Rule-Based, Statistical, GAN, and LLM-Distilled: The Four Families of Synthetic Data Techniques
ELI5
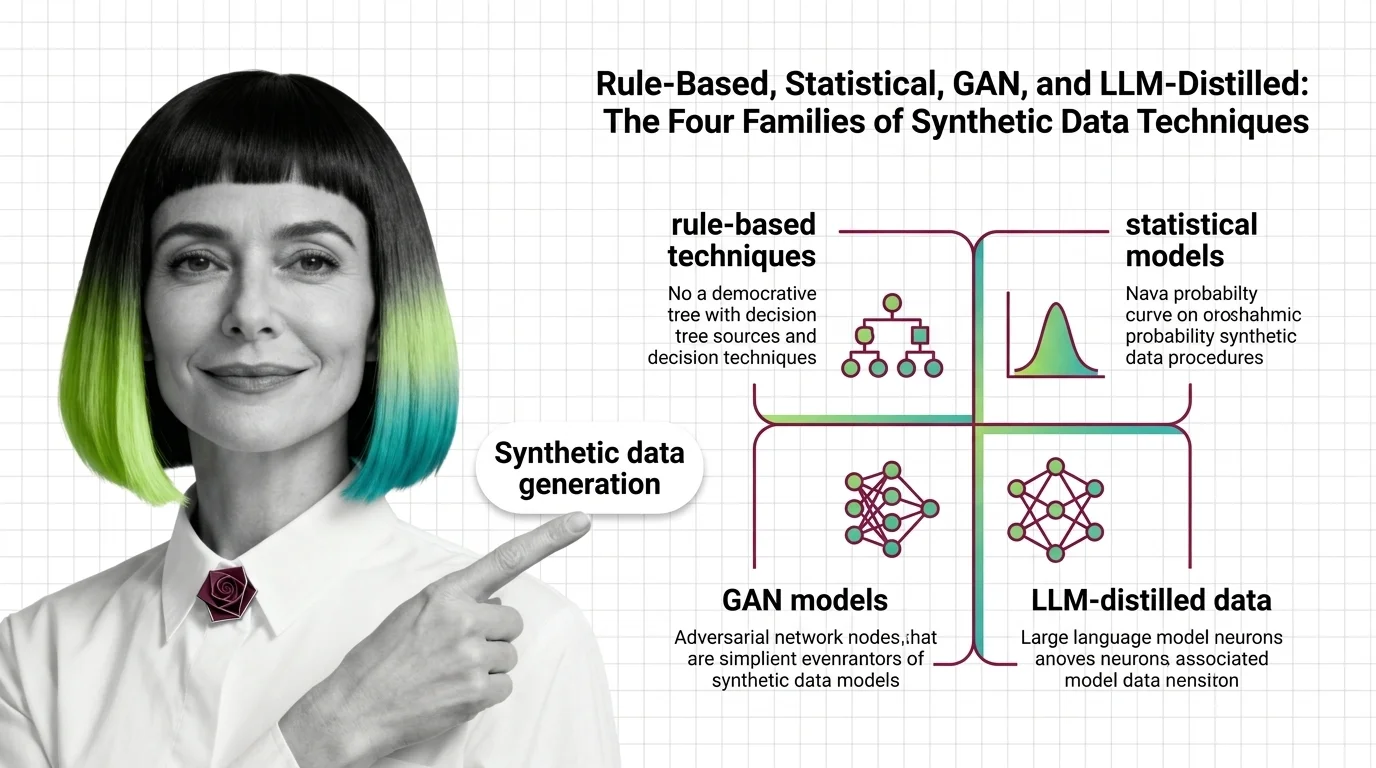
Synthetic data generation creates artificial records that mimic real data’s statistical patterns without copying real people. Four technique families exist — rule-based, statistical, GAN-based, and LLM-distilled — each learning a different depth of structure from the original.
A fraud-detection team once generated a million synthetic transactions to train their model. Every column looked impeccable: valid-shaped card numbers, plausible amounts, timestamps that landed in the right hours. The model trained on it cleanly, then collapsed the moment it met real fraud.
The data was photorealistic and statistically hollow.
The reason traces back to a single question that most teams never ask: which family of techniques produced it?
The Spectrum of Borrowed Structure
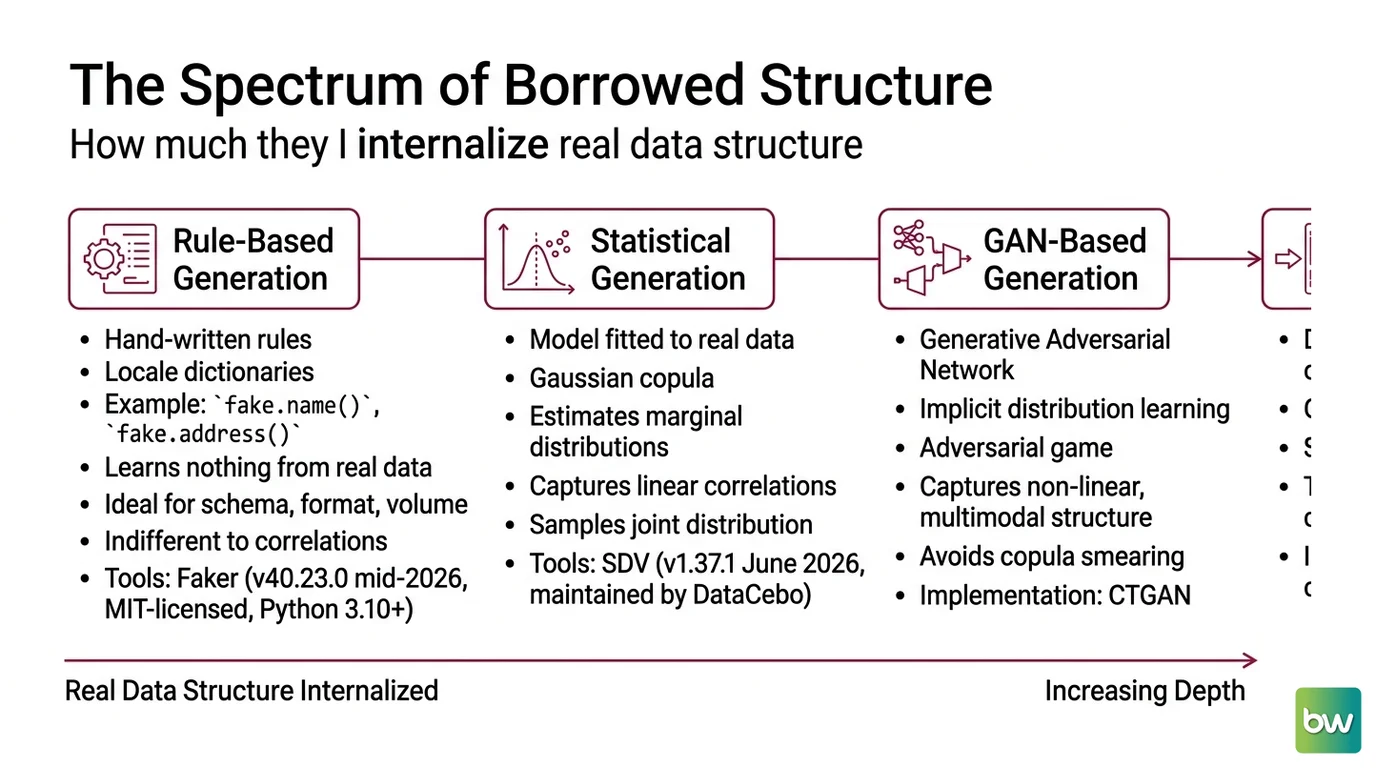
The mistake hiding inside that fraud story is a seductive one — the belief that synthetic data is good when each row looks real. Realism per row is the easy part. The hard part is whether the relationships between columns survive the trip from real to synthetic. Every Synthetic Data Generation method can be placed on a single axis: how much of the real data’s structure it actually internalizes.
Not realism. Structure.
What are the main techniques for generating synthetic data?
There are four families, and they sit at increasing depths along that axis.
The first is rule-based generation. Tools like
Faker build records from hand-written rules and locale dictionaries — call fake.name() and you get a name, call fake.address() and you get an address. It learns nothing from your real data; it never sees it. Faker reached version 40.23.0 by mid-2026, MIT-licensed and targeting Python 3.10+ (Faker’s PyPI page). This family is ideal for schema, format, and volume — and indifferent to every correlation that matters.
The second is statistical generation. Here a model is fitted to the real data and then sampled. The classic instance is a Gaussian copula, which estimates each column’s marginal distribution and the correlation structure linking them, then draws new rows from that fitted joint distribution. The Synthetic Data Vault (SDV) packages this approach; it sits at version 1.37.1 as of June 2026, maintained by DataCebo, and spans everything from copulas to deep models under one API (SDV’s PyPI page).
The third is GAN-based generation. A Generative Adversarial Network pits two networks against each other, and the standard tabular implementation is CTGAN. Instead of writing the distribution down, it learns one implicitly through an adversarial game. This lets it capture the non-linear, multimodal structure that copulas smear flat.
The fourth is LLM-distilled generation. A large pretrained model acts as a teacher, and the synthetic records inherit its compressed view of the world. The idea rests on Knowledge Distillation, where a student learns from a teacher’s soft output probabilities rather than hard labels (Hinton et al., 2015).
| Family | What it learns from real data | Example tool | Best for | Breaks on |
|---|---|---|---|---|
| Rule-based | Nothing (hand-written rules) | Faker | Schema, format, volume | Any real correlation |
| Statistical | Marginals + correlation matrix | SDV (Gaussian copula) | Linear, well-behaved tables | Multimodal, non-linear columns |
| GAN-based | An implicit joint distribution | CTGAN | Complex, imbalanced, multimodal data | Small data, training instability |
| LLM-distilled | A foundation model’s compressed priors | LLM teacher → dataset | Text, rare scenarios, reasoning traces | Factual drift, hallucinated records |
Treat these four families as a teaching lens, not a single industry-standard taxonomy. Surveys agree the categories exist; they draw the boundaries differently.
Where Copulas and GANs Part Ways
The two learned families — statistical and GAN-based — both claim to reproduce the joint distribution of your data. They reach it from opposite directions, and the difference is explicit versus implicit density modeling.
What is the difference between GAN-based and statistical synthetic data generation?
A statistical synthesizer writes the distribution down. A Gaussian copula fits each column’s shape, estimates a correlation matrix, and samples from that explicit object. The result is fast, transparent, and auditable — you can inspect exactly what dependency the model assumed. The cost is that it did assume one. When real columns are sharply multimodal, heavily imbalanced, or bound by conditional rules (“this category only co-occurs with that range”), the copula’s smooth Gaussian backbone flattens the very texture your downstream model relied on.
A GAN never writes the distribution down. The generator proposes fake rows; a discriminator tries to separate them from real ones; both improve until the discriminator can no longer tell the difference. What remains is an implicit distribution encoded in the generator’s weights — one that can bend around non-linear, conditional, multimodal structure no copula would express. In the original study, CTGAN surpassed classical Bayesian-network synthesizers on at least 87% of the benchmark datasets (Xu et al., NeurIPS 2019).
That expressive power is not free. GAN training is unstable, hungrier for data and compute, and prone to Mode Collapse — the generator quietly abandoning rare categories because faking the common ones fools the discriminator just as well. And because the density is implicit, you cannot read off what the model believes; you can only sample and measure.
So the choice is less “which is better” and more “which structure do you need to keep, and can you afford to assume it?”
Before You Generate Your First Row
The families are easy to list and easy to misuse. A few foundations separate a useful synthetic dataset from a convincing-looking trap.
What do you need to know before learning synthetic data generation?
Start with distributions and correlations, because they are the thing you are trying to preserve. If you cannot describe which relationships your downstream model consumes, you cannot tell whether a generator kept them.
Understand the privacy dimension as separate from generation. Differential Privacy is a formal mathematical guarantee — a bound on how much any single real record can influence the output (Dwork et al., 2006). It is bolted onto a generator; it is not itself a way to generate. Synthetic does not automatically mean private.
Know the tooling map. Faker covers the rule-based family. SDV unifies statistical and GAN approaches under one interface, and it is the recommended way to run CTGAN — prefer it to the standalone package, which still carries a legacy “pre-alpha” label despite being widely used in production. MOSTLY AI offers an open-source Synthetic Data SDK under Apache 2.0, with a LOCAL mode that runs on your own compute and a CLIENT mode that calls its platform (MOSTLY AI Blog). Gretel, reportedly acquired by NVIDIA in 2025, has since been folded into NVIDIA’s AI developer services rather than offered as an independent platform (SiliconANGLE).
Finally, adopt the right yardstick. Synthetic data is judged by downstream model performance, not by eye: train on the synthetic set, evaluate on held-out real data, and measure fidelity against the original’s statistics. The fraud team’s data passed the eye test and failed the only test that counted.
Reading the Failure Modes
Once you see the families as a depth axis, their failure modes become predictable. The mechanism turns into a set of if/then forecasts you can use before you waste a single GPU-hour.
- If you need volume and schema realism but no real correlations — load testing, demos, seeding a dev database — rule-based generation is sufficient, and anything fancier just burns compute.
- If your real data is roughly linear with clean dependencies, a copula will be faster, transparent, and good enough; reaching for a GAN buys instability you don’t need.
- If your columns are multimodal, conditional, or severely imbalanced — fraud, clinical records, financial events — expect a copula to blur them and a GAN to hold their shape.
- If you train on synthetic data and test accuracy holds while production accuracy drops, suspect a family mismatch: the generator preserved the marginals your eye checks and lost the joint structure your model depends on.
Rule of thumb: Match the family to the deepest correlation your downstream model actually consumes — not to how real the individual rows look.
When it breaks: Every learned generator can memorize and reproduce the rarest real records, so a synthetic dataset is not private by default; without a differential privacy budget, outliers can be reconstructed from the output, and outliers are exactly the people a dataset already exposes most.
The Data Says
Synthetic data quality is not a property of individual rows; it is a property of the structure a technique carries across from the original. Rule-based methods carry none of it, statistical methods carry the linear backbone, GANs carry the messy non-linear shape, and LLM distillation borrows a foundation model’s compressed priors. Choose by the deepest correlation your model consumes, then verify against real data — because a generator that looks convincing tells you nothing about whether it learned the structure that matters.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors