From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that silently cap your retrieval quality.
Embeddings and vector search are the data structures and algorithms behind semantic search — dense vector representations, similarity metrics, and indexing strategies that let machines retrieve by meaning instead of keywords.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Embeddings are dense vector representations that map words, sentences, or other data into continuous numerical spaces …
Multi-vector retrieval is a search approach that represents each document as multiple vectors rather than a single …
Sentence Transformers is a framework that uses contrastive learning and siamese networks to produce sentence-level …
Similarity search algorithms are the core mathematical methods used to find the nearest matching vectors in …
Vector indexing encompasses the data structures and algorithms that make approximate nearest-neighbor search practical …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Mar 24, 2026
Concepts covered
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that silently cap your retrieval quality.
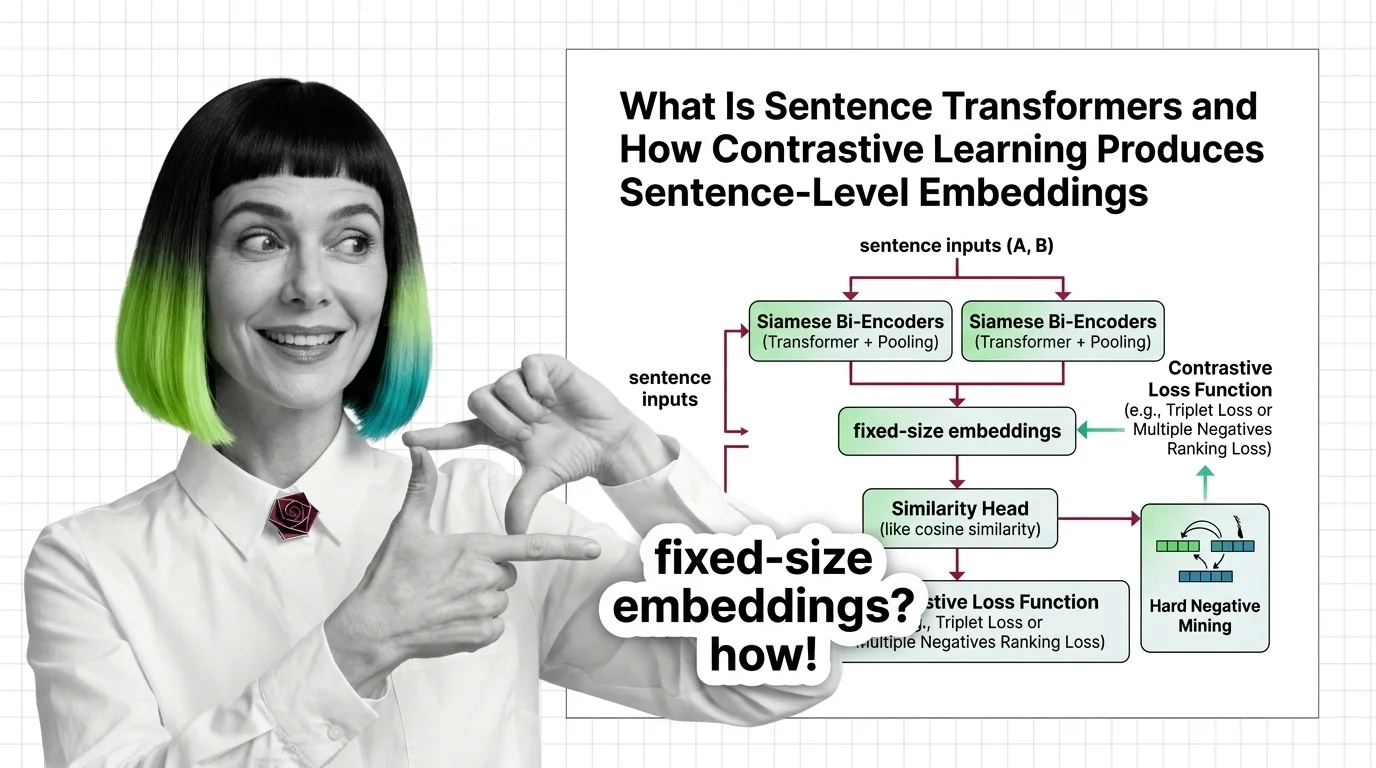
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss functions, pooling, and hard negative mining.

Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and scaling bottlenecks before you commit.
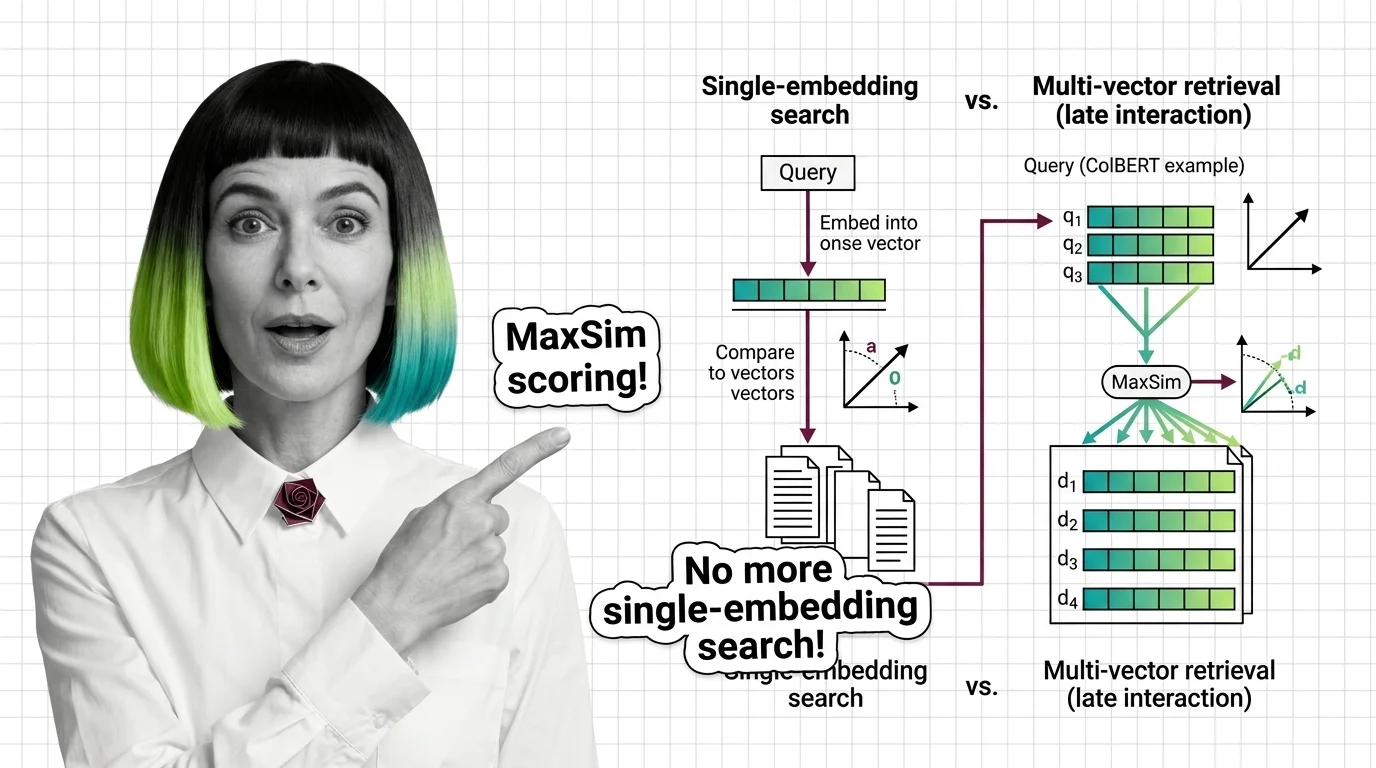
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring preserves nuance dense search destroys.

Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and IVF parameters make sense.
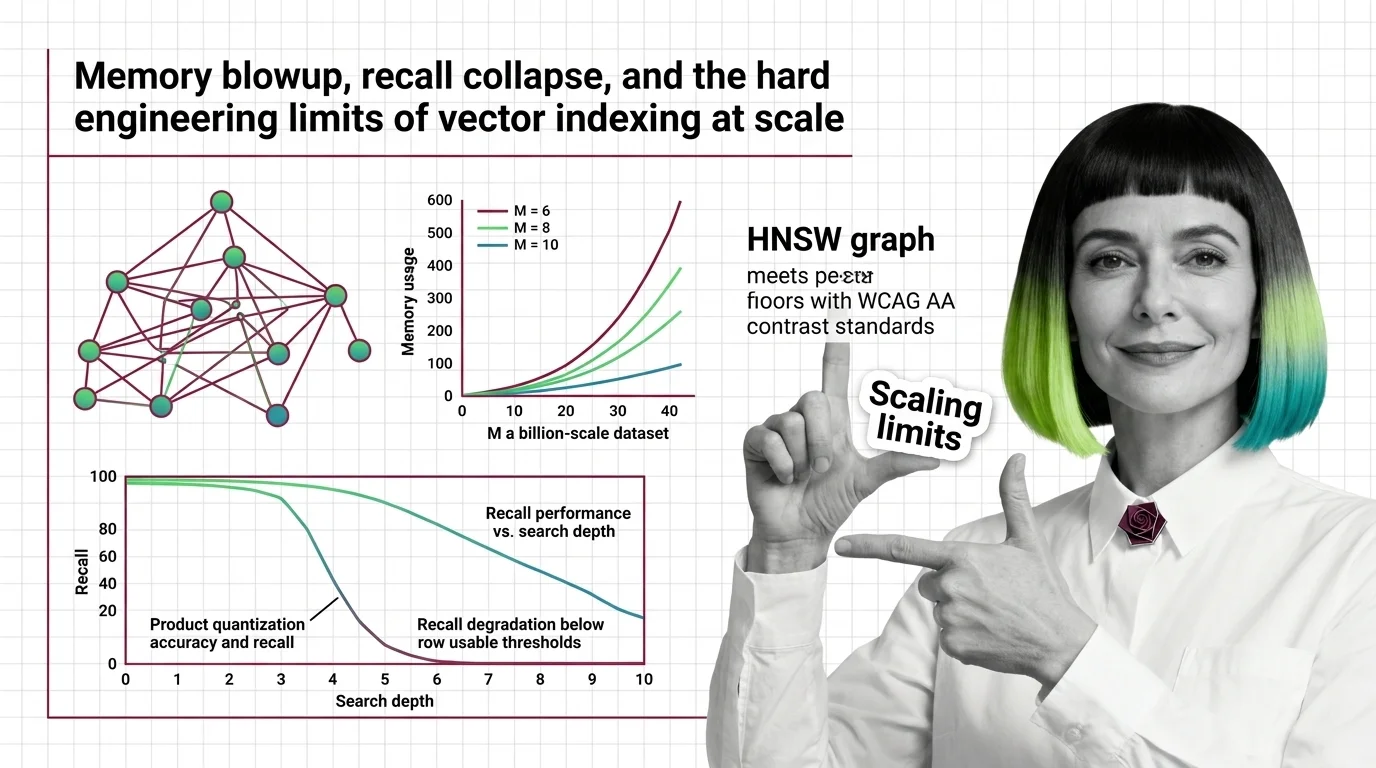
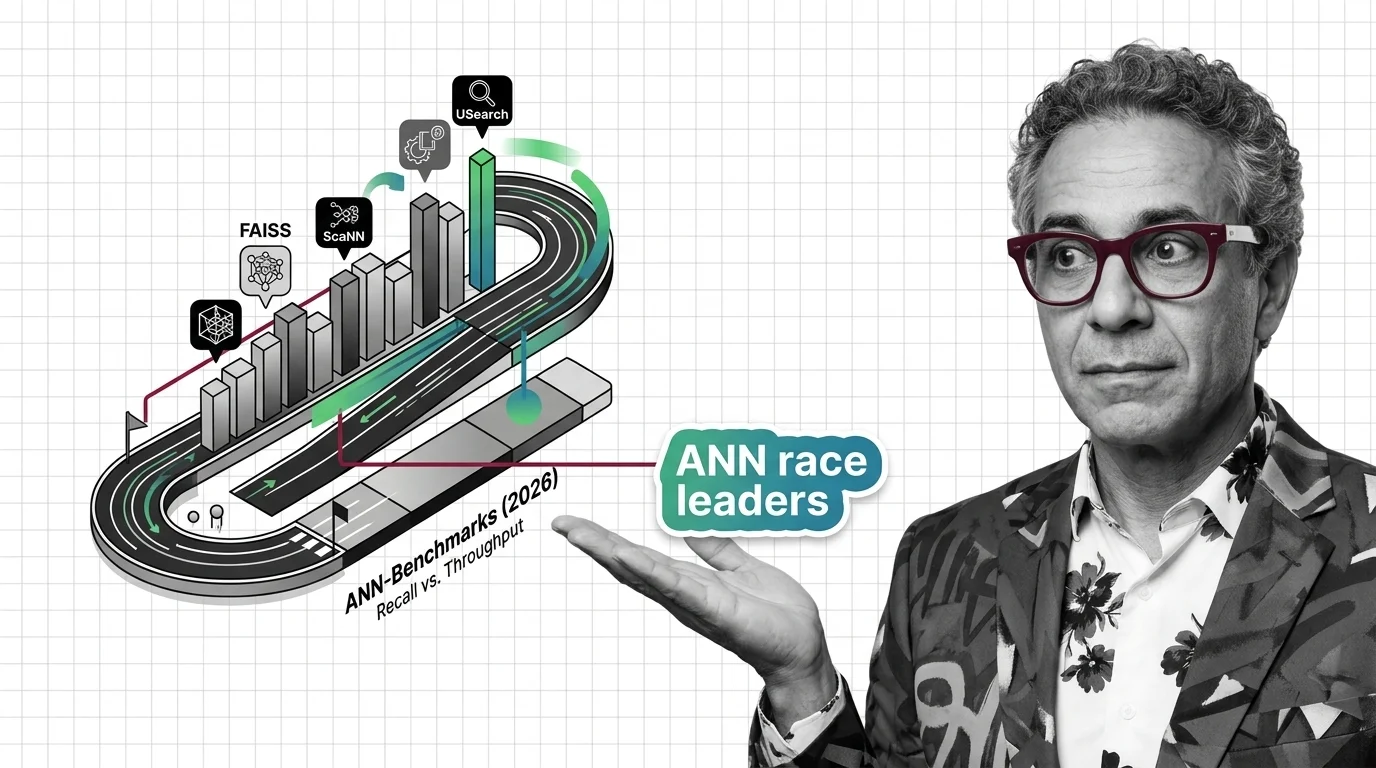
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where vector indexing limits hit at billion scale.
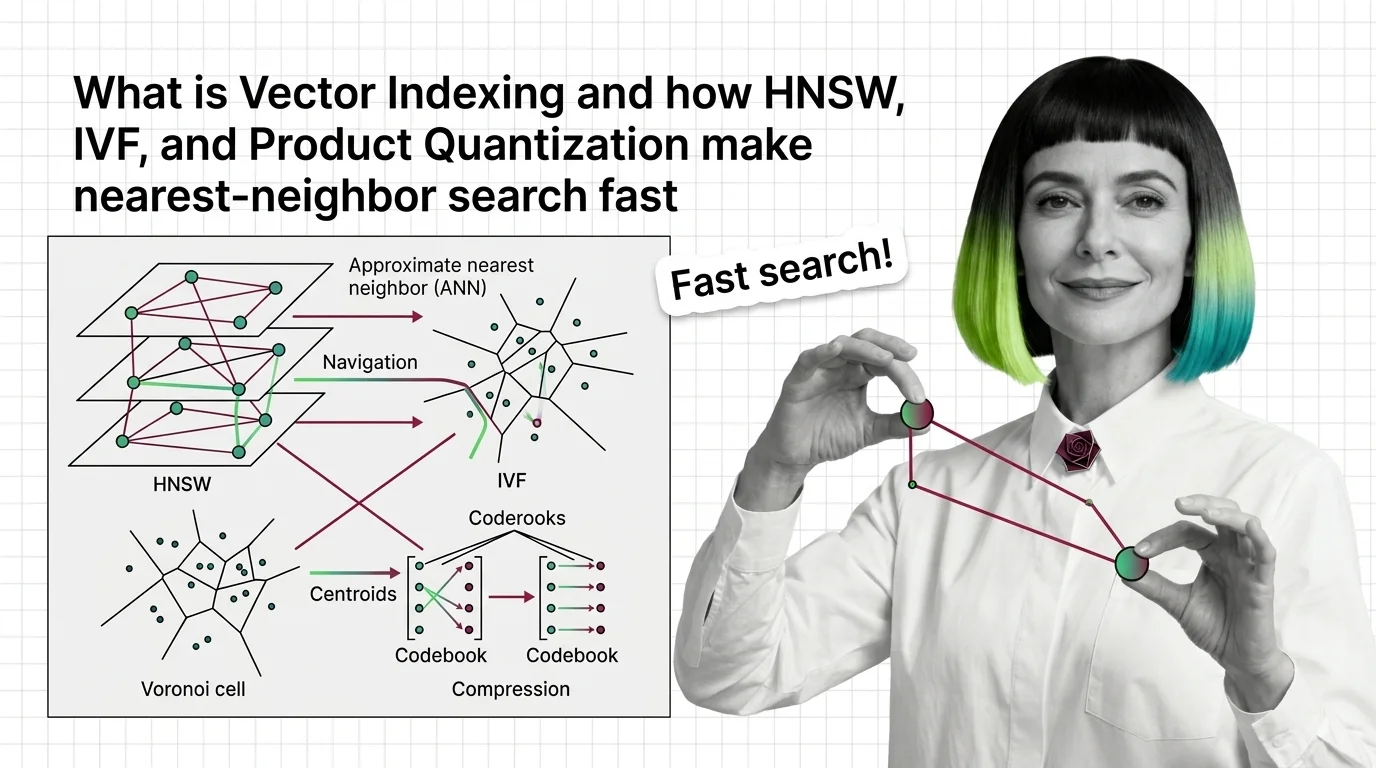
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and product quantization actually work.

High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed tradeoffs, and when brute force wins.
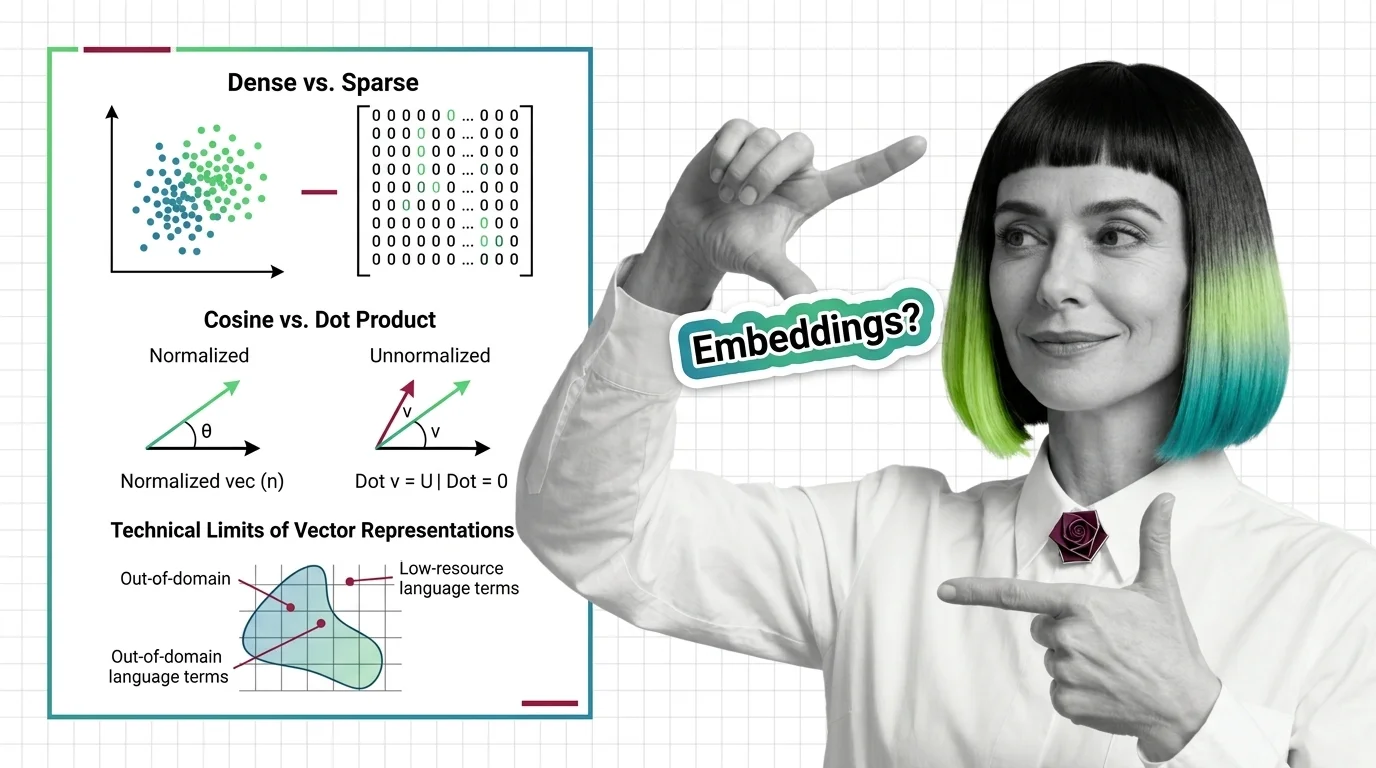
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance shape search — and where vectors fail.
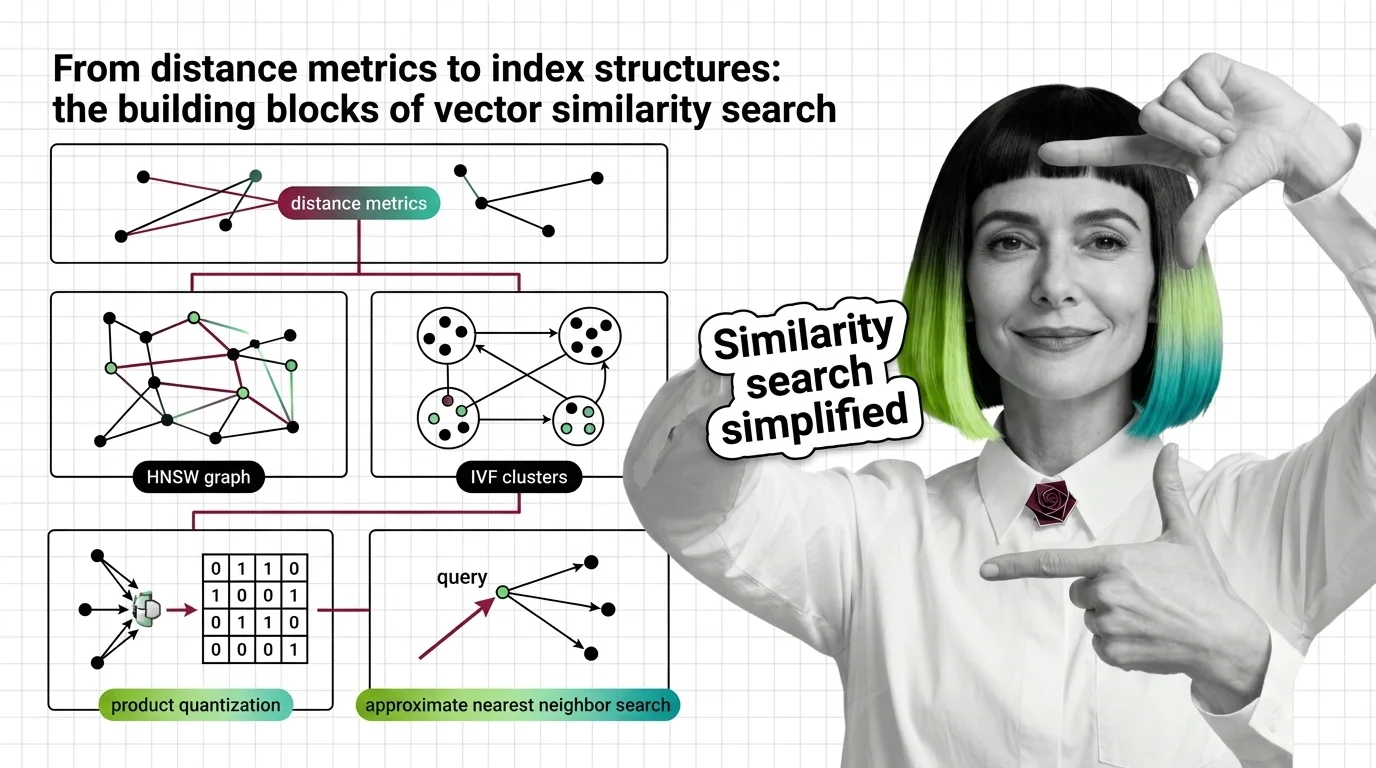
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product quantization trade accuracy for speed at scale.
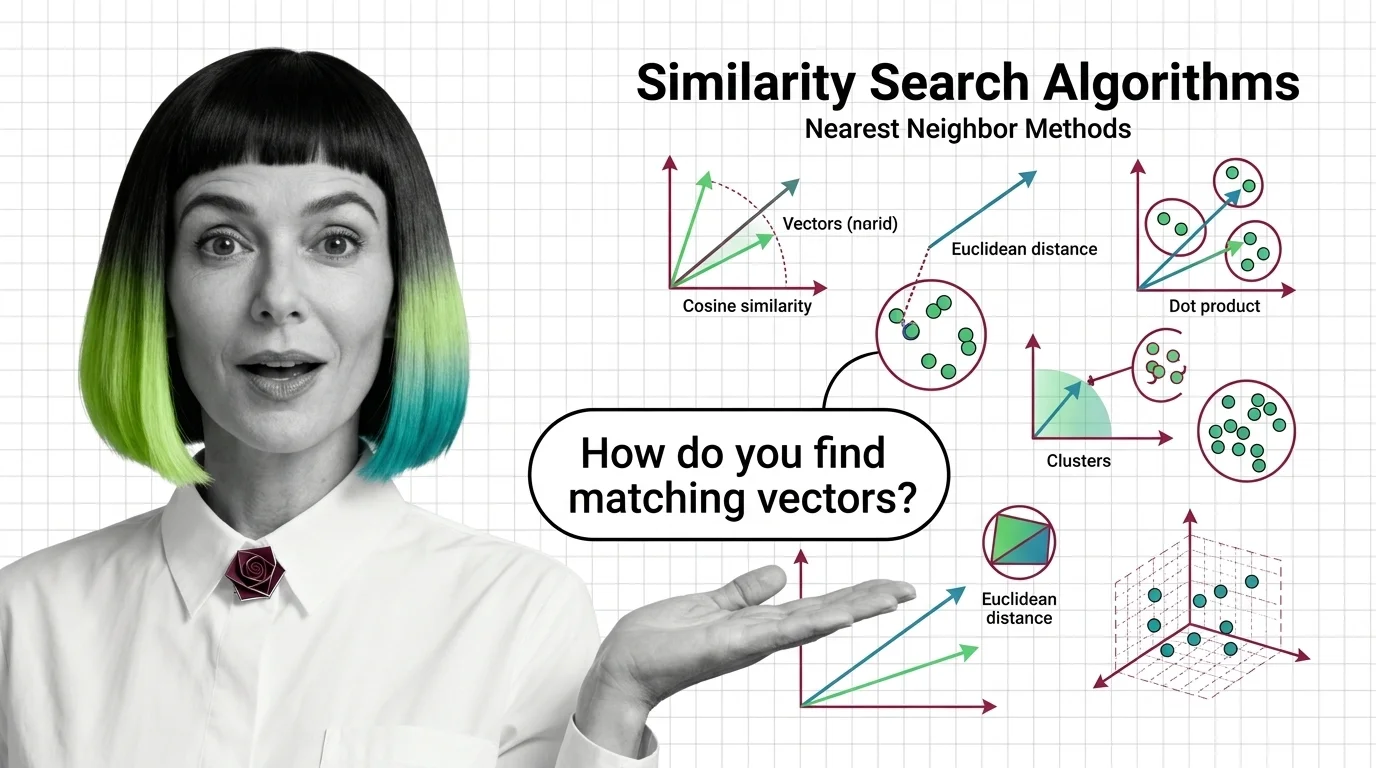
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, and metric choice shape retrieval quality.

Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and failure modes of this core AI concept.