Routing Collapse, Load Balancing Failures, and the Hard Engineering Limits of Mixture of Experts

ELI5
Mixture of experts models activate only a few specialist networks per input, but routers tend to funnel most tokens to the same few experts — a failure called routing collapse that wastes capacity and degrades output quality.
You build a model with 671 billion parameters. On any given token, 37 billion of them fire. The rest sit in memory, waiting for their turn — which, in many cases, never arrives. That is the promise of Mixture Of Experts: enormous capacity at a fraction of the compute. The engineering failure mode is almost comically mundane. The tiny network responsible for routing tokens to the right expert develops a preference, and once it starts picking favorites, the preference compounds.
When a Router Learns to Be Lazy
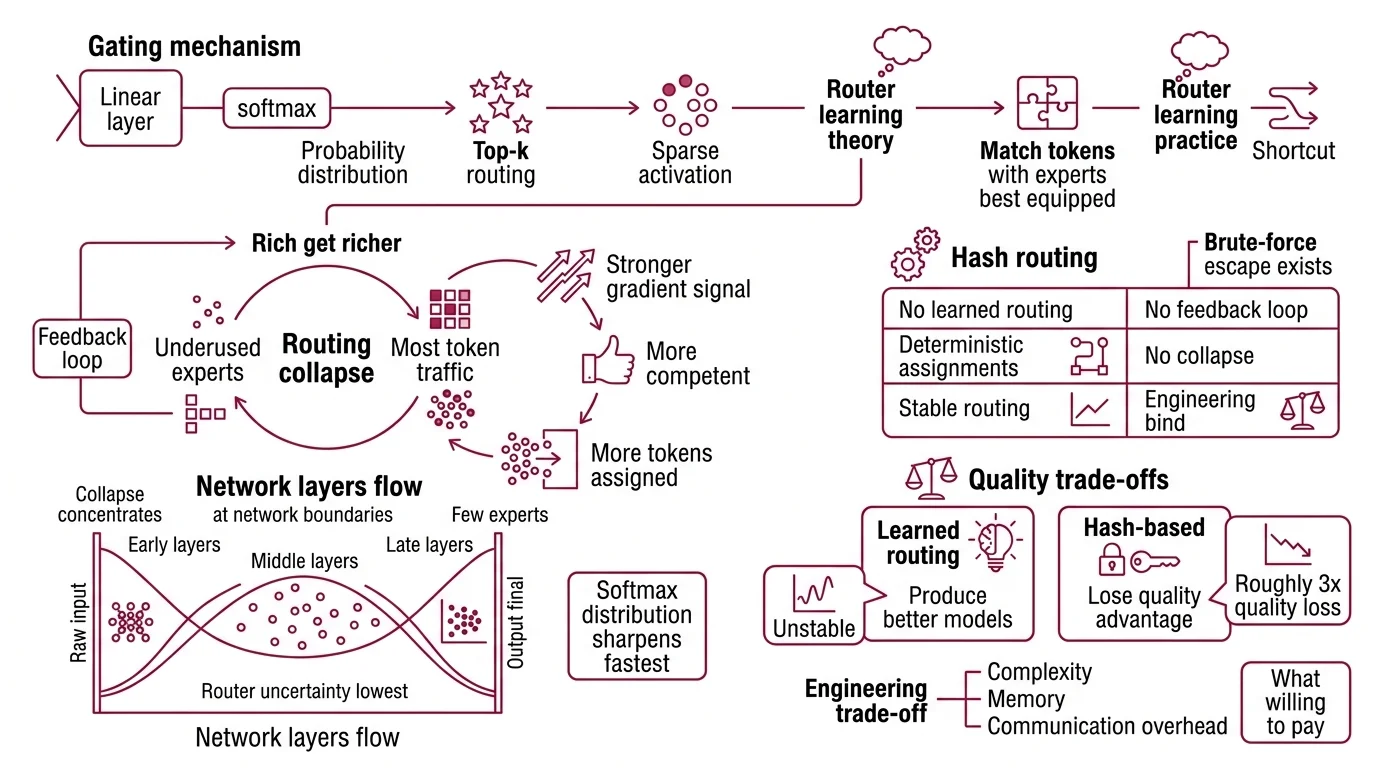
The Gating Mechanism inside an MoE model is typically a single linear layer followed by softmax. It maps each input token to a probability distribution over available experts, and the Top K Routing rule selects the highest-scoring subset for Sparse Activation — the principle that only a fraction of the network computes on any given input. In theory, the router should learn to match tokens with the experts best equipped to handle them. In practice, gradient descent finds a shortcut.
What is routing collapse in mixture of experts models?
Routing collapse occurs when a small number of experts capture the majority of token traffic while the rest go underused. The mechanism is a feedback loop: an expert that processes more tokens accumulates stronger gradient signal, which makes it marginally more competent at the tasks routed to it, which causes the router to assign even more tokens its way. The rich get richer — not by design, but by the geometry of the loss surface.
The pattern is not random. Early and late transformer layers funnel most tokens to one or two experts, while middle layers distribute more evenly (Cerebras Blog). Collapse concentrates at the network’s boundaries — where the input is still raw and the output nearly final, router uncertainty is lowest, and the softmax distribution sharpens fastest.
One brute-force escape exists. Hash routing assigns tokens to experts deterministically — no learned preferences, no feedback loop, no collapse. But deterministic routing discards the quality gains that learned routing provides; hash-based approaches lose roughly a 3x quality advantage compared to learned alternatives (Cerebras Blog). The engineering bind: learned routing produces better models but is unstable; deterministic routing is stable but mediocre.
The question becomes what you are willing to pay — in complexity, memory, and communication overhead — to keep learned routing from devouring itself.
The Three Taxes on Sparsity
Sparse activation is the defining trick of MoE architecture: activate a fraction of parameters per token, save compute, keep capacity high. The trick is not free. It comes with three distinct engineering costs that dense transformers never pay, and each constrains the architecture in ways that are easy to underestimate.
Why are mixture of experts models harder to train than dense transformers?
The first tax is the Load Balancing Loss. To prevent routing collapse, MoE training adds an auxiliary loss term that penalizes uneven expert utilization. In the Switch Transformer, the recommended coefficient was α = 0.01 — swept across five orders of magnitude from 10⁻¹ to 10⁻⁵ in that specific experimental setup (Fedus et al. 2022). Too small, and the router collapses. Too large, and the auxiliary loss interferes with the primary language modeling objective. The optimal value is not portable; it shifts with model scale, expert count, and batch size.
The second tax is communication. In distributed training, expert parallelism splits experts across devices, and every forward pass requires all-to-all communication — each device sends tokens to the device hosting the selected expert and receives the processed results. Depending on hardware topology and interconnect bandwidth, this overhead can consume more than 40% of total training time at large scale; at DeepSeek-V3 scale, NVIDIA measured figures exceeding 50% before targeted optimization (NVIDIA Hybrid-EP Blog). Their Hybrid Expert Parallel approach recovers a meaningful share — 14% throughput improvement on Grace Blackwell hardware — but communication remains the dominant bottleneck.
The third tax is instability. MoE models are more sensitive to learning rate, batch size, and initialization than their dense counterparts. The router introduces a discrete decision into an otherwise continuous optimization problem, and small perturbations in gating weights can trigger large shifts in expert assignment. Training runs that would converge smoothly with a dense model sometimes oscillate or diverge when experts are involved.
How much GPU memory do mixture of experts models need compared to dense models?
Here is the part that surprises people: MoE saves compute, not memory. Every expert must reside in GPU memory even though only a fraction activate per token. Mixtral 8x7B, which activates roughly 13 billion parameters per forward pass, requires approximately 90 GB in bfloat16 — memory comparable to a dense 45-billion-parameter model (Friendli AI). The gap between “active parameters” and “total parameters” is a compute discount.
Not a memory discount.
The current generation confirms the pattern at larger scale. DeepSeek-R1-0528 carries 671 billion total parameters with 37 billion active across 256 experts. Llama 4 Maverick: 400 billion total, 17 billion active, 128 experts. The gap between total and active parameters varies by architecture, but the rule holds — every idle parameter still occupies VRAM. The question is whether any of these taxes can be reduced without the bill arriving somewhere else.
The Arms Race Against Collapse
The field has not accepted routing collapse as inevitable. Two recent approaches attack the problem from opposite ends of the constraint space.
DeepSeek-V3 eliminates the auxiliary loss entirely. Instead of penalizing uneven utilization through a second loss term, it adjusts dynamic bias terms per expert during training — incrementing the gating score of underused experts, decrementing overused ones (HuggingFace MoE Balance Blog). Because the adjustment lives outside the loss function, it cannot interfere with the language modeling objective. The approach sidesteps the α-tuning problem by removing α altogether.
ScMoE, published at ICML 2025, attacks the communication tax instead. It decouples all-to-all communication from the sequential ordering of expert computation, achieving a 1.49x training speedup and 1.82x inference speedup over a top-2 baseline (Cai et al. 2025). The technique does not solve routing collapse directly, but by reducing the cost of expert parallelism, it makes larger expert counts — which naturally dilute collapse effects — more practical.
MoE is backbone-agnostic; the expert-routing pattern applies to transformer layers and increasingly to State Space Model architectures, so these engineering constraints follow wherever sparsity goes. Neither fix closes the loop entirely. DeepSeek’s bias approach requires careful γ tuning per architecture, and ScMoE’s gains depend on communication topology. What these constraints add up to, in practice, is a set of predictable decision boundaries.
What the Failure Modes Predict
The engineering limits create clear if/then rules for architecture decisions:
- If you are selecting an MoE model for inference, plan memory for total parameters, not active parameters. A model advertising “17B active” may demand the VRAM footprint of a model several times that size.
- If you are training with expert parallelism, assume communication overhead will dominate until you specifically optimize for it. Budget accordingly.
- If your training runs show sudden quality drops or oscillation, check expert utilization before adjusting the learning rate. Routing collapse mimics a convergence problem but responds to balancing interventions, not optimizer tuning.
Rule of thumb: Multiply active parameters by the total-to-active ratio to estimate true memory cost. If the result exceeds your GPU budget, quantization or offloading enters the equation — and both introduce their own quality tradeoffs.
When it breaks: MoE degrades most when expert counts are high but per-expert capacity is low. The router lacks enough signal to differentiate specialists, collapse accelerates, and the model produces output at a quality ceiling well below its theoretical capacity — silently, with no error to flag the waste.
The Data Says
Mixture of experts is the architecture behind the most prominent open-weight frontier models of 2026 — DeepSeek, Llama 4, Qwen3, Gemma 4. The engineering taxes are real: routing collapse wastes capacity, all-to-all communication dominates training time, and memory scales with total parameters regardless of sparsity. The field is converging on targeted solutions, but each introduces its own constraints. MoE is not a free lunch. It is a carefully negotiated trade.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors