GraphRAG Prerequisites: Knowledge Graphs and Where Vector RAG Falls Short
Table of Contents
ELI5
GraphRAG retrieves information by traversing typed relationships in a Knowledge Graph instead of fetching the most semantically similar text chunks. It only works if you already understand the vector RAG pipeline that sits underneath it — and the entity extraction step that builds the graph in the first place.
A team migrates from vector RAG to a graph-based retriever because their bot keeps confidently misattributing a quote to the wrong person. They install Neo4j, run an entity-extraction prompt over the corpus, plug in Microsoft’s GraphRAG repo, and ask the same question. The answer is now sourced from three documents instead of one — and still attributes the quote incorrectly. The graph did not invent new information. It propagated the same upstream error through typed edges instead of dense vectors.
That is the part most introductions skip. Knowledge Graphs For RAG is not a replacement for the vector RAG stack underneath. It is a second layer that depends on the first one being competent — and on a third layer of language-model entity extraction whose failure modes nobody warns you about.
The Vector RAG Pipeline You Cannot Skip Past
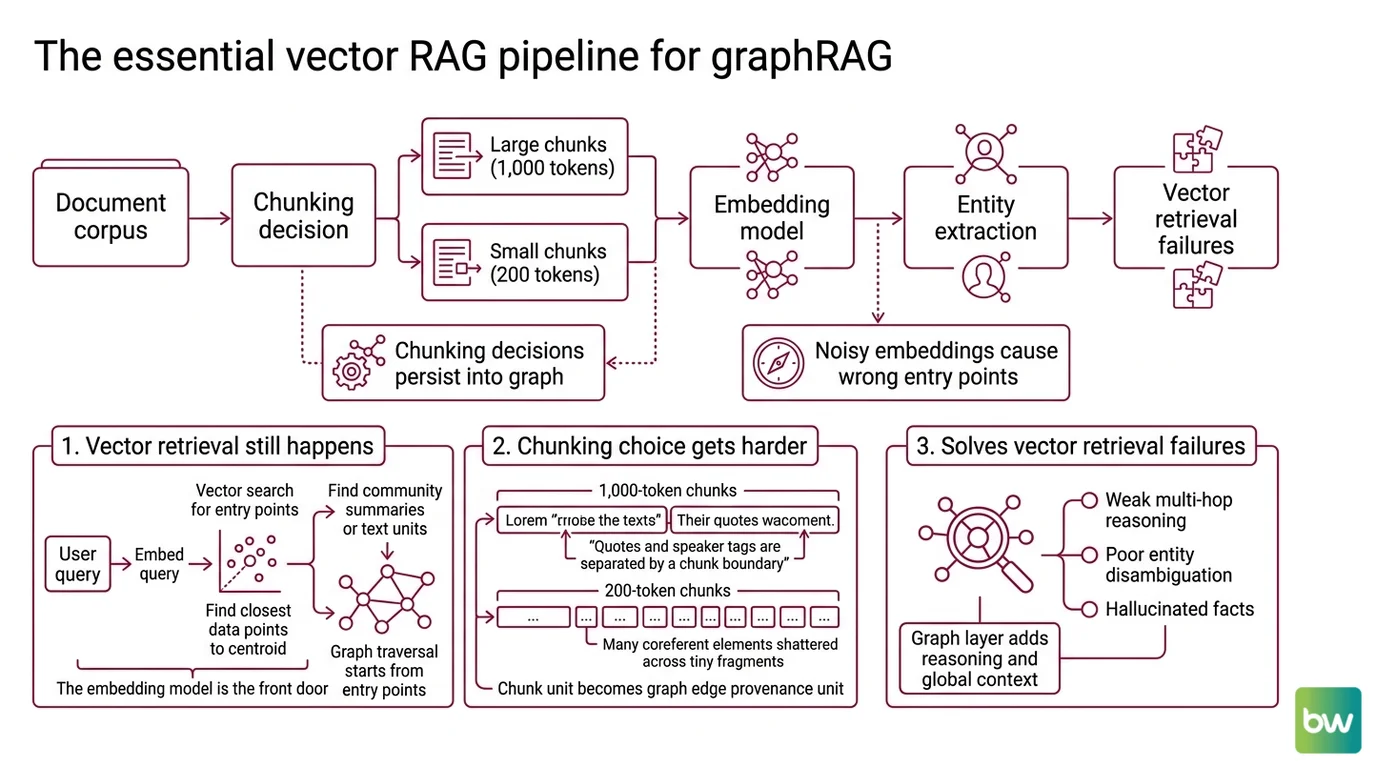
Before any node or edge exists, the document corpus has to be chopped into pieces, those pieces have to be embedded, and somebody has to decide which pieces become entities. Each of those decisions is inherited unchanged by the graph layer above. The recurring industry observation that “vector RAG falls short” is true; the trap is reading it as “skip vector RAG.” It is not a bypass. It is a list of design pressures that explain why a graph layer is being added on top.
Why do you need to understand vanilla RAG, chunking, and embeddings before adopting knowledge graphs for retrieval?
Three reasons, each a hard prerequisite.
The first is that vector retrieval still happens inside most production GraphRAG systems. In the Microsoft architecture, the retriever does not start from a node and walk outward — it starts from a query, embeds it, finds the nearest community summaries or text units, and then traverses the graph from those entry points (GraphRAG Docs). The Embedding model is the front door. If your embeddings are noisy, your graph traversal begins from the wrong room of the house.
The second is that chunking decisions persist into the graph. The unit on which you ran entity extraction becomes the provenance unit of every edge in the graph. Run extraction over 1,000-token chunks and a quote can be confidently linked to the wrong speaker, because the speaker tag and the quote ended up in different chunks and the resolver guessed. Run it over 200-token chunks and entity coreference shatters across hundreds of fragments that the language model then struggles to reconcile. The chunking choice is not a vector-RAG concern that gets retired by a graph; it is a graph-RAG concern that gets harder.
The third is the failure mode you came to fix. Vector retrieval pulls semantically similar chunks but lacks awareness of how facts connect — leading to weak multi-hop reasoning, poor entity disambiguation, and limited provenance, per the ScienceDirect 2026 survey on modern RAG architectures. Single-step vector retrieval often fails to capture implicit two-hop or higher-order information; iterative retrieval can drift from the reasoning path (StepChain GraphRAG, arXiv:2510.02827). Knowing this failure mode matters because it tells you what a graph is supposed to fix — and what it is not. It is not a recall booster on first-hop retrieval. It is a structural fix for follow-the-link queries.
There is a corollary worth naming explicitly: hybrid is the realistic default, not pure-graph. The “vector RAG falls short” claim is directional, not absolute. Most production systems that beat vector RAG on multi-hop benchmarks combine vector and graph retrieval rather than replacing one with the other (Neo4j Blog on multi-hop reasoning). If you treat the graph as an addition to the vector stack rather than a replacement, your design space expands; if you treat it as a swap, you tend to discover the chunking and embedding decisions you skipped only after the migration.
The reason this layer cannot be skipped: the graph inherits its building blocks from the vector pipeline that built it. A good chunker plus a noisy embedder plus a competent extractor still produces a graph whose edges trace back to bad neighbourhoods in latent space. Compounding zero is still zero.
From Text to Triples: The Graph You Actually Build
The second prerequisite is the part most tutorials show last and most production failures cluster around. A Knowledge Graph for retrieval is not handed to you with the corpus. It is constructed — by a language model, from your documents, under whatever prompt you wrote — and the construction step is where most of the quality is lost or won.
What do you need to know about knowledge graphs and Cypher before learning GraphRAG?
Three building blocks, in order: the data model, the extraction step that fills it, and the query language that reads it back.
The data model is the easy part to underestimate. A knowledge graph stores facts as typed relationships between entities — nodes for people, organisations, papers, products; edges for “authored”, “cites”, “works_at”, “supersedes”. The expressive jump over a vector index is that the relationship type carries meaning the embedding cannot. “Mona authored the explainer” and “Mona cited the explainer” produce nearly identical embeddings; the graph distinguishes them with two different edge labels. Two-hop queries — “who else authored work cited by people Mona cites?” — are tractable in the graph and approximately impossible against a flat vector index.
The construction step is the dangerous one. Knowledge-graph construction has shifted from rule-based and supervised named-entity-recognition pipelines toward prompt and in-context LLM extraction (REBEL, UniversalNER and similar systems), with the language model disambiguating entities from context rather than fixed rules (MDPI KG Construction Survey 2025). That sounds like progress, and on benchmarks it often is. The trade-off is that Entity Extraction becomes a stochastic process whose error distribution is correlated with the same biases as the generation model: rare entities are missed more often, common-name collisions resolve to the more famous referent, and edge types drift toward whatever the prompt suggested most strongly. The graph is no longer a curated artefact; it is a generated one.
Microsoft’s reference architecture in Microsoft GraphRAG formalises this construction pipeline as a three-stage process: an LLM-derived entity knowledge graph is built from text units, communities are detected over the graph using the Leiden algorithm, and pre-generated community summaries are stored and later combined with map-reduce query answering (GraphRAG Docs). It is a research demonstration, explicitly described as “not an officially supported Microsoft offering” on the Microsoft GraphRAG GitHub — useful as a reference implementation, not as an enterprise SLA. LightRAG, the EMNLP 2025 system from HKU’s Data Intelligence Lab (LightRAG GitHub), takes a lighter dual-level retrieval approach and is actively maintained, with v1.4.10 released in February 2026. LazyGraphRAG, a newer Microsoft Research variant, aims at lower indexing cost without quality loss (Microsoft Research Blog).
A piece of vocabulary the architecture introduces: Community Detection. Once the entity graph exists, an algorithm partitions it into densely connected clusters — communities — and a language model writes a summary of each. At query time the system can answer global questions (“what are the main themes across the corpus?”) by reading community summaries instead of retrieving individual chunks. This is the part that genuinely is not reducible to vector retrieval: it operates on graph topology, not on text similarity.
The query language is the third building block, and where the standards picture matters. Cypher Query Language is the de-facto language for traversing property graphs and is the practical prerequisite for working with Neo4j and most GraphRAG tooling. As of April 12, 2024, ISO/IEC 39075:2024 — the GQL standard — was published, the first new ISO database language since SQL in 1987, with Cypher as a major input (Neo4j Blog on Cypher and GQL). The openCypher project’s stated mission is to help implementors evolve toward GQL while keeping Cypher syntax available (openCypher). Treat Cypher as the practical prerequisite and GQL as the converging standard; in 2026 they are not interchangeable, and most production engines still implement Cypher with partial GQL alignment in progress.
A note on Neo4j versioning: as of April 2026, Neo4j 2026.04.0 is current, calendar-versioned since January 2025, with 5.26 LTS still supported (Neo4j Release Notes). Version strings like “5.x” now refer to the LTS line, not the latest release.
What the Stack Predicts About Your Build
The mechanism makes specific predictions you can test before you commit to a graph-based retriever.
- If your chunking strategy creates frequent coreference splits — pronouns separated from their antecedents, quotes separated from speakers — the resulting graph will encode those errors as edges. Fix chunking on the vector baseline first.
- If your embedding model under-represents your domain (legal jargon, biomedical terminology, internal product names), the entry points into the graph will land in the wrong neighbourhood. The graph cannot recover what the embedder lost.
- If your evaluation set does not include multi-hop questions, you will not measure the only thing the graph is supposed to improve. Single-hop benchmarks make GraphRAG look like an expensive vector index.
- If you treat GraphRAG as a swap rather than a hybrid, you give up the recall the vector index provides on first-hop questions in exchange for traversal you may rarely need. Hybrid retrieval is the empirically stronger default.
Rule of thumb: add a graph layer only after you have measured retrieval recall, multi-hop accuracy, and chunking-induced coreference errors on the non-graph baseline. The graph is a structural fix, not a recall fix.
When it breaks: the dominant failure mode is rarely a missing edge. It is a confidently extracted but wrong edge — a hallucinated relationship type, a mis-resolved entity, a quote attributed to the wrong speaker — propagated through community summaries until it appears in three different answers and reads as corroborated.
Not a missing fact. A wrong fact, retrieved with structural confidence.
Specific GraphRAG-vs-vector-RAG benchmark numbers vary widely by dataset; treat single accuracy figures as dataset-bound, not as a general claim.
Compatibility notes:
- Microsoft GraphRAG status: Open-source under microsoft/graphrag, but explicitly a research demonstration, not an officially supported Microsoft offering (Microsoft GraphRAG GitHub). Do not frame it as an enterprise product. Run
graphrag init --root [path] --forcebetween minor version bumps to refresh the config format (GraphRAG Docs).- Cypher vs GQL: ISO/IEC 39075:2024 (GQL) is published, but most production engines still implement Cypher with partial GQL alignment in progress. New content should mention GQL alongside Cypher rather than treating Cypher as terminal.
- Neo4j calendar versioning: Since January 2025, version strings like “5.x” refer to the LTS line, not the latest release. As of April 2026, the current series is 2026.04.0; 5.26 LTS is still supported (Neo4j Release Notes).
The Data Says
GraphRAG is a structural extension of the vector RAG pipeline, not a replacement for it — and the extension inherits every chunking, embedding, and extraction decision underneath. Build the vector baseline first; measure where multi-hop queries fail; only then add a graph and the entity-extraction step that constructs it. The math underneath the graph cannot fix what the embedder and chunker already lost.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors