Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
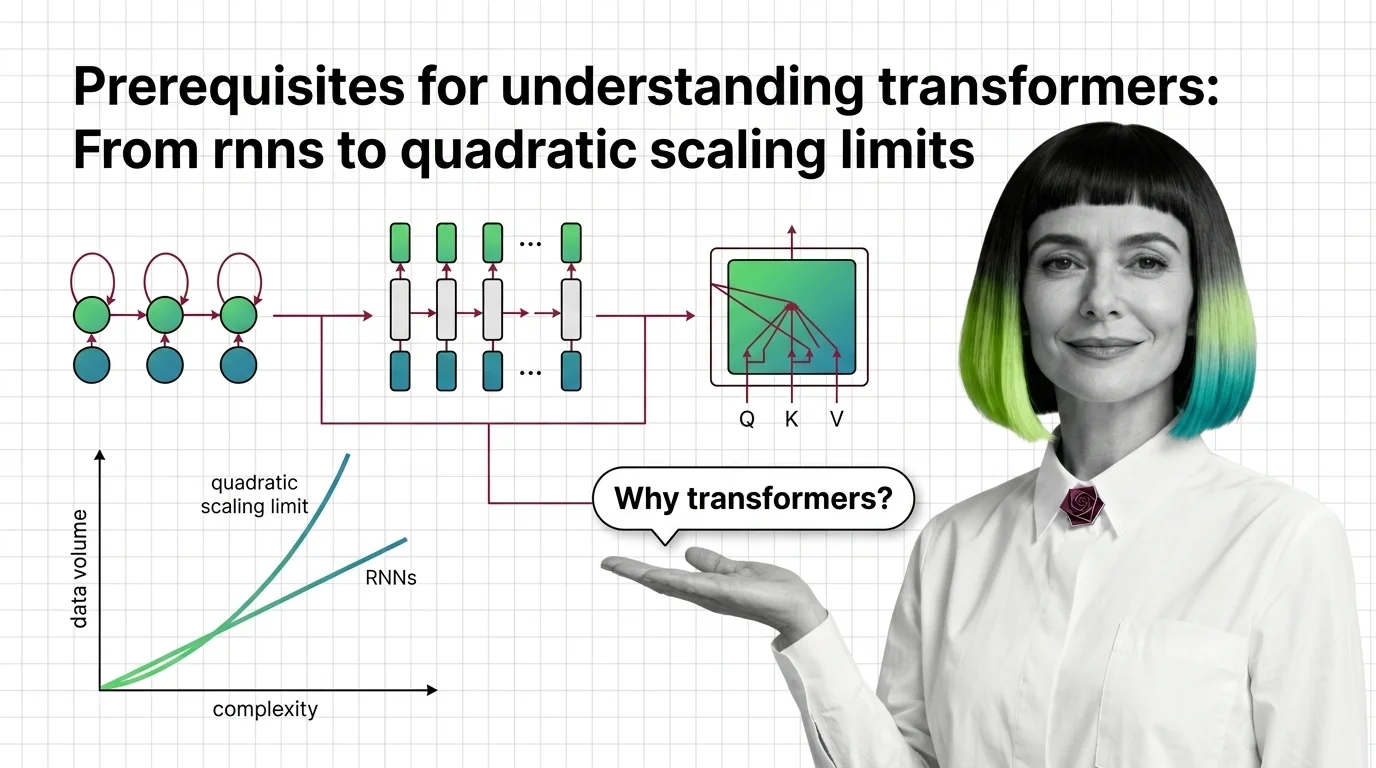
Table of Contents
ELI5
Transformers replaced older sequential models by processing all words at once, but this parallelism costs memory that grows with the square of the input length.
A recurrent neural network reads a sentence the way you read a phone number someone dictates too fast — one digit at a time, hoping the first few haven’t already faded from memory by the time you reach the last. For years, this was the architecture powering machine translation, text generation, and language understanding. It worked. Until it didn’t.
The transformer didn’t arrive because someone had a better idea about language. It arrived because the old idea — sequential processing — had a physical limit that no amount of engineering could remove.
The Sequential Bottleneck That Broke Language
Every architecture encodes an assumption about how information should flow. Recurrent networks assumed that language is strictly sequential: word n depends on word n-1, which depends on n-2, all the way back. This assumption is both true and catastrophically incomplete.
What should you understand before learning transformer architecture?
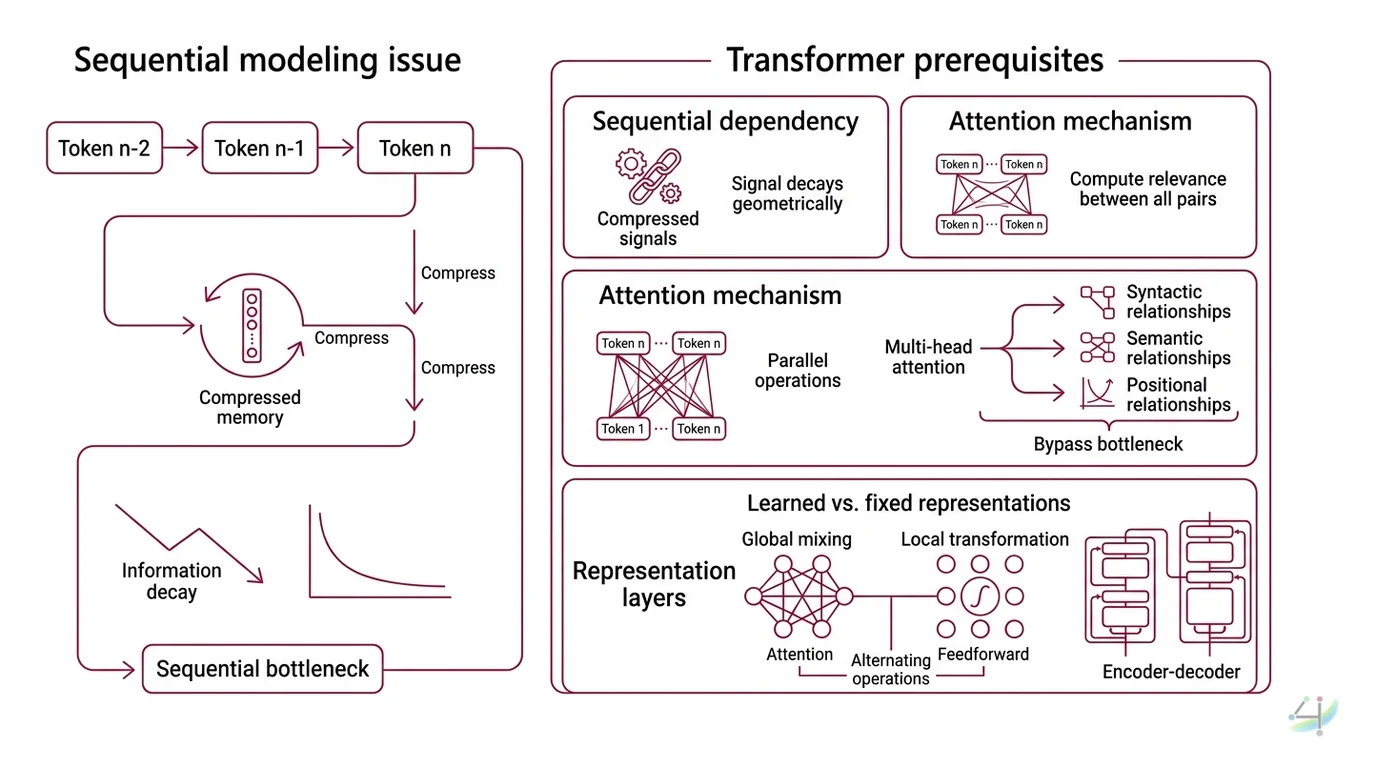
Three prerequisites define whether a transformer tutorial will make sense or remain opaque.
First, the problem of sequential dependency. RNNs and their gated descendants (LSTMs, GRUs) process tokens one at a time, maintaining a hidden state vector that acts as a compressed memory of everything seen so far. The trouble is compression. By the time the network reaches token 500, the signal from token 1 has been squeezed through hundreds of nonlinear transformations — each one a lossy compression step. Information doesn’t vanish instantly; it decays geometrically.
Second, the concept of Attention Mechanism itself. Attention is the operation that lets a model compute a relevance score between every pair of positions in a sequence, bypassing the sequential bottleneck entirely. Instead of routing information through a chain, attention connects every token to every other token in a single computational step. The Multi Head Attention variant runs this operation multiple times in parallel, each head learning to attend to different types of relationships — syntactic, semantic, positional.
Third, the idea of learned versus fixed representations. A Feedforward Network in a transformer applies the same two-layer transformation independently to each position, but this happens after attention has already mixed information across positions. Understanding why these two operations alternate — global mixing via attention, then local transformation via feedforward — is the structural intuition that makes the full Encoder Decoder architecture legible.
Without these three concepts, the transformer is a black box with impressive benchmarks. With them, it becomes a specific engineering answer to a specific mathematical problem.
Why did transformers replace RNNs and LSTMs for language modeling?
The short answer is parallelism. The complete answer is parallelism plus a performance gap that widened with scale.
RNNs are inherently sequential: token n+1 cannot be processed until token n has updated the hidden state. On a GPU with thousands of cores, this means most of the hardware sits idle. The computation is bottlenecked by the longest dependency chain, not by the total number of operations.
The Transformer Architecture eliminated this bottleneck by replacing recurrence with self-attention. Every token-to-token computation in a single layer happens simultaneously. Training time dropped from weeks to days.
The result was measurable and immediate. The original “Attention Is All You Need” paper achieved 28.4 BLEU on WMT 2014 English-to-German translation — more than 2 BLEU points above the previous best (Vaswani et al.). The English-to-French model hit 41.8 BLEU, trained in 3.5 days on 8 GPUs (Vaswani et al.). That training time mattered as much as the score; it meant researchers could iterate faster, which meant the architecture evolved faster.
But the replacement wasn’t just about speed. Attention captures long-range dependencies that recurrence structurally cannot. A transformer attending to position 1 from position 500 has the same computational path length as attending from position 2. In an RNN, that same dependency has a gradient path 499 steps long — and gradients either explode or vanish across paths that deep.
Not a tuning problem. A topology problem.
The Price Tag on Every Token Pair
Removing the sequential bottleneck solved one problem and introduced another. Self-attention computes a score between every pair of tokens in the sequence. For a sequence of length n, that means n times n comparisons — O(n squared) in both time and memory.
What are the computational limitations of transformer self-attention?
The quadratic cost is not an implementation detail; it is a mathematical property of the operation itself. Keles et al. proved that under the Strong Exponential Time Hypothesis (SETH), no algorithm can compute exact self-attention in truly sub-quadratic time (Keles et al.). Approximate methods can reduce the constant factor or trade accuracy for speed, but the fundamental scaling behavior of exact attention appears to be a hard boundary.
At a sequence length of 1,024 tokens, the attention matrix contains roughly one million entries. At 4,096 tokens, it grows to nearly seventeen million. At 32,768 tokens — a length modern models are expected to handle — the matrix exceeds one billion entries. Each entry requires computation, and each must be stored (or recomputed) during backpropagation.
This is why GPU memory, not model quality, is the binding constraint on context windows. The base transformer described in the original paper used d_model=512 with 6 encoder and 6 decoder layers and 8 attention heads — modest by current standards; modern production models use configurations orders of magnitude larger (Vaswani et al.). But the quadratic relationship between sequence length and compute remains unchanged.
Positional Encoding adds another layer of complexity. The original sinusoidal encoding scheme from the 2017 paper has been largely replaced by Rotary Position Embeddings (RoPE), now standard in most open-weight LLMs including LLaMA 3 and Mistral (Hugging Face Blog). RoPE encodes position through rotation in the embedding space — a geometric trick that makes extrapolation to longer sequences more stable, though it doesn’t eliminate the underlying quadratic cost.
Why do transformers struggle with very long sequences?
The struggle is not conceptual but economic. A transformer can attend to any position within its context window with equal ease. The problem is that the cost of attending to everything grows quadratically, which means there exists a practical ceiling on sequence length determined by available hardware.
Consider the arithmetic. Doubling the sequence length quadruples the attention computation. A model trained on 8,192 tokens requires four times the attention memory to process 16,384 tokens. This scaling behavior means that incremental gains in context length demand exponential increases in hardware.
Engineering mitigations exist. FlashAttention reorders the computation to reduce memory access overhead, achieving a significant speedup without changing the mathematical result. Grouped-Query Attention (GQA) reduces the number of key-value heads, cutting memory proportionally. These are optimizations within the quadratic regime, not escapes from it.
The real escapes come from architectures that abandon exact attention entirely. State Space Model architectures like Mamba process sequences in linear time by replacing pairwise attention with a selective state-space mechanism. The original Mamba paper showed its 3B-parameter model matching transformers twice its size, with 5x higher throughput (Gu & Dao). These results come from the original 2023 paper; the competitive positioning between SSMs and transformers continues to shift rapidly.
Hybrid architectures represent the current frontier — models like Jamba interleave transformer attention layers with Mamba blocks, using attention sparingly where long-range precision matters most.
What the Quadratic Wall Predicts
The mechanism produces specific, testable predictions about where transformers will succeed and where they will strain.
If your task requires attending to the full context — summarization of long documents, retrieval across a large codebase, multi-turn conversation — the quadratic wall will eventually dominate your compute budget. The solution space splits into three paths: truncate the context (lose information), approximate the attention (lose precision), or switch architectures (lose the ecosystem).
If your task uses short-to-medium contexts — classification, extraction, translation of individual sentences — the quadratic cost is negligible, and the transformer remains the most well-understood, best-tooled option available. The Hugging Face Transformers library alone supports over 400 model architectures with more than 750,000 Hub checkpoints as of v5 (Hugging Face Blog).
Rule of thumb: for short sequences of a few thousand tokens, the quadratic cost rarely matters in practice; once sequences stretch into the tens of thousands, it dominates your hardware budget regardless of optimization.
When it breaks: the failure mode is silent. A transformer processing a very long document doesn’t throw an error at a fixed position — it runs out of memory during the attention computation, producing either an OOM crash or, worse, quietly truncating context without warning. The model continues generating fluent text that simply lacks awareness of the truncated portions. Long-context failures look like competent answers to the wrong question.
For practitioners beginning to study transformer internals, the prerequisite knowledge maps cleanly. Understanding tokenization (BPE, WordPiece, SentencePiece) tells you what the model sees. Understanding attention tells you how the model relates what it sees. Understanding the quadratic cost tells you the boundary condition on everything the model can see at once. And understanding Fine Tuning tells you how to adapt the model’s behavior within those boundaries.
Security and compatibility notes:
- Hugging Face Transformers v5 (Dec 2025): TensorFlow and Flax backends were sunset; the tokenizer API was refactored to remove the Fast/Slow distinction. Projects relying on TF-based transformer pipelines require migration.
- Hugging Face Transformers security (2025): Twenty CVEs were reported, primarily involving code injection via malicious checkpoints. Upgrade to v5 and audit checkpoint sources before loading third-party models.
The Data Says
The transformer solved parallelism by making every token visible to every other token, and the cost of that visibility is a quadratic relationship that defines the architecture’s scaling ceiling. RNNs failed because they could not see far enough. Transformers may eventually strain because they insist on seeing everything. The prerequisite for understanding either is understanding the trade-off between the two.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors