Prerequisites for LLM-as-a-Judge: Eval Metrics, Rubrics, and Human Baselines
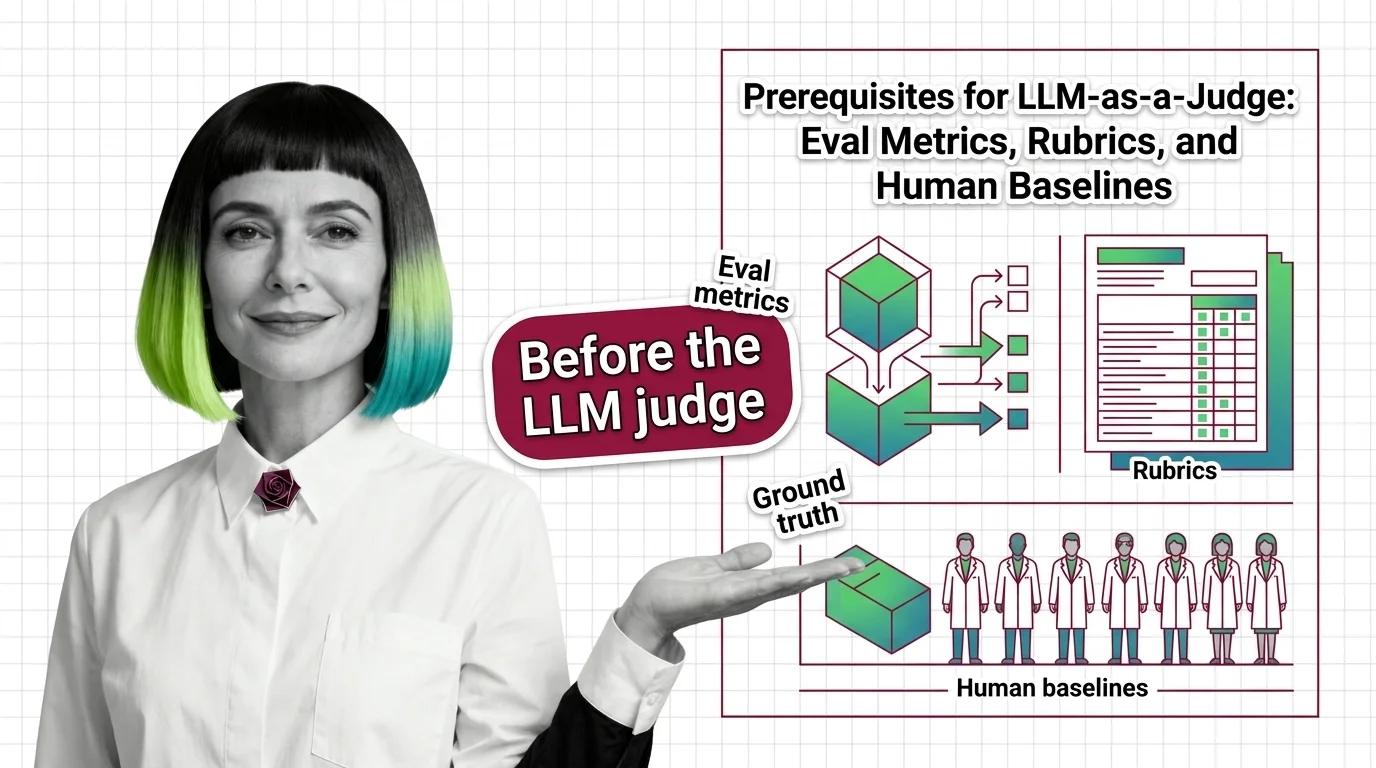
Table of Contents
ELI5
An LLM-as-a-judge uses one language model to grade another’s output. Before that grade means anything, you need four things: a written rubric, ground-truth examples, a measure of how often humans agree, and a human baseline to check the judge against.
Point a language model at two chatbot answers and ask which is better. It will tell you instantly, fluently, with a confidence that feels earned. The number it hands back looks like a measurement. Usually it is closer to a very articulate opinion, and the gap between those two things is the entire subject of this article.
Why a Judge Needs Something to Judge Against
A judge model converts text into a verdict: a score, a label, a winner. But a verdict carries information only when it can be checked against a reference, the same way a thermometer reading is meaningless until you know it agrees with a known temperature. Everything you build before turning the judge loose exists to create that reference.
What do you need to understand before building an LLM-as-a-judge evaluation?
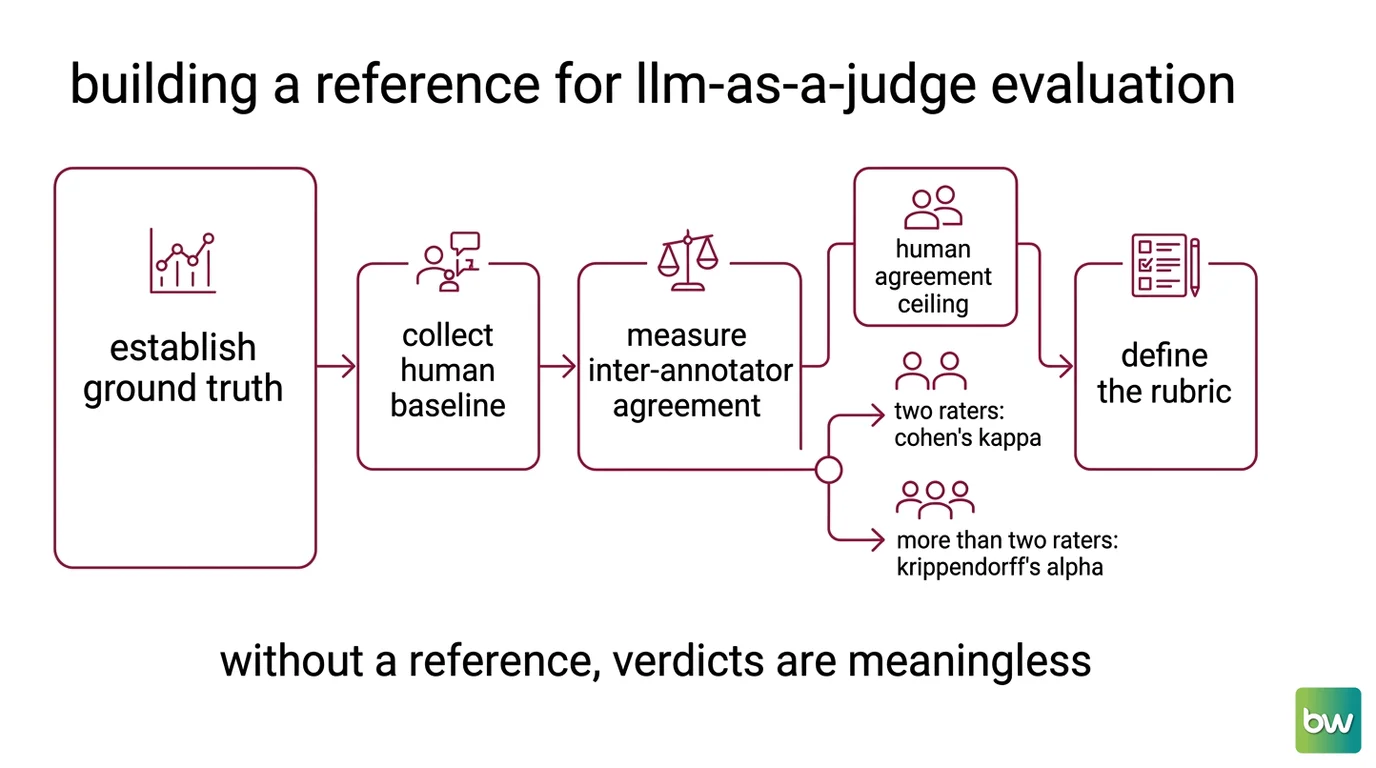
Start with ground truth. For any item you ask the judge to score, you need at least some items where you already know the correct answer or the preferred response. Ground Truth is the fixed point the whole evaluation pivots on; without it, you have no way to separate a judge that is wrong from a model that is wrong.
Next, the human baseline. A LLM-as-a-Judge is a stand-in for human evaluation, and a stand-in is only credible once you have measured what it replaces. That means collecting human judgments on a sample, then asking whether the model’s verdicts actually track them. Skip this and you are trusting the substitute without ever meeting the original.
Then the uncomfortable part: humans disagree. Two qualified annotators reading the same instructions will still split on borderline cases. Inter Annotator Agreement measures how much of their agreement is real signal and how much is luck. Cohen’s kappa, the standard for two raters since 1960, corrects raw agreement for the rate you would expect by chance. For more than two raters, or for partial labels, Krippendorff’s alpha is the correct tool instead; the two are not interchangeable, and reaching for kappa where alpha belongs is a common quiet error. This number is your ceiling. A judge cannot meaningfully be more correct than the humans it imitates are consistent with each other.
Finally, the rubric. “Better” is not measurable; “more factually accurate, with fewer unsupported claims” is. A rubric turns a vague quality into named criteria that the judge, and your humans, can apply the same way twice. A judge with no rubric and no human baseline still returns a clean score. That score simply is not evidence of anything. Not a measurement. An opinion with a number attached.
Get these four in place and you have a reference. What you do not yet have is a way to turn the judge’s raw verdicts into a number you can compare across models, and that is where the metrics come in.
What the Judge Computes, and What It Quietly Gets Wrong
Once the reference exists, the judge’s output has to become a metric: a single comparable quantity. How you compute it depends on what you asked the judge to do, and every method carries a failure mode baked into the model’s own behavior.
What evaluation metrics and ground-truth concepts should you know before using an LLM judge?
Three families of metric cover most cases.
When the judge assigns a pass/fail or a category, you score it like any classifier against your ground-truth labels, using Precision, Recall, and F1 Score. Agreement with human labels, reported as a raw percentage or as kappa, tells you whether the judge is tracking the humans at all.
When the judge picks a winner between two outputs, you aggregate many pairwise verdicts into a ranking. ELO Rating, borrowed from chess, and the Bradley Terry Model it approximates both convert win/loss records into a single skill number. This is how Chatbot Arena, now LMArena, ranks models: blind pairwise human votes, more than 6.8 million of them across 360+ models as of mid-2026, per LMArena. Because the board updates with every vote, any single Elo figure is a dated snapshot, not a fixed property of the model.
How good are these judges? In the 2023 study that introduced the method, a GPT-4 judge agreed with human preferences more than 80% of the time on MT-Bench, about the rate at which the human experts agreed with each other, according to Zheng et al. Read that number carefully: it is not a constant. It shifts with the task, the rubric, and which model is doing the judging.
Then the biases. The same study named three that show up reliably. Position bias: the judge favors whichever answer it sees first. Verbosity bias: it rewards longer answers even when length adds nothing. Self-enhancement bias: a judge tends to prefer outputs from its own model family. None of these are random noise. They are systematic, which means they survive averaging and quietly tilt your leaderboard in a fixed direction.
Ground truth has its own failure mode: contamination. A benchmark is only a reference if the model has not already seen the answers. SWE Bench, which scores models on resolving real GitHub issues inside reproducible Docker environments per the SWE-bench docs, became a cautionary case here. Benchmark Contamination can turn a high score into a measure of memorization rather than capability. The same risk applies to the humans in your loop: Data Labeling And Annotation platforms produce clean ground truth only when the annotation process itself is controlled. Label Studio is the widely used open-source option, free in its community edition per Label Studio, but the tooling is only as trustworthy as the rubric you feed it.
Tooling caveats (as of 2026):
- SWE-bench Verified: OpenAI stopped reporting this variant after audits found a large share of tasks flawed and gold-patch solutions recoverable from task IDs, with studies showing roughly a third leakage. Prefer decontaminated or live variants such as SWE-bench Pro, SWE-bench-Live, or LiveCodeBench, per OpenAI’s own write-up.
- Label Studio SDK 2.0 (Aug 2025): Breaking changes. Code written for SDK 1 must import from
label_studio_sdk._legacy, or pinlabel-studio-sdk<2.0.0until you migrate, per Label Studio’s migration guide.
What the Setup Predicts About Your Eval
The reward for getting the prerequisites right is that they let you predict where an unscaffolded eval will fail, before it fails in front of users.
- If you skip the human baseline, you cannot tell a judge error from a model error; every regression becomes ambiguous.
- If your rubric is vague, annotator agreement drops and the judge’s variance rises to match. Your scores get noisier without anyone touching the models.
- If the judge evaluates outputs from its own family, expect inflated scores for those models specifically. The bias is systematic, not noise you can average away.
- If you swap the order of two answers and the verdict flips, you have measured position bias directly, and any win rate built on that judge inherits it.
Agreement on average also says nothing about Calibration. A judge can be right overall and still be most confident exactly where it errs, which is the worst place to be confident.
Rule of thumb: validate a judge against a small human-labeled sample on the exact task you care about before trusting it at scale; agreement does not transfer across tasks for free.
When it breaks: A judge’s agreement with humans is specific to the task and rubric it was checked on. Move it to a new task, a new domain, or a model family it was never validated against, and the agreement you measured can silently evaporate. Add contamination, and a high score may reflect memorized answers rather than the capability you meant to test.
The Judge Measures Your Rubric, Not Quality
Here is the part that unsettles people who build these systems. An LLM judge has no access to quality in the abstract. It has access to your rubric and its own training distribution, and it scores the conformance between an output and those two things. Write a sharp rubric and the judge becomes a fast, repeatable extension of your standards. Write a vague one and the judge fills the gaps with whatever its training biased it toward: fluency, length, surface confidence.
Not quality. Conformance. The judge is a mirror held up to the criteria you wrote, which is exactly why those criteria, not the model, deserve most of your attention.
The Data Says
A judge model is only as trustworthy as the reference you validate it against. The 2023 work that launched the field showed a strong judge can approach human expert agreement on a given benchmark, but that result lives or dies on the rubric, the task, and freedom from contamination. Build the ground truth, the rubric, and the human baseline first; the judge is the last component you add, not the first.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors