Saturation, Contamination, and Construct Validity: The Technical Limits of AI Benchmarks

Table of Contents
ELI5
A high benchmark score measures how well a model does on one frozen test — not how smart it is. Saturation, contamination, and construct validity are the three reasons that number can soar while real ability stays flat.
A model lands at the top of the leaderboard — ninety-something percent on every test that matters — and your team adopts it on Monday. By Friday it is fumbling the exact task you hired it for. The score went up; the capability did not. That gap is not bad luck, and it is not a fluke of your prompt. It is built into how benchmarks are made.
A Score Is a Proxy, Not a Verdict
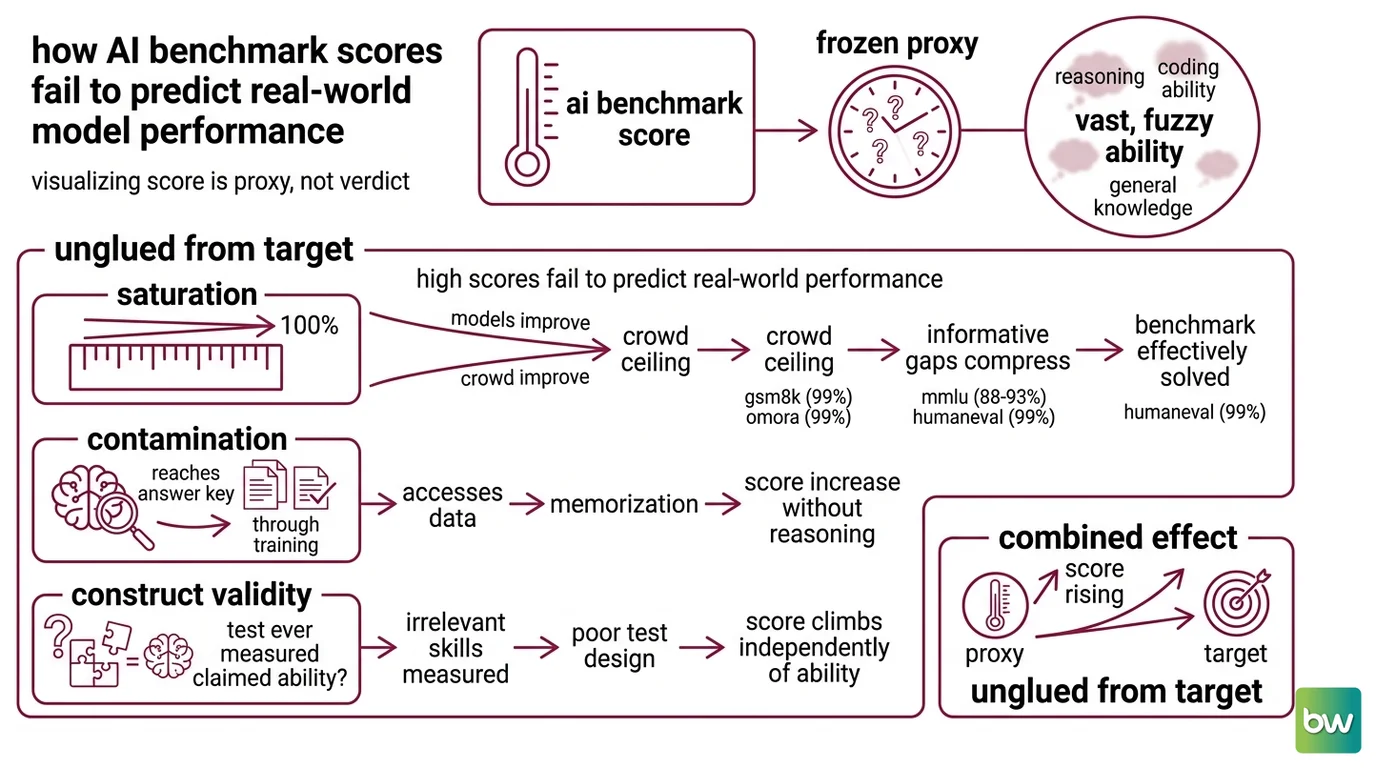
Every benchmark is a stand-in. It takes something vast and fuzzy — “reasoning,” “coding ability,” “general knowledge” — and freezes it into a fixed set of questions with a fixed answer key. The score you read is performance on that frozen set. Whether it tells you anything about the messy ability you actually care about depends on one thing: how tightly the proxy is still glued to the target.
Why do high AI benchmark scores fail to predict real-world model performance?
Because a score is a measurement of a narrow, frozen task, and three separate forces work to pull that task loose from the broad ability it is supposed to represent. Saturation erodes the benchmark’s ability to tell models apart. Contamination lets a model reach the answer key through training rather than reasoning. Construct validity asks whether the test ever measured the claimed ability in the first place. When a score climbs, you are seeing the combined effect of all three — and only one of them is the good kind of progress. The other two mean the proxy comes unglued from the target while the number keeps rising.
Not noise. Three distinct mechanisms.
Saturation: When the Ruler Runs Out of Marks
Saturation is the simplest failure to see and the easiest to ignore. A new benchmark spreads scores out: weak models score low, strong models score high, and the gaps between them carry information. As models improve, they crowd toward the ceiling, and those informative gaps compress into nothing.
Grade-school arithmetic word problems — the GSM8K Benchmark Datasets — are effectively solved; frontier models sit near 99%, up from roughly 35% when GPT-3 launched, according to LXT. MMLU Benchmark now clusters frontier models between 88% and 93%, and HumanEval pass@1 is approaching 99% for state-of-the-art systems. Once everyone scores in the low nineties, the spread between the first-ranked model and the fifth is no longer a capability difference. It is run-to-run variance with a leaderboard wrapped around it. A one-point lead is measurement noise, not a skill gap.
The test didn’t get easier. The models got better than the test.
This is why labs keep inventing harder exams. GPQA Diamond — graduate-level science questions where PhD experts score around 65% — already has frontier models in the 92–94% range as of mid-2026, per Artificial Analysis, which means it too is sliding toward the ceiling. Humanity’s Last Exam was built specifically to resist this, and leading models still sit only around 40–46% on it. A rising score, though, has an innocent explanation and a guilty one. Saturation is the innocent one.
Contamination: The Answer Key Leaked Into the Textbook
The guilty explanation is Benchmark Contamination. The Benchmark Data Contamination survey defines it plainly: exposure of a model to benchmark data during training leads to distorted evaluation results. The test questions, or text close enough to them, end up inside the training corpus. The model then “passes” by retrieval rather than reasoning — a textbook open to the exact page during the exam.
The survey sorts the damage into four levels of severity — semantic, information, data, and label — where the label level is the worst: the model has seen the questions paired with their correct answers and has simply stored them. That is no longer Data Leakage at the margins; it is Memorization of the test.
How much does this distort scores? Contamination has been detected at rates between 1% and 45% across various models and benchmarks, the survey reports. The sharpest demonstration: when researchers rebuilt HumanEval into a decontaminated variant (EvoEval), average scores fell by 39.4%. Nearly two-fifths of the apparent skill was leakage wearing the costume of competence.
Not intelligence. Recall.
Contamination is Overfitting to a test set you were never supposed to study — except the model didn’t choose to cheat; the data pipeline did it silently. And here is the cruelty of it: contamination and genuine improvement produce the exact same symptom, a higher number. You cannot tell them apart from the score alone.
Construct Validity: Measuring the Wrong Thing Precisely
Saturation and contamination are problems with the measurement. Construct validity is a problem with what you are measuring at all. A benchmark can be unsaturated and perfectly clean and still mislead you, because it never captured the ability it advertises.
Construct validity asks a single question: does the test measure the thing it claims to measure? Raji and colleagues argue that framing any benchmark as a “general” measure of ability is, in their words, ultimately dangerous and deceptive — a fixed dataset paired with a single metric cannot instantiate a general capability, only a specific, narrow instance of it. “General reasoning” measured by one question format is just performance on that format.
The fragility shows up the moment you change the test. Dehghani and colleagues call it the benchmark lottery: relative model rankings shift significantly depending on which benchmark tasks you happen to choose. Swap the test set and the rankings reshuffle — which means a model’s top spot can reflect the choice of exam rather than any real superiority over its rivals. The Ground Truth answer key encodes one definition of “correct,” and a model tuned to that definition looks brilliant until the definition changes.
Reading a Benchmark Like a Scientist
Once you see the three mechanisms, a benchmark score becomes a clue to interrogate rather than a verdict to trust. The mechanisms even make predictions you can check:
- If two models sit within a few points on a saturated benchmark, expect the ranking to be noise — re-run the evaluation and the order may flip.
- If a model’s score jumps on a static, popular benchmark but not on a freshly refreshed one, suspect contamination before you call it a breakthrough.
- If a benchmark claims to measure “general” reasoning, expect its ranking to hold only for tasks shaped like its questions, and to wobble everywhere else.
The practical move is to stop outsourcing your judgment to a public number. Build a small, private held-out evaluation on your actual task, keep its contents out of every training and fine-tuning pipeline, and treat public leaderboards as a coarse filter rather than a decision. The field is shifting the same way at the frontier: contamination-resistant and dynamic evaluations — LiveBench, which refreshes its questions; Humanity’s Last Exam, designed to resist saturation; SWE-bench Verified for real software tasks; and human-preference arenas like Chatbot Arena — exist precisely because static tests decay. Some of these lean on Synthetic Data Generation to mint fresh items faster than they can leak.
Rule of thumb: A benchmark score tells you a model can do the benchmark. Nothing beyond that comes for free.
When it breaks: The moment a benchmark becomes popular, it starts to die — it leaks into training data, models optimize directly to it, and its scores stop tracking the ability it was built to measure. Few public benchmarks survive their own success intact, which is why no single number should ever stand alone as your evidence.
The Data Says
A high benchmark score is a measurement of a narrow proxy task under leak-prone conditions, so it routinely fails to predict real-world performance. Saturation drains the signal, contamination inflates it, and construct validity questions whether there was ever signal to begin with. Read scores as evidence with error bars, not as a ranking you can act on blind.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors