benchmark Contamination, Score Divergence, and the Technical Limits of LLM Evaluation Harnesses
Same model, same benchmark, different scores. Understand why evaluation harnesses diverge and how benchmark contamination undermines LLM leaderboard trust.