Prerequisites for Reading AI Benchmark Scores: Metrics, Pass@k, and Contamination

Table of Contents
ELI5
A benchmark score is a compressed summary, not a guarantee. Before you trust one, you need three things: what the metric actually counts, how many tries the model got (pass@k), and whether it quietly trained on the test.
Imagine a model posts a score in the low nineties on a popular coding benchmark. The launch blog calls it state of the art. You run the identical model on the identical benchmark and land somewhere in the low seventies. Nothing broke — no bug, no regression. The number simply never meant what the headline implied.
That gap is not noise to be ignored. It is the most informative thing in the room. A benchmark percentage is a measurement, and every measurement carries assumptions about what was counted and how. Strip those assumptions away and the same model can look like a breakthrough or a disappointment, depending entirely on who is doing the reporting.
The Variables a Single Percentage Swallows
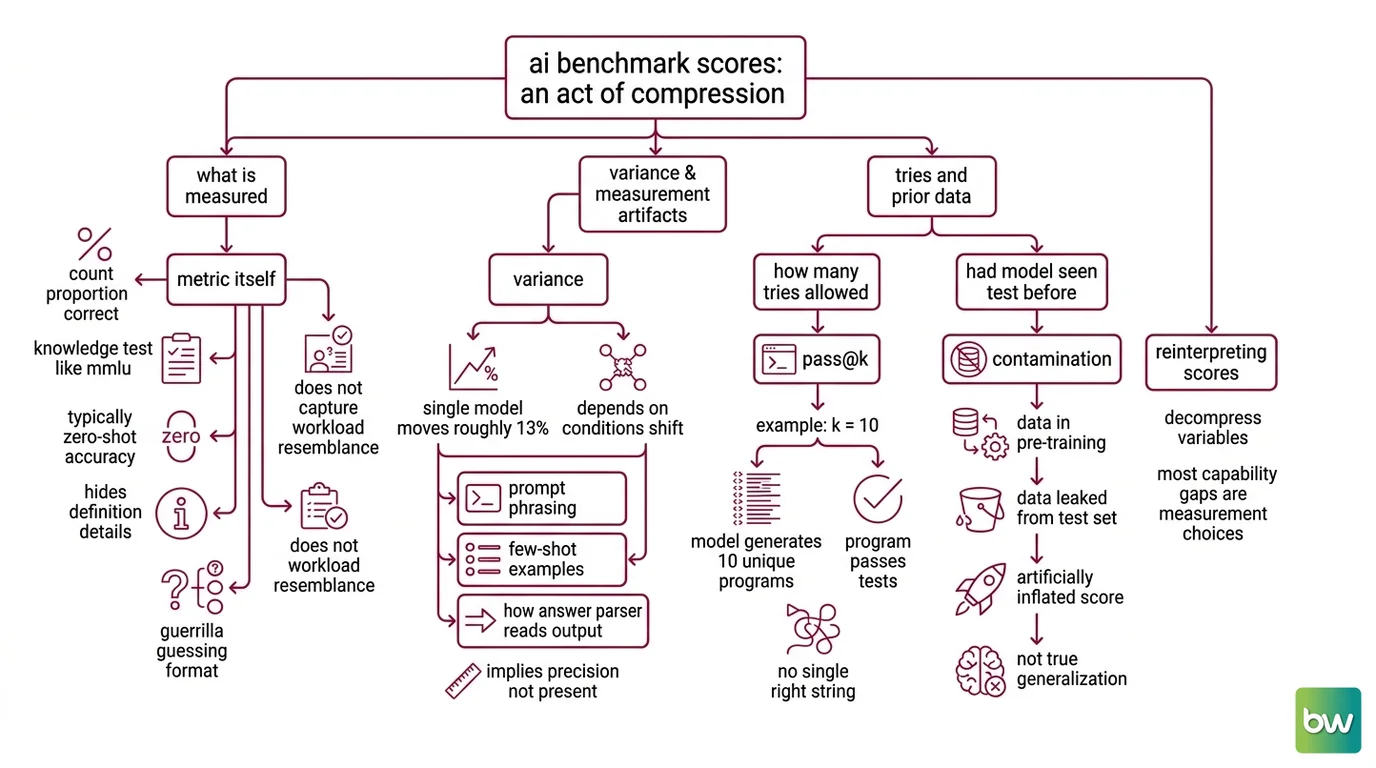
Every Benchmark Datasets score is an act of compression. Three independent variables — what you measure, how many attempts you allow, and what the model has already seen — collapse into one number on a leaderboard. Decompress them and most apparent capability gaps turn out to be measurement choices in disguise.
What do you need to understand before interpreting AI benchmark scores?
Start with the metric itself, because the word “score” hides what is being counted. Accuracy on a knowledge test like MMLU Benchmark is simply the proportion of items answered correctly, typically scored zero-shot on multiple-choice questions, per EmergentMind. That is a clean definition, but it tells you nothing about whether the questions resemble your workload or whether the model guessed well on a four-option format.
The second prerequisite is variance. The same model, on the same benchmark, does not return the same number twice when the conditions shift. On MMLU, a single model can move by up to roughly 13 percentage points depending on the run and the evaluation methodology, according to Galileo — prompt phrasing, the number of few-shot examples, and how the answer parser reads the output all push the result around. A score reported to two decimal places implies a precision the process does not have.
Not a capability gap. A measurement artifact.
The third prerequisite is the one the first two depend on: how many tries did the model get, and had it seen the test before? Those two questions deserve their own sections, because they are where most misread scores go wrong.
What does pass@k mean in coding benchmarks like HumanEval?
Coding benchmarks cannot use multiple-choice accuracy, because there is no single right string — there are infinitely many programs that pass. HumanEval handles this with 164 hand-written Python problems where the model generates a function body from a docstring, and each solution is graded by held-out unit tests, as introduced in the Codex paper. Either the code passes the tests or it does not. That is the unit of truth.
Pass@k is the metric built on top of that. It is the probability that at least one of k independently sampled solutions passes the unit tests, again from the Codex paper. The intuition is a developer hitting “regenerate”: pass@1 asks whether the first attempt works, pass@100 asks whether any of a hundred attempts works.
Estimating this naively — generate exactly k samples and check if any pass — is noisy. The Codex paper instead uses an unbiased estimator: generate n ≥ k samples, count the c that pass, and compute
pass@k = E[ 1 − C(n−c, k) / C(n, k) ]
where C is the binomial coefficient. The paper draws n = 200 samples per problem to estimate pass@1, pass@10, and pass@100 — though that sample count is the paper’s choice, not a universal rule; other evaluations pick their own n.
Here is where reported numbers mislead. A model whose pass@100 is high but whose pass@1 is mediocre is not a high-scoring model in any setting where you cannot automatically verify which sample is correct. pass@100 borrows a perfect oracle — the unit tests — to pick the winning sample. Strip the oracle away and you are back to pass@1. Many leaderboards report pass@1 unless stated otherwise, and some report a non-estimator “best-of-k” that is not the same quantity at all. To compare two coding scores honestly, k and the sampling temperature must be disclosed — without them, you are comparing different experiments and calling it a ranking.
When the Test Leaks Into the Training Set
A benchmark measures generalization only if the model has not already seen the answers. The moment evaluation data appears in the training corpus, the score stops measuring reasoning and starts measuring recall. This is the failure mode that quietly inflates the most famous numbers in the field.
What is benchmark contamination in LLM evaluation?
Benchmark Contamination, also called Benchmark Data Contamination, is when a model inadvertently incorporates evaluation-benchmark data through its training set, inflating scores and making them unreliable, as surveyed by Xu et al. (2024). The mechanism is mundane, which is exactly why it is hard to stop. Training corpora are scraped from the open web at enormous scale; public benchmarks live on that same open web. A copy of HumanEval in a GitHub mirror, an MMLU question quoted in a blog post, a solution pasted into a forum — any of these becomes training data. The model then recites where you assumed it reasoned.
This is the classic Train Test Split problem, scaled up until the test set and the training set can no longer be kept apart by intent alone. Detecting it after the fact is an active research problem. Methods such as Testset Slot Guessing and “Time Travel in LLMs” probe whether a model has memorized specific benchmark items, and the community CONDA shared task collects and tracks reported cases, per the CONDA 2024 report.
But detection has a hard ceiling. For a closed model with an undisclosed training set, contamination is generally undetectable from the outside — you cannot audit a corpus you are not allowed to see. This is a structural limitation, not a problem someone is about to solve. It is partly why fresh, held-out, and Synthetic Data Generation benchmarks keep appearing, along with harder successors like MMLU Pro and SWE Bench Verified. As of 2026, the original HumanEval and MMLU have largely saturated at the frontier — top models cluster above 90% — and are widely treated as contaminated, which is precisely why they no longer separate the best systems. A benchmark’s useful life ends when it leaks.
Reading a Score the Way the Model Was Tested
Once you treat a score as a compressed measurement, it starts making predictions you can act on. The decompression turns a passive number into an active diagnostic.
- If a coding result is reported without k and temperature, expect it to sit at the optimistic end of the model’s range, not where it lands on your first real attempt.
- If a benchmark predates the model’s knowledge cutoff and lives on the public web, expect some fraction of the score to be memorization rather than reasoning.
- If the same model’s score swings between two reports, suspect methodology — prompt template, few-shot count, answer parsing — before you believe the underlying capability changed.
The practical consequence is that the comparable artifact in an evaluation is rarely the headline percentage. It is the methodology: the dataset version, the sampling regime, and a credible claim that the model had not seen the questions. Two scores produced under different methods are not two points on one scale.
Rule of thumb: Trust a benchmark roughly in inverse proportion to its age and fame — the more famous and the older the test, the more likely it has already leaked into training data.
When it breaks: The entire framework assumes you can inspect what the model trained on. For closed models with undisclosed corpora you cannot, so contamination becomes a possibility you can suspect but never fully rule out — and a high score on a saturated public benchmark predicts almost nothing about novel, real-world tasks it was never built to measure.
The Data Says
A benchmark number is a measurement, and like any measurement it carries a method, a sampling regime, and an assumption that the test stayed secret. Remove those and the percentage is just a headline. The reproducible part of an evaluation is rarely the score itself — it is the methodology that produced it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors