Scraped Photos, Stripped Subjects: The Training Data Ethics Behind Every Background Removal API
The Hard Truth
What if the AI that has cut subjects out of nine-tenths of the product photos on your screen this morning was trained on millions of images of strangers who never agreed — and never even knew their photographs were used to teach a machine to ignore where they were standing?
The “Remove Background” button has become a small civilizational habit. We push it on portraits, product shots, medical scans, dating profiles, and the family photo we are about to mail to grandparents. We almost never ask what taught the model which pixels are subject and which are background — or what was paid, and to whom, for that knowledge.
The Erasure Beneath the Click
The act of separating a subject from its background looks technical. Underneath the click sits AI Background Removal, a layered pipeline that combines Semantic Segmentation, Salient Object Detection, and in some products Image Matting or Alpha Matting, sometimes guided by a Trimap that marks definite foreground, definite background, and uncertain regions.
Every one of those segmentation layers had to learn what “subject” meant. The teaching was done with photographs. And a question follows that almost nobody at the procurement meeting is willing to put on the agenda: whose photographs?
What the Defense of Scale Sounds Like
The case for treating training data as a low-priority detail is not nonsense. Computer vision is a research discipline, the argument goes; academic benchmarks like DUTS — the saliency dataset of 10,553 images behind U²-Net — were built so researchers could measure progress on the same yardstick (DUTS dataset site). Open releases like Meta’s SAM 2, governed by Apache 2.0 with the SA-V dataset under CC BY 4.0, have lowered the cost of building useful tools for everyone (Meta AI’s SAM 2 page).
The benefits are real. A small e-commerce business in Bratislava can today produce on-white product photos at a fidelity that would have required an in-house compositor a decade ago. Scientific imaging has gained accessible tools. The field genuinely needed shared benchmarks to make architectural progress visible.
So when industry voices say the data ethics question is overstated, they are not entirely wrong. Useful tools exist, useful research happened, and a great deal of it was done in good faith.
But good faith is not provenance. And benchmark culture is not a license.
The Quiet License That Was Never Granted
The hidden assumption inside the field’s defense of itself is that an academic dataset distributed for research, under whatever license its author posted to a webpage, can be quietly transmuted into the foundation of a commercial product simply because the model wrapper carries an open-source license.
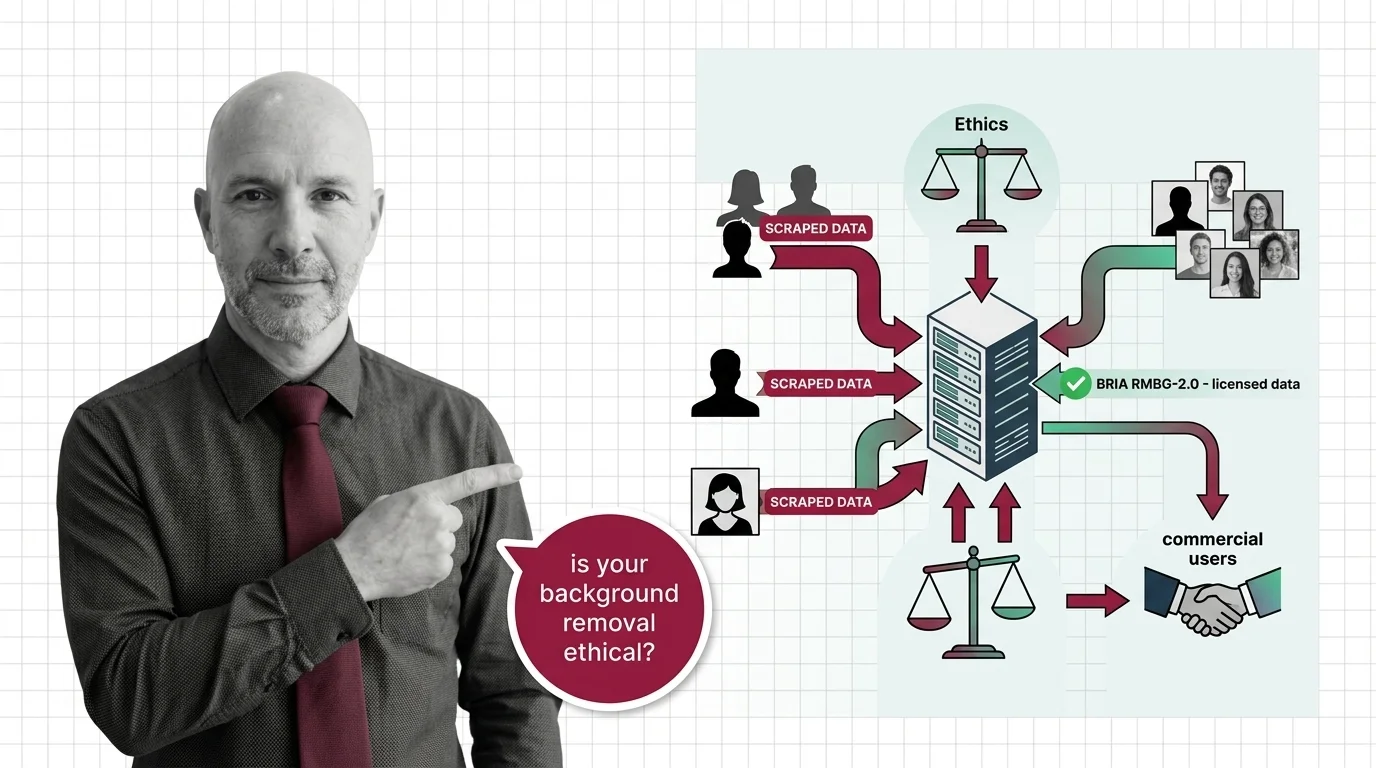
Here is the awkward technical detail. The dominant open-source pipeline ships under MIT — rembg 2.0.75, released April 8, 2026, bundles eighteen-plus model weights including u2net, isnet variants, sam, birefnet variants, silueta, and BRIA RMBG (rembg’s GitHub repository). Each set of weights carries its own license, and many were trained on datasets whose terms were never clearly granted for commercial reuse. The DUTS site states “All rights reserved by the original authors of DUTS Image Dataset” and grants no explicit commercial terms (DUTS dataset site). The wrapper says MIT. The ground beneath it says something else.
This is the licensing gap that downstream users keep stepping into without seeing. It does not feel like infringement. It feels like installing a library. The legal questions are unsettled and evolving, and they are not the heart of the matter. The heart of the matter is that the ethical question — was anyone whose face appears in the training corpus ever asked? — has been bypassed by the convenience of a single import statement.
A Different History of the Photograph
There is a longer story worth sitting with. In the late nineteenth century, when the first portrait photographers produced cabinet cards and cartes de visite, the social rule was that the photograph belonged, in some serious sense, to the sitter. The studio retained negatives; the subject’s permission was implicit in the act of sitting. This was not a legal regime. It was a moral grammar — a sense that the image of a face carried obligations that ran in both directions.
That grammar collapsed gradually across the twentieth century, and decisively when photographs migrated to the open web. By the time the first large-scale image datasets were assembled in the 2010s, the working assumption inside the research community was that anything publicly visible was, by that visibility, available. Crawl scripts inherited this assumption. The models inherited the crawl scripts. And every API that promises a clean cutout in seconds is downstream of this drift.
The photographic ethics of the studio era are not portable to the web. But the moral question they raised — does the subject of an image retain any standing when the image is processed at scale? — is something we stopped asking, not something we resolved.
What the Licensed Anomaly Reveals
Thesis: The persistent rarity of fully licensed training data in production-grade background removal is not a technical limitation but a market signal that the industry has decided consent is too expensive to pursue at scale.
BRIA's RMBG-2.0 is the exception that exposes the rule. Its model card describes a network trained on “over 15,000 high-quality, high-resolution, manually labeled (pixel-wise accuracy), fully licensed images” with self-reported balance across gender, ethnicity, and disability representation, and 87.7% photorealistic content (BRIA’s RMBG-2.0 model card). The architecture is built on BiRefNet at roughly 0.2 billion parameters. The weights ship under CC BY-NC 4.0; commercial use requires a separate paid agreement with BRIA. The licensing partners are not publicly named, so the “fully licensed” claim is a self-attestation rather than something independently auditable. But the structural pattern still matters. To produce a competitive model on provably licensed inputs, BRIA had to commit to a smaller dataset, pay for it, document it, and accept that the model would carry a paywall for commercial reuse.
Compare this with the dominant alternatives. remove.bg, owned by Canva since the 2021 acquisition of Kaleido AI (TechCrunch), prices its API from $0.20 per image with a Volume plan at $80.10 per month for 500 credits (remove.bg’s pricing page). Its training corpus has not been publicly disclosed. The platform offers an opt-in Improvement Program toggle that lets users decide whether their image will be used for future improvements (remove.bg help center). What can reasonably be inferred is that the corpus was assembled at industrial scale; what cannot be verified is whose images contributed and on what terms.
The question this asymmetry raises is uncomfortable. If consent-respecting curation is technically achievable — and BRIA’s release suggests it is — then every other vendor’s silence about training data is not an engineering answer. It is a business decision.
The Conversations We Are Owed
Several questions deserve to be sat with rather than answered too quickly.
What is the moral weight of an image of a person who was photographed for one purpose and then absorbed, without communication, into a system that teaches machines to recognize bodies in general? The face-obfuscated P3M-10k portrait benchmark — 10,421 images released as the first large-scale privacy-preserving matting dataset, with an agreement required even for download (P3M GitHub repository) — shows that the research community can build differently when it chooses to. Why has that choice remained the rare path?
Where does responsibility lie when a small developer fine-tunes an open model on a permissive license, embeds it inside a SaaS workflow, and discovers later that the underlying weights were trained on imagery from people whose consent was never sought? The German Hanseatic Higher Regional Court’s December 10, 2025 ruling in Kneschke v. LAION — which upheld the text-and-data-mining exception, but only where opt-outs from web-scraped training are machine-readable — gestures at one institutional answer (Norton Rose Fulbright). The Getty v. Stability AI dispute, in which Getty abandoned its primary copyright claims on November 4, 2025 (Bird & Bird), suggests another. Both cases involve Diffusion Models, a different family of systems entirely — and the relevance to background removal is thematic, not precedential. But the ground is moving, and segmentation pipelines do not sit safely outside the conversation just because no plaintiff has named one yet.
And what does it mean that the FTC, in early 2026, forced Clarifai to delete three million OkCupid profile photos used as training data without user consent (The Meridiem)? The settlement does not bind the segmentation industry. But it signals that biometric-relevant training corpora are being treated, increasingly, as a consent matter. Background removal sits adjacent to that category, not outside it.
These are the questions I think we are owed. They are not legal questions only. They are questions about the kind of digital society we are building when we click “Remove Background” without asking what the click is built on.
Where This Argument Is Most Vulnerable
This argument loses force if licensing-aware training data becomes commercially competitive at scale, if regulators outside the EU build the technical capacity to enforce dataset transparency, and if open-source ecosystems converge on a norm of declaring dataset provenance alongside model weights — the way software supply chains now declare dependencies. Recent shifts in dataset card practice, and licensing-conscious model releases like SAM 2, suggest the field can move when it chooses to. What remains uncertain is whether the convenience and pricing pressure of unaudited training data will continue to outpace any voluntary norm.
The Question That Remains
The image of a stranger on the open web has become a teaching example for systems that decide what counts as a subject and what counts as background. We did not vote on this. We mostly did not notice. The question we owe ourselves is whether a tool used billions of times across e-commerce, journalism, and identity infrastructure should keep being built on photographs whose subjects were never asked — and whether the existence of one vendor’s licensed alternative is enough to call the present arrangement a choice rather than an accident of market timing.
Ethically, Alan.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors