Multi-Agent Systems: Prerequisites and Hard Technical Limits

Table of Contents
ELI5
A multi-agent system is several LLMs working together through tools, memory, and a shared protocol. You should not build one until you understand the single-agent loop — and even then, four physical limits quietly break most orchestrations.
The seductive picture is a swarm of specialists — researcher, coder, critic, planner — humming in parallel and outperforming any single model. The unglamorous reality is that most production “agentic” systems that work are workflows, not autonomous orchestrations, and the ones that fail tend to fail for the same handful of structural reasons. Before you reach for a Multi Agent Systems framework, the question worth asking is whether the underlying primitives are even solid.
They usually aren’t.
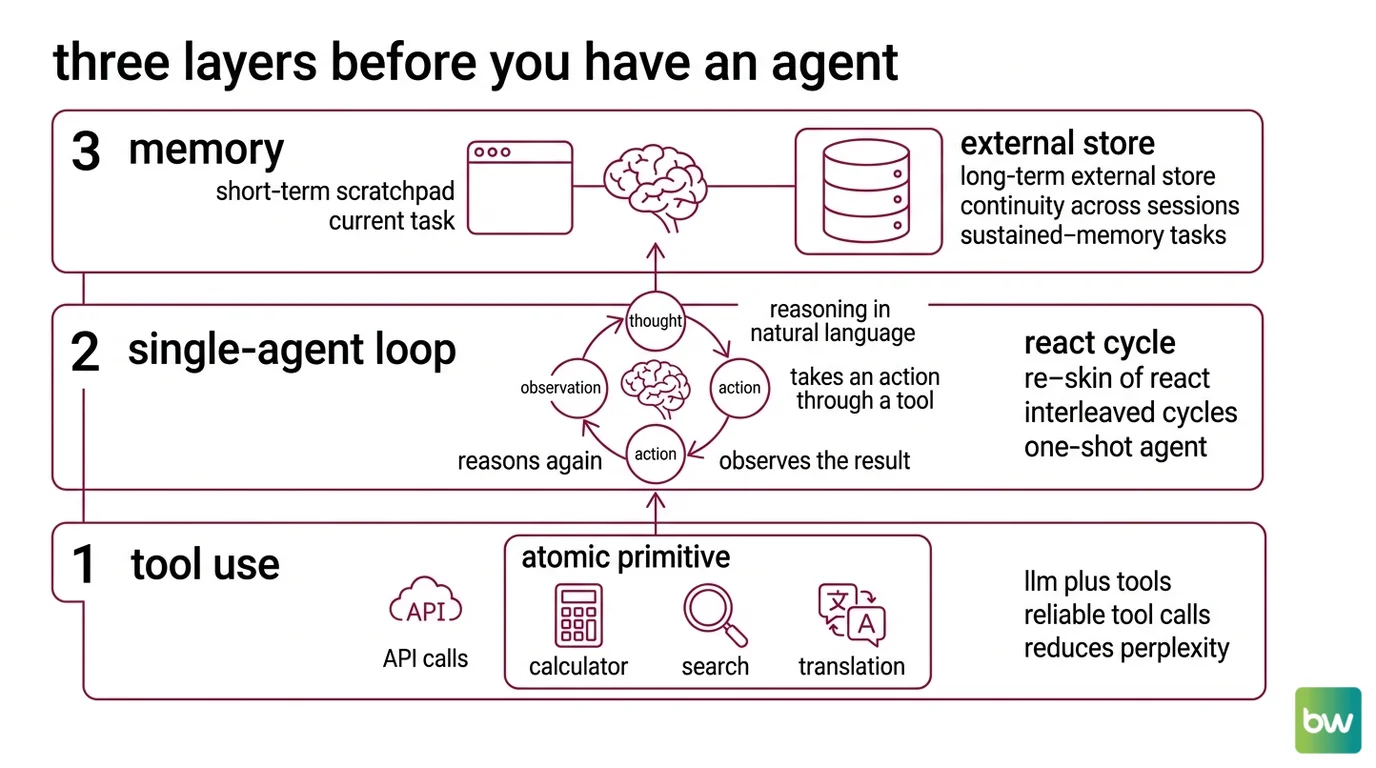
Three Layers Before You Have an Agent at All
A multi-agent system is not a fresh paradigm; it is a stack of three older inventions that must each be working before composition makes sense. Skip a layer and you do not get a sophisticated orchestrator — you get an expensive way to amplify the bug at the bottom of the stack.
What do you need to understand before building multi-agent systems: tool use, memory, and single-agent loops?
Three layers, in order:
Layer 1 — Tool use. This is the atomic primitive. Toolformer (Schick et al.) turned “LLM plus tools” from a prompt hack into a trainable capability: the model learns, in a self-supervised way, to insert API calls — calculator, search, translation — exactly where the call’s result reduces perplexity on the surrounding tokens (Toolformer paper). Modern function-calling APIs from OpenAI and Anthropic expose the same idea through JSON schemas. Without reliable tool calls, every agent built on top is hallucinating its environment.
Layer 2 — The single-agent loop. Every agent SDK is a re-skin of ReAct (Yao et al.): interleaved Thought → Action → Observation cycles, where the model reasons in natural language, takes an action through a tool, observes the result, and reasons again. On HotPotQA and Fever the loop beats action-only baselines; on ALFWorld and WebShop a one-shot ReAct agent beat imitation- and reinforcement-learning baselines trained on more than a hundred thousand tasks (ReAct paper). The implication is uncomfortable: the loop is doing most of the heavy lifting in the systems people call “agentic.”
Layer 3 — Memory. A short-term scratchpad — the Agent Memory Systems that live inside the context window — handles the current task. A long-term external store handles continuity across sessions. LongMemEval shows commercial assistants drop roughly thirty percent in accuracy on sustained-memory tasks, which means a multi-agent system without an external store will hemorrhage cross-session context the moment the lead agent’s window fills (LongMemEval paper). Memory is not a feature you bolt on later; it is the substrate the orchestrator coordinates over.
Anthropic’s own framing in Building Effective AI Agents makes the prerequisite chain explicit: their canonical baseline is the augmented LLM — a single model with tools, retrieval, and memory — and they distinguish workflows (LLMs on predefined code paths) from agents (LLMs dynamically directing their own process). Their headline guidance is to find the simplest solution possible and only increase complexity when needed; most reliable production systems described as “agentic” are, in their measurement, workflows (Anthropic Engineering).
Not architecture. Discipline.
The Four Physics That Break Multi-Agent Systems
Once those three layers are working, the next failure surface is coordination itself. Multi-agent failures rarely look like one model “going wrong.” They look like four physical pressures acting on the system at once, each compounding the others. The MAST taxonomy from Cemri et al. catalogues fourteen distinct failure modes across system design, inter-agent misalignment, and task verification, built from more than 1,600 annotated traces across seven frameworks with high inter-annotator agreement (Cemri et al., 2025). The four headings below are the shape underneath that catalogue.
What are the technical limitations of multi-agent systems: context blow-up, error compounding, and coordination overhead?
Context blow-up. The lead agent does not just see its own thinking; in any orchestrator-worker pattern, the sub-agent traces and tool outputs flow back into the lead window for synthesis. A documented production case shows a fifteen-turn conversation reaching roughly thirty thousand tokens, with single tool calls returning anywhere from two hundred tokens (a weather API) to several thousand (a database dump). Industry analyses report multi-agent stacks running at roughly three-and-a-half times the token cost of a comparable single agent, and runaway retry loops burning forty dollars in minutes (Future AGI / TDS analysis). The model has not become smarter; the context has become a landfill.
Error compounding. Reliability multiplies along the chain. If each step succeeds independently with probability 0.95, a five-hop flow — plan, delegate, sub-step one, sub-step two, synthesise — lands at roughly 0.77; a five-hop multi-agent pipeline at ninety-five-percent per-step reliability fails about one call in four. This arithmetic is illustrative, not measured, but it is also unavoidable: every additional agent or tool hop multiplies again, and the structure cannot be argued with.
Coordination overhead. When agents share state by broadcasting to each other, the cost is not linear. A naive broadcast across n agents over S steps with artifact size |D| scales as O(n × S × |D|) — a triply-multiplicative overhead that turns “let them all see everything” into a token bill that grows faster than the work being done (Token Coherence paper). Practical fixes use lazy invalidation and structured summaries instead of raw history, but those are themselves implicit choices about what to drop, and dropping the wrong thing causes the next failure.
Conflicting implicit decisions. This is Cognition’s argument and the one easiest to underestimate. In their Don’t Build Multi-Agents post, Walden Yan walks through a Flappy Bird build split across two parallel sub-agents: one writes a Mario-style background, the other writes a non-game-like bird, and the pieces do not fit. Neither agent was wrong in isolation. Each made implicit decisions about style, physics, and tone that the other never saw, because the system shared messages rather than full traces (Cognition Blog). Their two principles — share full context including complete agent traces, and recognise that every action carries implicit decisions — are less a philosophy than a debugging diary.
Anthropic’s How we built our multi-agent research system is the strongest counter-example, and reading it carefully is what makes the trade-off legible. On their internal research evaluation, an orchestrator-worker built from a Claude Opus 4 lead and Claude Sonnet 4 sub-agents in parallel scored about ninety percent above single-agent Opus 4. The same post reports that token usage explains roughly four-fifths of the performance variance, and the system uses on the order of fifteen times more tokens than a normal chat turn (Anthropic multi-agent post). Quality went up; efficiency went down by a factor that only makes sense for high-value research tasks where the answer matters more than the bill.
Why Anthropic and Cognition Are Both Right
Hold the two pictures side by side. Cognition argues against multi-agent systems; Anthropic published one and reports a roughly ninety-percent gain on their internal eval. Both are honest. Both are correct, on different problems.
Cognition’s case applies to parallel sub-agents that do not share traces — the Flappy Bird pattern, where the orchestrator hands out subtasks and stitches the results together without giving each worker visibility into the others’ decisions. Under that geometry, conflicting implicit decisions are inevitable, and parallelism amplifies them.
Anthropic’s case applies to a research orchestrator that aggressively shares context through the lead agent and pays for the parallelism in tokens. Their roughly fifteen-times-tokens framing is the price of beating the single-agent baseline on hard, breadth-first research.
If you are choosing a pattern, four if/then predictions follow from the four physics:
- If your task fans out into independent sub-questions, expect parallel sub-agents to win on quality and lose on cost.
- If your sub-tasks have implicit dependencies that are not encoded in the prompt, expect a Supervisor Agent Pattern (orchestrator-workers) with shared traces to outperform a Swarm Architecture of peer handoffs.
- If your reliability target requires more than ninety-five percent end-to-end and your chain has more than four hops, expect to need either fewer hops or a verifier — error compounding is not negotiable.
- If you reach for Agent Debate or group-chat patterns, expect coordination overhead to scale super-linearly; budget for summarisation, not raw history.
Rule of thumb: start with the augmented single-agent loop, add a workflow when the path is predictable, and only escalate to multi-agent when the task genuinely fans out and the value justifies the token bill.
When it breaks: the dominant production failure mode is silent context divergence — sub-agents make conflicting implicit decisions because they share filtered messages instead of full traces, and the lead agent stitches the inconsistencies into a confident, broken answer.
Security & compatibility notes:
- LangChain / LangGraph (CVE-2025-68664, “LangGrinch”): Serialization injection patched in LangChain Core 1.2.5 and 0.3.81. Affects every LangGraph multi-agent stack; the patch changed
load()/loads()defaults — review your deserialization paths before upgrading.- AutoGen and Semantic Kernel: In maintenance mode as of Microsoft Agent Framework 1.0 GA (April 2026). Bug fixes and security patches only — new code should target Microsoft Agent Framework. AG2 is the community fork of AutoGen and remains active but is not the main line.
- OpenAI Swarm (2024 prototype): Deprecated and replaced by the OpenAI Agents SDK launched March 2025. Tutorials older than mid-2025 reference the dead repo; “swarm” survives as a pattern name in
langgraph-swarm-pyand as a generic term for peer-to-peer handoff.
What the Stack Looks Like in 2026
The frameworks have collapsed into a small number of recurring patterns, and the names matter less than the geometry. Agent Orchestration today usually means picking among four shapes: supervisor (one orchestrator, many workers), swarm (peer handoffs via tools, no central manager), debate or group-chat (multiple agents critiquing the same prompt), and sequential or concurrent pipelines.
The reference implementations break down cleanly. LangGraph 0.4.x exposes graphs-with-cycles plus persistent state and provides both langgraph-supervisor (with handoff tools and an optional forwarder that skips rewriting subagent output to save tokens) and langgraph-swarm-py (peer-to-peer handoff, where a state checkpoint remembers the last active agent so the next message resumes there) (LangGraph Supervisor Docs; LangGraph Swarm Docs).
CrewAI 0.80+ exposes role-based crews and a hierarchical mode that requires a manager_llm and routes unassigned tasks centrally (CrewAI Hierarchical Docs). The OpenAI Agents SDK, launched March 2025 as the production-ready successor to Swarm, exposes Agents, Handoffs, Guardrails, Sessions, and Tracing as primitives (OpenAI Agents SDK Docs). Microsoft Agent Framework 1.0 — GA April 3, 2026, replacing AutoGen and Semantic Kernel — exposes Sequential, Concurrent, Handoffs, Group Chat, and the Magentic-One orchestrator as built-in patterns and supports the A2A protocol natively (Microsoft Agent Framework v1.0).
Google ADK, released April 2025, builds the same primitives around the Agent-to-Agent protocol with four language SDKs.
Claude Agent SDK was released alongside Claude 4.6 and is Claude-only.
MultiAgentBench’s empirical finding is the one to keep in mind when choosing a topology: across star, chain, tree, and graph protocols, the graph topology wins among coordination protocols, and explicit cognitive planning lifts milestone achievement by a few percentage points (MultiAgentBench paper). The headline is not which framework, but which shape — and graphs with shared state beat hierarchies with filtered messages on the same task.
The Data Says
Multi-agent systems are not a new paradigm; they are a stack on top of tool use, the single-agent loop, and external memory, and they inherit every limitation of those layers while adding four of their own. Cognition is right about parallel sub-agents that do not share traces; Anthropic is right about orchestrators that share context aggressively and pay in tokens — both observations describe the same physics from different sides. Build the augmented single-agent first. Reach for orchestration only when the task genuinely fans out, the per-step reliability supports the chain length, and the value of the answer justifies a token budget that is materially larger than the chat baseline.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors