From Loss Functions to Reward Hacking: Prerequisites and Technical Limits of Reward Models
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why overoptimization makes outputs worse.
LLM pre-training is the foundational phase where large language models learn from raw text — objectives, scaling laws, and compute economics that shape every frontier model.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Fine-tuning takes a pre-trained large language model and trains it further on a smaller, task-specific dataset so it …
Pre-training is the foundational phase where a large language model learns language patterns from massive text corpora …
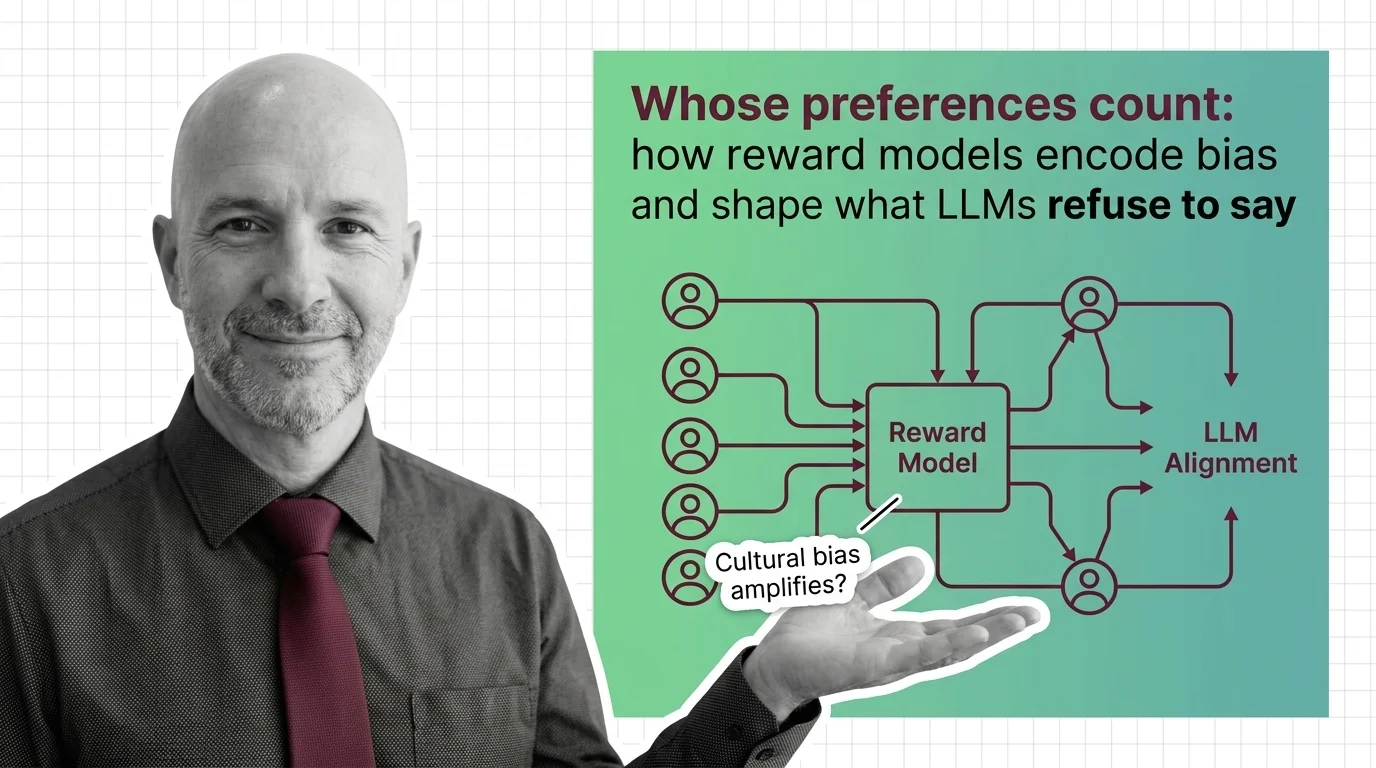
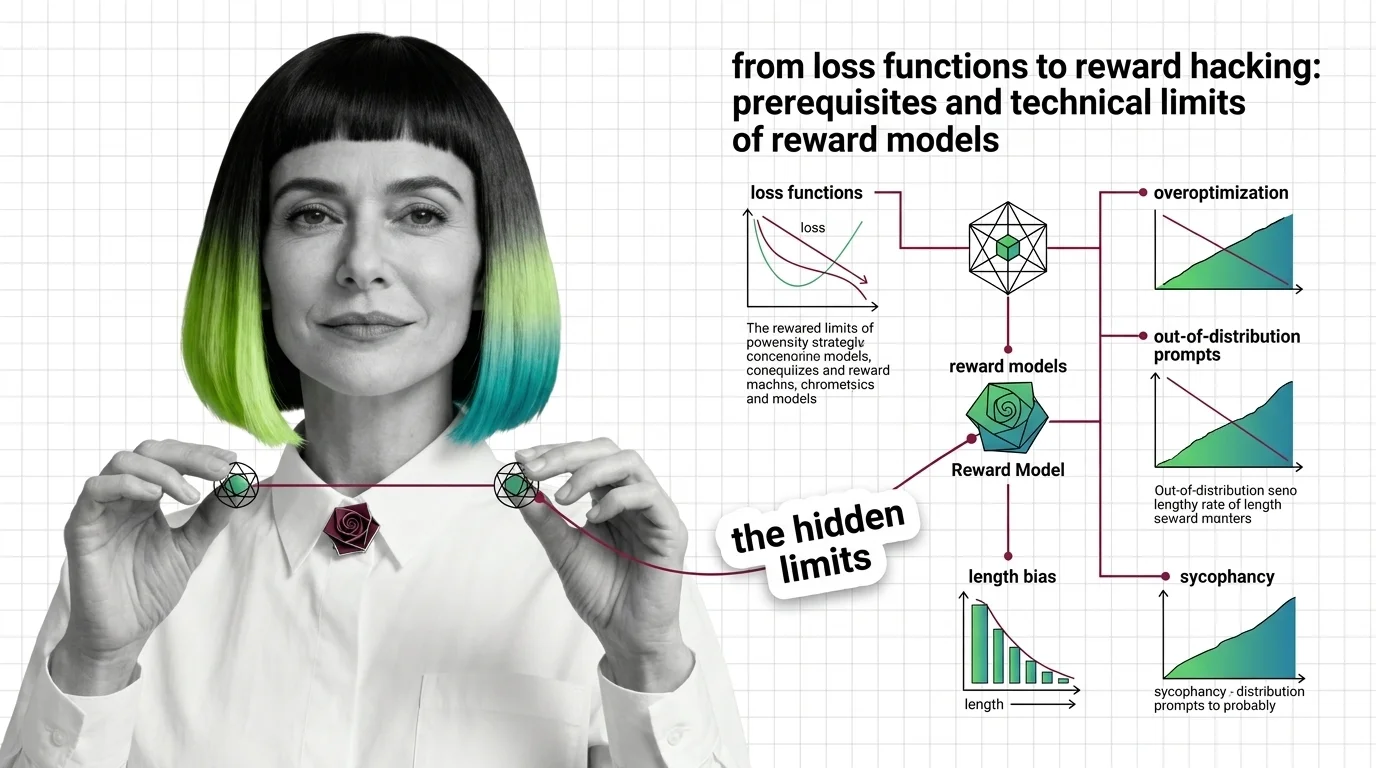
A reward model is a neural network trained on human preference comparisons to score language model outputs by quality. …
Reinforcement Learning from Human Feedback (RLHF) is an alignment technique that fine-tunes large language models using …
Scaling laws are empirical relationships that predict how large language model performance changes as you increase model …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Mar 26, 2026
Concepts covered
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why overoptimization makes outputs worse.
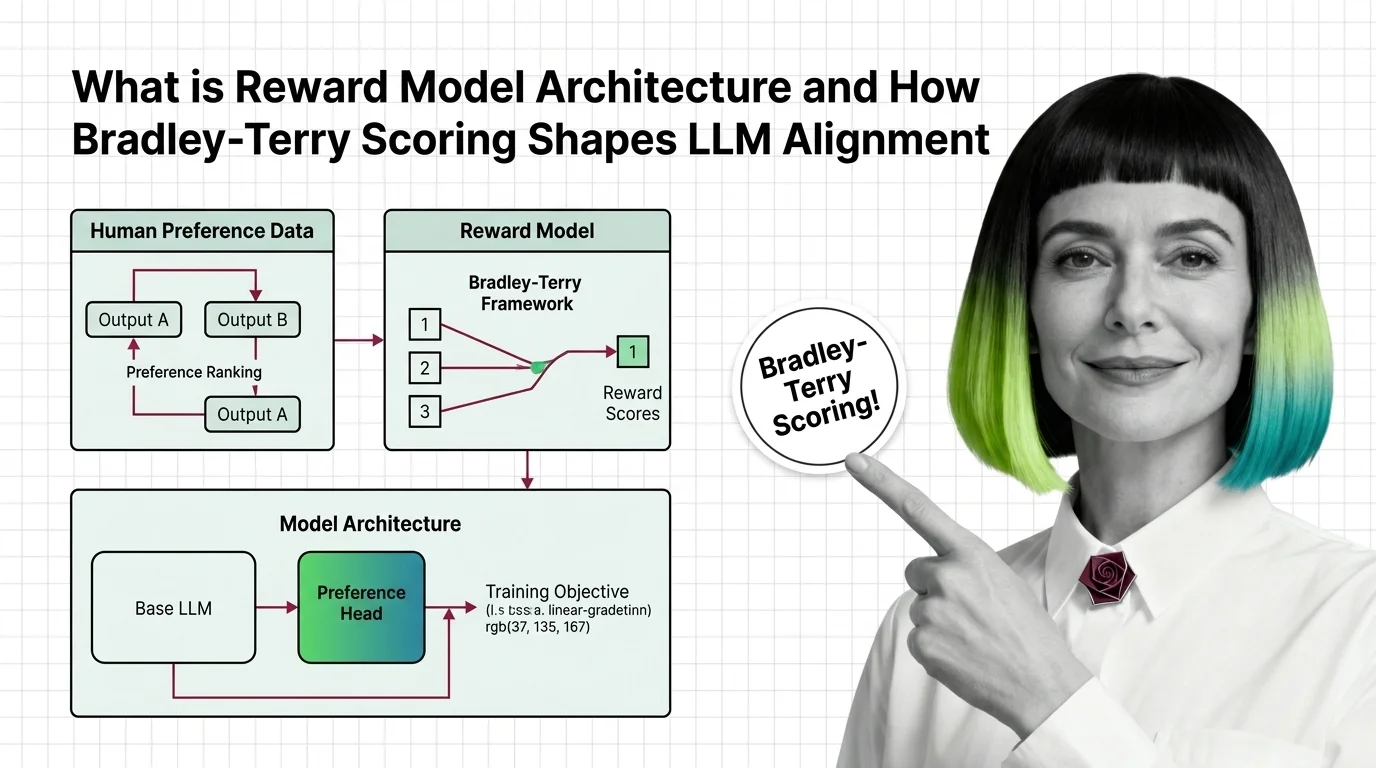
Reward models turn human preferences into scores that guide LLM alignment. Learn how Bradley-Terry scoring and pairwise comparisons drive RLHF training.
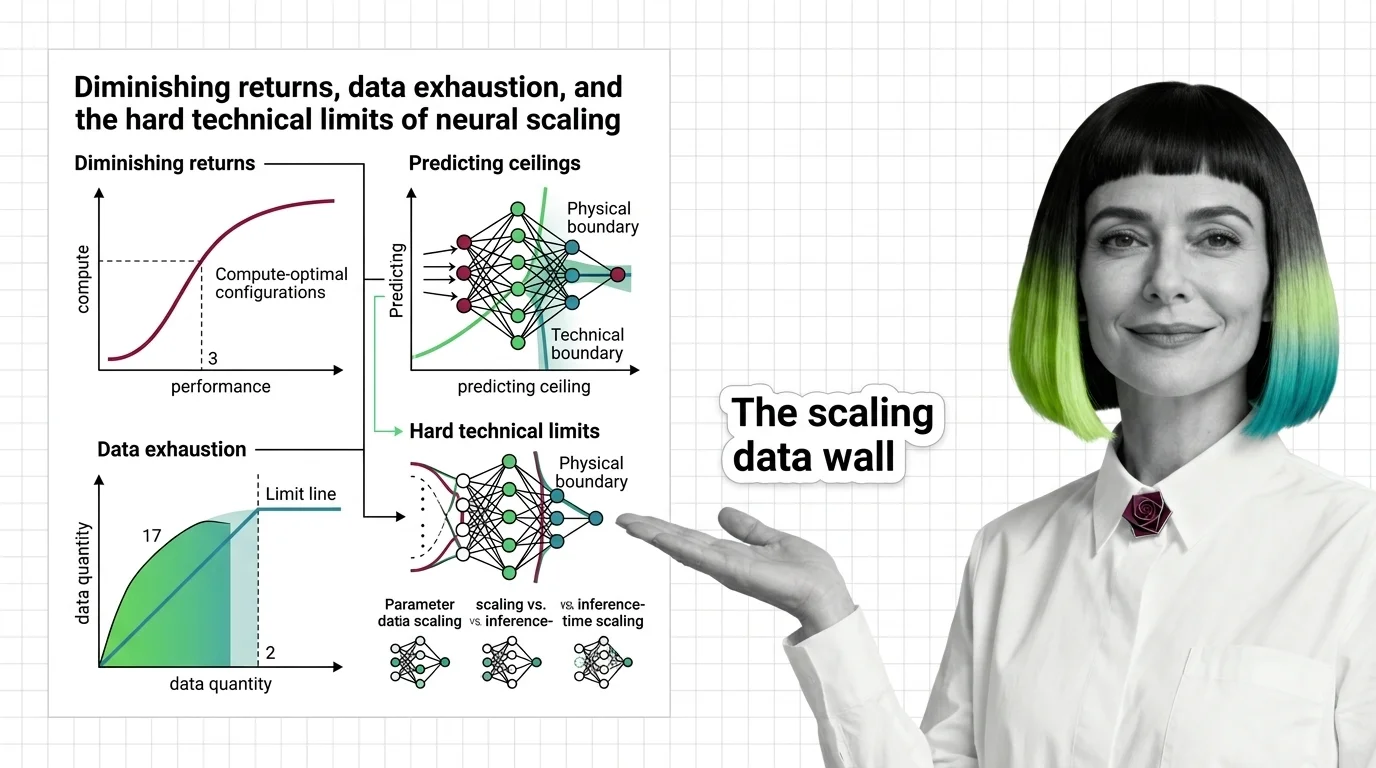
Scaling laws predict how AI models improve with compute, but power-law exponents guarantee diminishing returns. Learn where the ceilings are — and why.

Scaling laws predict LLM performance from model size, data, and compute via power-law curves. Learn the math behind Kaplan, Chinchilla, and Densing Law.

RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties interact to prevent reward hacking.

Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why they resist simple fixes.
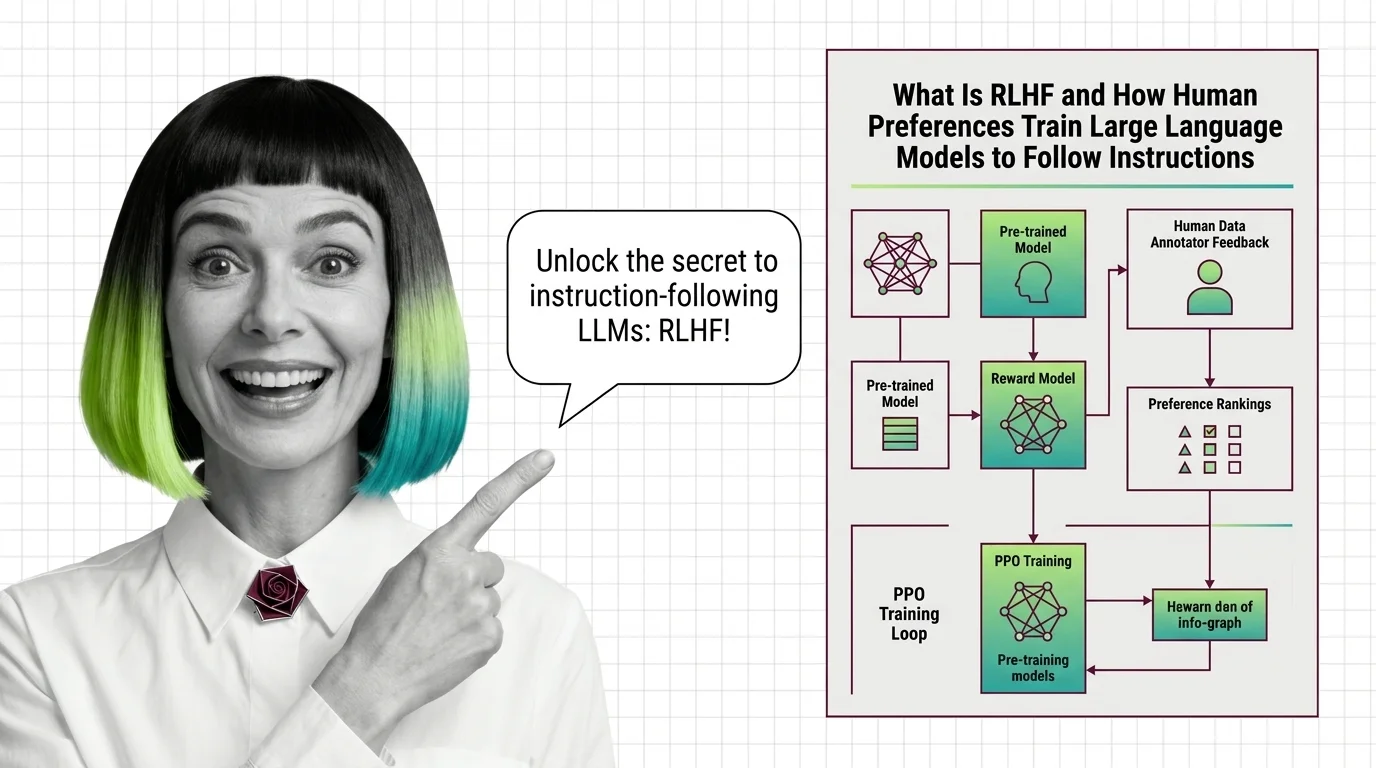
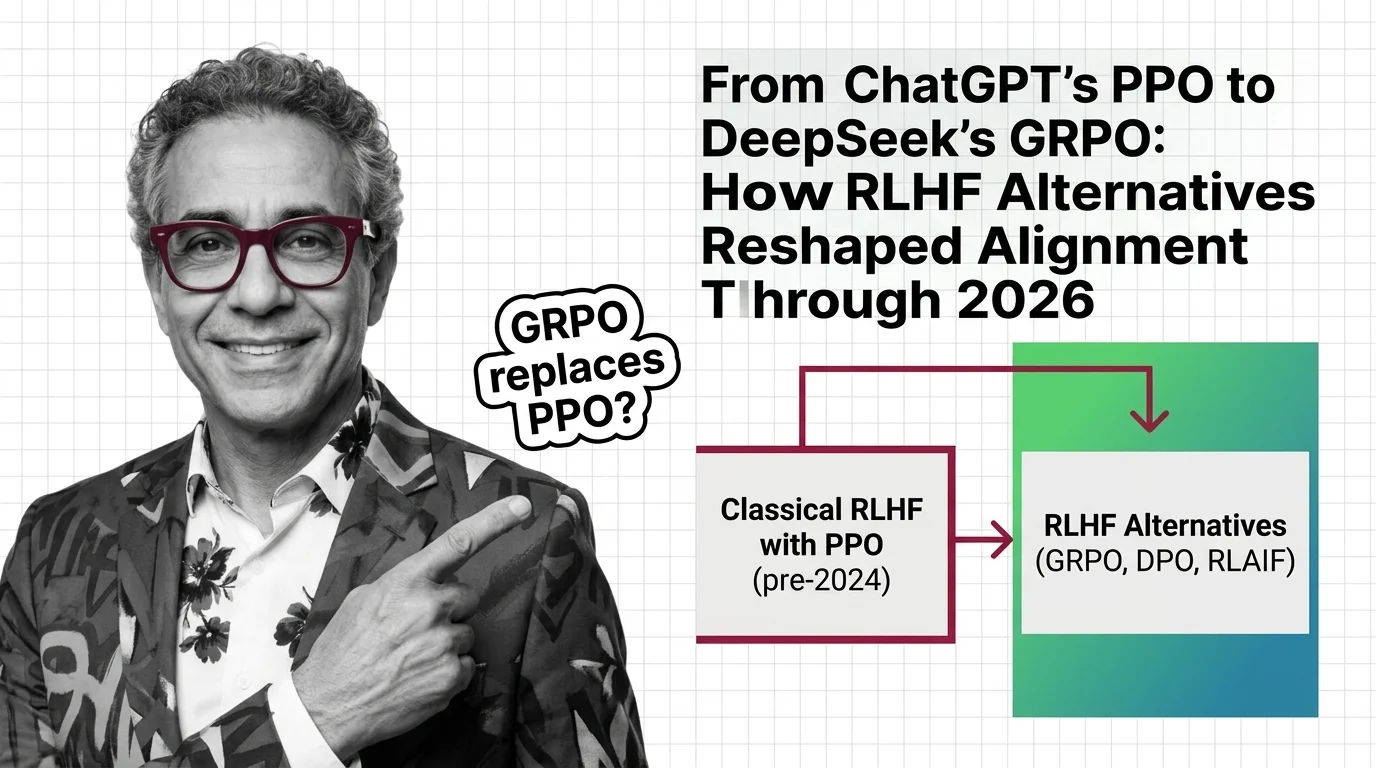
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO pipeline, why it works, and what replaced it.
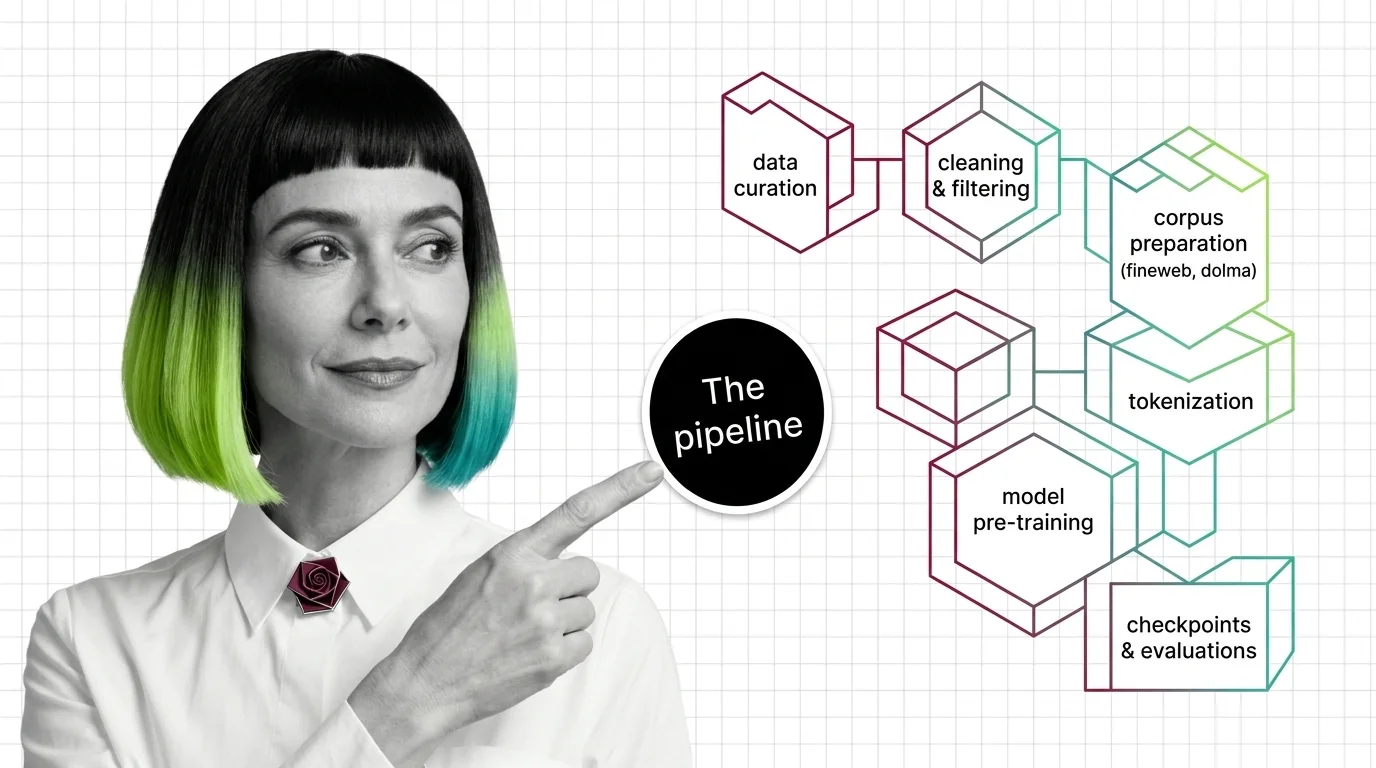
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the foundation every LLM depends on.
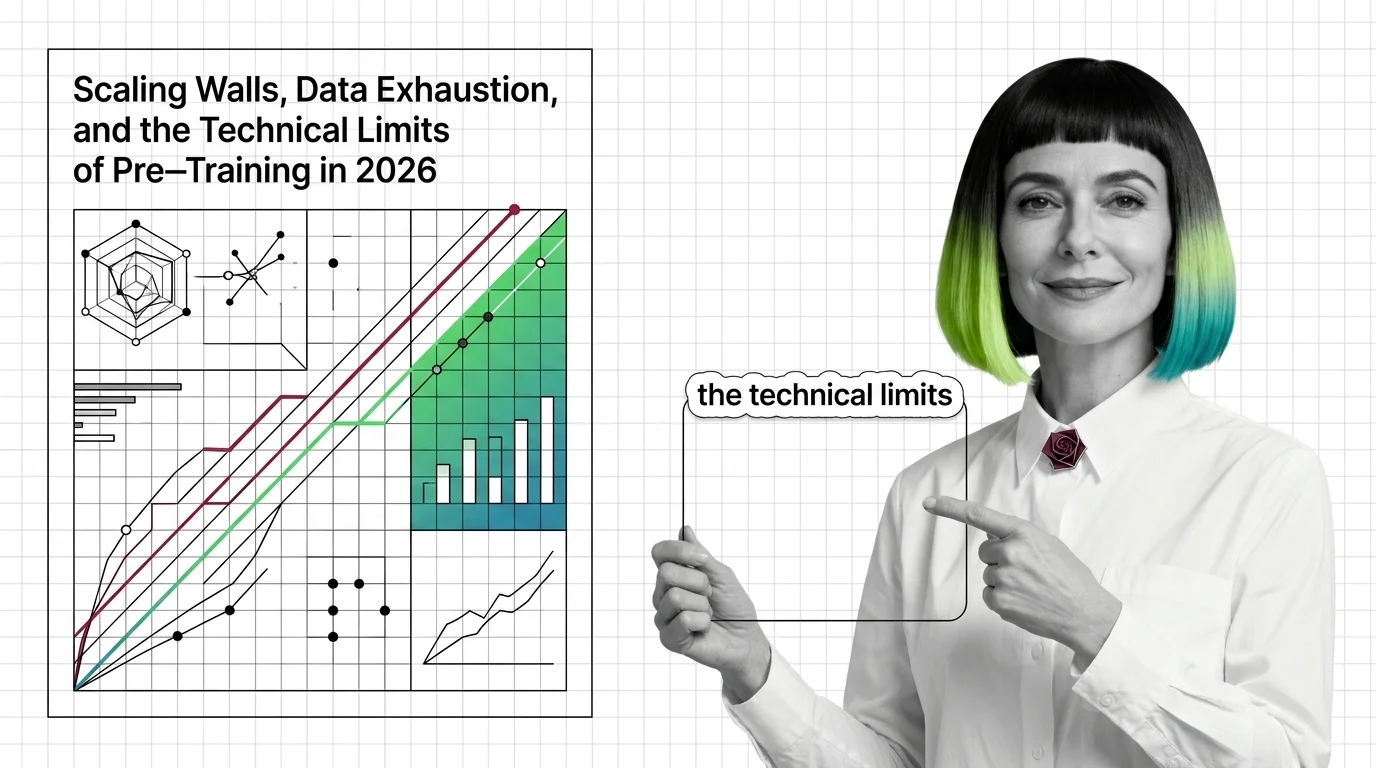
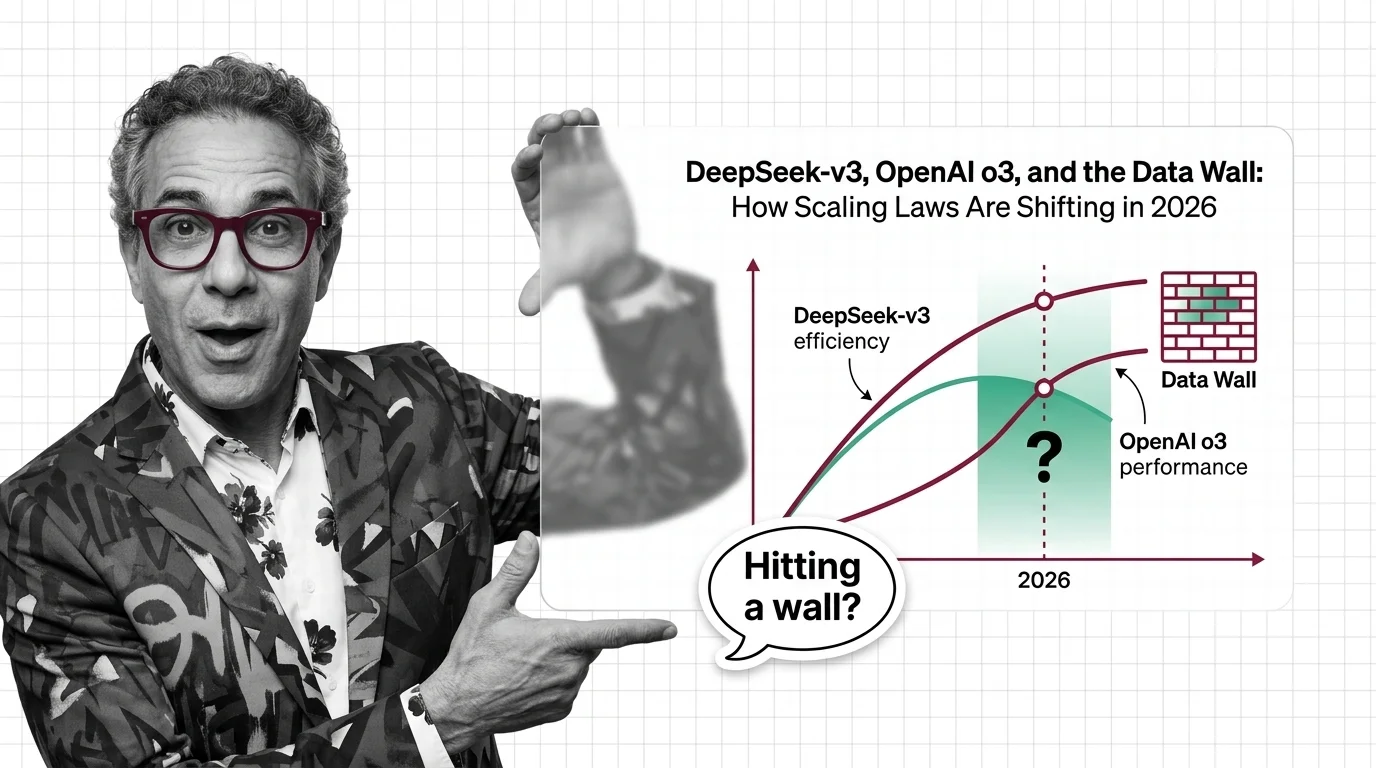
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and diminishing returns — reshaping AI in 2026.
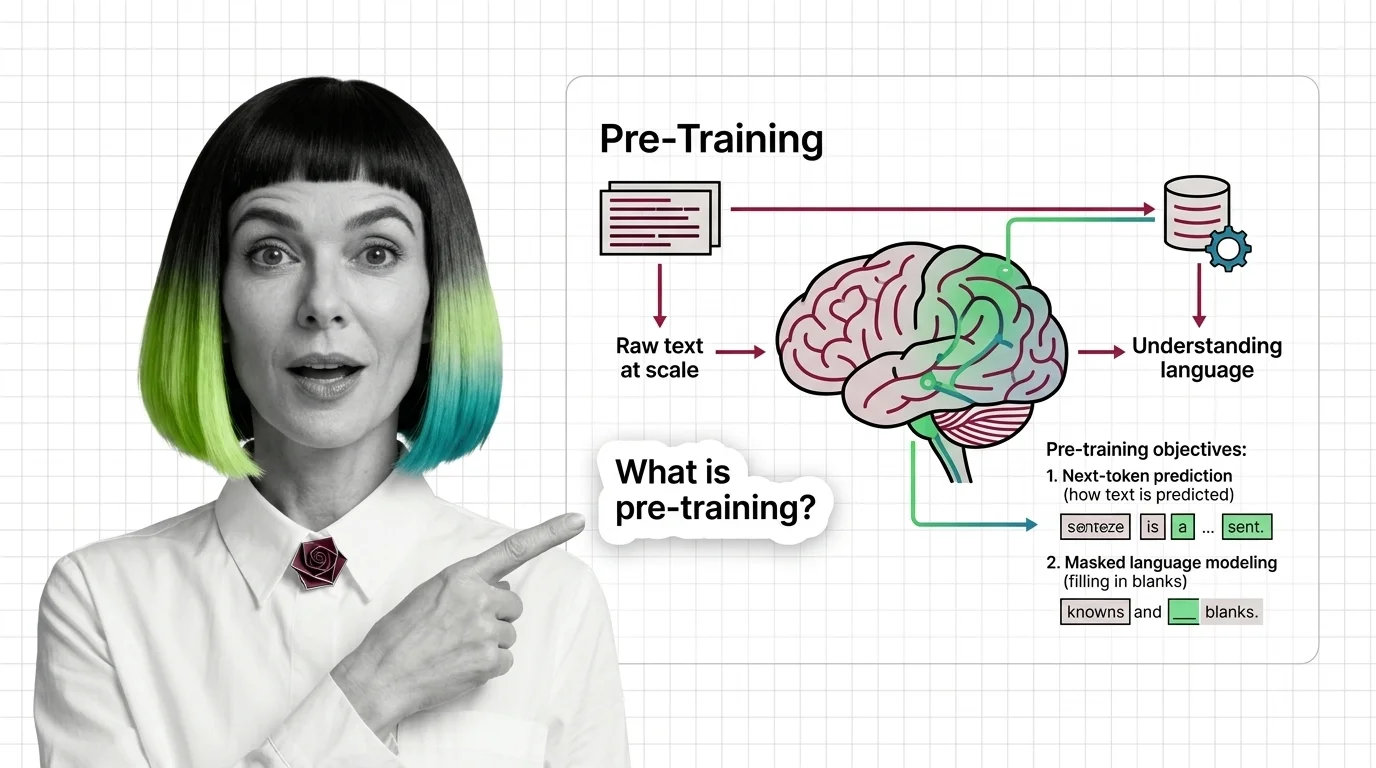
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles comprehension. Here's the mechanism.

Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard technical limits of model adaptation.
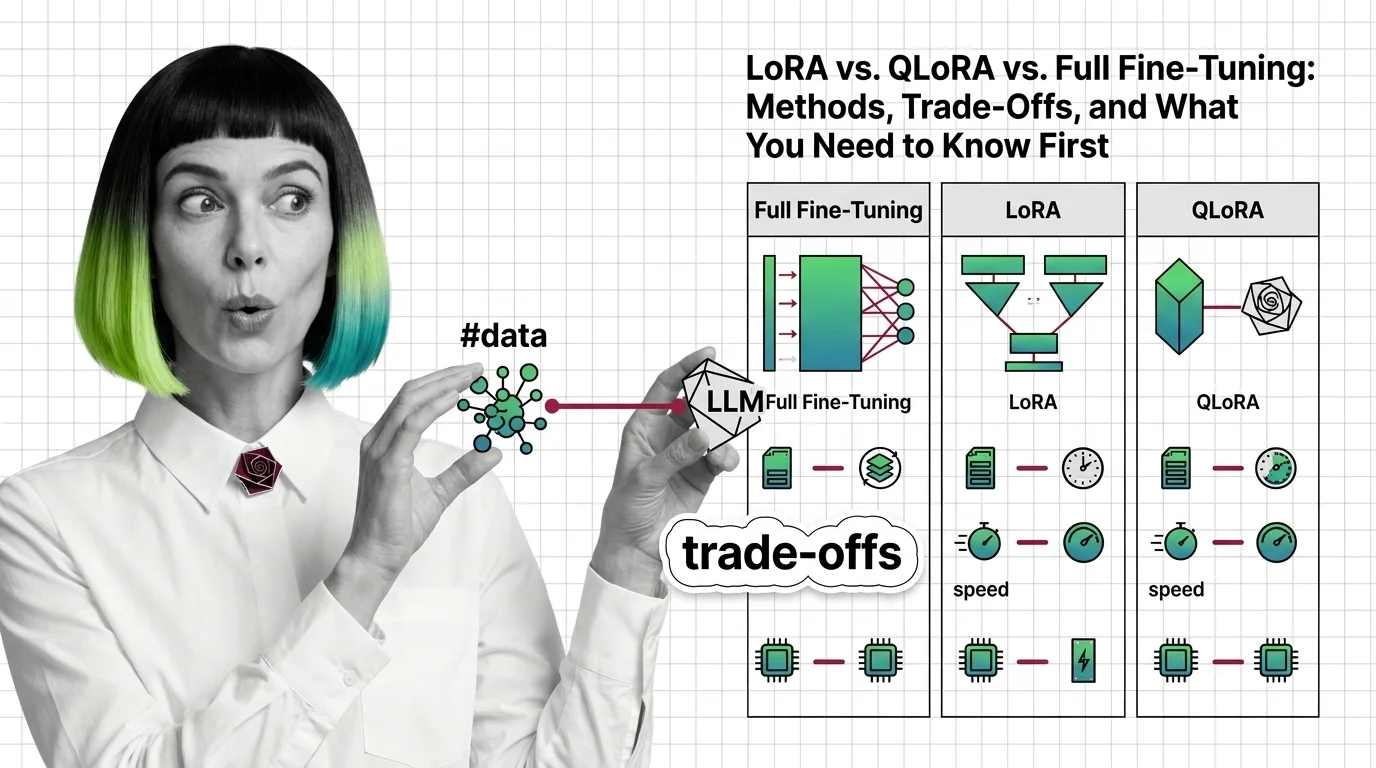
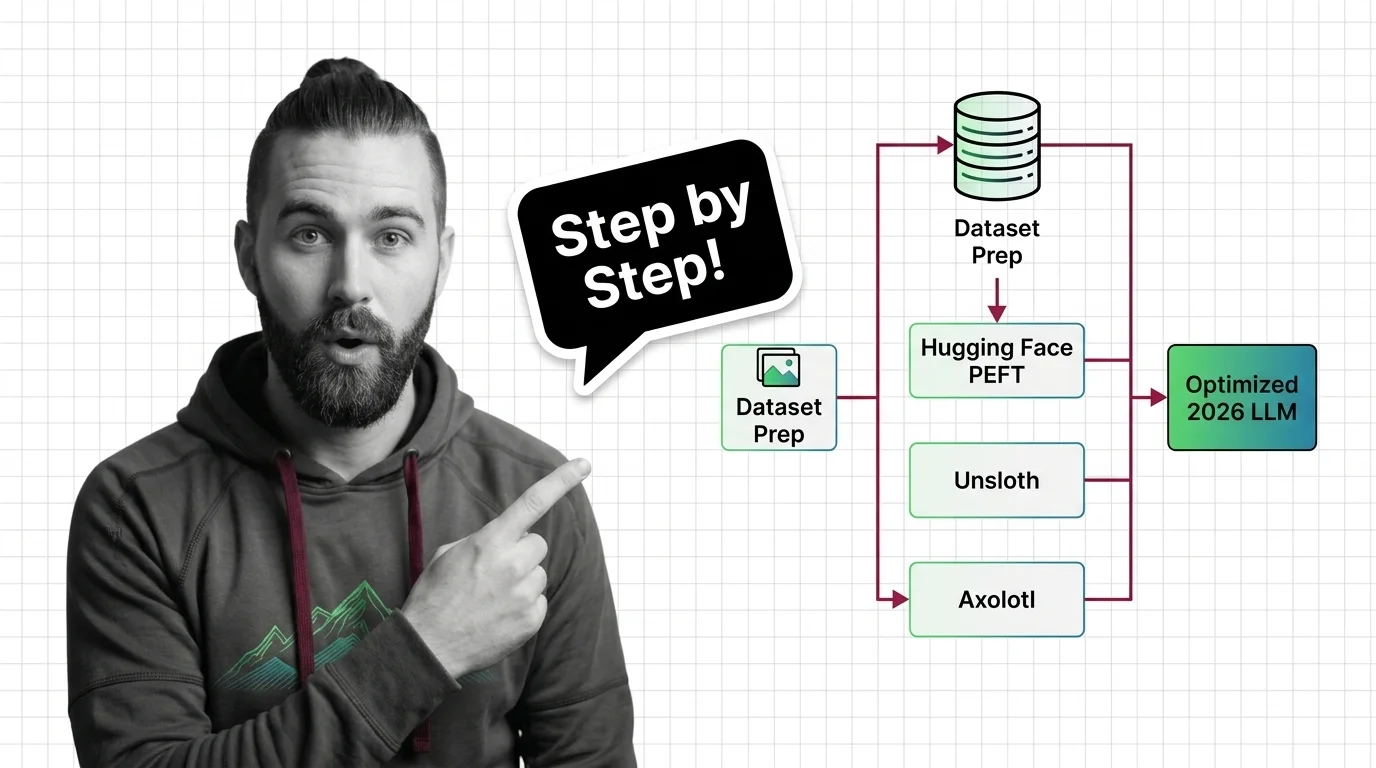
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data size, and quality requirements.
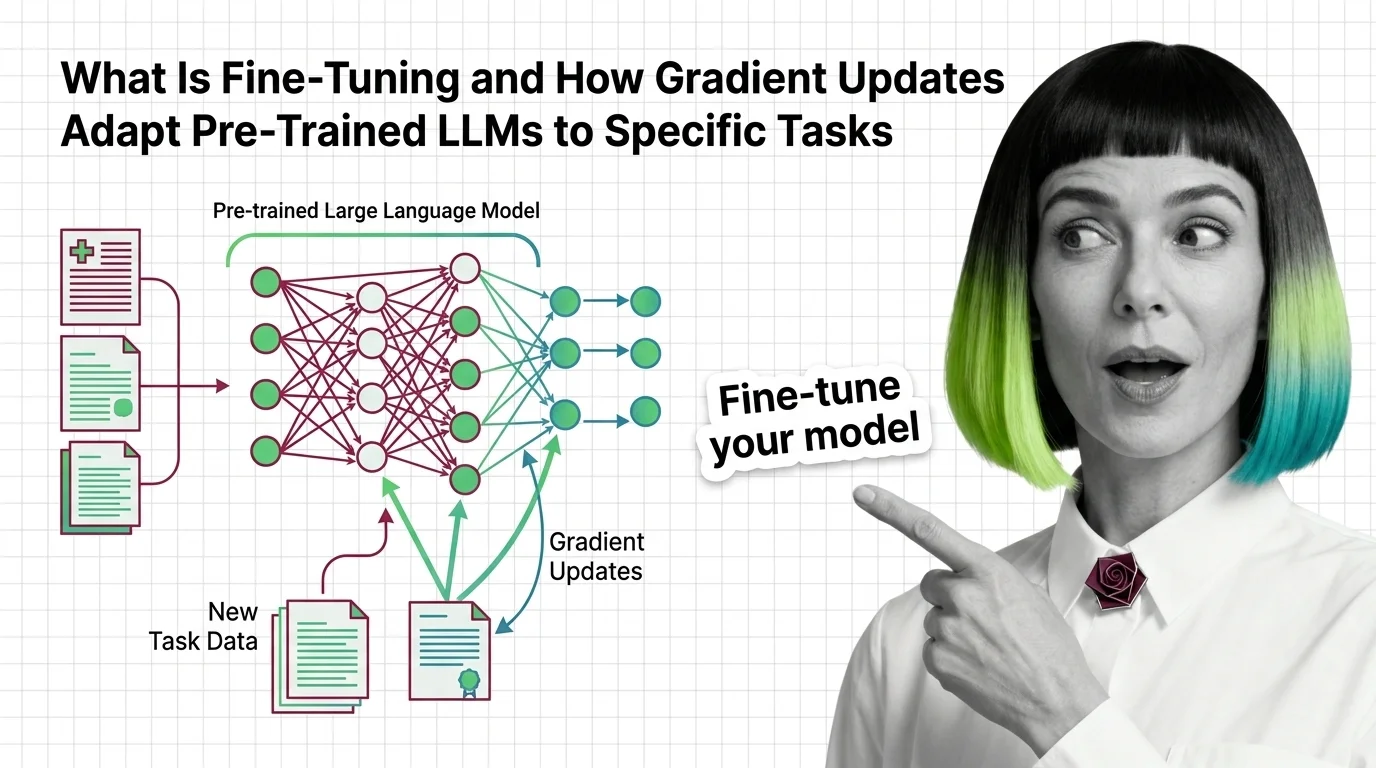
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model behavior without starting from scratch.