Repetition Loops, Hallucination Spikes, and the Hard Limits of Sampling Parameter Tuning
Table of Contents
ELI5
Sampling parameters control which words an LLM picks from its probability distribution. Set them wrong, and the model either repeats itself in loops or drifts into incoherent hallucination.
Here is a behavior that should bother you: a model generates three clean paragraphs, then starts repeating the same clause — verbatim — until you stop it. The prompt did not change. The weights did not change. Something in the sampling configuration created a gravitational well that the model could not escape.
That pattern is not a software bug. It is a mathematical inevitability hiding inside the probability distribution, activated by specific parameter combinations that most engineers set once and never revisit.
The Thermometer Inside Every Token Prediction
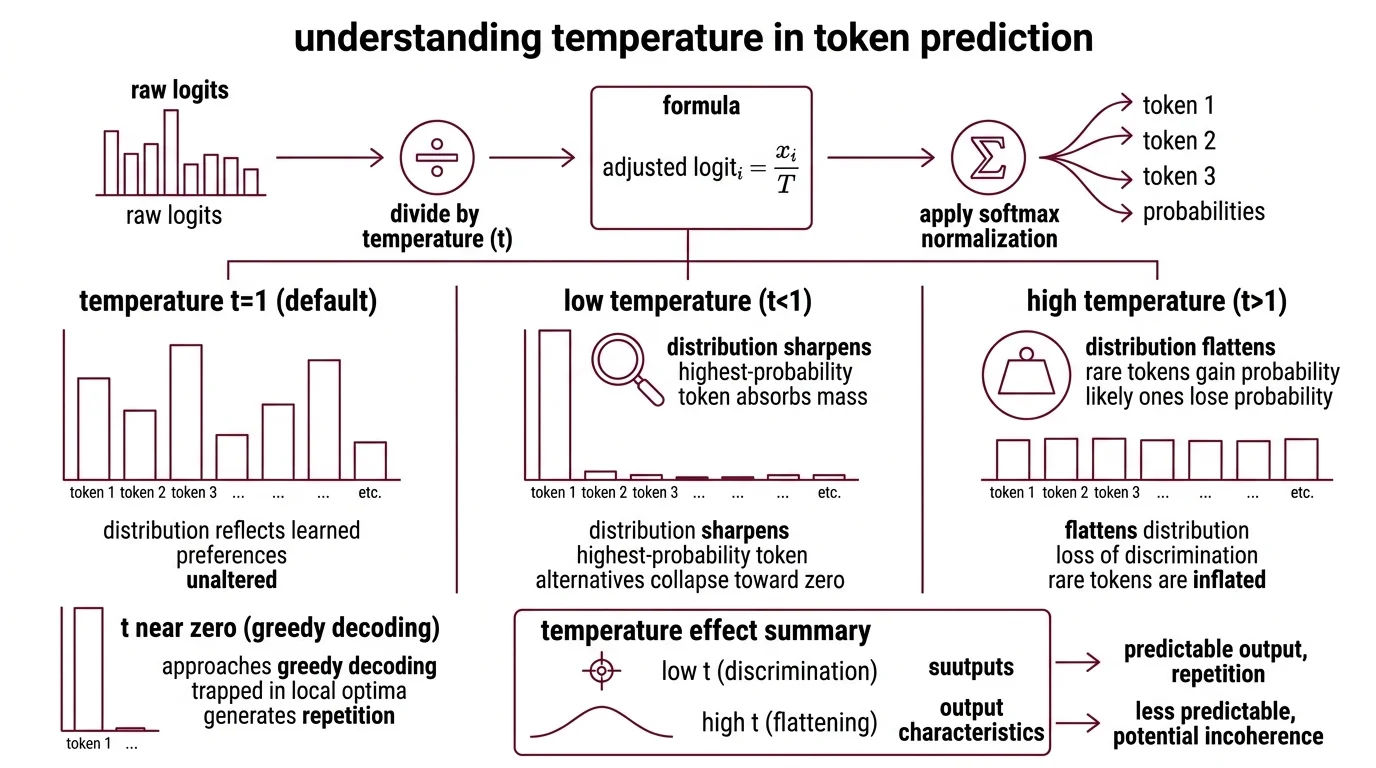
Temperature And Sampling governs the shape of the probability distribution a model samples from — and “shape” is doing serious work in that sentence. Temperature is not a creativity dial you turn up for brainstorming and down for factual tasks. It is a divisor applied to raw Logits before the softmax function converts them into probabilities.
The formula is clean: the adjusted logit for token i equals x_i / T, followed by softmax normalization to produce the final sampling probability. When T equals 1, the distribution reflects the model’s learned preferences unaltered. Drop T below 1 and the distribution sharpens — the highest-probability token absorbs more mass while alternatives collapse toward zero. Raise T above 1 and the distribution flattens — rare tokens gain probability at the expense of likely ones.
Think of it as a lens over a topographic map. Temperature 1 is the terrain as surveyed. Temperature below 1 is zooming in on the tallest peak until you can see nothing else. Temperature above 1 is pulling back until every hill looks the same height — and you can no longer tell which one is Everest. The analogy has limits; temperature also changes the entropy of the distribution, affecting not just which token wins but how decisively the model places its bet. But the core intuition holds: temperature controls how much the model discriminates between options.
What happens when LLM temperature is set too high or too low?
At the extremes, temperature does not produce “more creative” or “more precise” output. It produces pathology.
Near zero, the model approaches Greedy Decoding — selecting the single most probable token at every step. The immediate output looks crisp, confident, decisive. But confidence and variety are different properties; the model becomes trapped in locally optimal sequences, generating repetition because the same token remains most probable given identical preceding context. The failure is collapsed diversity, not removed randomness.
Well above the default on most providers (OpenAI permits values up to 2; Anthropic caps at 1.0), the distribution flattens enough that low-probability tokens — including semantically incoherent ones — begin winning the sampling lottery with uncomfortable regularity. Text may begin coherently, then drift into sequences resembling free association without semantic constraint.
A detail worth knowing: setting temperature to 0 does not guarantee fully deterministic output. Floating-point arithmetic on parallel hardware introduces non-determinism at the bit level; two identical API calls at temperature 0 can return different results (Anthropic Docs). The mathematical ideal of a perfectly greedy decode is approximated, never achieved.
One finding challenges the intuition that temperature is a meaningful tuning lever for reasoning tasks. Across nine LLMs tested with multiple prompt strategies, temperature values between 0 and 1 showed no statistically significant effect on problem-solving accuracy (Renze & Guven). That result applies specifically to structured, multiple-choice benchmarks — open-ended generation likely behaves differently — but it should make anyone treating temperature as a precision instrument for analytical work reconsider what exactly they are tuning.
Two Traps and a Fixed Point
The probability distribution an LLM samples from is not the distribution it learned during training. It is a filtered, truncated, temperature-adjusted approximation — and the filtering strategy determines which failure mode you encounter. Imagine a river: temperature sets the current’s speed, but the truncation threshold decides how wide the channel is. Too narrow and the water stalls in place. Too wide and it dissipates into mud.
Basu et al. formalized the failure modes as two regimes. In the “boredom trap,” restrictive truncation — low Top P Sampling or top-k values — causes perplexity to decrease as generated text grows longer. The model converges on a narrow, repetitive pattern, circling the same phrases with increasing certainty. In the “confusion trap,” permissive truncation causes perplexity to increase with length — coherence degrades as the model wanders through progressively unlikely regions of probability space (Basu et al.).
The relationship between cross-entropy and repetition in generated text follows a near-linear correlation (Basu et al.). That is not a loose tendency. It is a measurable, reproducible link between the mathematics of the distribution and the observable quality of the output.
Why do some LLM sampling configurations produce repetitive or degenerate text output?
The mechanism beneath repetition loops has a specific geometry. Once a phrase appears three to four times in a generated sequence, the conditional probability of that phrase — given its own recent context — becomes so high that the model cannot escape the fixed point. Each repetition reinforces the next. The loop is self-stabilizing.
Not a tendency. A mathematical attractor.
The model’s Inference process at each step reads the context window, finds the repeated phrase dominating recent tokens, and assigns it overwhelming probability mass. Escaping requires either external intervention — the user stopping generation — or a sampling mechanism that explicitly penalizes repetition.
The root cause runs deeper than parameter misconfiguration. Finlayson et al. demonstrated that the softmax bottleneck — the fundamental inability of the softmax function to perfectly represent all target distributions — is the structural reason truncation sampling works at all (Finlayson et al.). Top-p and top-k do not refine the model’s distribution; they coarsely eliminate errors that the softmax bottleneck introduces. The fix is accidental. The benefit is real, but built on a workaround for a limitation nobody chose.
Patching a Distribution You Cannot See
The standard industry tools for combating repetition — frequency penalties and repetition penalties — are blunt instruments. Even with these penalties active, degenerate repetition rates reach up to four percent (Ginart et al.). That percentage sounds manageable in a research paper. In a user-facing application, a single visible loop destroys trust in the entire output.
Three alternative approaches try to solve this at a deeper level, each with a distinct philosophy.
Min P Sampling uses the top token’s probability as a dynamic scaling factor for truncation. Instead of a fixed nucleus size, the threshold adapts to the model’s confidence at each step. The method was accepted at ICLR 2025, but a critical reanalysis presented as an ICLR 2025 oral found that min-p did not outperform baselines in either quality or diversity metrics (Schaeffer et al.). The original claims appear overstated; the scientific debate is unresolved.
Mirostat takes a fundamentally different approach. Rather than setting static thresholds, it uses a feedback loop targeting a specific perplexity level — adjusting truncation dynamically to avoid both the boredom and confusion traps (Basu et al.). The algorithm treats quality as a control problem. Where temperature and top-p are open-loop configurations — you set them and hope — Mirostat closes the loop, measuring the output’s statistical properties and correcting in real time. The difference is the difference between a thermostat and an open window.
The LZ penalty, proposed in 2025 by Ginart et al., applies an information-theoretic penalty derived from LZ77 compression. Sequences that compress well — containing repetitive patterns — receive a probability penalty proportional to their informational redundancy. The result: near-zero degenerate repetitions with no measurable loss on standard benchmarks (Ginart et al.). Where frequency penalties count surface-level token occurrences, the LZ penalty operates on the compressibility of the generated sequence — a distinction that matters because repetition manifests in structural forms that simple counting misses.
The three approaches represent three different questions about distribution management. Min-p asks: which tokens deserve to be in the running? Mirostat asks: is the output staying at the right statistical difficulty? The LZ penalty asks: is the output saying something new? The questions are orthogonal, which suggests that future sampling stacks may combine them — though no widely documented system combines all three as of early 2026.
What the Failure Modes Predict
The practical consequences follow directly from the mechanics above, and they take the form of testable predictions.
If you lower temperature aggressively for “consistency,” expect repetition to increase — not as an occasional artifact, but as a near-certain outcome once generation exceeds several hundred tokens. The model is not being consistent. It is being trapped.
If you push top-p near its maximum seeking variety, expect coherence to degrade after the first few sentences. The confusion trap does not announce itself immediately. It accumulates, sentence by sentence, until the output reads like plausible syntax with no semantic thread.
If you combine low temperature with tight top-p, the effects compound — both mechanisms independently narrow the distribution, and the boredom trap activates faster. Conversely, high temperature with wide top-p compounds the confusion trap. The interaction between parameters is multiplicative, not additive, and most debugging treats them as if they were independent.
If you rely on provider-default repetition penalties, expect failure rates in the low single digits — acceptable for batch processing where outputs get reviewed, unacceptable for real-time generation where a single visible loop undermines trust.
API parameter ranges are not universal. OpenAI permits temperature from 0 to 2 with a default of 1; Anthropic restricts the range to 0.0-1.0 with a default of 1.0. A configuration producing acceptable output on one provider may behave differently on another, not only because the underlying models differ but because the parameter spaces themselves are scaled differently.
Rule of thumb: Start with provider defaults, adjust temperature in small increments, and treat each change as a hypothesis — test across diverse prompts, not just the one that motivated the adjustment.
When it breaks: Sampling parameter tuning reaches its limit when the underlying model has restricted distributional diversity — Quantization can narrow effective vocabulary width, and domain-specific fine-tuning can shrink the learned distribution to the point where no sampling configuration avoids repetition. The sampling layer cannot fix what the model’s probability mass does not cover.
Compatibility note:
- vLLM
best_ofparameter: Deprecated in vLLM V1. If your Continuous Batching pipeline usesbest_offor sampling selection, migrate to alternative strategies.
The Data Says
Sampling parameters are not creative controls. They are geometry controls operating on a probability distribution with hard boundaries. The boredom trap and confusion trap are measurable regimes with predictable onset conditions and a near-linear relationship to cross-entropy — not metaphors for bad output. The most effective mitigations — Mirostat’s feedback loop, the LZ penalty’s compression-aware design — succeed precisely because they treat text generation as a control problem rather than a configuration problem.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors