Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Table of Contents
ELI5
Transformers turn words into number vectors, then use matrix multiplication and attention to figure out which words matter to each other.
The Misconception
Myth: You need a graduate degree in mathematics to understand transformer architecture. Reality: The math behind transformers uses four operations: vector embedding, matrix multiplication, softmax normalization, and dot products. Linear algebra at the undergraduate level covers all of them. Symptom in the wild: Engineers treating the attention mechanism as a black box because they assumed the prerequisites were beyond their reach — then making architectural decisions based on analogy instead of understanding.
How It Actually Works
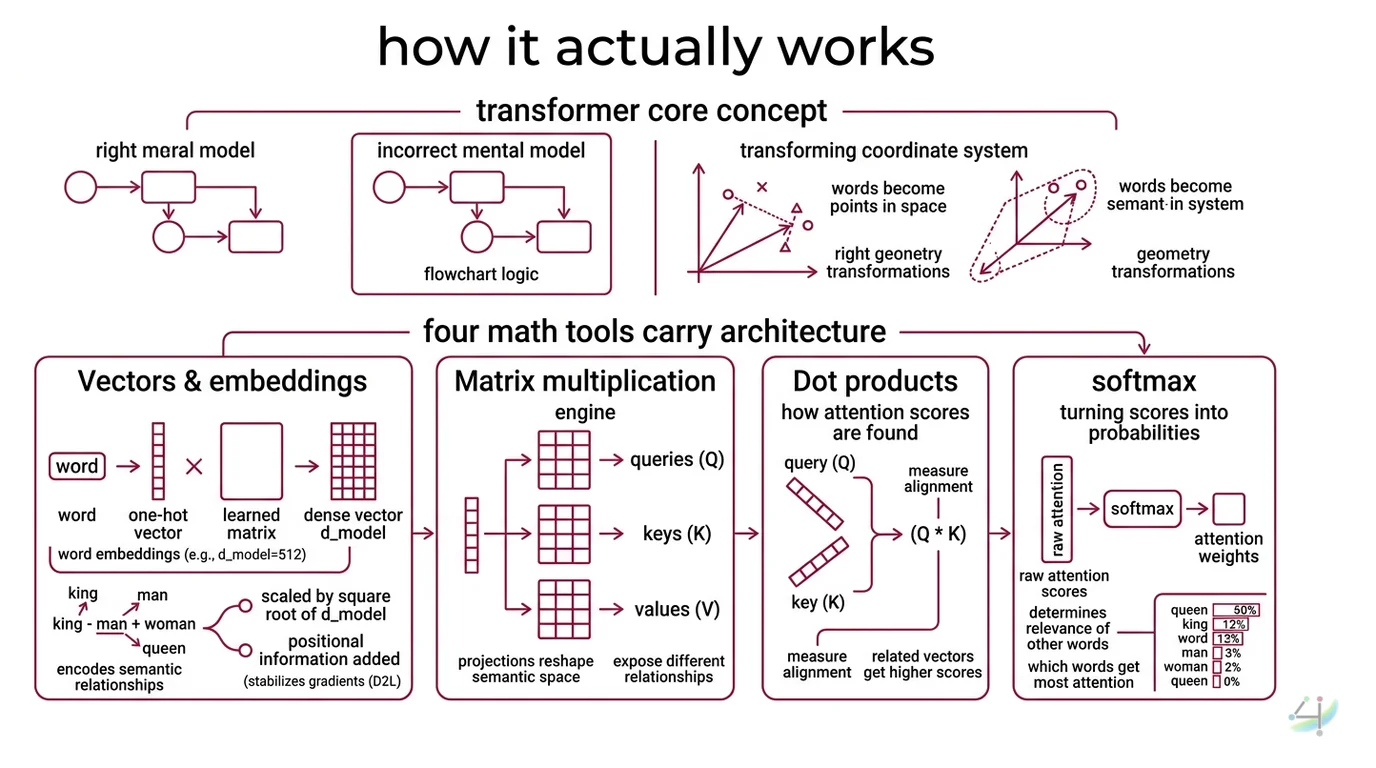
The Transformer Architecture is, at its foundation, a sequence of geometric operations on vectors. Every word becomes a point in high-dimensional space; every layer transforms the geometry of that space so that related meanings cluster together and unrelated ones drift apart. The right mental model is not a flowchart — it is a coordinate system that keeps rotating until meaning emerges from structure.
What math do you need to understand transformer architecture?
Four mathematical tools carry the entire architecture.
Vectors and embeddings. A word enters the transformer as a one-hot vector — a sparse, meaningless index — and gets multiplied by a learned embedding matrix to produce a dense vector of dimension d_model. In the original “Attention Is All You Need” paper, d_model was 512 (Vaswani et al.). That 512-dimensional vector encodes not just the word’s identity but its semantic relationships: king minus man plus woman lands near queen. The embedding matrix is learned during training, and it is the first set of parameters the model adjusts — and the first thing Fine Tuning modifies when you adapt a pretrained model to a new domain.
These input embeddings are scaled by a factor of the square root of d_model before positional information is added — a detail that stabilizes gradient flow during training (D2L).
Matrix multiplication. This is the engine. Every attention computation, every feed-forward layer, every projection from one representation space to another reduces to a matrix multiply. When the model computes attention, it multiplies the input by three separate weight matrices to produce queries (Q), keys (K), and values (V). Each of these projections reshapes the semantic space to expose different relationships.
The feed-forward layers in the original transformer use a hidden dimension of 2048 — four times d_model — creating an expansion-contraction bottleneck that forces the network to compress information through a narrow channel before reconstructing it (Vaswani et al.).
Dot products and softmax. The attention score between two tokens is the dot product of their query and key vectors, divided by the square root of the key dimension. The formula is exact: Attention(Q,K,V) = softmax(QK-transpose / square root of d_k) times V. The square root of d_k — which equals 64 in the base model — prevents the dot products from growing so large that softmax saturates into a near-one-hot distribution. Without this scaling, gradients vanish and training stalls.
Softmax itself converts a vector of raw scores into a probability distribution. Every attention weight sums to one across the sequence, which means the model must decide how to allocate limited attention — a zero-sum constraint that forces prioritization.
Linear algebra intuitions. If you understand that a matrix multiply is a change of basis — a rotation, scaling, or projection of one vector space onto another — you have the geometric intuition for every layer in the transformer. Attention is a soft lookup table implemented as a weighted average. The feed-forward network is a nonlinear projection. Layer normalization rescales vectors to unit variance. Everything is geometry.
How does positional encoding work in transformers?
A pure attention mechanism is permutation-invariant. Scramble the word order, and the raw attention scores stay identical. The model has no native concept of sequence.
Positional Encoding fixes this by injecting position information directly into the embedding vectors. The original transformer used sinusoidal functions — sine for even dimensions, cosine for odd dimensions — with wavelengths forming a geometric progression from 2-pi to 10000 times 2-pi. The formula: PE(pos, 2i) = sin(pos / 10000 raised to the power of 2i/d_model), and PE(pos, 2i+1) = cos(pos / 10000 raised to the power of 2i/d_model) (Vaswani et al.).
The elegance of this design: for any fixed offset k, the positional encoding at position pos+k can be expressed as a linear function of the encoding at position pos. The model can learn to attend to relative positions through simple linear transformations.
But sinusoidal encoding has a ceiling. It was designed for sequences of a few hundred tokens and does not extrapolate gracefully to longer contexts.
Modern production models — Llama 3, Claude, Gemini, Mistral, DeepSeek — have converged on Rotary Position Embedding, or RoPE (Su et al.). RoPE encodes position by rotating the query and key vectors in two-dimensional subspaces, which preserves the dot-product structure of attention while making relative position the native signal. The rotation angle is a function of the token’s absolute position, but the attention score depends only on the difference between positions. This is why RoPE scales to longer Context Window lengths far better than sinusoidal encodings ever could.
What is multi-head attention and why do transformers use it?
A single attention head computes one set of attention weights — one pattern of which tokens attend to which. That pattern captures one type of relationship: maybe syntactic dependency, maybe semantic similarity.
Multi Head Attention runs multiple attention heads in parallel, each with its own learned Q, K, and V projection matrices. The original transformer used 8 heads, each operating on 64-dimensional slices of the 512-dimensional model space (Vaswani et al.). The outputs are concatenated and projected back to d_model through another learned matrix.
Why not just use a bigger single head?
Because different heads learn to specialize. Empirical analysis — including Anthropic’s “A Mathematical Framework for Transformer Circuits” — shows that individual heads develop interpretable roles: one head tracks the previous token, another copies rare words forward, another resolves pronoun references (Anthropic Research). A single large head would blend these signals into noise.
The math is clean: 8 heads times 64 dimensions equals 512 total dimensions. The parameter count stays identical to a single 512-dimensional head. Multi-head attention does not add computational cost — it restructures it, allocating capacity across parallel subspaces that each solve a different sub-problem.
This factored design also explains why transformers generalize across tasks. The same head that learned syntactic parsing in English can partially transfer to code completion, because both involve long-range dependency resolution in sequential data. Libraries like Hugging Face Transformers expose these multi-head weights directly, making the internal geometry inspectable rather than opaque.
What This Mechanism Predicts
- If you skip the embedding scaling by the square root of d_model, you should observe training instability and slower convergence — the positional signal will dominate the semantic signal.
- If you remove the square root of d_k scaling from attention, the failure mode is softmax saturation: attention weights collapse to near-binary values and gradient updates vanish.
- If you increase the number of attention heads while keeping d_model fixed, each head operates in a lower-dimensional subspace. The tradeoff is that individual heads lose representational capacity even as collective coverage improves.
What the Math Tells Us
The prerequisite knowledge for transformers is not abstract — it is operational. Vectors are how the model sees words. Matrix multiplies are how it transforms what it sees. Dot products are how it decides what to pay attention to. Softmax is how it commits to a distribution.
Once you hold these four tools, every component of the transformer — from multi-head attention to positional encoding to the feed-forward sublayers — decomposes into a sequence of operations you already understand.
Rule of thumb: if you can multiply two matrices by hand and explain what a dot product measures geometrically, you have enough math for the core transformer. Everything else is architecture.
When it breaks: the linear algebra intuition fails at scale. Attention is quadratic in sequence length — doubling the context window quadruples memory and compute. This is why alternatives like State Space Models and Mixture Of Experts architectures are gaining traction; they trade the transformer’s expressive all-pairs attention for subquadratic approximations that sacrifice some representational flexibility for practical efficiency.
One More Thing
The original “Attention Is All You Need” paper has accumulated over 173,000 citations as of 2025, placing it among the top-10 most-cited papers of the 21st century (Wikipedia). That single paper — six encoder layers, six decoder layers, eight attention heads — spawned an entire computational paradigm.
And the math underneath it is four operations that fit on a napkin.
The gap between reading the paper and understanding the paper is not intelligence. It is knowing which four things to learn first.
The Data Says
Transformers are not mathematically exotic. They are geometrically elegant — built from embeddings, matrix multiplications, dot products, and softmax, arranged so that meaning emerges from the rotation and projection of high-dimensional vectors. The real prerequisite is not calculus or statistics; it is the willingness to think about words as points in space and sentences as transformations of that space. Everything the model does — attention, encoding position, splitting into parallel heads — follows from that single shift in perspective.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors