Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
Using LLMs and human raters to evaluate AI output quality, including ELO rankings and structured human evaluation methodologies.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
LLM-as-a-Judge is a method where one large language model evaluates the output of another, scoring responses for …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Jun 24, 2026
Concepts covered
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
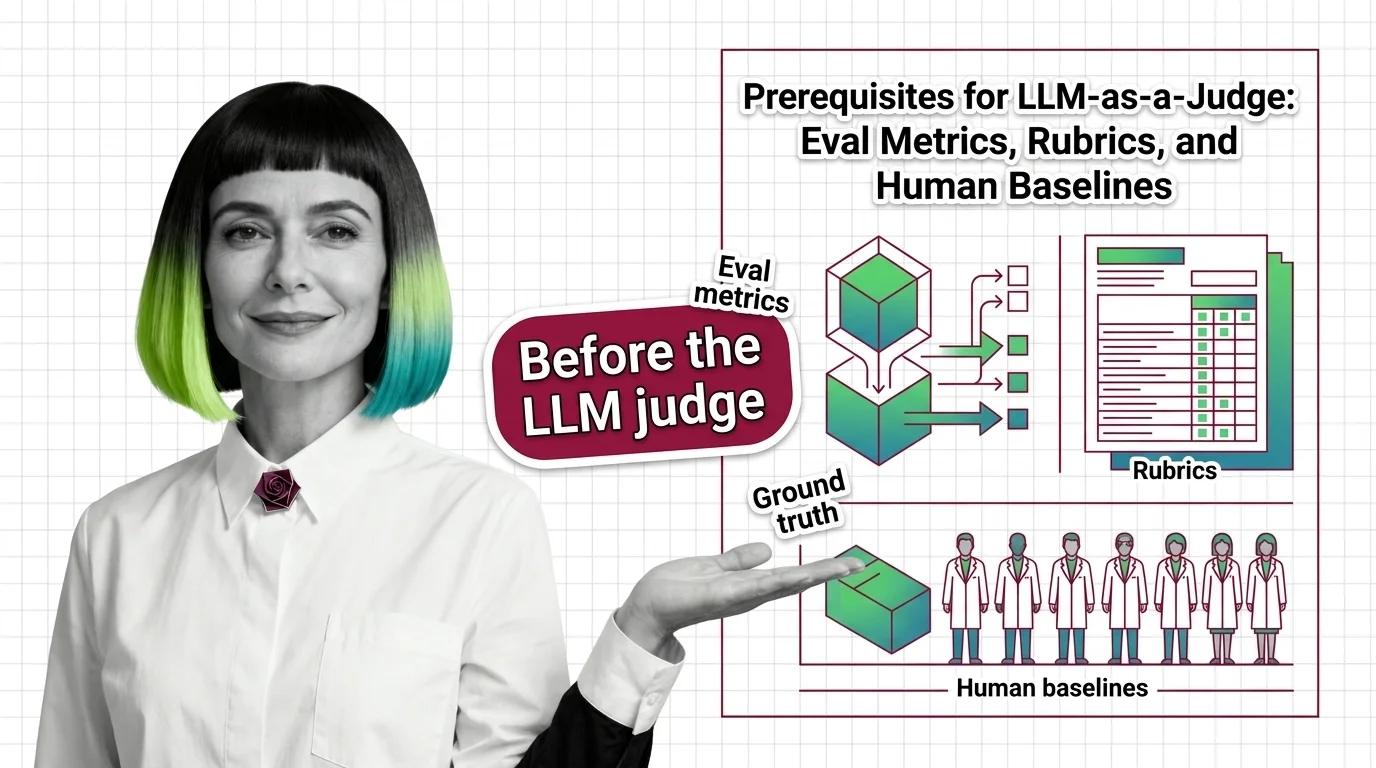
An LLM-as-a-judge is only as reliable as its scaffolding: ground-truth labels, rubrics, and a human baseline. GPT-4 judges hit 80%+ agreement on MT-Bench.

LLM-as-a-judge uses one model to grade another's output via pointwise, pairwise, or rubric scoring. Fast, but prone to position and self-preference bias.