Prerequisites for Code Execution Agents: From ReAct Loops to microVM Isolation
Table of Contents
ELI5
A code execution agent is an LLM that writes code, runs it, reads the output, and decides what to do next. Building one safely requires three layers: a reasoning loop, a sandbox runtime, and hardware-level isolation underneath.
There is a tempting one-paragraph version of this technology. The LLM writes Python, you call exec(), you feed the result back into the prompt, and you have built an agent. People build this. People are surprised when their agent learns to delete the parent directory.
What looks like a single capability — “the model can run code” — is actually a stack of three independent decisions made under three different sets of constraints. Skip any of them and the whole thing collapses in a way that is either embarrassing, expensive, or audit-relevant.
The Three Layers Underneath Every Code Execution Agent
Before naming the layers, it helps to be precise about what a Code Execution Agents system actually does. It does not “have code execution.” It alternates between two distinct modes — generating tokens that happen to be syntactically valid code, and observing the side effects of running those tokens through an interpreter. The agent is the glue between the two modes. Everything else — the SDK, the sandbox, the isolation primitive — is plumbing that makes the alternation safe and fast enough to be useful.
What do I need to know before building a code execution agent?
You need to know three things: the reasoning loop that decides when to call code, the runtime that executes it, and the isolation boundary that contains the blast radius. Each layer has a default that looks adequate in a notebook and turns out to be wrong in production. The reasoning-loop default is “let the model decide everything.” The runtime default is “spin up a Docker container.” The isolation default is “Docker is enough.” All three defaults fail under load, under attack, or under audit.
The interesting thing is that the failures stack. A poorly bounded reasoning loop will generate weirder code; weirder code is more likely to escape a weak sandbox; a weak sandbox shares the host kernel with everything else. The shape of the stack matters as much as any individual choice.
The reasoning loop: ReAct as the conceptual ancestor
The conceptual ancestor of every modern code-execution agent is ReAct, introduced by Yao and colleagues in October 2022 and published at ICLR 2023 (arXiv). ReAct interleaved reasoning traces with actions — “reason to act, act to reason” — and evaluated the pattern on HotpotQA, Fever, ALFWorld, and WebShop. On the harder action-heavy benchmarks the absolute success rate jumped by 34 percentage points on ALFWorld and 10 points on WebShop versus imitation and reinforcement-learning baselines (arXiv).
The mechanism is unremarkable in retrospect. The model emits a thought, then an action, then receives an observation, then emits the next thought. The prompt is the entire state machine. There is no separate planner — and that is the structural difference between ReAct and classical Workflow Orchestration For AI, where the graph of steps lives outside the model. Here the language model is the planner, the executor, and the critic, distinguished only by which token slot it is currently filling.
That is the conceptual ancestor. It is not the current implementation pattern. Modern systems — the Responses API, Claude’s code execution tool, agent SDKs — wrap tool-use protocols around the same loop but with structured boundaries between reasoning and action. ReAct, in the form Yao et al. described, predates these APIs and should be read as the architectural argument for why the loop exists, not as a runnable design today.
The runtime: sandbox SDKs as the convenience layer
Once you commit to the loop, you need somewhere to actually run the code. The market in May 2026 splits into two tiers.
The foundation-model providers ship code execution as a built-in tool. OpenAI’s Code Interpreter, available through the Responses API, runs Python in a sandboxed environment at $0.03 per session (OpenAI API Docs). Anthropic’s code execution tool exposes server-side Python, bash, and file operations, with a “Programmatic Tool Calling” mode where Claude writes a script that orchestrates other tools rather than calling them one at a time (Claude API Docs). These are the path of least resistance. You get a working sandbox without thinking about the runtime.
The dedicated providers ship sandboxes as a primitive. E2B is the most established — its open-source SDK reached version 2.21.0 for Python and 2.20.0 for JavaScript in early May 2026 (E2B Docs). Daytona advertises sub-90 ms cold starts (with a best-case figure of 27 ms in vendor marketing — treat that as a ceiling, not a guarantee) and charges $0.0504 per vCPU-hour plus $0.0162 per GiB-hour, with $200 of free compute (Daytona). Modal sandboxes run at roughly 3× the standard Modal compute rate, with the multiplier reflecting the per-sandbox overhead rather than the underlying instance (Northflank Blog).
The choice between the two tiers reduces to a question about control. The built-in tools are correct for agents that just need to run pandas. The dedicated providers are correct when you need GPU support, custom base images, persistent filesystems, or transparent control over how the sandbox is torn down.
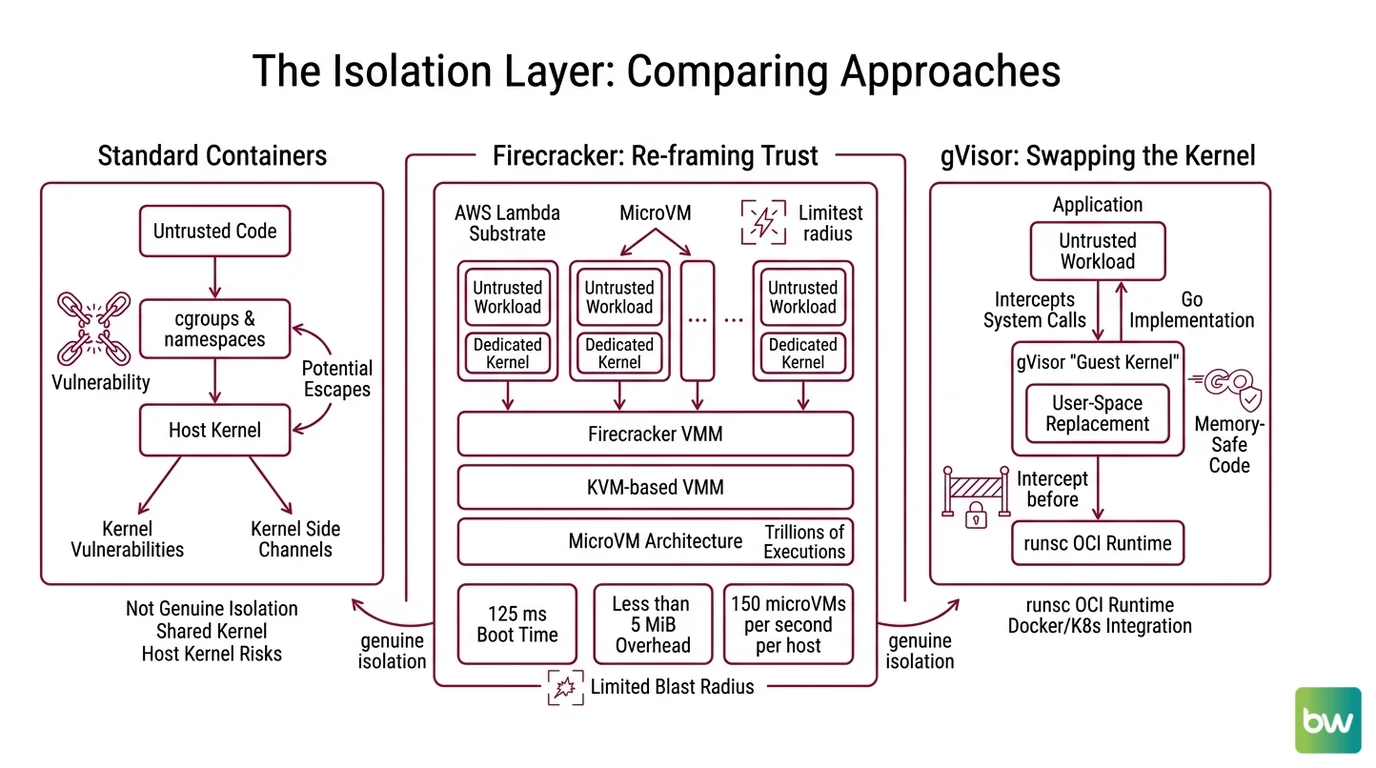
The Isolation Layer: Containers Are Not Enough
The interesting choices live underneath the sandbox SDK, at the layer where one piece of code is prevented from observing another. Vendors describe this in marketing as “isolation,” and the word covers radically different mechanisms.
A Linux container is a process — a normal one, viewed through the lens of cgroups and namespaces. It shares the host kernel. Kernel vulnerabilities, kernel-level side channels, and entire classes of escape are not theoretical: they are the operational history of multi-tenant container platforms.
Not isolation. Bookkeeping.
Two technologies sit at the level genuinely worth calling isolation, and both have entered the agent stack within the last twelve months.
How Firecracker reframes the unit of trust
Firecracker is a virtual machine monitor — a KVM-based VMM — that AWS open-sourced as the substrate for Lambda and Fargate. The numbers are the design statement: roughly 125 ms to boot a microVM, less than 5 MiB of memory overhead per VM, and up to 150 microVMs launched per second per host (AWS Open Source Blog). The codebase powers what AWS describes as trillions of executions per month across Lambda and Fargate (Firecracker GitHub).
The architectural move is to give every untrusted workload its own kernel. The agent’s sandboxed process is not a tenant in a shared kernel — it is the only thing running in a tiny dedicated kernel that boots, executes, and dies inside the same second. The blast radius of an exploit shrinks from “host kernel” to “throwaway VM that no longer exists.”
How gVisor swaps the kernel for a user-space replacement
gVisor takes a different route. Instead of giving the workload a real kernel, it gives it a fake one — a user-space “guest kernel” written in Go that intercepts system calls and re-implements them in memory-safe code (gVisor Docs). It ships as runsc, an OCI runtime that slots into Docker and Kubernetes wherever a runtime is expected.
The implication for agents is the MAGI pattern — Multi-Agent gVisor Isolation — published April 15, 2026, which proposes one sandboxed container per agent so that one agent’s hallucinated rm -rf cannot reach another agent’s working directory (gVisor Blog). The pattern treats the agent loop as a unit of trust rather than the host as a unit of trust.
What the Stack Predicts
The structure of the stack is not academic. It maps directly onto observable failure modes and operational choices.
- If your agent’s reasoning loop has no budget on tool calls, expect the loop to either flatline on a single bug or burn through tokens on a recursion the model finds funny.
- If your runtime is a notebook server you stood up on a single VM, expect one agent’s misbehavior to take down every other agent’s session, because they all share the kernel and the filesystem.
- If your isolation layer is “we run it in Docker,” expect your security team to ask exactly one question — “do you trust the LLM’s output to never include a kernel exploit?” — and to be unimpressed by the answer.
The architectural rule of thumb that falls out of this is simple: the unit of isolation should be tighter than the unit of failure you can tolerate. If you can tolerate losing a single user’s session, isolate per session. If you cannot, isolate per call.
Rule of thumb: Use the foundation-model built-ins for prototypes, dedicated sandbox SDKs for production workloads, and never let untrusted LLM output touch a shared kernel.
When it breaks: The stack breaks at the seams between layers — when the reasoning loop assumes the runtime is stateful and it isn’t, when the runtime assumes the isolation layer can survive a malicious filesystem write and it can’t, or when a “sandbox” is actually just a container sharing the host kernel. Most production incidents in this space are seam failures, not single-component failures.
Security & compatibility notes:
- vm2 sandbox-escape CVEs: Multiple critical vulnerabilities in the vm2 Node.js sandbox — CVE-2026-43999 (CVSS 9.9), CVE-2026-43997 (CVSS 10.0), and CVE-2026-26332 (CVSS 9.8) — allow sandboxed code to escape to the host. Patches landed in the 3.11.x series. Do not use vm2 to sandbox AI-generated JavaScript.
- OpenAI Assistants API shutdown: The Assistants API beta —
/v1/assistants,/v1/threads, and related endpoints — reaches end-of-life on August 26, 2026. Migrate to the Responses API.- Containers are not a sandbox for untrusted code: Both gVisor’s April 2026 MAGI post and multiple 2026 vendor write-ups argue that vanilla containers are insufficient isolation for AI-generated code. Use a microVM (Firecracker) or user-space kernel (gVisor) layer underneath.
The Data Says
Code execution agents are not a feature. They are an integration of three independent systems — a reasoning loop, a runtime, and an isolation primitive — each of which has its own threat model and its own pricing curve. The teams that build safely are the ones that pick a deliberate choice at every layer rather than inheriting whatever default came with the first SDK they installed.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors