The Hidden Bias in Tokenizers: Why Non-English Speakers Pay More Per Token
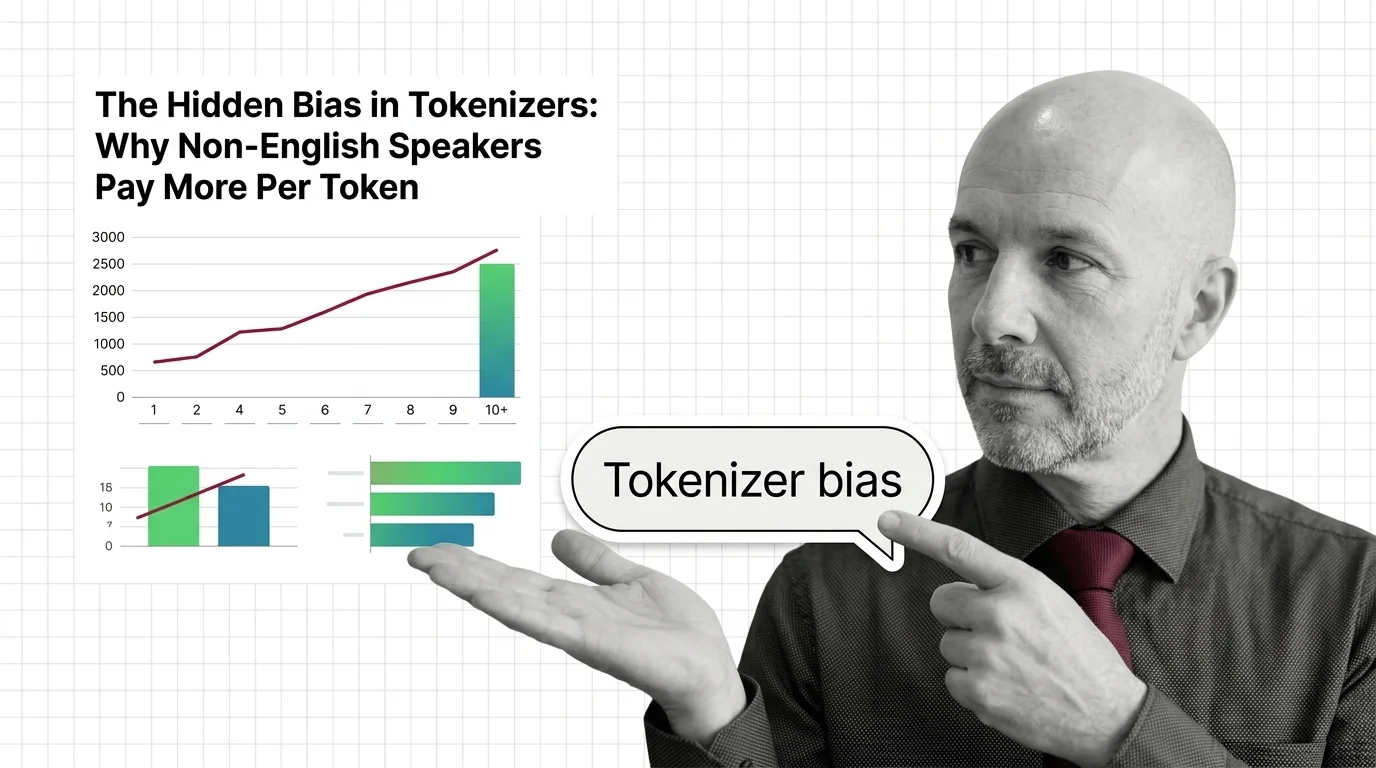
Table of Contents
The Hard Truth
What if the tool that promises to democratize intelligence charges different prices for different mother tongues — not by design, but by the quiet inheritance of whose language was optimized first?
Every major LLM API charges by the token. The price per token is the same regardless of language. But the number of tokens required to express the same idea is not — and that gap, invisible on the pricing page but enormous on the invoice, is where bias hides in plain sight.
The Price of a Word
Consider a sentence. In English, a Transformer Architecture processes it through a Tokenizer Architecture that splits text into subword units — pieces of meaning the model can ingest. The sentence “The cat sat on the mat” might cost six or seven tokens. The same sentence in Burmese, Tibetan, or Yoruba might cost forty, sixty, or — in the most extreme documented cases — over a hundred.
This is not hypothetical. A study evaluating 17 different tokenizers across multiple languages found that some languages require up to 15x more tokens than English for equivalent text, though this represents a worst-case figure for specific language pairs rather than a median (Petrov et al.). The same information. The same API endpoint. A radically different bill.
Who decided that was acceptable? And how did a compression algorithm become a mechanism for pricing some languages out of the conversation?
The Reasonable Defense
The engineers who built these systems are not villains, and the argument for current Subword Tokenization designs is genuinely strong. Algorithms like Byte Pair Encoding, Wordpiece, and Unigram Tokenization solve a real problem — they create finite vocabularies from infinite language. A Decoder Only Architecture or Encoder Decoder Architecture needs a fixed vocabulary to function, and subword tokenization provides one that balances coverage against computational cost.
The logic is elegant: train on a large corpus, identify the most frequent character sequences, merge them into tokens. English dominates the training data because English dominates the internet. OpenAI’s Tiktoken library — the tokenizer behind GPT models — expanded its vocabulary from 100,000 tokens in cl100k_base to 200,000 in o200k_base, improving non-Latin compression in the process (OpenAI tiktoken). The gap narrowed. Progress was made.
And yet the gap persists. Expanding the vocabulary helped, but no published study has quantified exactly how much disparity remains after the expansion. The improvement is real. The sufficiency of that improvement is an open question — one the industry seems content to leave unanswered.
What Efficiency Left Behind
The hidden assumption underneath this entire architecture is that English-centric optimization is a neutral starting point. It is not. When training data is approximately 95% English and code — as documented for Llama 3 (Maksymenko & Turuta) — the resulting tokenizer learns to compress English efficiently and treats everything else as residual. Not as a secondary priority. As leftover.
That residual is not trivial. Non-Latin, morphologically complex languages consistently produce token ratios three to five times higher than English for equivalent content (Lundin et al.). Arabic text can incur processing costs roughly three times higher than English for the same semantic content, though exact figures vary by model and tokenizer version (Predli Blog). And the consequences extend beyond invoices — there is a consistent correlation between higher token counts and lower model accuracy across all tested models and subjects, measured across 16 African languages on the AfriMMLU benchmark (Lundin et al.).
The cost is not just financial — it is epistemic. When your language produces more tokens, the model sees your meaning through a more fragmented lens. The Attention Mechanism must attend across more positions. The context window fills faster. The same question, asked in a language that happens to tokenize poorly, receives a qualitatively different — and measurably worse — answer.
This is where the technical artifact becomes an ethical problem. And this is where we should stop treating it as an engineering inconvenience.
A Tariff No One Voted For
There is a useful analogy outside technology. Trade tariffs are taxes imposed at borders — they make foreign goods more expensive, protecting domestic production. Tokenization disparity functions as a kind of invisible tariff on non-English participation in the AI economy. The border is not geographic. It is linguistic. And unlike trade tariffs, nobody debated this one, nobody voted on it, and most people subject to it do not know it exists.
As of early 2026, major API providers charge per million tokens — GPT-5.2 at $1.75 input and $14 output, Claude Sonnet 4.5 at $3 input and $15 output, Gemini 3.1 Pro at $2 input and $12 output (PricePerToken). The per-token price is language-blind. But the per-idea price is not. When doubling the token count leads to roughly quadrupling the training cost and computation time (Lundin et al.), the economics compound in ways that systematically disadvantage anyone whose language was underrepresented in the training corpus.
Glitch Tokens — those strange artifacts where tokenizers produce nonsensical or unstable outputs — appear disproportionately in underrepresented languages, a quiet signal that the vocabulary was never designed with them in mind.
The Architecture of Exclusion
Thesis: Tokenizer design, as currently practiced, encodes a structural economic bias against non-English speakers — not through intent, but through the inherited assumption that English-first optimization is linguistically neutral.
This is not a conspiracy. It is something harder to address — an emergent property of optimization under constraints that nobody questioned early enough. The engineers optimized for the data they had. The data they had reflected existing power structures. The resulting system perpetuates those structures at scale, through infrastructure that looks too technical to be political.
The question of accountability is uncomfortable precisely because it has no clean answer. Is the tokenizer designer responsible? The dataset curator? The API provider who sets uniform per-token pricing while knowing that tokens are not uniform across languages? The industry that collectively decided English-internet text was a sufficient foundation for “universal” intelligence? Each actor made individually reasonable decisions. The aggregate outcome is a system where your mother tongue determines how much intelligence costs you — and how much intelligence you receive in return.
Questions the Builders Owe
I am not going to prescribe solutions. The problem is not primarily technical — it is political and economic. Custom tokenizers for specific language families exist. Vocabulary expansion continues. Byte-level models that bypass tokenization entirely are being explored. The technical paths forward are multiple and known.
The harder questions are about willingness. Who pays for multilingual tokenizer research when the paying customers are predominantly English-speaking? Who decides when “good enough” compression for Amharic or Bengali becomes a priority rather than a footnote? At what point does a pricing model that charges equally per token — while knowing that tokens are not equal across languages — become something other than an engineering trade-off?
These are not questions an architecture diagram can answer. They require something the AI industry has been reluctant to engage with — an honest accounting of who this technology serves and who it quietly excludes.
Where This Argument Weakens
Intellectual honesty demands acknowledging the counterarguments. The disparity is narrowing — o200k_base is demonstrably better than cl100k_base, and future tokenizers will likely improve further. Byte-level and character-level models may eventually render this entire problem obsolete. The market incentive to serve non-English speakers is growing as AI adoption expands globally, and economic pressure alone may close the gap faster than any ethical argument could.
It is also worth noting that tokenizer design involves genuine engineering trade-offs — larger vocabularies improve compression for minority languages but increase model size and memory requirements for everyone. The optimization problem is real, not fabricated.
If multilingual tokenization reaches rough parity within the next few years through normal market forces, the structural bias I have described here will have been a transitional artifact rather than an enduring injustice. That is possible. Whether it is likely is a different question — and “possible” has never been the same thing as “probable.”
The Question That Remains
The technology to reduce tokenization disparity exists. The research documenting the harm is published and growing. What remains is a question not about capability but about priority — and priorities reveal values more honestly than mission statements ever will.
If the most widely used AI systems in history charge some languages more than others for the same understanding, and if that disparity maps neatly onto existing global inequalities, then we are not building universal intelligence. We are building intelligence that speaks every language but listens best to the ones that were already loudest.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors