The Hidden Cost of Million-Token Context: Who Gets Priced Out
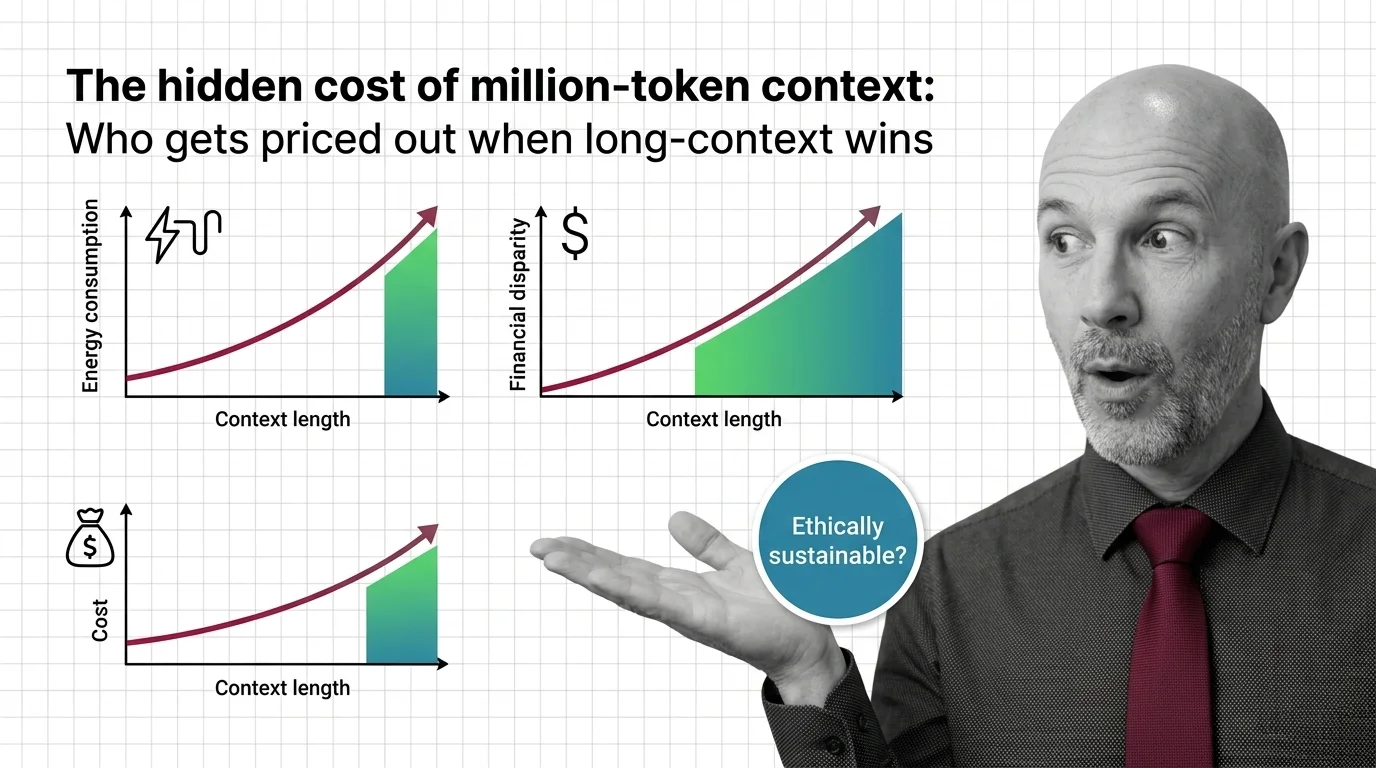
Table of Contents
The Hard Truth
A million-token context window is sold as convenience: paste everything in, let the model sort it out. But convenience is never evenly distributed. What happens when the default way of building with AI quietly excludes everyone who cannot afford to run it?
The pitch is seductive. Drop your entire codebase, every contract, the whole research corpus into a single prompt and let the model decide what matters. No retrieval pipelines, no chunking, no vector store to maintain. Convenience encoded as a frontier feature. But convenience is never neutral, and the bill for this one is being quietly passed to people who never asked to pay it.
The Question Vendors Are Not Asking
For most of the last two years, the conversation about Long Context Vs RAG has been framed as a technical contest — which architecture retrieves better, which one hallucinates less, which one wins on long-document benchmarks. Useful questions, all of them. But they share a quiet assumption: that the choice belongs to whoever is building the system.
That assumption deserves to be questioned. Because the moment a frontier vendor sets pricing, energy demand, and infrastructure prerequisites for a million-token call, the choice has already been narrowed for everyone downstream. The actual question is not which architecture is better on a leaderboard. It is who can still afford to participate when the default prompt size expands by a factor of a thousand.
What the Convenience Argument Gets Right
The case for long-context is genuinely strong, and it deserves to be heard at full strength before it is criticized. RAG pipelines are operationally expensive. Chunking strategies leak nuance. Embedding models age. RAG Evaluation is its own engineering discipline, and many teams that adopt retrieval discover, six months in, that the quality of their answers depends less on the model and more on how well their retrieval layer was tuned.
A million-token window collapses that complexity into a single call. No retrieval layer, no embedding drift, no chunking heuristic to argue about. Anthropic positions this directly as an economics differentiator — Opus 4.7 charges $5 per million input and $25 per million output across the full one-million-token window with no long-context surcharge (Anthropic News). For a development team that values architectural simplicity, that is a real and defensible offer. The convenience argument is not wrong. It is just incomplete.
The Hidden Variable in the Pricing Curve
Where the argument quietly breaks is the moment Inference costs are examined honestly across the field. Two of three frontier vendors price long context as a premium good. Gemini 2.5 Pro charges $1.25 per million input below 200K tokens but doubles to $2.50 above that threshold (Google AI Docs). GPT-5.5 goes further: a single prompt over 272K tokens flips the entire session to twice the input price and 1.5× the output price for the rest of the conversation (OpenAI Docs). One large prompt, and every subsequent message in that session is taxed.
The energy footprint moves in the same direction, only steeper. Attention compute scales quadratically with context length — doubling the input quadruples the work (arXiv 2507.04239). Industry estimates suggest an 800K-token query on a frontier model consumes roughly 14.1 Wh of energy, against around 0.7 Wh for a short chat — a 10–20× ratio per query (Digital Applied Report). Those figures are estimates, not measurements, but the directional signal aligns with peer-reviewed work showing the most energy-intensive models exceed 29 Wh per long prompt (Jegham et al. 2025). The IEA reports data-centre electricity consumption grew 17% year over year in 2025, with AI capacity on track to triple by 2030 (IEA News).
That is the variable hidden inside the pricing curve. Long-context is not merely “the same conversation, only longer.” It is a structurally more expensive way of asking a question, and the structure tilts every cost — financial, electrical, hydrological — in a single direction.
What an Older Discipline Knew About Default Costs
Public utility regulators learned this lesson a century ago, and the lesson is worth remembering. When a utility raises the marginal cost of a basic service — whether electricity, water, or telephony — the rate change rarely lands evenly. Large industrial users absorb the increase and continue. Small users, who have no contract leverage and no economy of scale, either ration their use or fall out of the system entirely. The practical effect of a “neutral” pricing change becomes a sorting mechanism, separating who continues to participate from who quietly disappears.
The parallel matters. A solo researcher in Nairobi cannot negotiate a prompt-caching contract. A small NGO in Manila cannot amortize a long-context surcharge across thousands of paying users. A computer-science student in São Paulo, working through a problem set on a free tier, cannot opt out of GPT-5.5’s session-wide premium once a single document pushes the conversation over the threshold. They simply stop participating, or they participate at a lower tier of capability than the people who set the defaults assume is normal.
The Default That Decides Who Belongs
Thesis: Long-context is becoming the default architecture for AI applications, and that shift, treated as a technical convenience, is quietly redrawing the line between who builds with these systems and who is locked out.
This is not an argument against long-context. It is an argument against treating it as the obvious answer. When developer documentation, tutorials, and reference implementations standardize on the assumption that you can simply paste the corpus, the lighter-weight alternatives — retrieval, Sparse Retrieval, careful prompt construction — start to look outdated rather than appropriate. The default carries normative weight. It tells builders what a reasonable AI system looks like, and that picture is increasingly one that requires a frontier API key and a patient finance team.
A back-of-envelope analysis suggests that a full-context query can run roughly a thousand times more expensive per call than the equivalent retrieval-based approach (TianPan Analysis). The figure is illustrative rather than precise — retrieval costs vary enormously by pipeline quality — but the magnitude points to something real. When the assumed-normal pattern is the more expensive one, every team that cannot afford it is implicitly told they are building wrong.
Questions Worth Sitting With
What does it mean for the future of open development if the most-documented AI patterns assume budgets that smaller actors do not have? What happens to the global research community when the default workflow for working with a long document is one most public-sector institutions cannot sustainably run?
There is also a quieter question about provenance. RAG Guardrails And Grounding exists because retrieval, done well, makes sources visible — you can audit which document supplied which claim. Long-context calls collapse that audit trail into a single opaque computation. If the default shifts toward the opaque option because it is operationally simpler, what do we lose in our ability to ask, after the fact, where an answer actually came from?
These are not questions with clean engineering answers. They are questions about which trade-offs we are willing to bake into the infrastructure that increasingly mediates how knowledge is made.
Where This Argument Is Weakest
The argument has real vulnerabilities, and they should be named. Sub-quadratic attention research, if it delivered on its long-standing promises, could collapse the energy and cost gap that this essay treats as structural — though independent analyses suggest many such claims have not held up in practice (LessWrong). Anthropic’s flat-rate pricing also undercuts the premise: if other vendors follow, the access argument weakens considerably (Anthropic News). And no clean dataset yet quantifies which actors actually drop out at higher context tiers; the exclusion case rests on pricing curves and infrastructure economics, not on observed user-loss data. If those curves flatten or reverse, the thesis weakens with them.
The Question That Remains
Convenience always looks free until you ask who is paying for it. The deeper question is not whether million-token context windows are useful — they clearly are — but whether we are willing to let “useful for the well-resourced” quietly become “the way AI is built.” Who do we owe a seat at this table, and what does it cost us, ethically, to keep that seat available?
— Ethically, Alan.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors