The Impossibility Theorem and Why No Model Can Satisfy Every Fairness Metric at Once
Table of Contents
ELI5
Mathematical proofs show that when different groups have different base rates, no algorithm can simultaneously achieve calibration, equal false positive rates, and equal false negative rates. Fairness requires choosing which metric to satisfy, not finding one that satisfies all.
In 2016, ProPublica published an investigation showing that COMPAS — a criminal risk assessment tool used in US courts — assigned higher false positive rates to Black defendants than to white defendants. Northpointe, the company behind COMPAS, responded that the tool was well-calibrated: a given risk score meant the same recidivism probability regardless of race. Both sides presented valid statistical evidence. Both were correct. That should unsettle you, because it means the disagreement was never about the data. It was about which definition of fairness gets to win.
The Geometry of Incompatible Demands
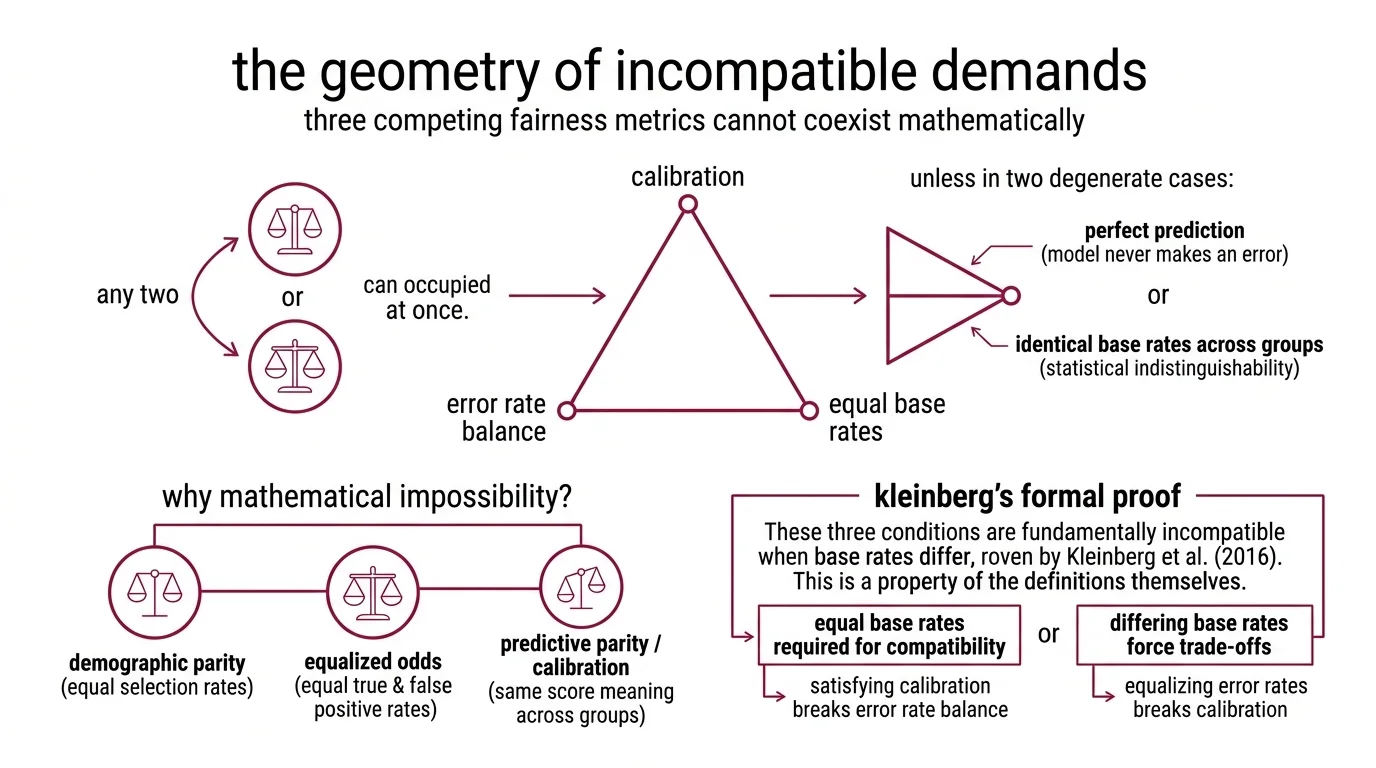
Three definitions of Bias And Fairness Metrics compete for the same mathematical space, and the proof that they cannot coexist is not approximate or context-dependent. It is arithmetic.
Think of it as a physical constraint. You have a triangle with three vertices — calibration, error rate balance, and equal base rates. You can occupy any two simultaneously. You cannot occupy all three unless the triangle collapses into a single point, which requires either perfect prediction (the model never makes an error) or identical base rates across groups (the groups are statistically indistinguishable). Neither condition holds in any deployment that matters.
Why is it mathematically impossible to satisfy all fairness metrics simultaneously?
The incompatibility emerges from the relationship between three properties. Demographic Parity requires that a classifier selects members from each group at equal rates, regardless of the underlying base rate. Equalized Odds demands equal true positive rates and equal false positive rates across groups. Predictive parity — also called calibration — insists that a given score means the same thing for every group: if the model assigns a risk level, that probability should hold whether the individual belongs to group A or group B.
Kleinberg, Mullainathan, and Raghavan formalized the conflict. Their result proves that these three conditions cannot simultaneously hold except in two degenerate cases: perfect prediction or equal base rates (Kleinberg et al. (2016)). When base rates differ — and in practice, they almost always do — satisfying calibration mathematically forces unequal error rates between groups. Equalizing error rates, in turn, breaks calibration.
The incompatibility is not a flaw in any particular algorithm — it is a property of the definitions themselves.
This is not a claim that fairness is unachievable. It is a claim that fairness, as formalized by these three metrics, contains an internal contradiction whenever groups differ statistically. The two exceptions — perfect prediction and equal base rates — are mathematically valid but practically irrelevant, the way absolute zero is valid in thermodynamics but irrelevant to engineering.
What is the Chouldechova impossibility theorem in algorithmic fairness?
Alexandra Chouldechova’s 2017 proof narrows the lens. Where Kleinberg et al. addressed three fairness conditions in general terms, Chouldechova specifically proved that calibration and error rate balance — equal false positive rates and equal false negative rates across groups — cannot coexist when Protected Attribute groups have unequal base rates (Chouldechova (2017)).
The proof operates on a binary classifier. When one group’s base rate is meaningfully higher than another’s, holding calibration constant forces different false positive and false negative rates between the groups for any threshold the classifier applies. The algebra does not bend. You can choose which error rate to equalize — you cannot equalize both while maintaining calibration.
The COMPAS case is the theorem made visible. ProPublica measured error rate imbalance and found it. Northpointe measured calibration and confirmed it (ProPublica). Both were right — and the Impossibility Theorem is why neither was wrong. The debate was never a technical dispute. It was a definitional one, with a mathematical proof sitting underneath it the entire time.
Where the Ruler Itself Distorts
The impossibility results establish that no single metric can do everything. But the practical problem runs deeper: the instruments we use to measure fairness carry their own distortions, and the toolkits that compute them inherit those limits.
What are the technical limitations of current bias detection methods in machine learning?
Start with the Four Fifths Rule — the EEOC screening threshold from 1978. If one group’s selection rate falls below 80% of the highest group’s rate, that constitutes prima facie evidence of Disparate Impact. The rule is intuitive. It is also brittle: a selection rate just below the threshold triggers a finding; a rate just above it does not. A small shift in sample composition can flip the verdict entirely. The rule was designed for employment screening with well-defined applicant pools — not for continuous-score classifiers generating thousands of predictions per second.
Counterfactual Fairness offers a theoretically cleaner alternative: a decision is fair if it would remain the same in a world where the individual’s protected attribute differed (Kusner et al. (2017)). The definition is precise, but it demands a causal model — a directed acyclic graph specifying which variables are affected by the protected attribute and which are not. Building that graph requires domain knowledge that frequently does not exist in the form the method needs, and the resulting fairness assessment is only as valid as the graph’s assumptions. Get the causal structure wrong, and you are measuring fairness in a world that does not correspond to this one.
Intersectionality compounds the difficulty. Most bias audits evaluate one protected attribute at a time — race or gender, rarely both simultaneously. But disparate impact can hide at intersections: a model that appears fair for women overall and fair for Black individuals overall may be systematically unfair for Black women specifically. The number of intersectional subgroups grows combinatorially with each additional attribute, and sample sizes shrink in proportion — making statistical estimation unreliable precisely where the stakes are highest.
The toolkit situation reflects this structural gap. Fairlearn provides MetricFrame for group-level fairness assessment and mitigation algorithms that automate threshold adjustment. AI Fairness 360 offers dozens of fairness metrics and mitigation algorithms across pre-processing, in-processing, and post-processing stages. Both toolkits compute individual metrics accurately. Neither can resolve which metric to choose — and that limitation is the theorem itself, not a feature request waiting for a patch.
Security & compatibility notes:
- AI Fairness 360: Last release v0.6.1 (Apr 2024) — no update in approximately two years. Still functional, but maintenance pace is unclear. Verify current status before adopting for new projects.
What the Proof Forces You to Choose
The impossibility theorem does not end the conversation about fairness. It restructures it. Instead of asking “is this model fair?”, the operative question becomes “which fairness violation causes the least harm here?” — and no algorithm can answer that.
If you optimize for calibration in a lending model, expect unequal false positive rates across groups with different default rates. Qualified borrowers from the lower-base-rate group are more likely to be rejected — not because the model is biased in implementation, but because calibration forces the error distribution to track the base rate gap.
If you equalize false positive rates instead, the model’s predictions begin to mean different things for different groups. A given risk score corresponds to different actual probabilities depending on group membership. The score becomes locally meaningless — a kind of measurement Hallucination, internally consistent but disconnected from the quantity it claims to represent.
If you enforce demographic parity — equal selection rates regardless of base rates — expect predictive accuracy to degrade, because you are forcing the model to select at rates that do not reflect the underlying data distribution.
Each choice has a constituency. Calibration serves actuarial accuracy. Error rate balance serves procedural justice. Demographic parity serves representational equity. The EU AI Act requires high-risk AI systems to implement bias detection and correction using representative datasets, with the majority of provisions applicable as of August 2026 (EU Digital Strategy). But regulation does not resolve the impossibility — it requires documentation of which trade-off was chosen and why.
Rule of thumb: Choose the fairness metric whose violation causes the most concrete harm in your specific deployment context, then document the trade-off explicitly.
When it breaks: The impossibility theorem assumes a single binary classifier with fixed group definitions. Multi-stage systems, human-in-the-loop processes, and continuous-score models introduce degrees of freedom that can partially mitigate — but never fully eliminate — the fundamental trade-off between calibration and error rate balance.
The Data Says
Fairness in machine learning is not a calibration problem, an error-rate problem, or a selection-rate problem. It is a design decision — constrained by proofs that show these goals are mathematically incompatible when group base rates differ. The Chouldechova and Kleinberg et al. results do not make fairness impossible; they make it honest. Every deployment encodes a choice about whose harm counts most, and the only indefensible position is pretending that choice does not exist.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors