Prerequisites for Vibe Coding and the Technical Limits That Break the Illusion

Table of Contents
ELI5
Vibe coding means accepting AI-generated code without reading it. The prerequisites are not vibes — they are connected tools, disciplined context, and security gates that catch what the model gets statistically wrong.
When Andrej Karpathy coined the phrase on February 2, 2025, he framed it as a posture for throwaway weekend projects — “fully give in to the vibes, embrace exponentials, and forget that the code even exists” (Wikipedia). Simon Willison sharpened the definition shortly after: vibe coding, strictly speaking, means accepting the generated code without reading it (Simon Willison’s blog). Within a year, that posture had migrated from hobby repos into production stacks.
The failure modes followed.
What the Tools Need to See Before You Press Enter
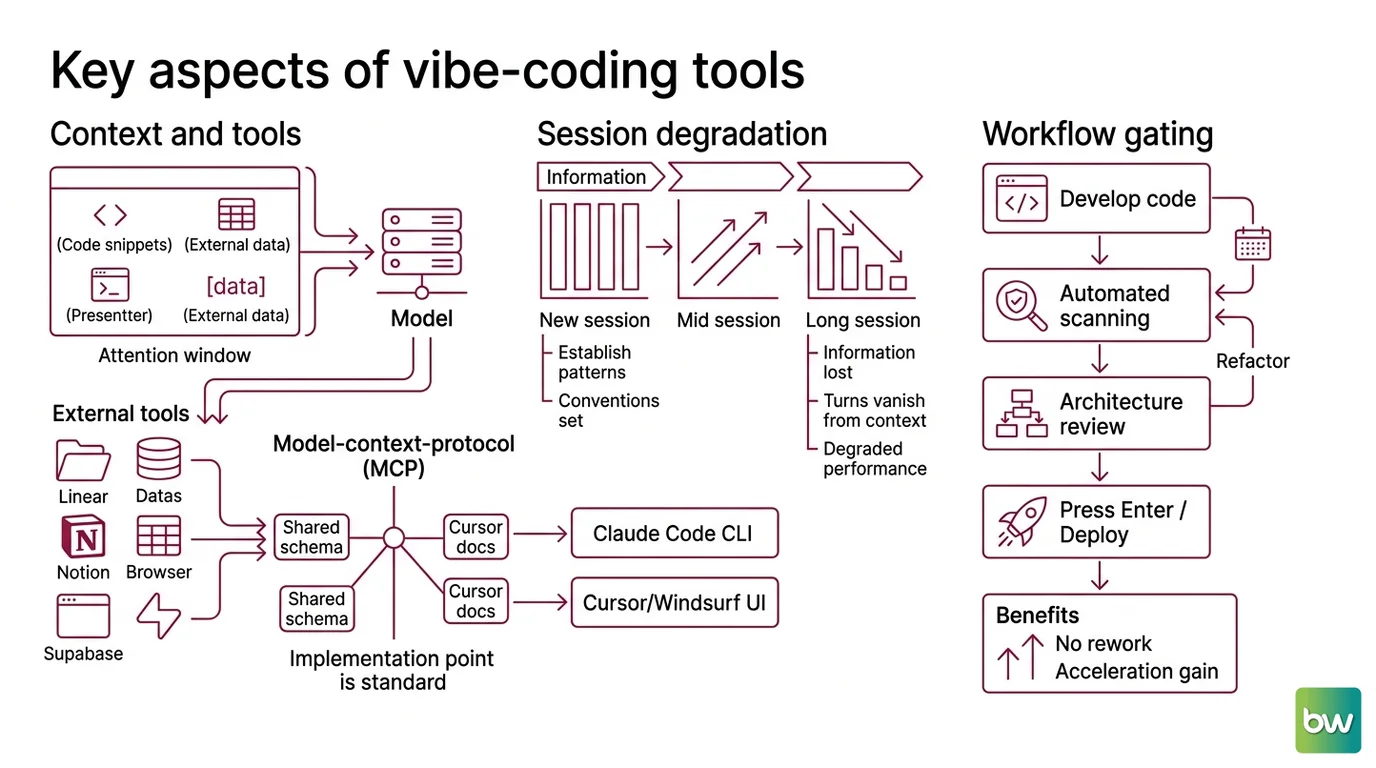
The prerequisite that matters most is also the least vibe-shaped: context. The model is not reading your codebase; it is sampling tokens conditional on what fits inside its attention window. Everything that does not fit is invisible. The art of Vibe Coding is deciding what gets in — and what gets verified afterward.
What do you need to know before starting with vibe coding in 2026?
You need to know three things, and none of them is “how to ask nicely.”
The first is the Model Context Protocol layer. MCP is an open client/server protocol that lets LLM-driven editors reach external tools — Notion, Linear, Supabase, your own internal services — through a shared schema (Cursor Docs). Cursor 0.45 and later expose it through a settings UI; Claude Code exposes it through the CLI. The same MCP server works across Cursor, Claude Code, and Windsurf, so you configure once and reuse everywhere.
The second is the failure mode of long sessions. Vibe-coding tools degrade as the conversation grows. Builder.io’s analysis of long-running sessions describes the pattern plainly: established patterns are not reapplied next session, because the relevant turns no longer fit the context window (Builder.io). The model is not forgetting; it is being shown a different set of tokens than the ones that taught it your conventions.
The third is the gate stack. Industry analyses report that vibe-coding teams who layer automated security scanning and a senior-engineer architecture review onto the AI workflow see acceleration in the range of thirty to fifty percent with no measurable rise in incident rate (Clarista). Skip the gates and the acceleration disappears into rework.
The vibe was never the productivity gain.
The gates are.
Cursor and Claude Code — version notes:
- Cursor pre-0.45: Older builds use a different settings UI and do not support MCP via the modern flow. Update before configuring servers (Cursor Docs).
- Claude Code (May 2026): Tool Search now defers schema loading, so adding MCP servers no longer inflates session-start context. Older guides warning about “context bloat from many MCP servers” are outdated (Claude Code MCP guide).
How the prerequisite stack actually composes
A useful way to picture the prerequisites is as a three-layer constraint on the probability distribution the model samples from.
Layer one — MCP servers — extends the model’s reachable world. Without it, the model can suggest a migration; with it, the model can run the migration and read back the result. The constraint becomes empirical instead of imagined.
Layer two — context discipline — shapes which prior tokens influence the next prediction. Keeping the right files, the right snippets, and the right error logs inside the window is what determines whether the model writes against your conventions or against the median of its training data.
Layer three — verification — is the only layer the model cannot perform on itself. Every other layer is upstream of the sampling pass. Verification happens downstream, after the tokens are written. Skip it and you are asking the probability distribution to also be the judge.
Where the Illusion Collapses
The vibe is comfortable until you look at what the model is doing under the hood. Vibe coding is not a single mechanism; it is a chain of sampling decisions, each one statistical, each one happening faster than any human reader can audit. The failures cluster around the points where the chain meets reality.
What are the technical limitations of vibe coding for production software?
The limits are not philosophical. They are mechanical. Three of them dominate.
Hallucinated dependencies. Industry analyses report a sharp pattern in Q1 2026: a strong majority of vibe-coded applications surveyed shipped with at least one hallucination-related vulnerability, and the rate of flaws in AI-written code ran several times higher than the rate in human-written equivalents (Clarista). Attackers noticed. The “slopsquatting” pattern — pre-registering fake package names that LLMs are statistically likely to invent — turns a hallucinated import into a supply-chain breach (State of Surveillance).
Security alert (BREAKING — 2026): AI package hallucination is an active attack surface. Attackers pre-register the fake package names LLMs invent. Treat any unfamiliar package name in generated code as untrusted until you verify it on the registry (State of Surveillance).
Cross-site scripting and input-handling defects. The same analyses report that the strong majority of vibe-coded web applications surveyed fail basic XSS checks (State of Surveillance). The mechanism is not malice; it is statistical. The model is sampling from a training distribution that includes a lot of vulnerable example code. Without a gate, that distribution becomes your codebase.
Context loss across sessions. The third limitation is the one developers feel before they read about it: the model that knew your conventions yesterday does not know them today. AI Code Migration workflows that depend on stable conventions — refactors, framework upgrades, style rewrites — degrade fastest, because the convention is the constraint and the constraint lives in the context window.
Not a glitch. An emergent property of probabilistic generation at scale.
What the Mechanism Predicts About Your Next Production Bug
Once you see the prerequisites as constraints on a probability distribution, the failures stop looking random. They become predictable — which is the first prerequisite for engineering them out.
- If the relevant code is outside the context window, expect the model to invent a plausible substitute. The substitute will compile.
- If you accept a package suggestion without verifying it on the registry, expect a supply-chain risk proportional to the model’s statistical confidence in the hallucination, not its actual correctness.
- If you skip the post-generation review gate, expect the security-defect distribution of your shipped code to converge toward the training data, not toward your team’s standards.
The first prediction explains why “the AI forgot my conventions” is a category of bug, not an anecdote. The second explains why slopsquatting works at all. The third explains the gap between teams that report acceleration from vibe coding and teams that report incidents — they are running the same model, but only one of them is filtering its output.
Rule of thumb: every line the model writes is a sample from a distribution. The prerequisites shape the distribution before sampling; the verification gates filter it afterward. Treat them as one system.
When it breaks: Vibe coding fails hardest at the boundary between fast generation and slow verification. The model generates faster than any human reviewer can read, which means without automated security scanning and a senior-engineer architecture pass, the failure rate scales with the line count — not with the difficulty of the task.
The Hidden Asymmetry in the Stack
There is a subtler consequence worth naming. The prerequisites and the gates are not symmetric in cost. Adding an MCP server takes a few minutes. Writing a context document takes an afternoon. Running automated security scans takes seconds per commit. A senior-engineer architecture review takes hours — and it is the layer most often dropped under deadline pressure.
The asymmetry is the trap. The cheap prerequisites give the team enough acceleration to feel productive; the expensive verification gate is the one that catches what the cheap layers cannot. When the gate is skipped, the productivity gain looks intact in the moment and only appears as cost in the incident postmortem weeks later. The mechanism does not care about deadlines. The distribution it samples from is the same distribution at 5pm Friday as at 9am Monday.
The Data Says
Vibe coding is not a productivity gain in isolation. It is a probabilistic generation system whose output quality is governed by what you feed in and what you check downstream. The prerequisites — MCP-connected tools, disciplined context, and a verification stack — are not optional polish. They are the mechanism that turns a sample from a noisy distribution into shippable software.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors