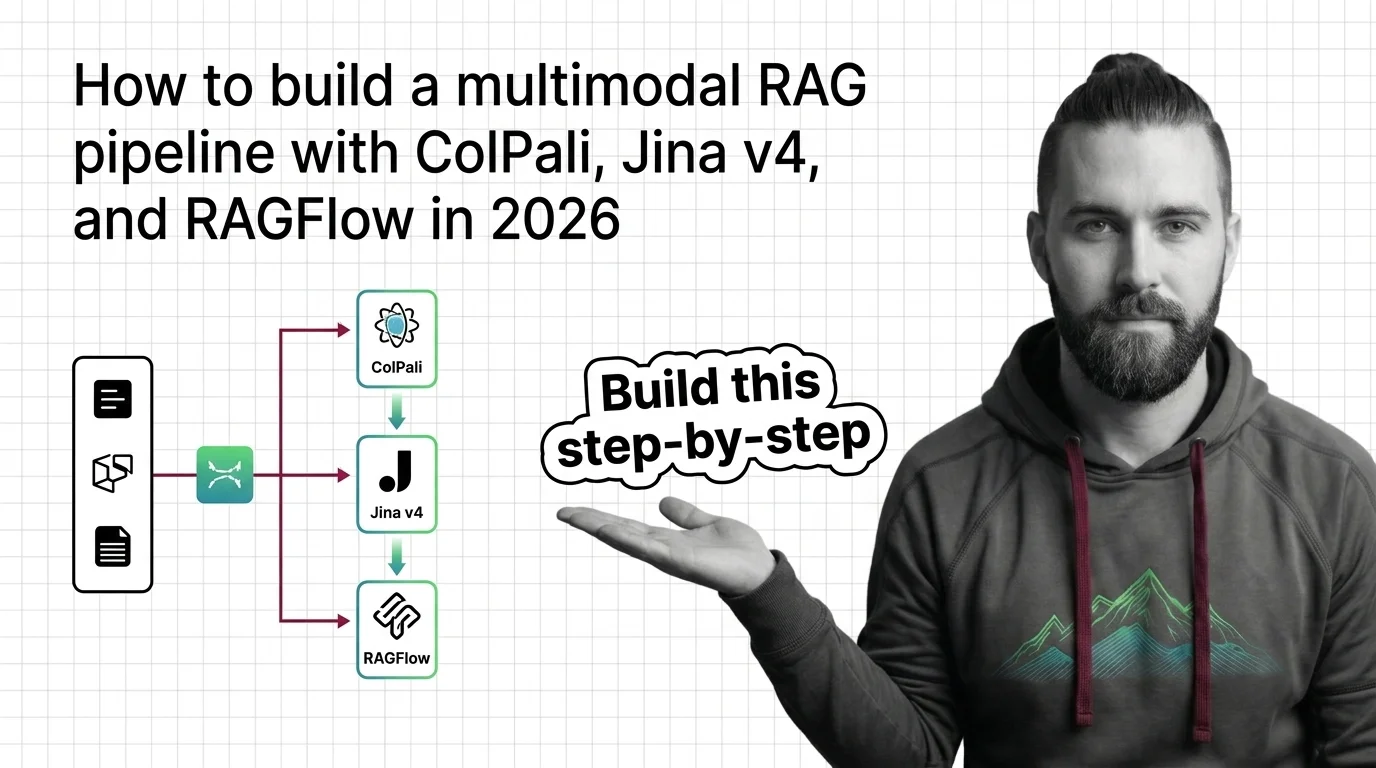
What Is Multimodal RAG and How It Retrieves Across Images, Tables, and Text
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first retrieval handle images, tables, and text.
Structured knowledge integration, document parsing, metadata filtering, and multimodal retrieval for production knowledge systems.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
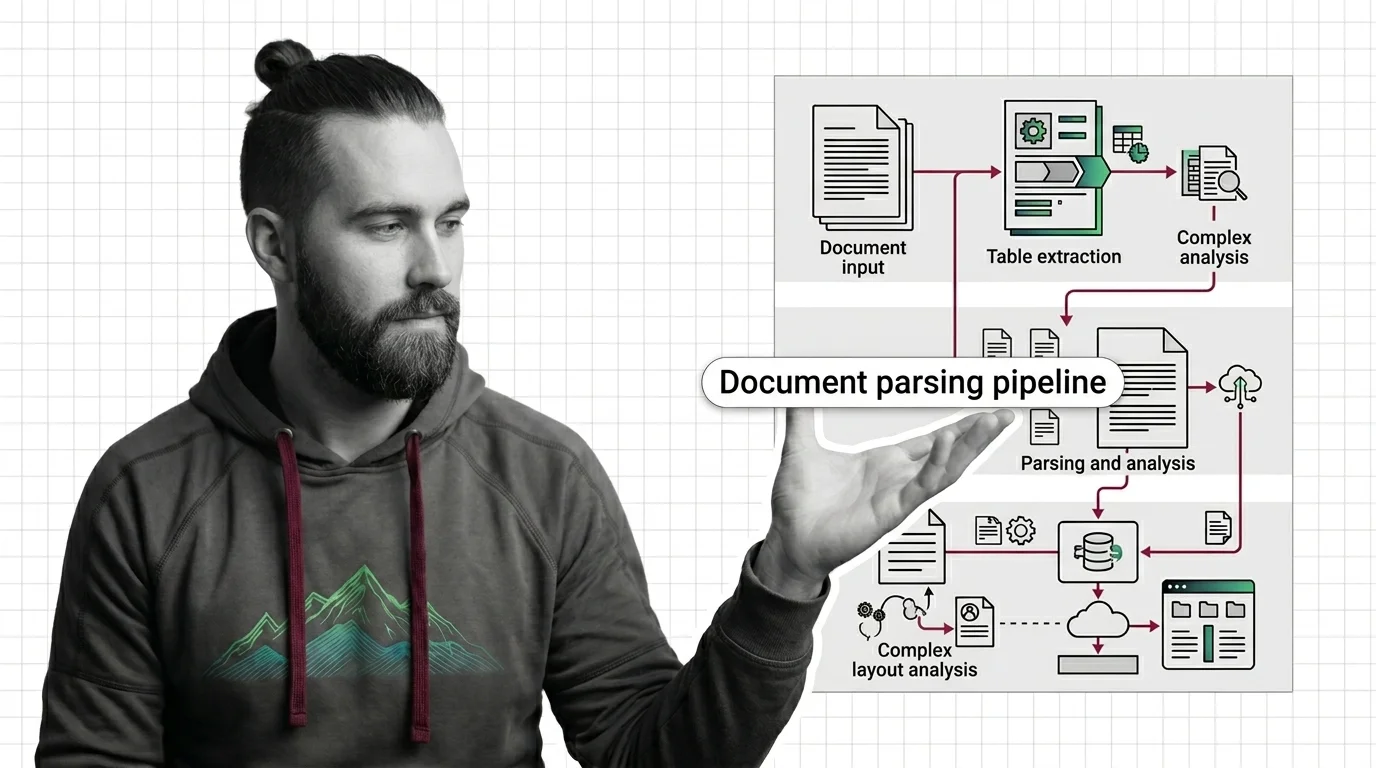
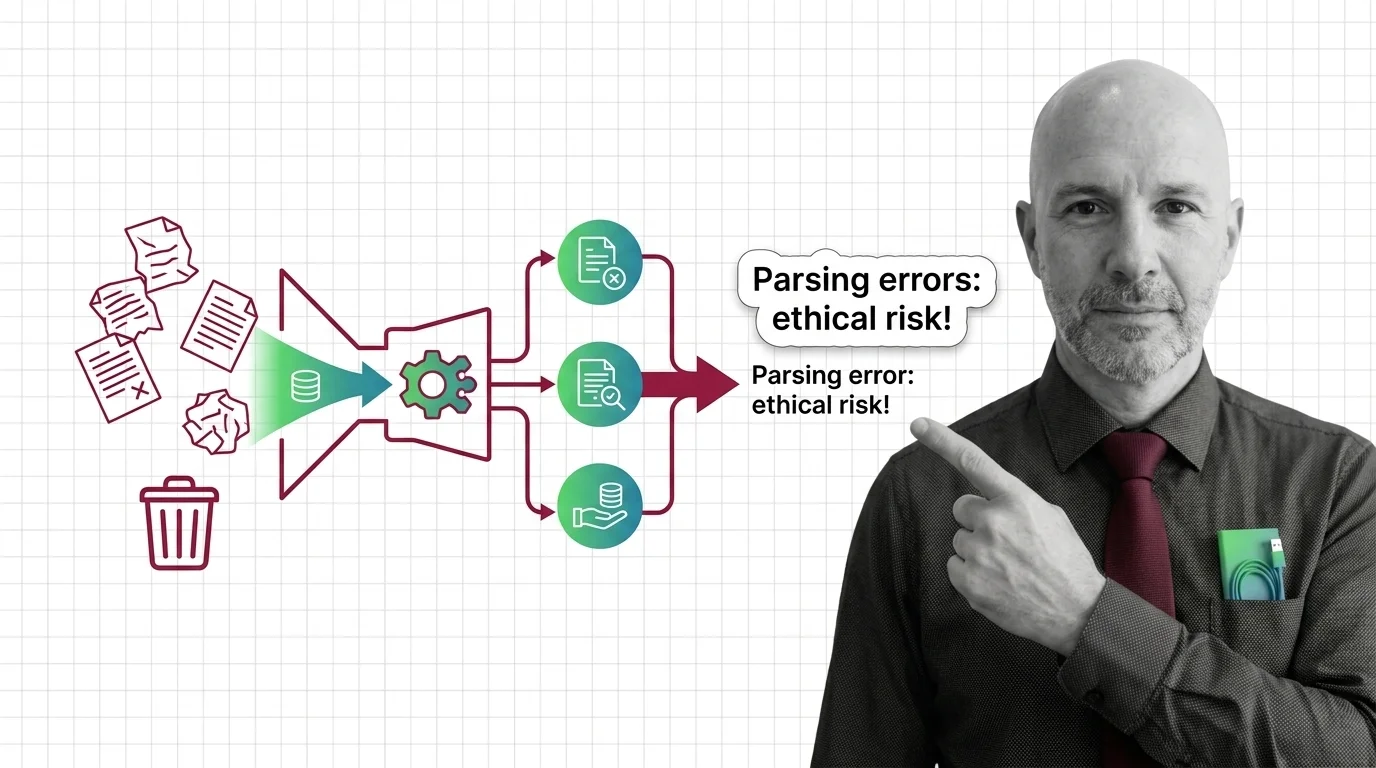
Document parsing and extraction is the preprocessing step that turns PDFs, scanned pages, tables, and images into clean, …
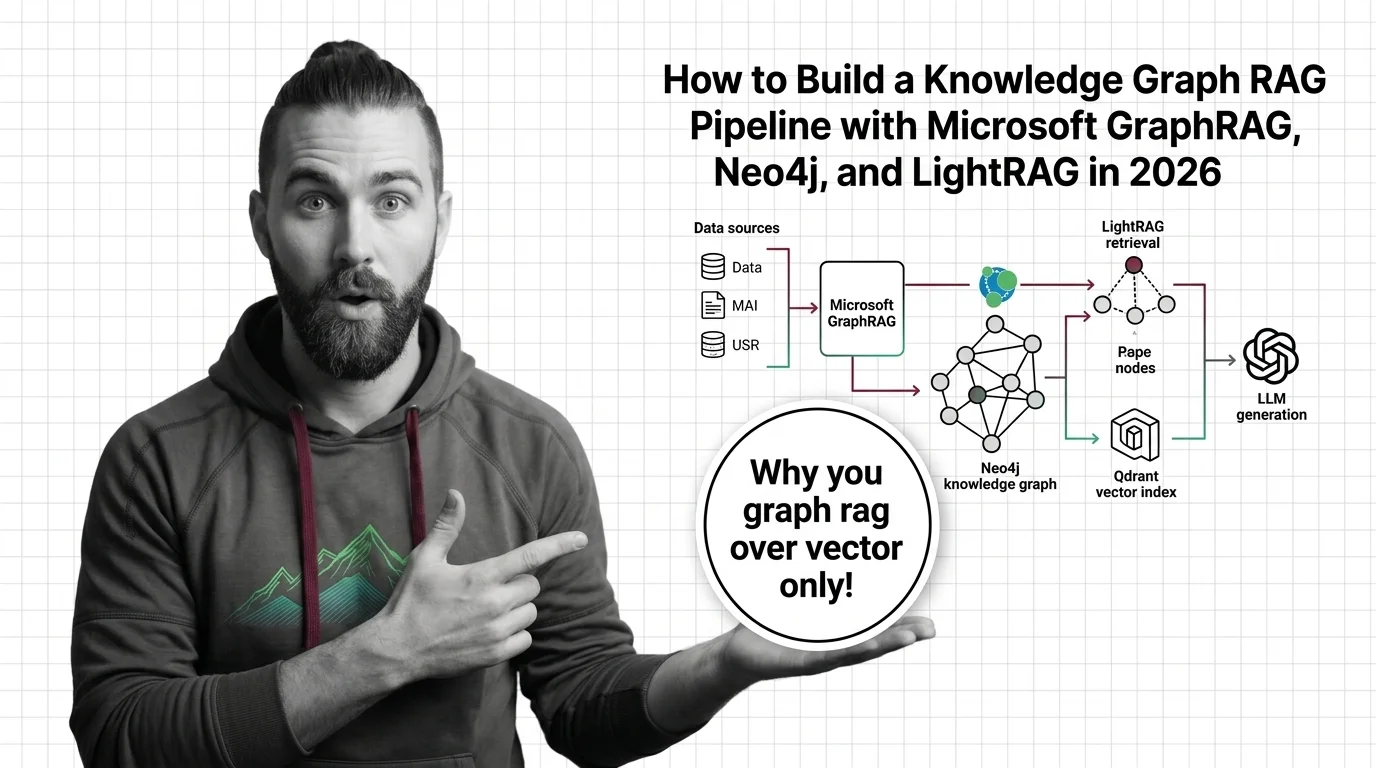
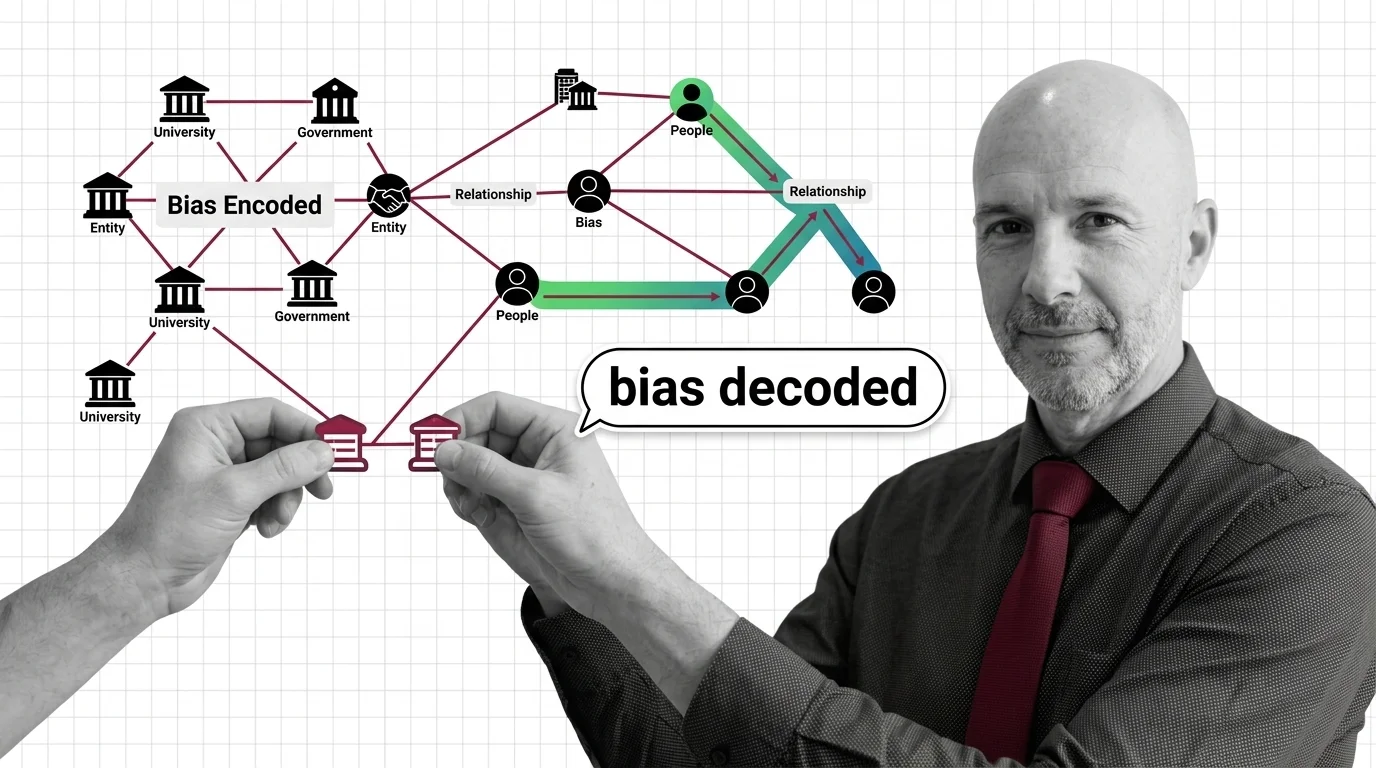
Knowledge Graphs for RAG use structured graph representations of entities and their relationships to retrieve …
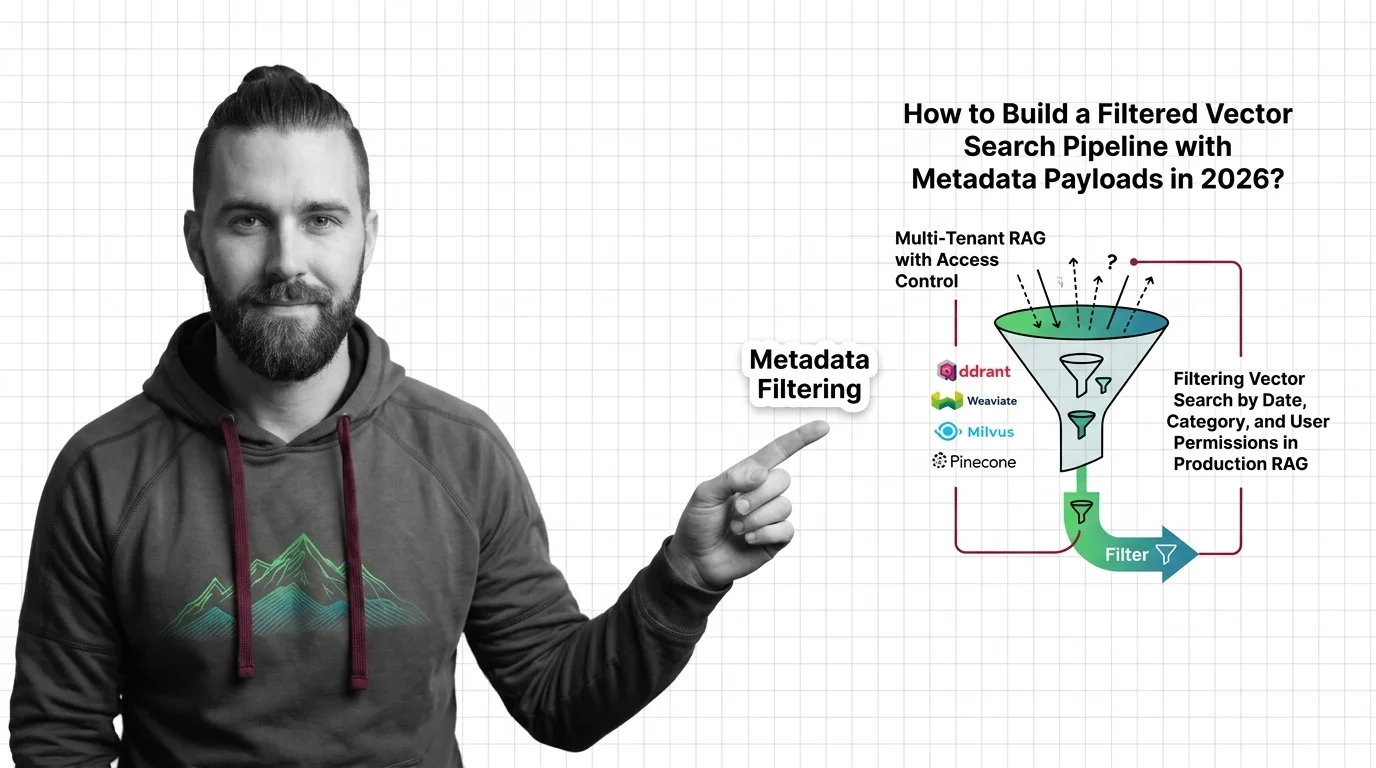
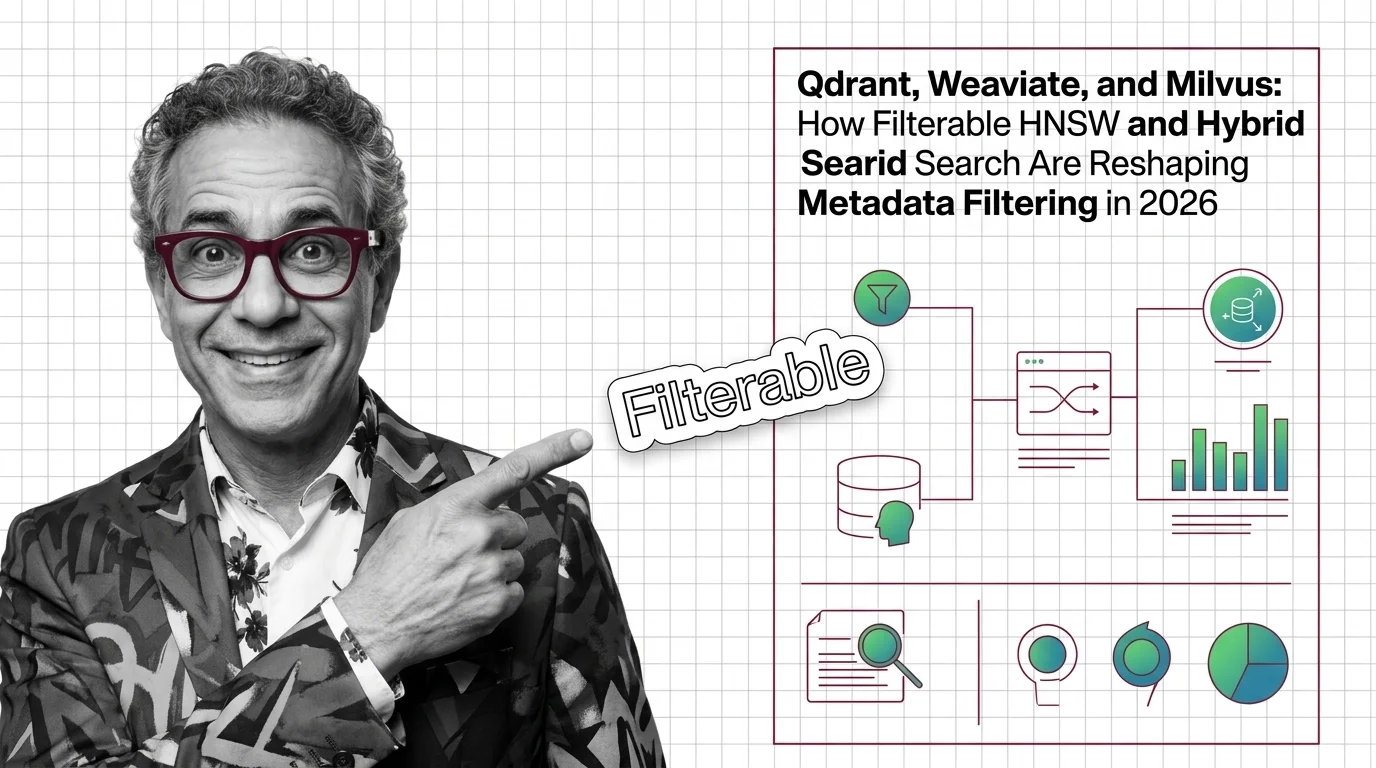
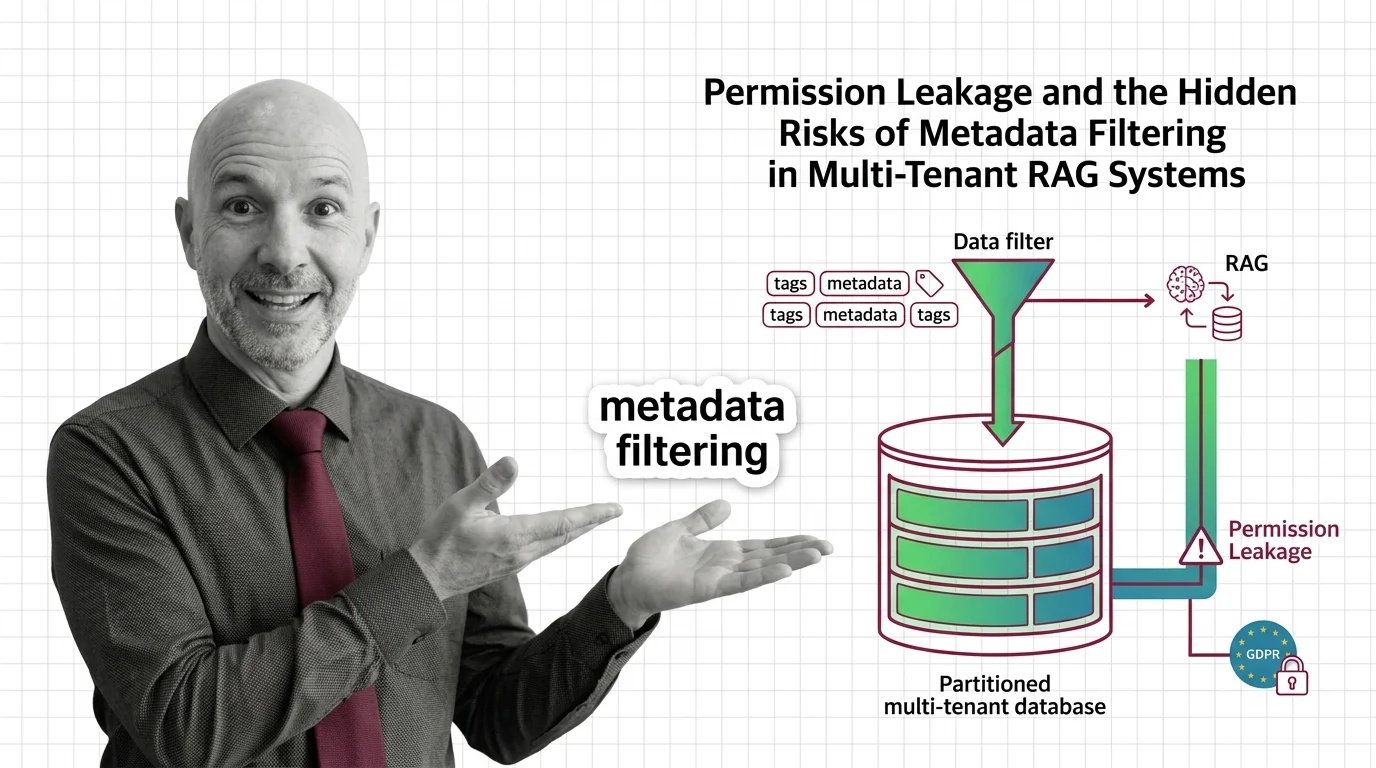
Metadata filtering is the practice of constraining vector search results using structured attributes such as dates, …
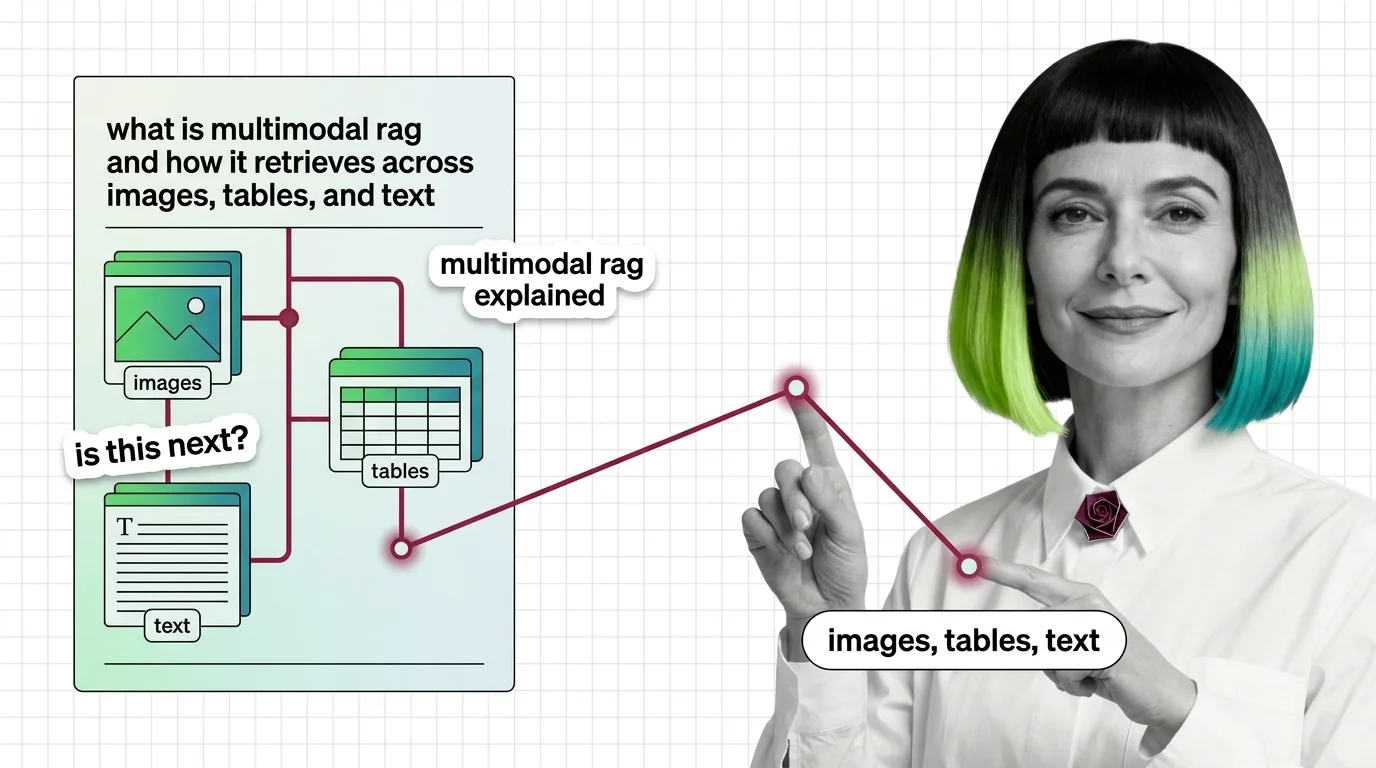
Multimodal RAG extends retrieval-augmented generation beyond plain text so a system can search and reason over images, …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated May 6, 2026
Concepts covered
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first retrieval handle images, tables, and text.
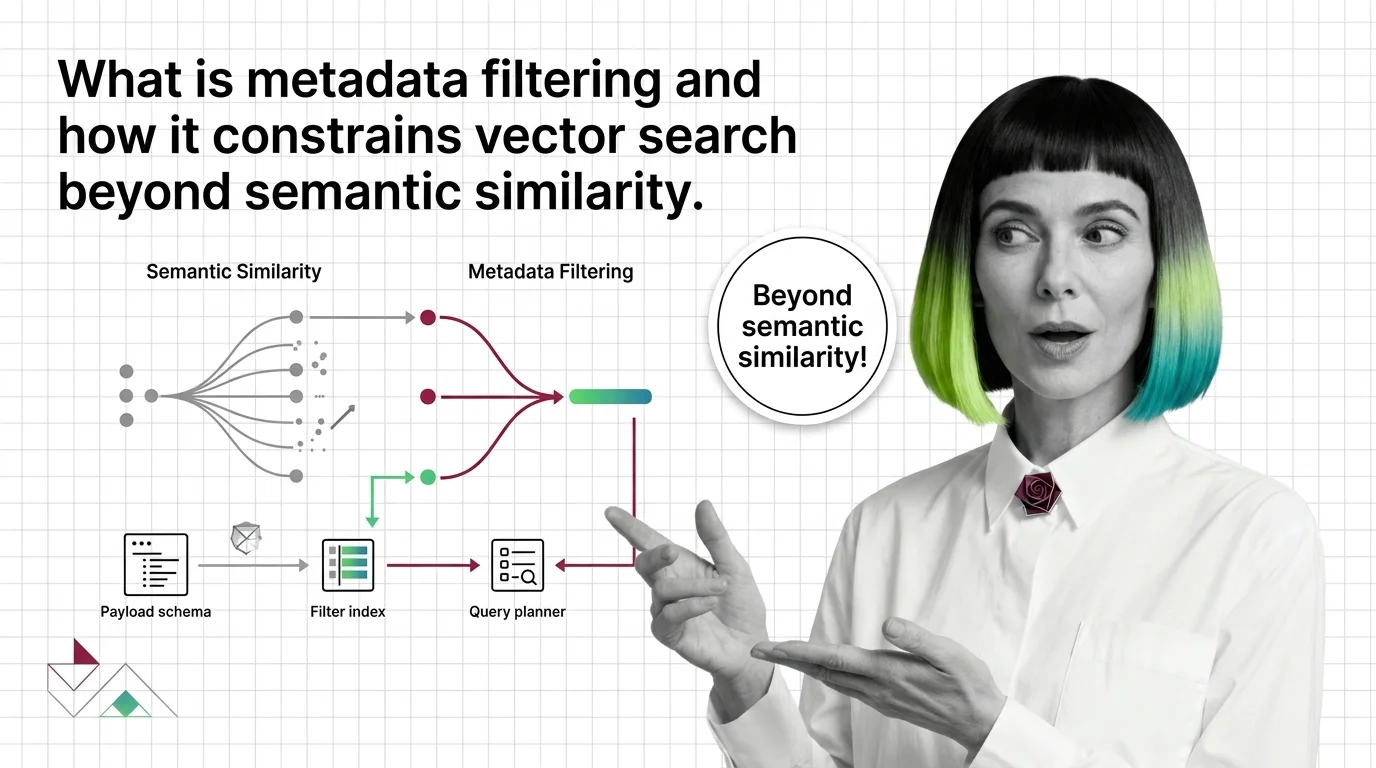
Metadata filtering attaches typed key-value payloads to each vector and applies predicates during search, narrowing results beyond pure semantic similarity.
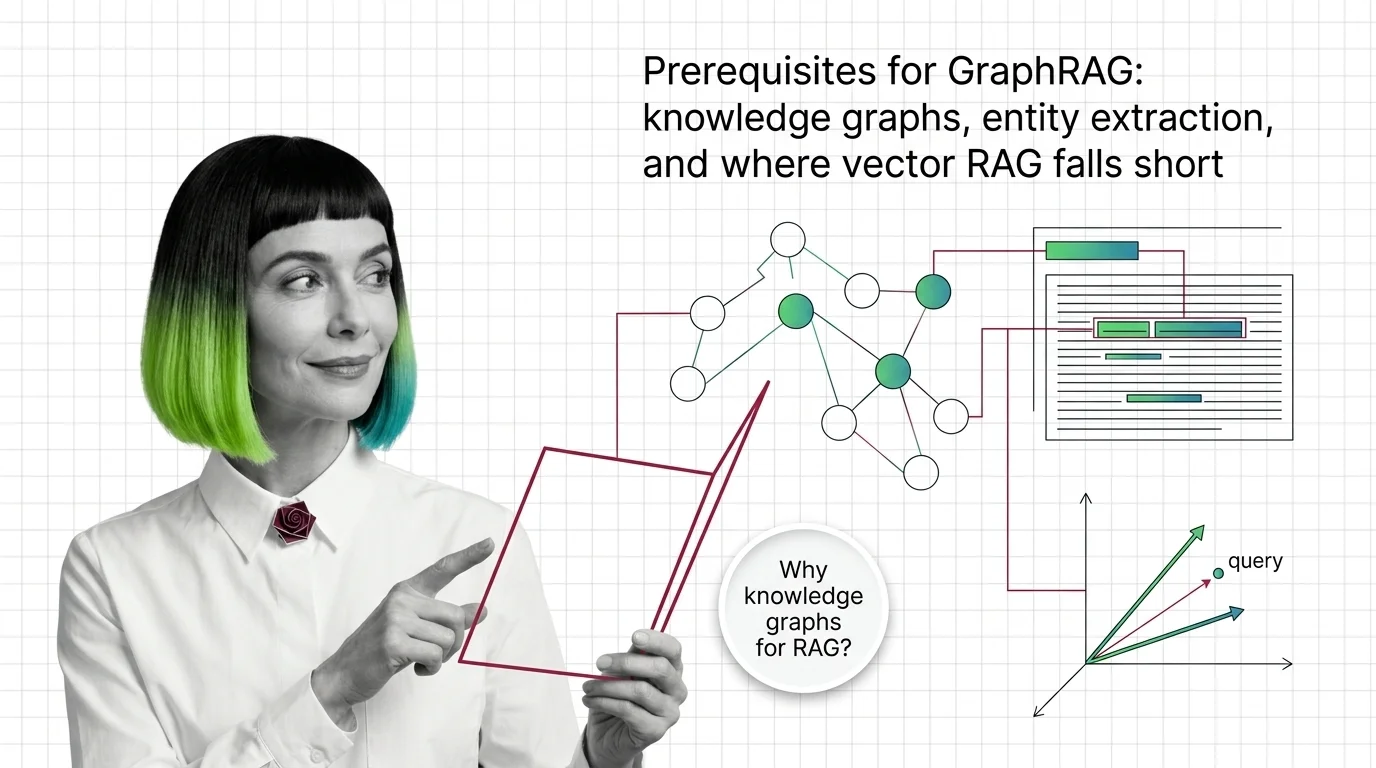
GraphRAG inherits chunking, embeddings, and entity extraction from vector RAG. Learn what you need first and where the underlying pipeline breaks.
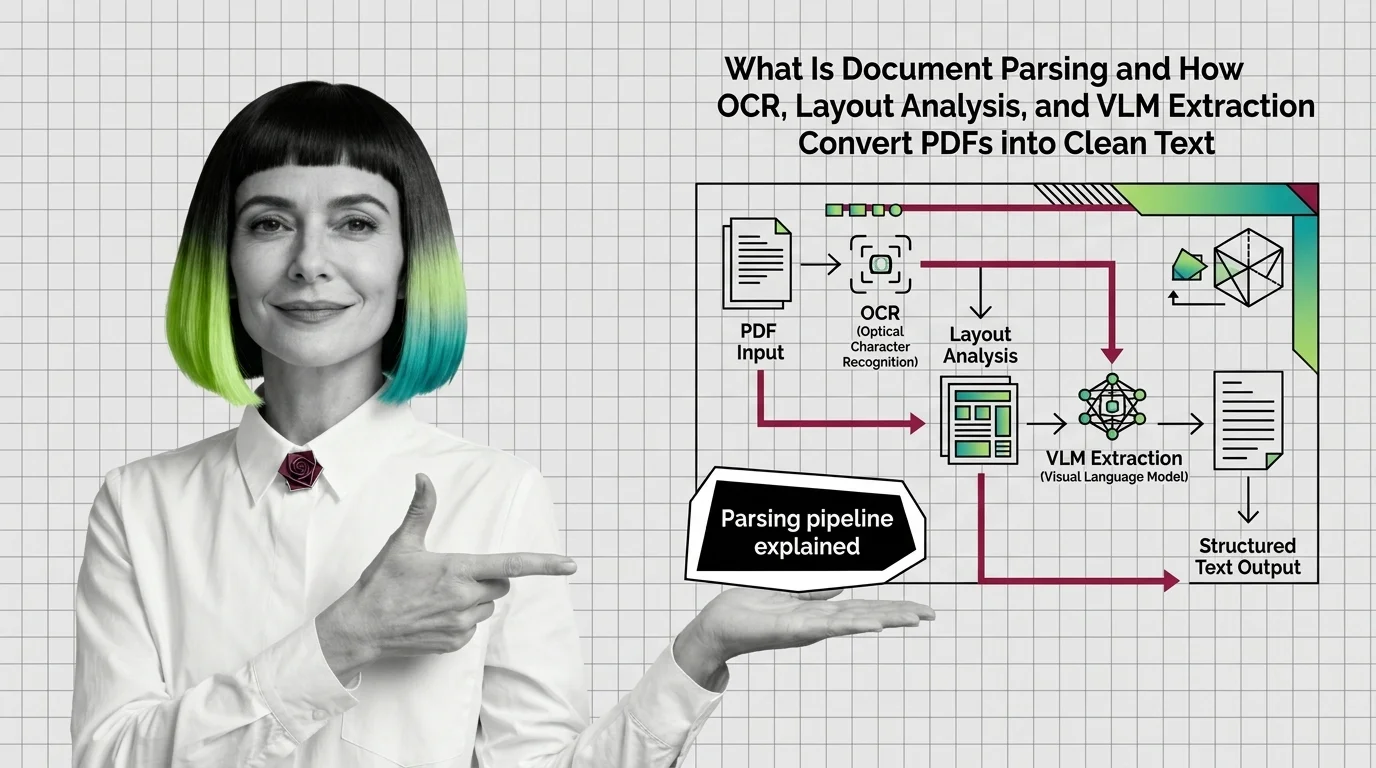
Document parsing converts PDFs into structured text via layout analysis, OCR, and VLMs. Here is how each component works and where each one breaks.
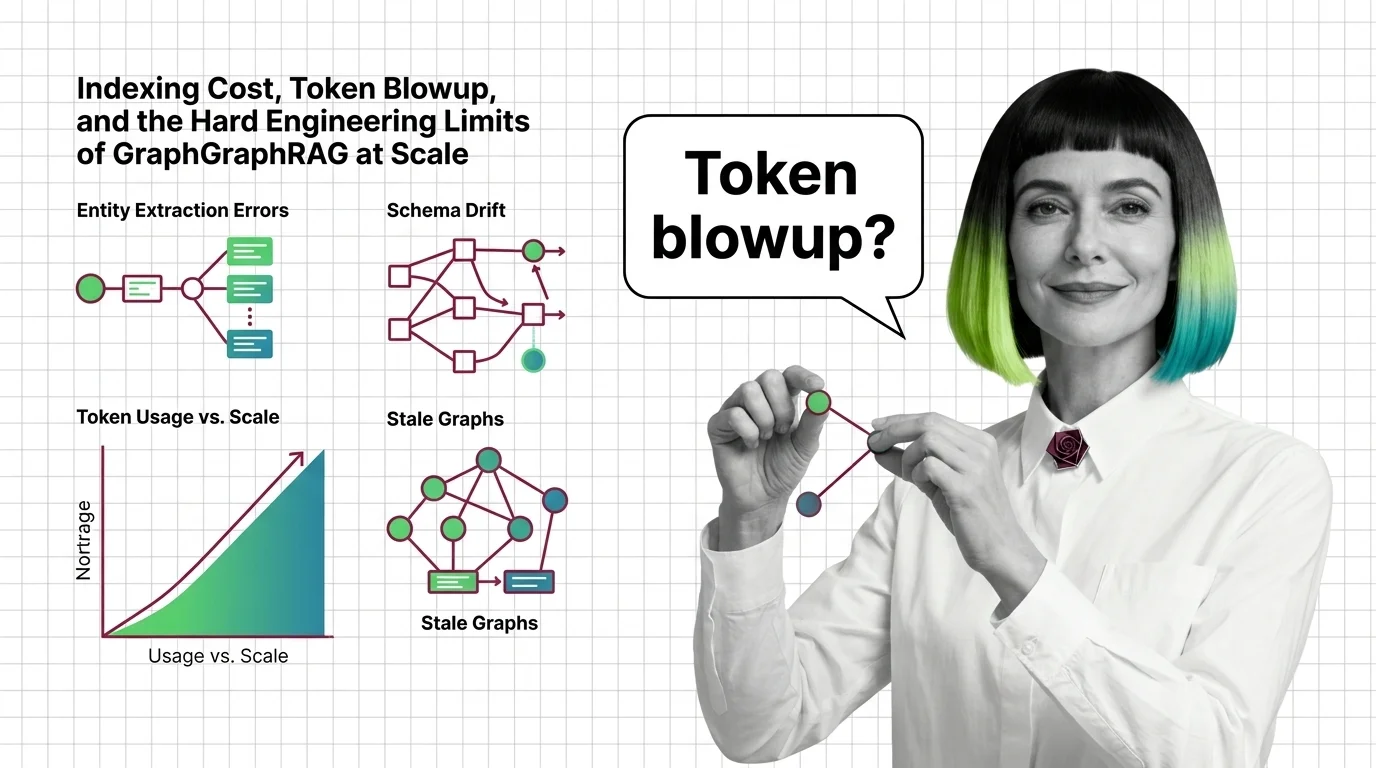
GraphRAG indexing costs scale with token recursion, not document size. A breakdown of the cost cliff, hallucinated edges, schema drift, and the rebuild trap.
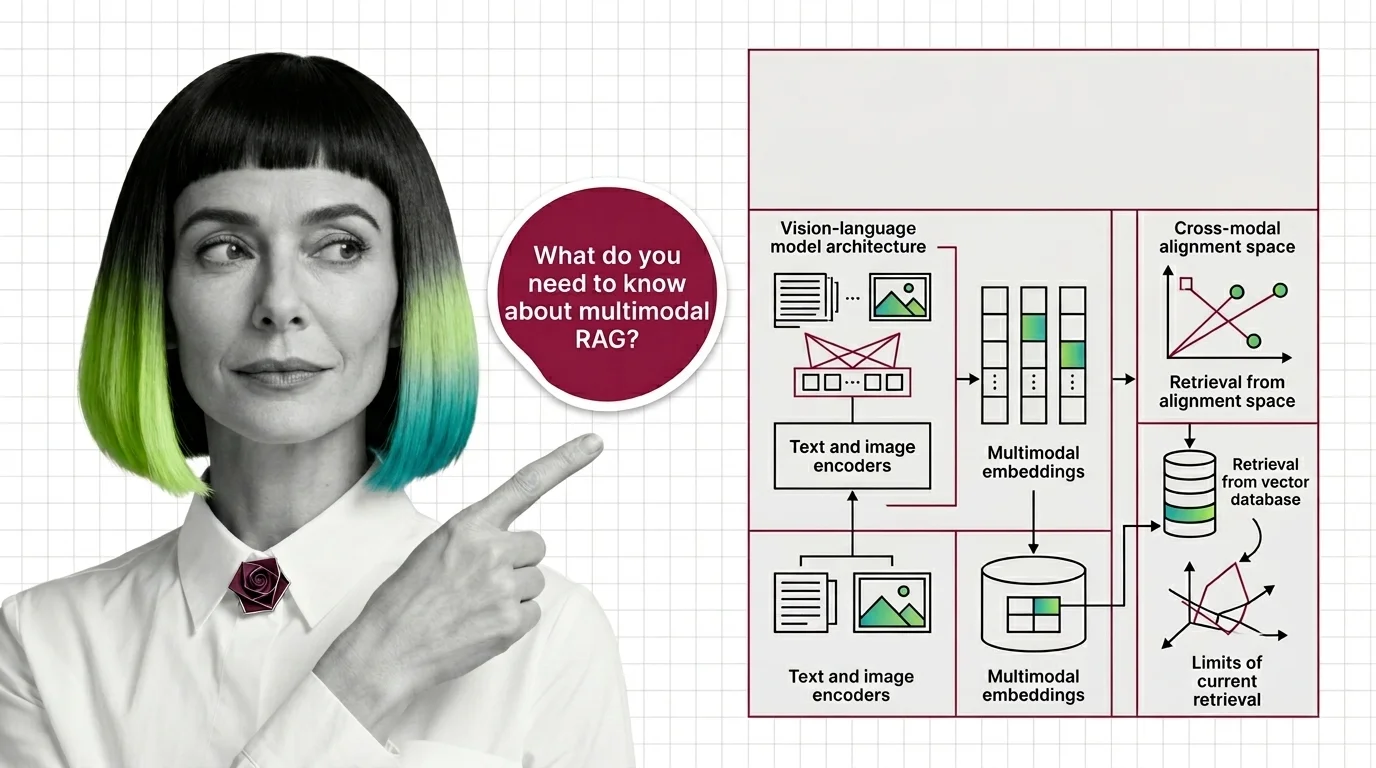
Before multimodal RAG works, you need vision-language models, shared embeddings, and a theory of cross-modal retrieval. Here's the prerequisite stack.
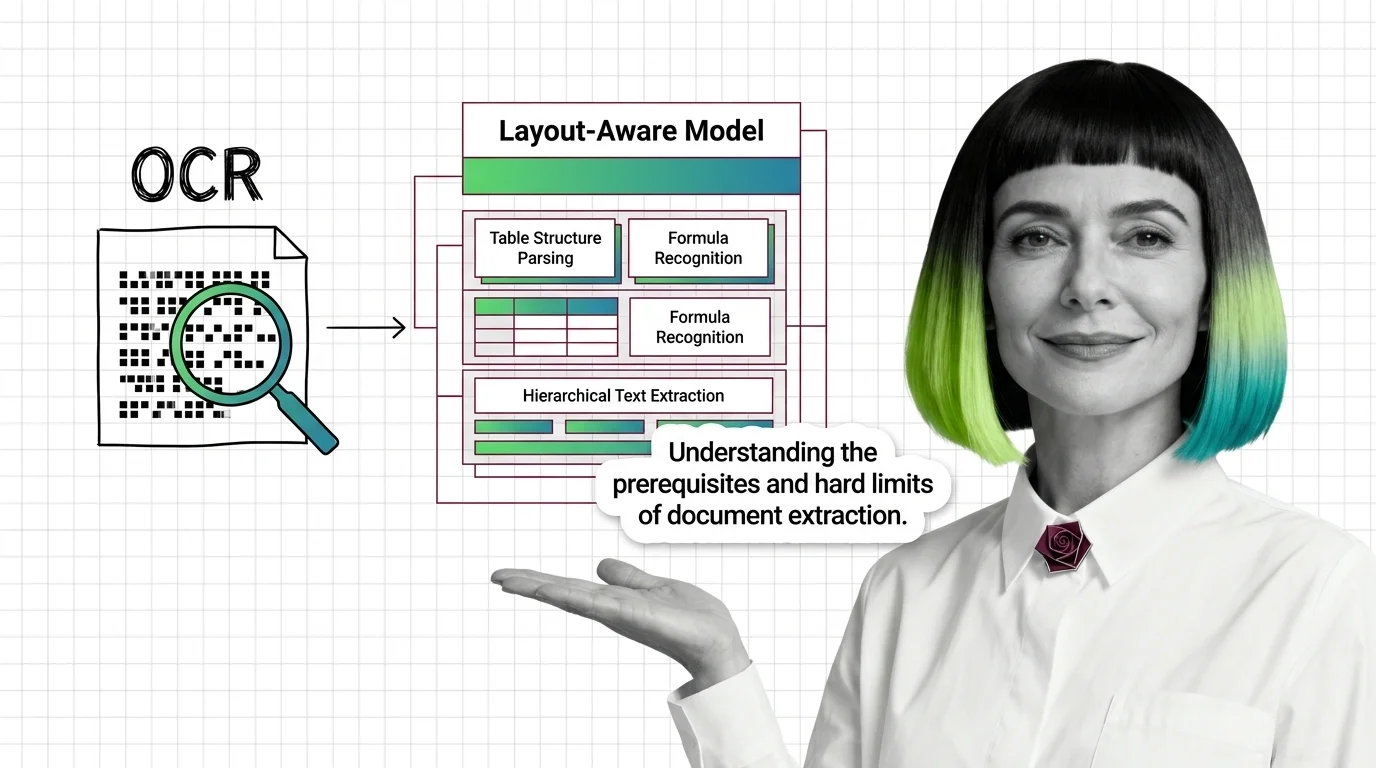
Document parsing breaks in predictable ways. Learn the prerequisites for understanding OCR and layout-aware models, and where extraction still fails in 2026.
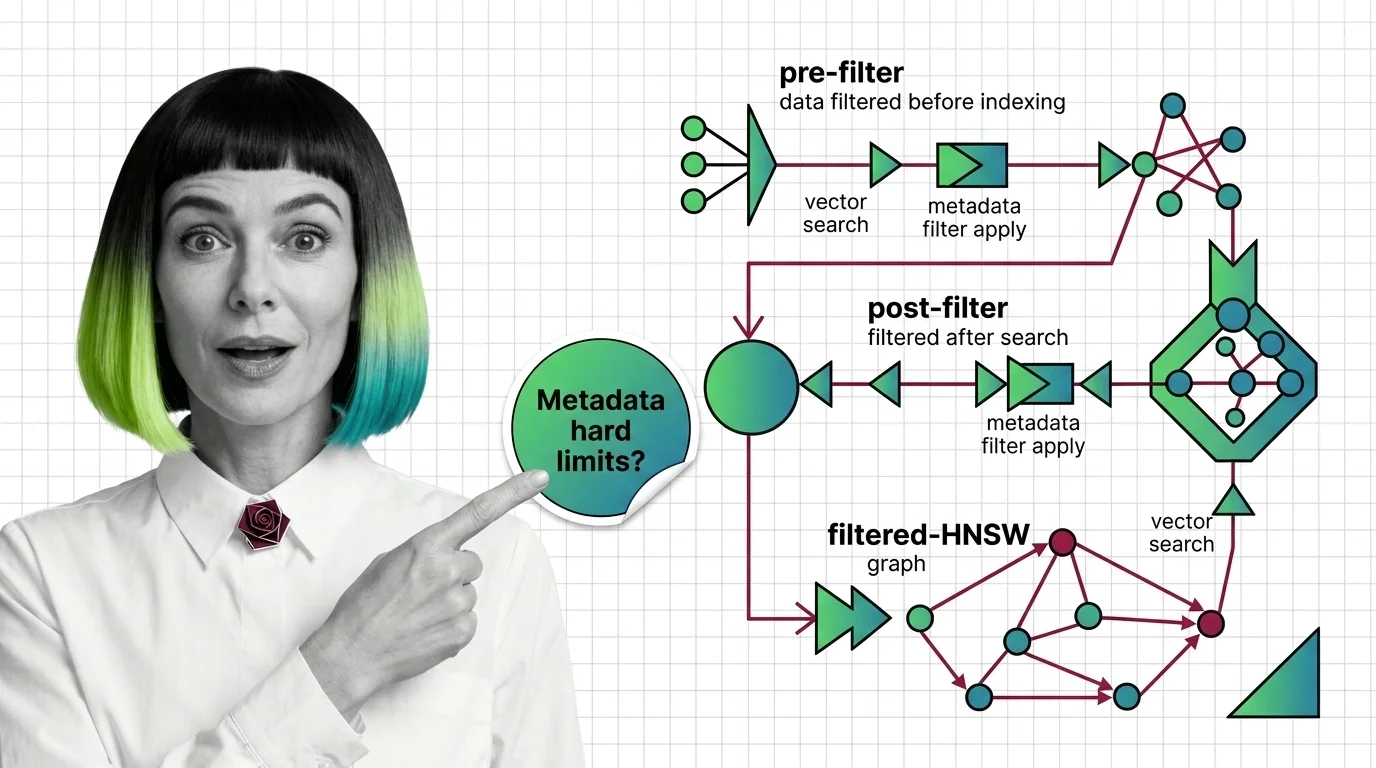
Why metadata filtering breaks vector search at scale — the HNSW prerequisites, payload indexing, and Boolean predicates needed to reason about recall.

GraphRAG turns documents into a knowledge graph and uses community summaries to answer multi-hop questions vector retrieval cannot reach. Here is the mechanism.