Prerequisites for RAG Grounding: Retrieval Quality, the RAG Triad, and Faithfulness Metrics

Table of Contents
ELI5
** RAG Guardrails And Grounding** is not a wall you bolt onto the output of a retrieval-augmented system. It is a measurement framework with three checkpoints — was the right context retrieved, did the answer stay faithful to it, and did it address the user’s question?
The first time most teams add Guardrails to a RAG system, they reach for a hallucination filter, wire it to the output, and call the work done. Six weeks later the same teams discover the hallucinations were never quite the bug they thought. The retrieval was returning loosely related chunks, the generator was paraphrasing those chunks faithfully, and the filter was silently approving every confident-sounding answer that happened to be grounded in the wrong evidence. Guardrails do not sit on top of RAG. They sit underneath — in the metrics that decide whether each stage of the pipeline is even functioning.
The Mental Models You Need Before Guarding a RAG System
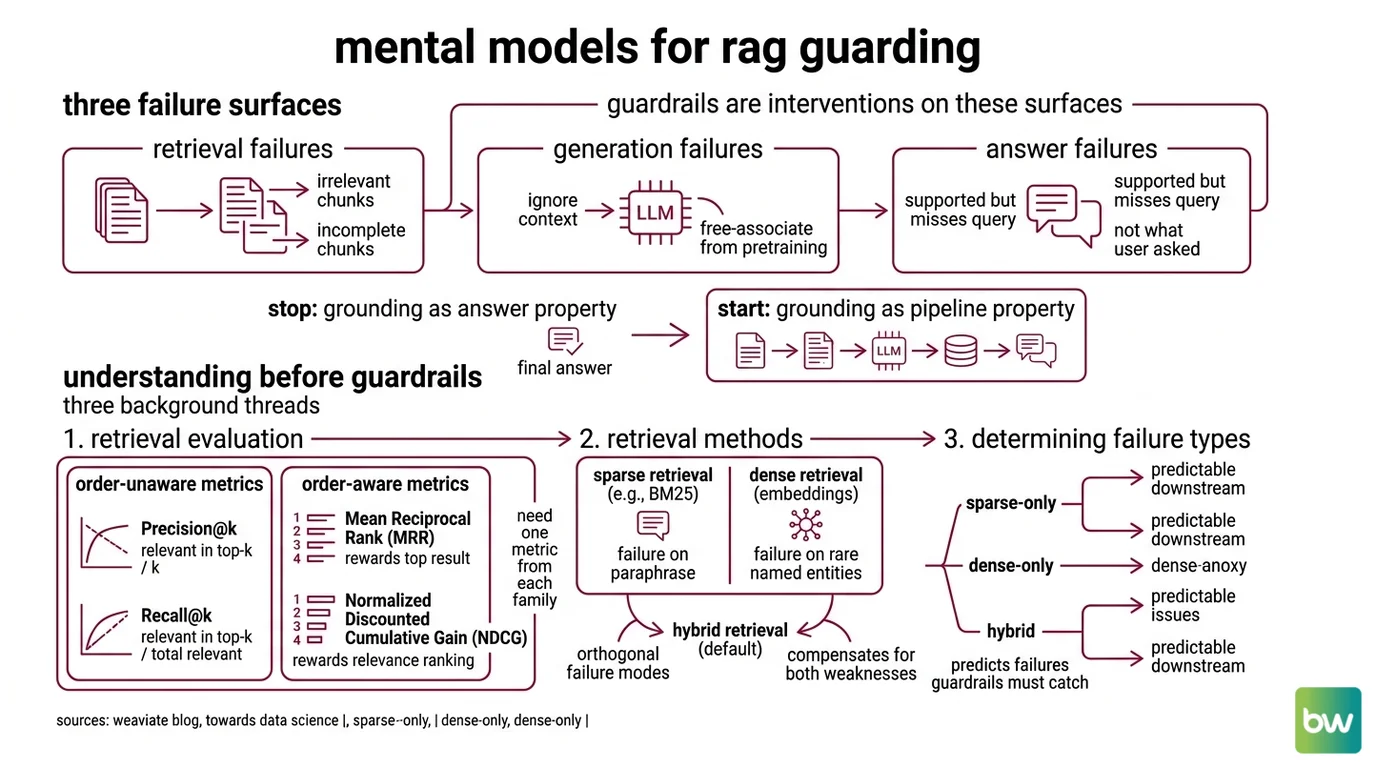
A RAG pipeline has three failure surfaces, not one. Retrieval can return irrelevant or incomplete chunks. Generation can ignore the chunks it was given and free-associate from the model’s pretraining. The final answer can be technically supported by the retrieved context yet still miss what the user actually asked. Guardrails are interventions on these three surfaces; you cannot intervene on a surface you cannot measure.
The mental shift is small but consequential: stop thinking of grounding as a property of the answer and start thinking of it as a property of the pipeline.
What do you need to understand before implementing RAG guardrails?
Three background threads, in order.
First, retrieval evaluation. If you cannot score the retriever in isolation, you cannot tell whether downstream errors are coming from bad context or bad generation. The standard metrics split into two families. Order-unaware metrics — Precision@k = relevant in top-k / k, and Recall@k = relevant in top-k / total relevant in the corpus — measure whether the right documents made it into the cutoff at all (Weaviate Blog). Order-aware metrics — Mean Reciprocal Rank, where MRR=1 means the first result is always correct, and Normalized Discounted Cumulative Gain, which rewards placing more relevant docs higher and is preferred when relevance is graded rather than binary — measure whether the retriever ranked the good results above the noise (Weaviate Blog; Towards Data Science). Without one metric from each family, you are flying half-blind.
Second, the Sparse Retrieval versus dense retrieval split. The retriever you ship determines what kinds of failures the guardrails downstream have to catch. Sparse methods like BM25 fail on paraphrase; dense embedding methods fail on rare named entities. Hybrid retrieval is now the default precisely because the two failure modes are orthogonal. The guardrail layer cannot fix a retrieval method that is structurally blind to the user’s query.
Third, the distinction between Grounding and retrieval quality. These two phrases are used almost interchangeably in vendor blog posts, and the conflation matters. Strictly, grounding refers to generation faithfulness — whether the answer’s claims can be traced back to the retrieved context. Retrieval quality refers to whether the right context was retrieved in the first place. A perfectly grounded answer that cites the wrong document is still wrong; a poorly grounded answer over the right document is also wrong. The two failures look identical to the end user and have completely different fixes.
Why isn’t a hallucination filter alone enough?
A hallucination filter operates on the (answer, context) pair after both have been produced. It can catch one specific failure: the generator inventing facts not present in the retrieved context. It cannot catch the retrieval that returned irrelevant chunks, because by the time the filter runs the irrelevant chunks have already been promoted to “ground truth” for the faithfulness check. It cannot catch the answer that is faithful to the context but unresponsive to the question, because faithfulness and relevance are independent dimensions.
Not a filter. A framework.
The filter is one component of a measurement framework that also has to score the retriever and score the answer-question alignment. Without those two upstream checks, the filter is verifying a fluent paraphrase of whatever happened to land in the context window — an audit of the wrong artifact.
The RAG Triad and Its Reference Implementations
The cleanest articulation of this three-checkpoint framework is the RAG Triad, introduced in 2023 by the TruEra team in the TruLens open-source project and computed via LLM-as-a-Judge feedback functions (TruEra). The same three checks appear under different names in other libraries — Ragas calls them Context Precision, Faithfulness, and Answer Relevancy; DeepEval uses similar splits — so the Triad is best understood as a naming convention for an idea that the field converged on independently.
The shift the Triad demands is from one number to three.
What is the RAG Triad and why is it the prerequisite framework for grounding?
The Triad scores a RAG response on three independent axes (TruLens Docs):
- Context Relevance — verifies that the retrieved chunks are relevant to the query, before generation runs. This is a guardrail on the retriever.
- Groundedness — measures the extent to which claims in the LLM response can be attributed back to source text. The response is split into atomic claims, and each claim is independently checked against the retrieved context. This is the guardrail on the generator.
- Answer Relevance — confirms the final response actually addresses the user input, regardless of whether it was grounded in the right evidence.
The three axes catch failure classes the others cannot see. A high-groundedness, low-context-relevance answer is a faithful summary of the wrong document. A high-context-relevance, low-groundedness answer is a confident hallucination on top of correct evidence. A high-relevance-on-both-axes, low-answer-relevance response is the model answering a question the user did not ask. Any guardrail strategy that does not measure all three is, by construction, blind to two of these failure modes.
The implementations matter because each picks a different mechanism for the central question — how do you decide if a claim is supported by a chunk of text?
The RAG Evaluation ecosystem has settled on three families of approach.
LLM-as-a-Judge. TruLens, Ragas, and DeepEval all default to prompting a separate LLM to judge entailment between answer and context. Ragas formalizes its Faithfulness score as (claims in answer that can be inferred from retrieved context) / (total claims in answer), with the calculation done in two steps: extract atomic claims from the generated answer, then cross-check each claim against the retrieved context for entailment (Ragas Docs). The score lives in the 0–1 range, higher is better. The judge can be GPT-4-class, Claude, or any model capable of structured entailment judgments — and that flexibility is also the method’s main weakness, because the score depends on which judge you pick.
Specialized hallucination-detection models. Vectara HHEM ships HHEM-2.1-Open as a T5-based open-weights classifier on Hugging Face — under 600 MB at 32-bit precision, roughly 1.5 seconds for a 2k-token input on a modern x86 CPU (Vectara Hugging Face). The closed-weight successor HHEM-2.3 powers Vectara’s public hallucination leaderboard via API, while the open variant can be plugged into Ragas as the entailment classifier in the second step of the Faithfulness calculation, replacing the LLM judge with a smaller, deterministic, locally-runnable model (Ragas Docs).
Reasoning-grade detector models. Patronus Lynx fine-tunes Llama-3-70B-Instruct (also released as an 8B variant) specifically for hallucination detection. As of its July 2024 release, Lynx scored 87.4% accuracy on HaluBench against GPT-4o’s 86.5%, becoming the first open-source detector to surpass GPT-4o on that benchmark; HaluBench itself is a 15,000-sample benchmark drawn from real-world domains including Finance and PubMedQA medical QA, released alongside the model (Patronus AI; arXiv Lynx paper). Lynx’s differentiator is that it produces a score and the reasoning for the verdict, which makes its judgments auditable in a way that black-box scores are not.
How do production guardrails wire these scores into the response loop?
A score is not yet a guardrail. The guardrail is the action the system takes when the score crosses a threshold.
Nemo Guardrails is the reference open-source framework for this wiring. Its fact-checking rail offers two built-in approaches: a Self-Check approach where an LLM verifies entailment between the response and the evidence and is allowed to abstain, and an AlignScore approach using a built-in RoBERTa-based factual-consistency scorer (NVIDIA NeMo Guardrails Docs). The framework exposes a $relevant_chunks context variable that holds the retrieved evidence used for the fact-checking step — making the wiring between the retriever’s output and the guardrail’s input explicit rather than implicit.
The 0.20.0 release (January 2026) is the current canonical entrypoint, and the repository now lives at github.com/NVIDIA-NeMo/Guardrails after the move into the NVIDIA-NeMo organization (NVIDIA NeMo Guardrails Repo). Older tutorials pointing at the previous repo path still resolve via redirect, but new integrations should target the new canonical path.
What the Triad Predicts — and Where It Breaks
Once you hold the three-axis structure, the catalogue of guardrail tools stops looking like a market of competing products and starts looking like engineered responses to one of three failure surfaces. The framework gives you a diagnostic discipline: when a RAG system misbehaves, you can localize the fault before you start changing components.
If Context Relevance is low, expect downstream Groundedness to look misleadingly fine — the generator will faithfully ground its answer in the wrong evidence. The fix is upstream, in the retriever or the chunking strategy, not in a stronger hallucination filter.
If Context Relevance is high but Groundedness is low, expect that the generator is over-relying on its pretraining priors. The fix is in the generation prompt or in adding a dedicated detector model on the output, not in tightening the retriever.
If both Context Relevance and Groundedness are high but Answer Relevance is low, expect the failure to be in question understanding — query rewriting, intent classification, or a missing step that decomposes multi-part questions. No improvement to retrieval or generation will fix this.
Pick the metric to the failure surface; do not pick the loudest tool to the loudest symptom. A faithfulness-focused guardrail on a retrieval-broken pipeline buys you nothing but a more confident description of the same wrong answer.
Rule of thumb: measure all three Triad axes before you choose any guardrail product. The shape of the failure tells you which layer to harden, and most teams discover that two of the three axes are already healthy and only one needs intervention.
When it breaks: every score in this framework is judge-dependent. Ragas, TruLens, and DeepEval all default to LLM-as-a-Judge for the entailment check, and the resulting scores vary across judge models, prompt versions, and even temperature settings. A faithfulness score of 0.78 from GPT-4 is not directly comparable to 0.78 from Claude or from HHEM-2.1-Open. Treat the Triad as a trend signal within a fixed judge configuration, not as a portable absolute number you can quote across systems or vendors.
The Data Says
RAG guardrails are not a hallucination problem solved at the output. They are a measurement discipline applied at three checkpoints — retrieval, generation, and answer relevance — with each checkpoint catching failures invisible to the others. The reference implementations of this discipline (TruLens, Ragas, HHEM, Lynx, NeMo Guardrails) differ in how they score entailment, not in whether the three checkpoints are needed. That part the field already settled.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors