The Attention Monopoly: How One Mechanism Shapes Who Gets to Build AI
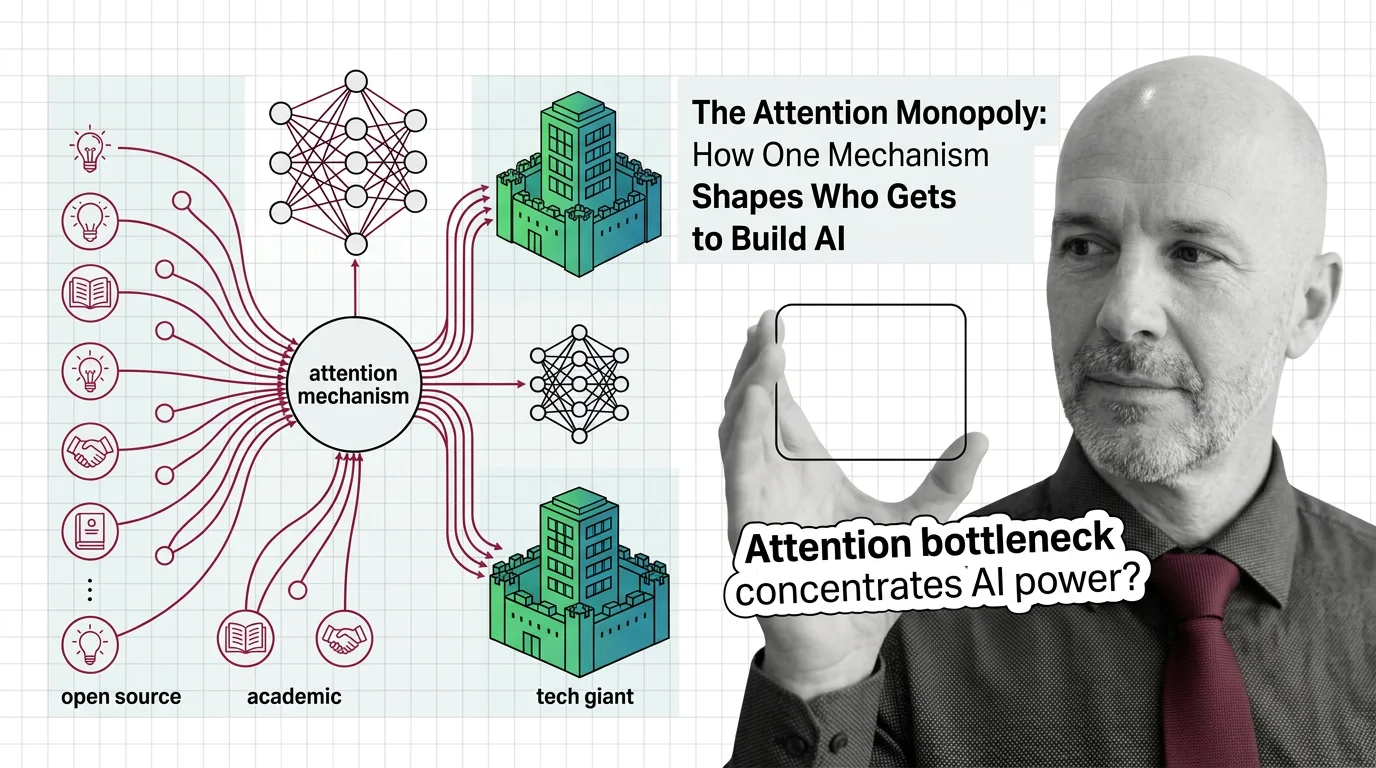
Table of Contents
The Hard Truth
A single mathematical operation — scaled dot-product attention — sits inside every frontier AI model on Earth. What happens when the computational cost of that one operation determines which organizations get to participate in the future of intelligence?
The Question We’re Not Asking
We talk endlessly about AI alignment, about bias in training data, about whether models should be open or closed. These are important conversations. But there is a quieter question hiding beneath all of them, one that rarely surfaces in policy debates or conference keynotes: what does it mean when a single architectural choice — the Attention Mechanism — functions as a gate that determines who can afford to build the most capable systems?
The original 2017 paper by Vaswani et al. has accumulated over 173,000 citations as of 2025 (Wikipedia). That number alone signals something beyond academic influence. It signals a kind of gravitational lock-in, a world where nearly every serious effort in language modeling orbits around one mechanism and the infrastructure it demands.
The question is not whether attention works. It works remarkably well. The question is what its dominance costs us — and who pays.
What We Think We Know
The conventional wisdom runs something like this: attention democratized AI. Before transformers, sequential models like RNNs were slow to train and difficult to scale. The Transformer Architecture replaced recurrence with parallelism, and the Softmax-weighted Query Key Value mechanism at its heart allowed models to learn rich, context-dependent representations. The result was an explosion of capability — machine translation, code generation, multimodal reasoning — that has genuinely expanded what is possible.
And there is a reasonable case that this expansion benefits everyone. Open-weight models exist. Inference costs are falling. Techniques like Flash Attention have made attention faster and more memory-efficient, with FlashAttention-3 achieving up to 75% utilization of H100 GPU capacity (Tri Dao’s Blog). Efficiency research — low-precision training, sparse attention variants — has reportedly reduced some training costs significantly, though the magnitude depends on the source and workload.
This is the strongest version of the optimistic position: attention is hard, but the ecosystem is making it cheaper, and the benefits are flowing outward.
What We’re Missing
The hidden assumption inside that optimism is that efficiency gains will outpace concentration. That making attention cheaper at the margin will counteract the structural tendency of attention-based training to consolidate around the wealthiest players.
But look at the numbers. Frontier training costs have grown at roughly 2.4x per year since 2016 — with a 95% confidence interval of 2.0x to 3.1x — and are projected to cross the billion-dollar threshold by 2027 (Epoch AI). Epoch AI’s analysis of 45 frontier models concludes that these runs are already “too expensive for all but the most well-funded organizations.” Efficiency improvements chip away at the per-unit cost, yes. But the ambition of what counts as “frontier” scales faster than the savings. The goal posts move. And they move in a direction that favors those who can write the largest checks.
This is the pattern that attention’s quadratic complexity — O(n^2 d), where n is sequence length and d is hidden dimension (Fichtl et al.) — makes structurally inevitable. Every time you want a model to attend to a longer context, to hold more of the world in working memory, the cost doesn’t grow linearly. It compounds. And compounding costs create compounding barriers.
The Blind Spot
There is a useful analogy outside of computer science. In the history of broadcasting, the move from print to radio to television progressively raised the capital required to reach a mass audience. Each new medium was celebrated as a democratizing force — and each ultimately concentrated control in fewer hands, because the infrastructure costs selected for scale. The content changed. The power dynamics didn’t.
Attention is AI’s broadcasting tower. The mechanism itself is elegant, almost simple in its formulation. But the infrastructure required to train it at frontier scale — the GPU clusters, the energy, the engineering teams — creates a selection pressure that has nothing to do with ideas and everything to do with capital.
Consider that FlashAttention, the most significant efficiency improvement for attention in recent years, is optimized specifically for NVIDIA GPUs (DigitalOcean). An optimization designed to make attention more accessible simultaneously deepens dependency on a single hardware vendor. The efficiency gain is real. The lock-in is also real. And the lock-in benefits those who can afford the hardware at scale.
Meanwhile, sub-quadratic alternatives exist. Linear Attention variants, sub-quadratic state-space models like Mamba, RWKV-7 with constant memory per token — these architectures offer fundamentally different cost curves (Fichtl et al.). Yet as of late 2025, no sub-quadratic model occupies a position in the LMSys top 10 (Fichtl et al.). The frontier remains quadratic. The frontier remains expensive. And the frontier is where the power accumulates.
The Uncomfortable Truth
Thesis (one sentence, required): The attention mechanism’s quadratic cost structure functions as an economic filter that concentrates frontier AI development among a shrinking number of organizations, and no amount of efficiency optimization changes the underlying dynamic.
This is uncomfortable because it means the technical choice that made modern AI possible is also the technical choice that narrows who gets to shape it. Not through malice, not through conspiracy — through arithmetic. When your core operation scales quadratically with ambition, ambition becomes a luxury good.
The implications extend beyond who trains the largest models. They reach into what gets researched, which problems get prioritized, whose values get encoded into systems that will mediate billions of daily interactions. When frontier development is concentrated, the diversity of approaches — technical, ethical, cultural — narrows with it. We don’t just lose competitors. We lose perspectives.
So What Do We Do?
I am not going to offer a five-point plan. The structural dynamics at play are not amenable to quick fixes, and pretending otherwise would be dishonest.
But there are questions worth sitting with. If sub-quadratic architectures can match attention’s quality at fundamentally lower cost, what would it take for the research community to treat them as more than curiosities? What role should public funding play in building training infrastructure that isn’t controlled by three or four companies? And if attention’s dominance is partly a function of ecosystem inertia — the tooling, the libraries, the talent pipelines all optimized for transformers — how do we create credible alternatives without waiting for the incumbent architecture to fail on its own?
NIST’s launch of an AI Agent Standards Initiative in February 2026 (NIST) gestures toward interoperability and security, but standards for agents downstream do little to address concentration in the training layer upstream. The policy conversation hasn’t caught up to the infrastructure reality.
What Would Make This Wrong
If sub-quadratic models were to reach frontier quality within the next two years — matching attention-based systems on reasoning, code, and multimodal tasks while training at a fraction of the cost — the concentration dynamic I’ve described would weaken significantly. The structural barrier would dissolve. That possibility is real, and it is the strongest counterargument to this thesis.
The Question That Remains
A single mechanism made modern AI legible, powerful, and astonishingly capable. It also made modern AI expensive in ways that select for wealth over wisdom. The question is whether we will notice that selection pressure before it finishes shaping the world — or only after.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors