Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Table of Contents
ELI5
Attention lets a transformer weigh how much each word should influence every other word. Self-attention looks within one sequence, cross-attention bridges two sequences, and causal masking prevents future tokens from leaking backward.
Feed a Transformer Architecture the sentence “The bank was steep, so the river current picked up speed” and it will correctly associate “bank” with “steep” and “river”—not with money. It does this not because it understands geography, but because somewhere inside its attention layers, the word “bank” issued a query that matched the keys of “steep” and “river” far more strongly than the key of “money.” That matching operation—a dot product in projected space—is the smallest decision unit inside every modern language model. And it comes in three distinct flavors, each with a different geometry and a different cost.
The Mathematical Vocabulary Underneath
Before dissecting the mechanism, the vocabulary needs to be precise. Attention is not a metaphor. It is a sequence of linear algebra operations with a probabilistic normalization step at the center, and without a clear picture of those operations, everything downstream looks like guesswork.
What linear algebra and probability concepts do you need before learning attention mechanisms?
Three concepts carry almost all the weight.
Matrix multiplication is the core operation. When a model computes attention, it multiplies a query matrix Q against a transposed key matrix K-transpose. The result is a matrix of raw alignment scores—one score for every pair of tokens in the sequence. If you have never traced a matrix multiply by hand, the entire Attention Mechanism will remain opaque.
Vector dot products are how individual alignment scores form. The dot product between a query vector and a key vector measures directional similarity in a projected space. High dot product means the two vectors point in roughly the same direction; low dot product means they are orthogonal—irrelevant to each other. The model learns these projections during training, which means it learns what counts as similar.
Probability distributions via Softmax turn raw scores into weights that sum to one. The softmax function exponentiates each score and normalizes, converting a row of arbitrary real numbers into a proper distribution. The result: every token gets a probabilistic budget for how much attention it pays to every other token.
The canonical formulation, introduced by Vaswani et al. in 2017, compresses all of this into a single line:
Attention(Q, K, V) = softmax(QK-transpose / sqrt(d_k)) V
The sqrt(d_k) term— Scaled Dot Product Attention—prevents the dot products from growing so large that softmax saturates into a near-one-hot distribution. Without this scaling factor, gradients collapse and training stalls.
That equation is the entire mechanism. Everything that follows is about who provides Q, K, and V—and what you choose to mask.
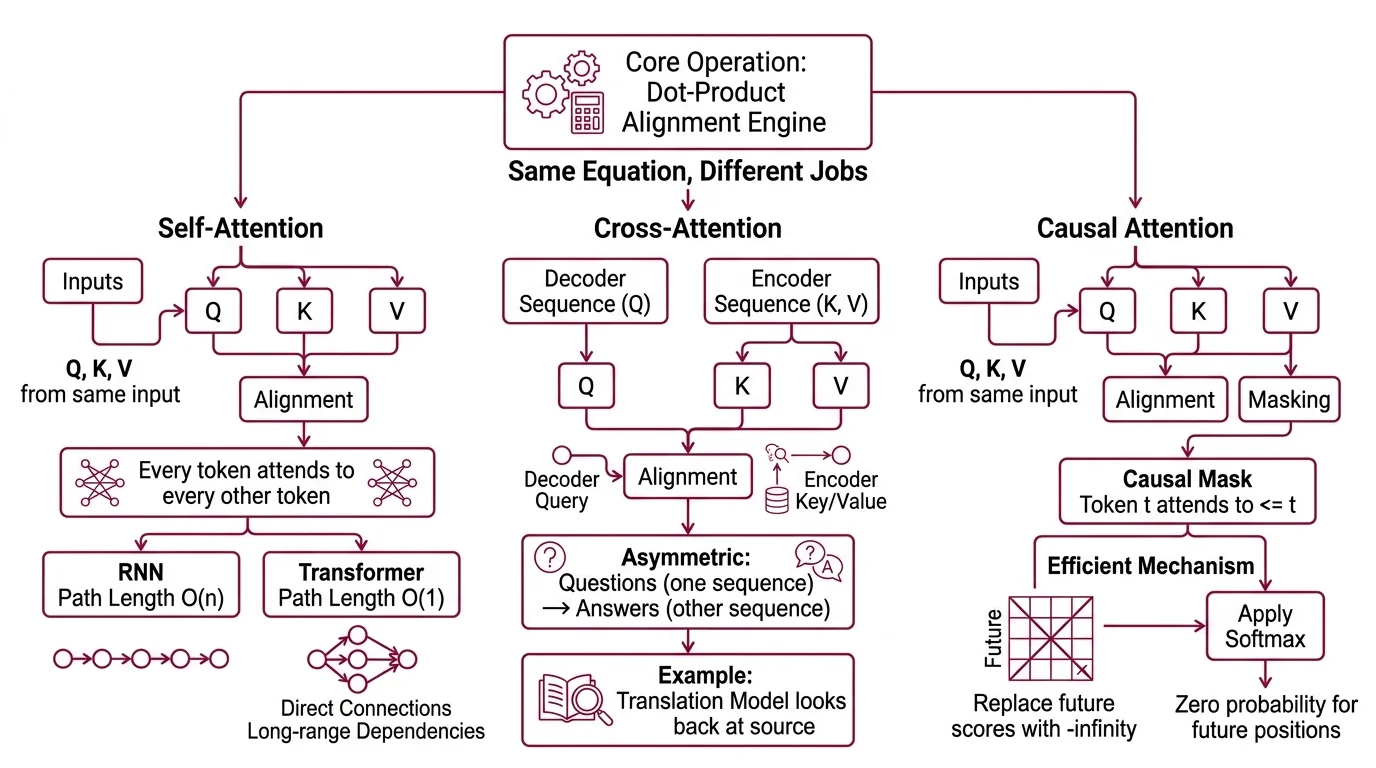
Same Equation, Three Different Jobs
The distinction between self-attention, cross-attention, and causal attention is not about different formulas. It is about different routing configurations applied to the same core operation. Think of it as one machine—a dot-product alignment engine—connected to three different wiring diagrams.
What is the difference between self-attention, cross-attention, and causal attention?
Self-attention is the purest configuration. Q, K, and V all come from the same input sequence. Every token attends to every other token—including itself. The result is a maximum information path length of O(1): any token can directly influence any other token in a single layer, regardless of distance. Compare that to O(n) for a recurrent network, where information must traverse the entire sequence step by step.
This is why transformers handle long-range dependencies so effectively. Not because transformers are “smarter,” but because the wiring diagram allows direct connections.
Not magic. Geometry.
Cross Attention splits the wiring. The query comes from one sequence—typically the decoder—while keys and values come from another sequence, typically the encoder output (Sebastian Raschka). This is how a translation model “looks back” at the source sentence while generating the target. It is how a multimodal model reads an image encoding while producing text. The asymmetry is the point: one sequence asks questions; the other provides answers.
Causal attention (also called masked self-attention) uses the same self-attention wiring but adds a constraint: token t can only attend to tokens at positions less than or equal to t. The mechanism is elegant—replace all future-position scores with negative infinity before applying softmax, so those positions receive zero probability mass (Sebastian Raschka). This is more numerically efficient than applying softmax first and then zeroing out future positions, because it avoids a renormalization step.
Causal masking is what makes autoregressive generation possible. Without it, a language model generating the fifth token would already “know” the sixth—which is the token it is supposed to predict.
The three variants are not alternatives. In the original transformer, the encoder uses self-attention, the decoder uses causal self-attention, and the decoder-to-encoder bridge uses cross-attention. All three operate inside the same architecture, simultaneously.
The Quadratic Wall and Who Is Trying to Climb It
Self-attention’s O(1) path length comes at a price that every engineer working with long sequences eventually hits. The cost is quadratic, and the quadratic is not optional.
Why does standard self-attention scale quadratically with sequence length and what are the practical limits?
The QK-transpose multiplication produces an n-by-n matrix of attention scores—one entry for every token pair. For a sequence of 1,000 tokens, that matrix has 1,000,000 entries. For 10,000 tokens: 100,000,000. The computational complexity is O(n-squared times d) in time and O(n-squared) in memory, where n is sequence length and d is the model dimension.
This is not an implementation quirk. Keles et al. proved in 2022 that O(n-squared) time is necessary for exact self-attention unless the Strong Exponential Time Hypothesis is false—a conjecture most complexity theorists consider unlikely to be overturned. The quadratic wall is a proven theoretical bound, not an engineering limitation waiting for a clever fix.
The practical consequence: as of early 2026, training contexts for dense self-attention models typically range from roughly 16K to 32K tokens on current GPU hardware, with inference extending somewhat further depending on available memory. These limits shift with hardware generations and should be treated as approximate.
Two engineering responses have gained wide adoption.
Grouped Query Attention (GQA) reduces memory consumption by sharing key-value heads across multiple query heads—an intermediate strategy between full multi-head attention and the extreme compression of multi-query attention. Ainslie et al. introduced GQA at EMNLP 2023, and it has since become the default in frontier models including Llama 2 and 3, Mistral 7B, Gemma 3, and Qwen3 (IBM Research).
FlashAttention attacks the memory bottleneck differently—not by reducing mathematical operations but by restructuring them to minimize GPU memory reads and writes. FlashAttention-3 achieves 740 TFLOPS in FP16 on H100 GPUs, reaching approximately 75% hardware utilization (FlashAttention-3 paper). FlashAttention-4, currently in beta, targets both Hopper and Blackwell architectures; no stable release date has been announced. PyTorch 2.10 now natively exposes scaled dot-product attention through torch.nn.functional.scaled_dot_product_attention, with automatic backend selection that routes to FlashAttention when available.
Neither GQA nor FlashAttention eliminates the quadratic scaling. They reduce the constant factors and memory overhead—making longer sequences practical without changing the fundamental complexity class. The bound remains; the engineering question is how close to that bound you can afford to operate.
What the Attention Matrix Tells You and Where It Misleads
The practical implications follow directly from the mechanism.
If you increase sequence length, expect memory to grow quadratically—not linearly. A model that comfortably processes 8K tokens will not merely double its memory consumption at 16K; it will quadruple it, because the attention matrix scales with the square of token count.
If you freeze the encoder and fine-tune only the decoder, cross-attention weights become your adapter. The decoder learns new query projections to extract different information from the same encoder representation—a principle that explains why decoder-only fine-tuning can be surprisingly effective even with frozen encoder states.
If you remove causal masking from a generative model and allow bidirectional attention, you get BERT-style encoding—useful for classification and retrieval, useless for generation. The distinction between encoder and decoder is not about separate architectures; it is about whether the attention mask allows future tokens.
Rule of thumb: when debugging unexpected transformer behavior, examine what each layer’s attention weights attend to. Tokens attending strongly to distant, seemingly irrelevant positions often reveal learned shortcuts or data artifacts—not genuine semantic relationships.
When it breaks: self-attention fails silently on sequences that exceed the model’s training context. The model does not refuse or warn; it produces confidently wrong output because the positional encodings extrapolate into untrained territory, and the attention distribution spreads across positions the model has never learned to weight correctly.
The Data Says
Attention is one equation with three wiring configurations—self, cross, and causal—each serving a different information-routing purpose inside the transformer. The quadratic cost of that equation is not an accident but a proven lower bound, and the engineering responses (GQA, FlashAttention) buy practical headroom without changing the fundamental complexity. Understanding which variant operates where—and what each mask permits—is the difference between treating a transformer as a black box and reading its internal logic.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors