SD-VAE, VQ-VAE, and NVAE: How Variational Autoencoders Power Image Generation in 2026
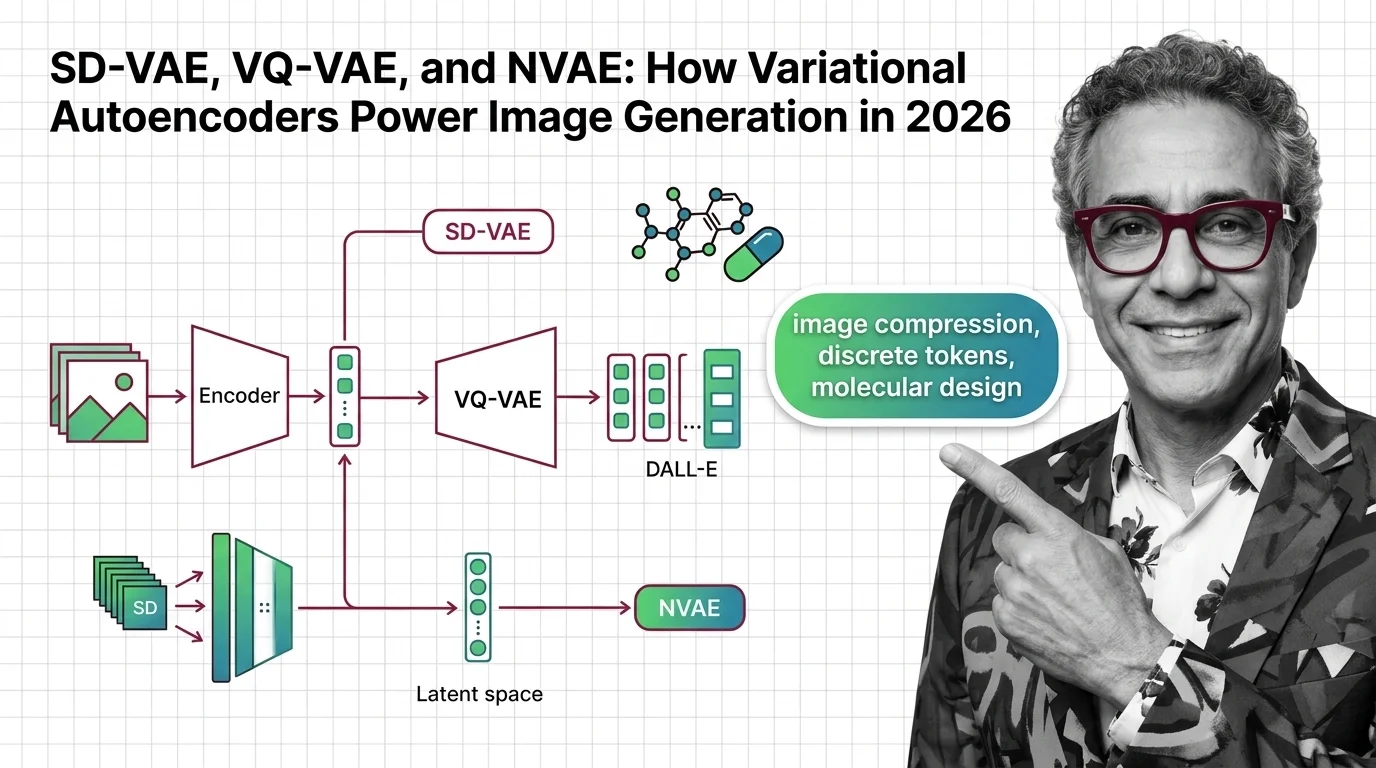
Table of Contents
TL;DR
- The shift: The VAE layer powering latent diffusion has split the field — some teams quadrupled its capacity, others are removing it entirely.
- Why it matters: VAE compression quality directly controls image fidelity and inference cost across every major diffusion model.
- What’s next: VAE-free research shows order-of-magnitude speedups, but production pipelines still run on encoder-decoder architectures.
Every image Stable Diffusion generates passes through the same gate — a Variational Autoencoder that compresses raw pixels into a format diffusion models can work with. For three years, that gate was invisible. A background component nobody questioned.
Now it’s the most contested architecture decision in generative AI.
The Compression Layer Everyone Wants to Replace
Thesis: The VAE that made Latent Diffusion viable is now the primary engineering bottleneck — and the field has split between radically upgrading it and eliminating it altogether.
The original Stable Diffusion VAE used a simple Encoder Decoder pipeline. A 512-pixel image went in, a 64-pixel representation with 4 channels came out — 48x compression (SD VAE Notes).
Unlike sequential generation built on Recurrent Neural Network architectures, VAEs compress an entire image in one forward pass. That parallel efficiency is why they became the default.
SD3 expanded to 16 channels with 12x compression. FLUX.2 from Black Forest Labs pushed to 32 channels and just 6x compression — the smallest ratio in any major model (SD VAE Notes).
Each generation trades compression for fidelity.
Then the replacement bets arrived.
SVG, presented at ICLR 2026, removes the VAE entirely. It uses pretrained DINO features instead and reports 62x faster training and 35x faster inference — though these claims come from the authors’ paper and are not yet independently replicated (arXiv, Shi et al.). NVIDIA’s SANA model swaps the VAE for DC-AE, a deep compression autoencoder achieving 32x compression (ICLR Blogposts).
These aren’t tweaks. These are architectural replacements.
Three Bets, One Component Under Siege
The evidence clusters into three directions.
Expand the channels. FLUX.2’s 32-channel VAE preserves far more image detail than the original 4-channel design. The cost is a larger tensor at every step.
Both the original SD VAE and FLUX.2 still produce known artifacts at higher resolutions — a limitation the community is actively working around (SD VAE Notes). For production systems shipping today, this is the bet that works.
Remove the VAE. SVG and DC-AE represent the most aggressive move. If comparable quality is achievable without the encoder-decoder bottleneck, the entire latent diffusion stack simplifies. Training and inference costs drop.
Extend VAE to new domains. VQ-VAE variants power neural audio codecs — Google’s SoundStream uses residual VQ to compress speech to 3 kb/s while outperforming Opus at 12 kb/s (Google Research). In drug discovery, at least four new VAE architectures — PCF-VAE, TGVAE, ScafVAE, and ICVAE — were published last year alone (Nature Sci Reports).
The architecture that image generation may outgrow is just arriving in molecular design.
Who Gains Ground
Black Forest Labs. Their FLUX.2 VAE is the clearest proof that expanding channel count works at production scale. Teams building on FLUX.2 inherit the fidelity advantage without redesigning their stack.
Drug discovery labs. VAE architectures built on the Reparameterization Trick and Evidence Lower Bound optimization are generating novel molecular candidates at a pace traditional screening can’t match. This field is years behind image generation in architecture maturity — the headroom is massive.
Audio codec teams. Residual VQ-VAE tokenizers in SoundStream and EnCodec are already in production. These tokenizers now feed into the foundational Neural Network Basics for LLMs stack for multimodal AI.
The winners picked a direction and shipped.
Who Falls Behind
NVAE. The NVIDIA paper that hit NeurIPS 2020 as a spotlight — the first VAE to generate realistic 256x256 images, achieving 2.91 bits/dim on CIFAR-10 (arXiv, Vahdat & Kautz) — remains a research landmark. But the repository hasn’t been updated in over five years.
The ideas migrated into diffusion-VAE hybrids. The codebase did not.
Teams locked to 4-channel VAEs. The gap between 4-channel and 32-channel output quality is not subtle. If your pipeline still runs on the original SD compression, you’re shipping with a constraint your competitors are removing.
Pure VQ-VAE codebook approaches. Codebook collapse remains an unsolved engineering problem. Finite Scalar Quantization already matches VQ quality without the collapse risk. DALL-E 1 used an 8,192-vector codebook to compress images into 32x32 token grids, but DALL-E 2 moved to diffusion decoders — and later versions continued that direction.
Legacy architectures don’t announce their expiration. They just stop winning benchmarks.
What Happens Next
Base case (most likely): Production systems keep VAEs for the next 12-18 months while channel counts climb. Convolutional Neural Network backbones in the encoder get deeper. VAE-free alternatives stay in research. Signal to watch: A major open-source model ships without a VAE and matches FLUX.2 image quality. Timeline: Mid-2027.
Bull case: VAE-free latent diffusion proves out at production scale. Training costs drop by an order of magnitude. The pipeline simplifies from three stages to two. Signal: Independent replication of SVG’s reported training speedup on ImageNet-scale data. Timeline: Late 2026.
Bear case: Fragmentation. Five competing compression strategies, no standard. Model interoperability breaks. Fine-tuning communities fracture along architecture lines. Signal: Two major model families ship with incompatible compression layers in the same quarter. Timeline: Already starting.
Frequently Asked Questions
Q: How does Stable Diffusion use the VAE encoder decoder to compress images into latent space? A: The VAE encoder maps a full-resolution image to a smaller spatial grid with multiple channels. The diffusion process runs entirely in that compressed format. The decoder reconstructs the final image after denoising completes. Channel count and compression ratio vary by model version.
Q: How are variational autoencoders used in drug discovery and molecular design? A: VAEs encode molecular structures into continuous representations where similar compounds cluster together. Researchers sample new points and decode them into candidate molecules. Multiple new architectures emerged last year addressing prior issues like posterior collapse.
Q: How does VQ-VAE enable discrete latent tokens in DALL-E and neural audio codecs? A: VQ-VAE maps continuous inputs to a fixed codebook of learned vectors, converting data into discrete tokens a transformer can process. DALL-E 1 used this for images. Audio codecs like SoundStream stack residual VQ layers for speech compression at extremely low bitrates.
Q: NVAE, diffusion-VAE hybrids, and ViT-VAE — where are variational autoencoders heading in 2026? A: NVAE proved deep hierarchical VAEs could match GANs on image quality, but its codebase is no longer maintained. The ideas live on in diffusion-VAE hybrids. Vision Transformer-based VAEs are replacing CNN encoders, tracking the broader shift from U-Net to DiT architectures.
The Bottom Line
The VAE layer that made latent diffusion mainstream is no longer a settled component. It’s an active battlefront — teams are either pushing channels higher or stripping the layer out entirely.
You’re either tracking this architectural split or you’re building on assumptions that expired last quarter.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors