Score Mismatch, Tuning Hell: The Hard Limits of Hybrid Search Fusion

ELI5
** Hybrid Search** runs keyword and vector search in parallel and merges the ranked lists. The merge is the hard part — two rankers produce scores in different mathematical worlds, and naive averaging fails in ways teams discover only in production.
A retrieval pipeline goes live. BM25 returns the right document at rank 1. The dense retriever returns the right document at rank 1. The hybrid layer that was supposed to combine them returns the wrong document — a worse answer than either retriever alone. The two retrievers were not the problem; the merge step was. Most Retrieval Augmented Generation stacks treat fusion as an afterthought, and the fusion is where the strange behavior actually lives.
Two Rankers, Two Distributions, One Merge Step
Hybrid search combines a lexical retriever — usually BM25 over an Inverted Index — with a dense retriever that scores documents by cosine similarity in an embedding space. Both produce ordered lists of documents, and both attach numbers to those documents. At first glance the numbers look comparable.
They are not.
What are the technical limitations and failure modes of hybrid search?
Three structural failure modes account for most of the strange behavior teams report.
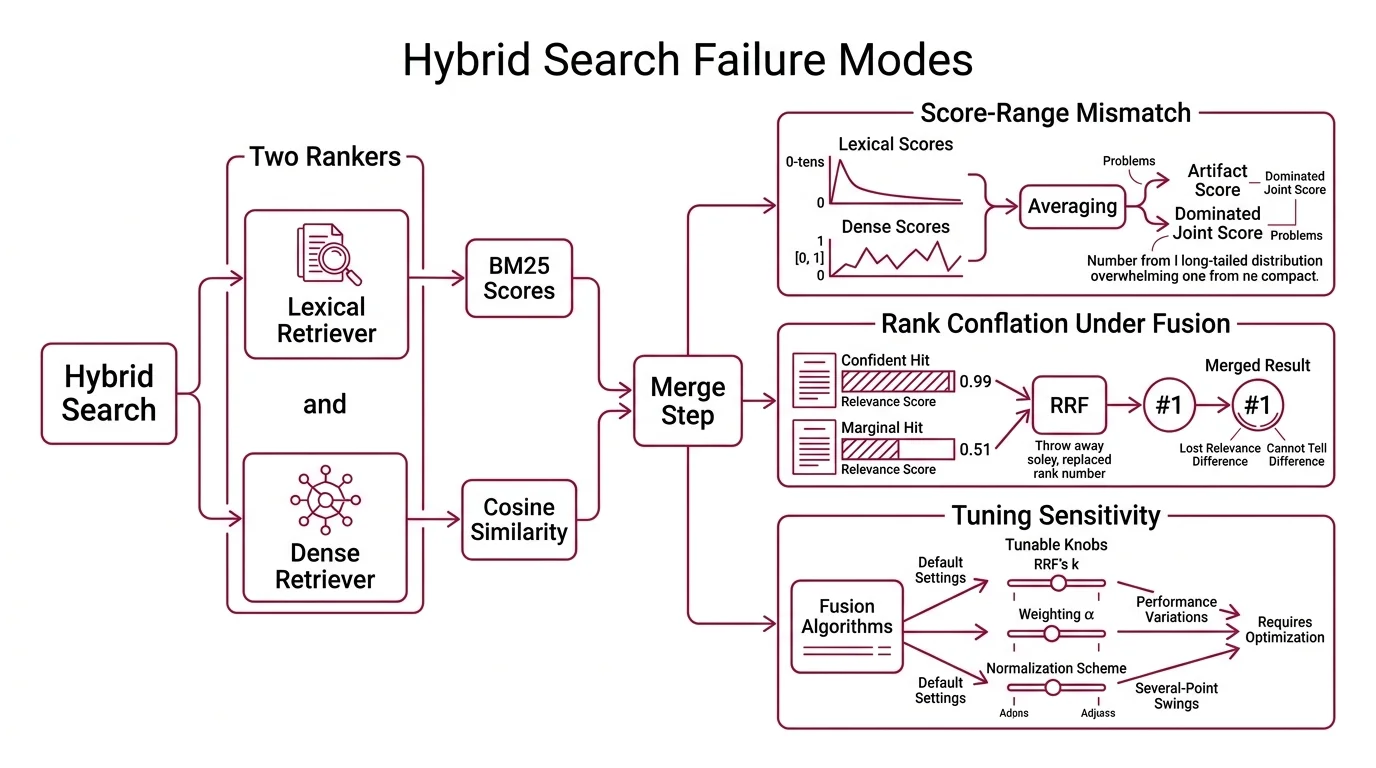
The first is score-range mismatch. BM25 scores are unbounded — on a typical English corpus they range from roughly 0 to a few tens, with the upper bound set by document statistics rather than any normalization. Cosine similarity between L2-normalized embeddings is bounded in [-1, 1] and is usually rescaled to [0, 1] before display. These are not just two different scales; they are two different distributions, with different shapes, different variances, and different sensitivities to corpus drift (Andrey Chauzov). A linear average of a number drawn from a long-tailed unbounded distribution and a number drawn from a bounded compact distribution does not produce a meaningful joint score. It produces an artifact dominated by whichever side carries the larger raw values on this particular query.
The second is rank conflation under fusion. Reciprocal Rank Fusion sidesteps the score-distribution problem by throwing the scores away and using ranks alone. That looks safe — until you notice that a #1 hit with relevance 0.99 is now indistinguishable from a #1 hit with relevance 0.51 (apxml RRF Algorithms). The merge layer has lost the ability to tell a confident retrieval from a marginal one.
The third is tuning sensitivity hiding behind the word “default.” Every fusion algorithm has at least one knob — RRF’s k constant, a weighting alpha, or the chosen normalization scheme. Published evaluations report several-point swings in NDCG@1000 and Recall@K as k sweeps from 1 to 100, despite the folk claim that RRF is k-robust (apxml RRF Algorithms). Worse, the optimal knob position is per-query-class: a global setting that works for keyword-heavy queries underperforms on paraphrased semantic queries, and vice versa (OpenSearch Blog).
Not vendor bugs. Properties of the merge problem itself.
Reciprocal Rank Fusion’s Convenient Lie
RRF is the most-used fusion method in modern hybrid retrieval because it makes the score-mismatch problem disappear. It does so by refusing to look at scores at all. The convenience is real. So is the cost — and most teams discover the cost only after they have already committed to a vendor’s defaults.
Why does RRF treat a #1 with score 0.99 the same as a #1 with score 0.51?
The formula explains everything. RRF assigns each document a fused score equal to the sum, over each retriever, of 1 / (k + rank_d) — where rank_d is the document’s rank in that retriever and k is a smoothing constant. The original SIGIR paper used k = 60, chosen from a pilot study where mean average precision stayed roughly flat for k ∈ [20, 100] (Cormack et al. 2009).
Notice what is missing. Nothing in 1 / (k + rank_d) consults the actual relevance score the retriever produced. A document at rank 1 contributes 1 / (k + 1) to the fused score whether the retriever was certain or barely confident — the magnitude information is discarded by construction.
Most of the time, this is fine. When two retrievers agree on the top of the list, the order they pick is usually right. The pathological case is the one where one retriever is highly confident in its top hit and the other is producing a near-coin-flip across the top ten. RRF treats both inputs as equally informative votes; the high-confidence signal is averaged away. The merge layer is operating on ordinal information from one retriever and ordinal information from another, with no channel to express “this side actually knows what it is talking about and that side is guessing.”
Not noise. A direct consequence of the formula.
How sensitive is RRF to the k constant?
More than the folk wisdom suggests. The “k is robust” claim traces back to Cormack’s original pilot, which observed roughly flat MAP for k ∈ [20, 100] on the TREC test sets used in 2009. Recent evaluations on different corpora and different query distributions report several-point swings in NDCG@1000 and Recall@K as k is swept across that same range (apxml RRF Algorithms). The robustness claim is overstated outside the original benchmarks.
The vendor implementations make the issue concrete. Elasticsearch defaults to k = 60, matching the original paper (Elastic RRF Reference). Qdrant defaults to k = 2 (Qdrant Docs); a parameterized k became available only in v1.16+. These two choices are not minor.
A small k weighs the very top of each list aggressively. At k = 2, the contribution from rank 1 is 1/3 and from rank 10 is 1/12 — a four-fold gap. At k = 60, those same ranks contribute 1/61 and 1/70, a barely 15% gap. The fusion curve is not the same algorithm under the two settings. Code copied from a non-Qdrant tutorial assuming k = 60 will silently produce different rankings on Qdrant unless k is passed explicitly.
RRF’s “robustness to k” is a property of the original benchmarks, not of the algorithm.
Compatibility notes:
- Qdrant RRF default: k = 2 (Qdrant Docs), diverging from Cormack’s k = 60. Pass k explicitly when porting code from non-Qdrant tutorials. Parameterized k requires Qdrant v1.16+.
- Default fusion swap: Weaviate switched its default fusion from
rankedFusiontorelativeScoreFusionin v1.24 (Weaviate Blog). The legacyrankedFusionis still supported but produces different rankings; tutorials written before 2024 that showfusionType: rankedFusionare silently outdated on current Weaviate.
When Score-Based Fusion Breaks Differently
Score-based fusion is the natural counter-move to RRF: keep the relevance information, normalize the two distributions to a common range, and combine them with weights. Weaviate calls its default relativeScoreFusion; Qdrant ships a method it calls Distribution-Based Score Fusion. The naming differs across vendors — DBSF is Qdrant-specific terminology, while other systems describe equivalent ideas as z-score or trimmed normalization. The shape of the failure mode, however, is the same. And it is not the failure mode RRF has.
Why does a single BM25 outlier ruin min-max normalization?
relativeScoreFusion and similar approaches use a min-max normalization on each per-query score list — subtract the minimum, divide by the range — and then sum the per-document normalized scores with weights. The math is clean. The corpus is not.
Consider a query with three BM25 hits scoring 15.2, 8.1, and 4.8. The first score is more than three times the second; the gap between second and third is small. Min-max normalization maps the top hit to 1.0, the bottom hit to 0.0, and crushes the middle hit to roughly 0.31 (Andrey Chauzov). The shape of the original distribution — two roughly competitive results and one clear winner — collapses into a near-binary signal. Whatever the dense retriever was contributing to the second-place document is now drowned out, because the BM25 outlier has consumed almost the entire normalized range.
Distribution-Based Score Fusion attempts to fix this by clipping the per-query score range at mean ± 3 standard deviations before normalizing, then summing per-document (Qdrant Docs). It is more robust to single-outlier compression than naive min-max. It is also stateless across queries — it uses only the current query’s results, with no memory of long-run corpus statistics. When the current query happens to be unusual (very few hits, very tight distribution, or a single dominant outlier), that limit shows up as inconsistent ranking quality across the same workload.
A weighting parameter sits on top of all of this. Weaviate’s alpha ranges from 0 (pure BM25) to 1 (pure vector) and is applied before the fusion combines the two sides (Weaviate Docs). The official documentation does not commit to a numeric default — example code uses alpha = 0.5, but treating that as a corpus-tuned value would be a mistake. Alpha is corpus- and query-class-dependent, not a universal constant.
Weaviate’s published comparison reported a recall improvement of relativeScoreFusion over rankedFusion on the FIQA dataset (Weaviate Blog). The directional finding is real — score-based fusion commonly outperforms rank-based fusion when the score distributions are not pathological. The exact percentage is dataset-specific and has not been reproduced as a portable benchmark across corpora.
Score-based fusion does not solve the score-mismatch problem; it relocates it.
What the Mechanism Predicts — and Where It Breaks
Once you hold the two failure modes — discarded magnitude on the RRF side, outlier compression on the score-based side — the catalogue of “why is hybrid search inconsistent on my corpus” stops looking mysterious and starts looking like a list of structural consequences.
If your corpus has long-tail BM25 distributions (legal documents, code, product catalogues with rare SKUs), expect score-based fusion to behave worse than RRF on outlier-heavy queries. The single high-scoring lexical hit will compress everything else into a narrow band.
If your corpus is uniform and your queries are paraphrased natural language, expect RRF to behave worse than score-based fusion on close calls. Two near-equivalent rank-1 candidates will be treated as identical, and the actual best one will be picked by tiebreaker rules that have nothing to do with relevance.
If your queries split into “keyword-heavy” and “semantic-heavy” classes, expect a single global alpha or a single global k to be dominated on both sides — the optimal weighting is per-query-class, not per-corpus (OpenSearch Blog). A learned router or a query classifier in front of the fusion layer will out-perform any global tuning that treats all queries uniformly.
If you are searching for out-of-domain tokens — internal product codes, freshly minted SKUs, proprietary names that did not exist when the embedding model was trained — expect dense retrieval to underperform on those tokens, and expect hybrid to be a partial mitigation rather than a fix (OpenSearch Blog). The lexical side carries those queries; the semantic side adds noise.
If you are layering an Agentic RAG loop on top of hybrid retrieval, expect the failure modes above to compound across agent steps. A noisy fusion at step one becomes misleading context for the planner at step two, and the agent has no signal that its retrieval was the weak link.
Rule of thumb: the right fusion method depends on the shape of your corpus and the variance of your queries — not on which vendor’s default ships first. Sample real queries, log per-method recall and rank stability, and pick the fusion method that survives your worst query class.
When it breaks: every fusion algorithm has at least one query class on which it produces strictly worse rankings than the better of its two retrievers alone. The fusion layer cannot rescue score-distribution mismatch, outlier compression, and per-query-class alpha tuning at the same time — it only chooses which one to fail on.
The Data Says
Hybrid search is not a fused score; it is a stack of decisions about how to combine two retrievers whose scores were never meant to live in the same number line. Both RRF and score-based fusion solve a real problem, and both create a different one in exchange. The real question is not which method is correct, but which failure mode is acceptable on the corpus and queries you actually have.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors