Multimodal RAG Prerequisites: Vision-Language Models, Cross-Modal Alignment
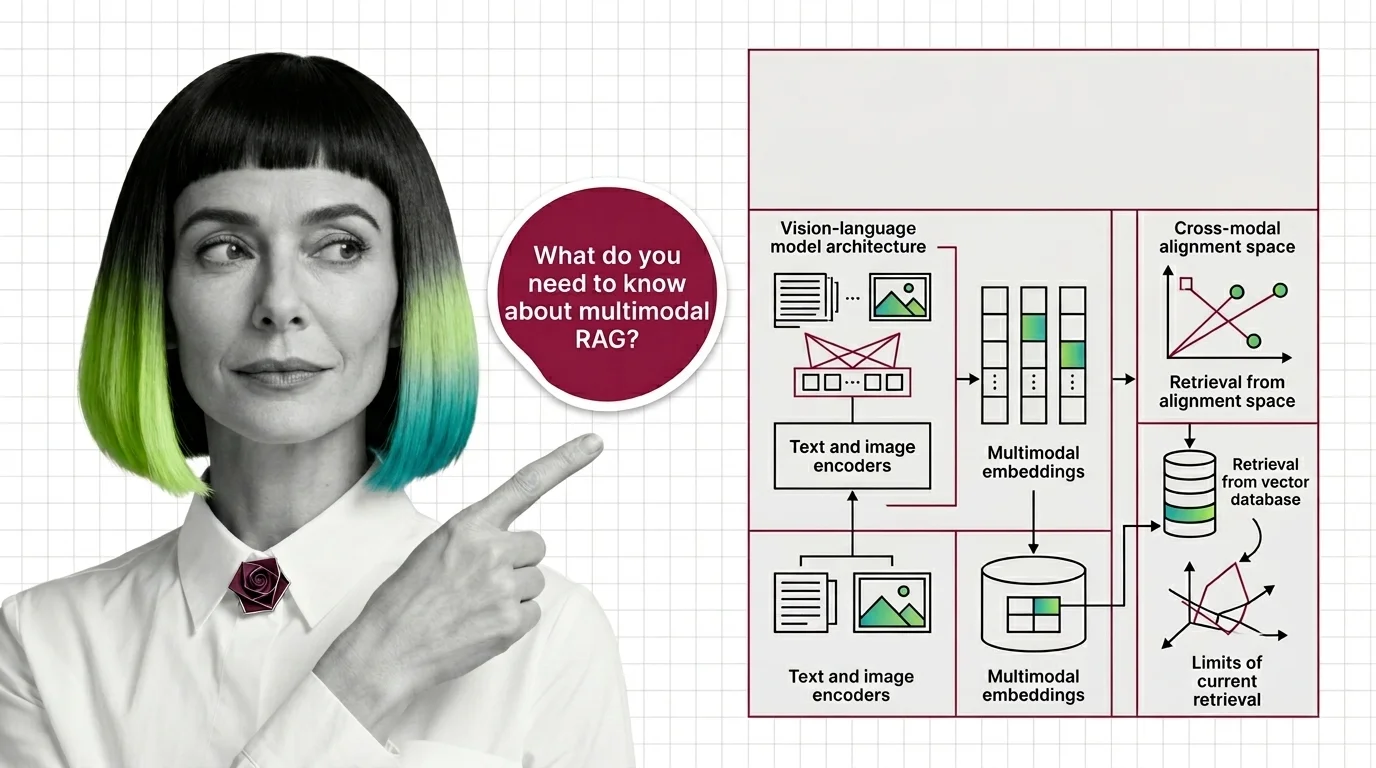
Table of Contents
ELI5
Multimodal RAG retrieves text, images, and tables in one pipeline. Before that works, you need vision-language encoders that map pixels and words into the same space, plus a parser that turns documents into typed objects.
A team builds a clean text RAG pipeline, then decides to add images. They swap in a multimodal encoder, drop image vectors into the same store as text, run a query, and watch the retriever return text snippets ranked far above semantically perfect images of the same concept. The code is correct. The geometry is not.
That gap — between “the embeddings exist” and “the embeddings actually compare” — is what the prerequisites for Multimodal RAG are for.
The Stack Before You Have a Pipeline
Before any of the multimodal-specific machinery does useful work, several layers have to be in place. Some of them are general RAG plumbing the team probably already understands. The rest are vision-specific and break in ways text RAG cannot warn you about.
The interesting failures happen at the seams between these layers, not inside any one of them.
What do you need to know before learning multimodal RAG?
Five components sit underneath any working multimodal RAG system, and they are not interchangeable.
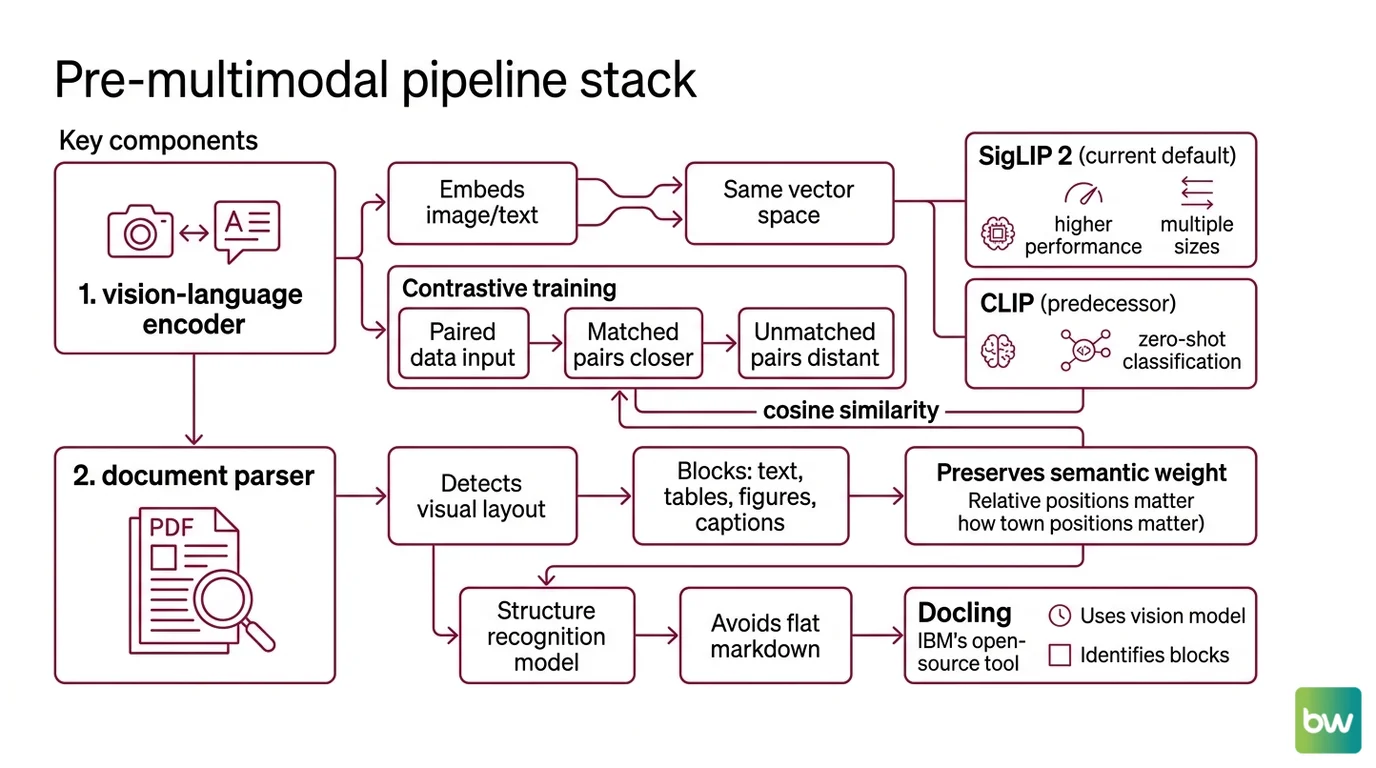
The first layer is a vision-language encoder. This is a model that produces an Embedding for an image and an embedding for a text query, in the same vector space, so cosine similarity is meaningful across modalities. The original recipe is contrastive: train two encoders on a large corpus of paired image-text data so matched pairs land closer together than unmatched ones. OpenAI’s CLIP paper trained over 400 million image-text pairs this way and demonstrated zero-shot transfer to image classification with no task-specific fine-tuning. SigLIP 2, released by Google in February 2025, replaces the softmax contrastive loss with a sigmoid loss and ships in four sizes from 86M to 1B parameters, outperforming the original SigLIP and CLIP at every scale on zero-shot classification and retrieval (Hugging Face SigLIP 2 blog). For new builds, SigLIP 2 is the current default; CLIP remains workable but is increasingly framed as the predecessor.
The second layer is a document parser that respects structure. PDFs are not text. They are visual layouts where the position of a table relative to its caption carries semantic weight. A parser that flattens everything to Markdown loses what the retriever needs to disambiguate. Docling, IBM’s open-source toolkit, uses a vision model to detect layout blocks — text, tables, figures, captions — and a separate structure-recognition model to preserve their relationships (IBM Research Blog). Unstructured emits typed elements (Title, NarrativeText, Table, ListItem) instead of flat Markdown. Either way, the output of Document Parsing And Extraction is a graph of typed objects, not a string. This is the first place where text-only RAG habits will quietly hurt you.
The third layer is a retrieval pattern that does not pretend everything is a single vector. The naive approach — embed images, embed text, throw both into one collection — is the one the introduction described. It usually loses to a slightly more thoughtful pattern. LangChain’s multi-vector retriever indexes summaries or captions for retrieval but returns the original document, image, or table to the generator (LangChain Blog). LlamaIndex maintains separate text and image vector stores and fuses results with explicit ranking logic. The shared idea: the thing you retrieve on does not have to be the thing you hand to the model.
The fourth layer is metadata as a first-class citizen. Metadata Filtering is not multimodal-specific, but it carries more weight in multimodal stacks because modality is itself a metadata field. “Restrict to figure captions from chapter 3” is a metadata query that prevents many cross-modal retrieval pathologies before they happen.
The fifth layer is optional: a graph backbone. Knowledge Graphs For RAG is general RAG plumbing rather than multimodal-specific machinery, but it becomes useful when documents have strong cross-references between figures, tables, and prose. A graph layer is not a prerequisite for multimodal RAG. It is a prerequisite for multimodal RAG that does not collapse on long technical PDFs.
That is the stack. The reason the order matters is that swapping out a layer affects everything downstream — a different encoder changes which retrieval pattern is viable, which changes what parser output the encoder needs as input.
Where Image and Text Embeddings Refuse to Meet
Two encoders trained on hundreds of millions of paired examples should land an image and its caption near each other in the shared space. They do — relative to random pairs. They emphatically do not — relative to other text or other images.
This is not a bug in any one model. It is a property of how contrastive training shapes the geometry, and it has direct consequences for how the retriever ranks results.
What are the technical limits of multimodal embeddings and vision-language retrieval?
Three failure modes show up reliably enough that they are worth naming before you build, not after.
The first is the modality gap. Liang et al.’s 2022 paper “Mind the Gap” documented that in CLIP-style spaces, image embeddings and text embeddings cluster in separate narrow cones rather than mixing freely (Mind the Gap paper). The gap is induced by deep-network initialization combined with the contrastive objective; later work reframes it as low uniformity on the latent sphere, but the empirical phenomenon is the same. The practical effect: when you query a mixed-modality store with text, the top results tend to be other text, not the relevant image — even when the image is a strictly better answer. A 2025 follow-up measured this directly and showed intra-modal similarities systematically dominate cross-modal ones in retrieval workloads (Closing the Modality Gap paper).
The second failure is that captioning-then-text-embedding does not fix it. A reasonable engineering reflex says: skip the joint space, caption every image with a strong VLM, embed the captions as text, and retrieve over text only. ColPali tested this baseline against late-interaction visual retrieval that encodes the page image directly and skips the caption step. The visual retriever won, even when the captioning baseline used a strong VLM (ColPali paper). On the ViDoRe benchmark, the advantage was largest on infographic-heavy and table-heavy documents — exactly the cases where multimodal RAG is supposed to shine. Captioning is a legacy baseline now, not a default.
The third is object hallucination in the vision-language model itself. Even after retrieval works, the synthesizing VLM can describe objects that are not in the retrieved image. The “Hallucination of Multimodal LLMs” survey documents this as a frequent and well-studied failure mode, and notes that even reference benchmarks like RefCOCO contain labeling and bounding-box errors. This is the multimodal analog of text-side hallucination, and it is not solved by retrieving the right image — only by grounding the generation step against it.
The shape of the problem is geometric, not lexical. Each of these failures is a fact about where vectors land in space. None of them is fixed by a better prompt.
Not a prompting problem. A geometry one.
What Changes When You Plan for the Gap
Once the prerequisites are in place, the design questions stop being “which embedding model” and start being “how does retrieval behave when the geometry misbehaves.” Several if/then predictions follow directly from the mechanism.
If you index images and text into a single collection without modality-aware reranking, expect text results to crowd out images on text queries — and the reverse on image queries. The modality gap acts as an unwanted sort key.
If you rely on captioning-then-text-embedding for visual documents, expect retrieval quality to degrade on infographic-heavy or table-heavy corpora compared to a VLM-native retriever. The caption is a lossy projection of the page.
If your generator hallucinates objects on retrieved images, the failure is at the generation step, not the retrieval step. A stronger encoder will not help — only a grounding mechanism that forces the VLM to attend to what was actually returned.
If you skip parser output that preserves structure, your “multimodal” RAG is really text RAG with images attached. The retrieval surface is text-shaped no matter what you put into the encoder.
Rule of thumb: Match the retrieval pattern to the geometry — if your encoder has a documented modality gap, your retriever needs to know which modality each query and document belongs to.
When it breaks: The most common failure mode is not a bad embedding but a retriever that treats cosine similarity as if it were modality-agnostic. The mathematics does not care that you intended a fair comparison; the cones are still cones. A separate modality-aware ranker, or per-modality vector stores fused after retrieval, is usually less work than retraining the encoder.
A note on dependencies. GPT-4o, which appears in many older multimodal RAG tutorials as the synthesis model, was retired by OpenAI on February 13, 2026 (OpenAI Help Center). Tutorials that anchor on it should be treated as legacy reference material, not as deployable patterns.
What the Field Actually Looks Like
Vision-language models have stopped being a niche. The recent survey “Vision Language Models: A Survey of 26K Papers” tracked the share of VLM work across CVPR, ICLR, and NeurIPS abstracts and found it rose from 16% in 2023 to 40% in 2025 (VLMs: A Survey of 26K Papers). The first systematic survey of the multimodal RAG subfield appeared the same year (Multimodal RAG Survey). The infrastructure has matured ahead of the conceptual frame, which is why most production failures are still about the same three things: a bad parser, a naive joint-store retrieval pattern, and a missed modality gap.
The Data Says
Cross-modal alignment is a goal, not a single algorithm. CLIP, SigLIP 2, and ColPali are different bets on how to reach it, and each has documented limits — the modality gap chief among them. The prerequisite for multimodal RAG is not a model. It is a stack: parser, encoder, retrieval pattern, metadata, and a working theory of where vectors land.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors