The Benchmark Trap: How MMLU Optimization Drives Data Contamination and Rewards Western Academic Bias
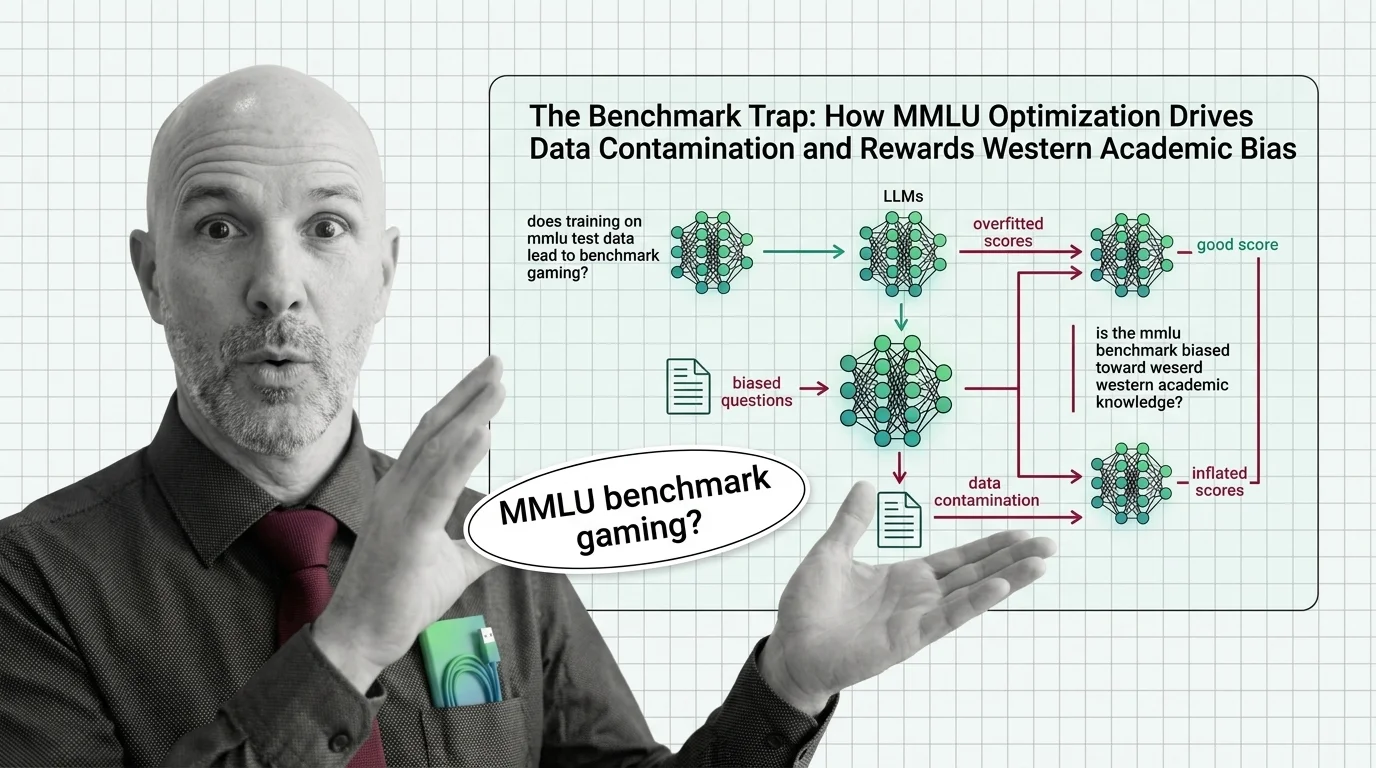
Table of Contents
The Hard Truth
What if the test that crowned the smartest AI in the room was broken from the start — riddled with errors, saturated with its own answers, and blind to most of the world?
For four years, a single benchmark has served as the unofficial IQ test for large language models. Labs race to top its leaderboard. Investors cite its scores. Journalists use them as shorthand for progress. But the MMLU Benchmark has never been examined with the rigor we demand from the systems it claims to measure — and the cracks are now too wide to ignore.
The Consensus That Built Itself
When MMLU arrived in September 2020 — 15,908 multiple-choice questions spanning 57 subjects — it looked like exactly what the field needed: a single, standardized yardstick for measuring how much a language model “knows.” The appeal was obvious. Unlike narrow benchmarks that tested code generation or arithmetic in isolation, MMLU promised breadth. From abstract algebra to professional medicine, it appeared to capture something close to general understanding.
And the field embraced it with almost no friction. Model Evaluation became, in practice, MMLU evaluation. The number went up, the press releases followed, and the community settled into a rhythm where a higher score meant a better model — full stop. That rhythm persisted long after the instrument deserved scrutiny.
The Reasonable Case for a Universal Yardstick
The desire for a single benchmark is not naive. Researchers need comparable metrics. Journalists need legible shorthand. Product teams need a way to track progress across model generations. MMLU filled a vacuum that the field desperately wanted filled, and it did so at a moment when Few-Shot Learning was making language models seem genuinely capable of general reasoning for the first time.
The logic was seductive: if a model can answer questions about virology, jurisprudence, and world history, it must possess something approaching broad understanding. That logic held — until the test itself started to crack under the weight of the optimization it incentivized.
The Score That Ate the Test
The first crack is in the test’s own integrity. A systematic audit found that 6.49% of questions in a 5,700-question sample contain outright errors — and in the Virology subset, that figure reaches 57% (Gema et al.). When more than half the questions in a subject area are wrong, the benchmark is not testing the model’s knowledge. It is testing the model’s willingness to agree with a flawed answer key.
The second crack runs deeper. Benchmark Contamination is no longer a theoretical concern — it is measurable. In an analysis of GPT-4-era models, GPT-4 achieved a 57% exact match rate when asked to guess answer options it had never been shown, a contamination signal suggesting the model had encountered the test data during training (Deng et al.). That finding predates the current generation of frontier models, and exact contamination rates for 2025-2026 releases remain unverified. But the structural incentive has not changed. If anything, it has intensified.
What happens when you strip out the contaminated questions? Microsoft’s MMLU-CF, accepted at ACL 2025, provides an uncomfortable answer: double-digit accuracy collapses across leading models. GPT-4o fell from 88.0% to 73.4% — a 14.6-point drop. Qwen2.5-72B dropped 13.7 points. Llama-3-70B, 13.1 (Microsoft MMLU-CF). The gap between the reported score and the contamination-free score is not noise. It is the distance between what we measured and what we thought we measured.
Frontier models now cluster above 88% accuracy on the original MMLU, against a human expert baseline of roughly 89.8%. The benchmark is saturated. The race it was designed to adjudicate is functionally over — and it ended not because models became more capable, but because the test stopped being able to tell the difference. Artificial Analysis has already dropped MMLU Pro from its Intelligence Index in favor of real-world task evaluations. That is not a methodological preference. It is a concession that the numbers stopped meaning what everyone assumed they meant.
Whose Knowledge Counts?
If contamination is the first betrayal of MMLU’s promise, cultural bias is the second — and the quieter one. An analysis of the benchmark’s content found that 28% of all questions require culturally sensitive knowledge, and 84.9% of geography questions focus exclusively on North American or European regions (Singh et al.). The test does not just measure knowledge. It measures a particular kind of knowledge, from a particular tradition, expressed in a particular language.
The consequences are not abstract. On multilingual extensions of MMLU, models suffer up to a 38-point accuracy drop when evaluated in low-resource languages like Swahili compared to English (LXT). That is not a performance gap. It is a measurement artifact dressed up as an intelligence deficit. The model did not become less capable. The test simply stopped speaking its language — and then penalized it for the silence.
Global MMLU, a 42-language expansion with culturally sensitive subsets, is one attempt to address this (Singh et al.). NIST’s AI 800-3 report, published in February 2026, takes a different approach — advocating statistical evaluation frameworks over raw accuracy scores (NIST). Both represent an acknowledgment that the old yardstick was measuring the wrong thing. But acknowledgment and adoption are not the same, and MMLU scores still dominate the headlines that shape funding decisions.
The Instrument Became the Objective
Here is the thesis, stated plainly: MMLU measures optimization, not understanding. The models that score highest are not necessarily the models that know the most. They are the models most thoroughly trained on the test itself, evaluated on questions that privilege one civilization’s academic canon, and scored by a methodology that cannot distinguish memorization from reasoning.
This is not a technical failure. It is an epistemic one. We built a Confusion Matrix for intelligence and then forgot that every matrix encodes assumptions about what counts as a correct answer — and whose answers count at all. The benchmark became the objective, and the objective replaced the question it was supposed to answer.
Questions We Owe the Measurement
If MMLU is broken, what replaces it? The instinct is to build a better benchmark — more questions, more languages, better quality control. That work matters. But it also risks repeating the same structural error: the belief that a single test, properly designed, can capture something as complex and contested as understanding.
Maybe the deeper question is not how to build a better yardstick, but whether reducing intelligence to a single number is itself the problem. Precision, Recall, and F1 Score metrics work because they measure defined, bounded tasks. “General knowledge” is neither defined nor bounded. Who decides what belongs in the test — and what that decision reveals about the test-makers — may matter more than any score the test produces.
Where This Argument Is Weakest
The vulnerability in this argument is real. Without standardized benchmarks, comparison becomes impossible, and the field loses its shared language for progress. The alternatives — human evaluation, task-specific testing, statistical frameworks like those proposed by NIST — are more nuanced but also more expensive, slower, and harder to communicate. It is possible that a flawed benchmark, openly acknowledged as flawed, remains better than no benchmark at all. If the community abandons MMLU without converging on a replacement, the vacuum may be filled by something worse: marketing claims with no empirical anchor whatsoever.
The Question That Remains
We built a test, optimized for the test, and then celebrated the optimization as intelligence. The question is not whether MMLU is broken — the evidence for that is already in. The question is what it means that we kept using it long after we knew.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors