Resilient AI Agents: Failure Modes, Idempotency, Durable Execution
Table of Contents
ELI5
Resilient agents survive three uncomfortable facts: they fail in predictable, classifiable ways; retries will duplicate side effects unless you design against it; and crashes erase progress unless something outside the agent remembers.
An Agent Error Handling And Recovery system completes seventeen tool calls, then crashes on the eighteenth — a transient network blip. The orchestrator retries from step one. Two refunds get issued. One database row appears twice. The support ticket arrives before the bug report.
Not a prompt problem. An architecture problem.
Why agents fail differently than functions
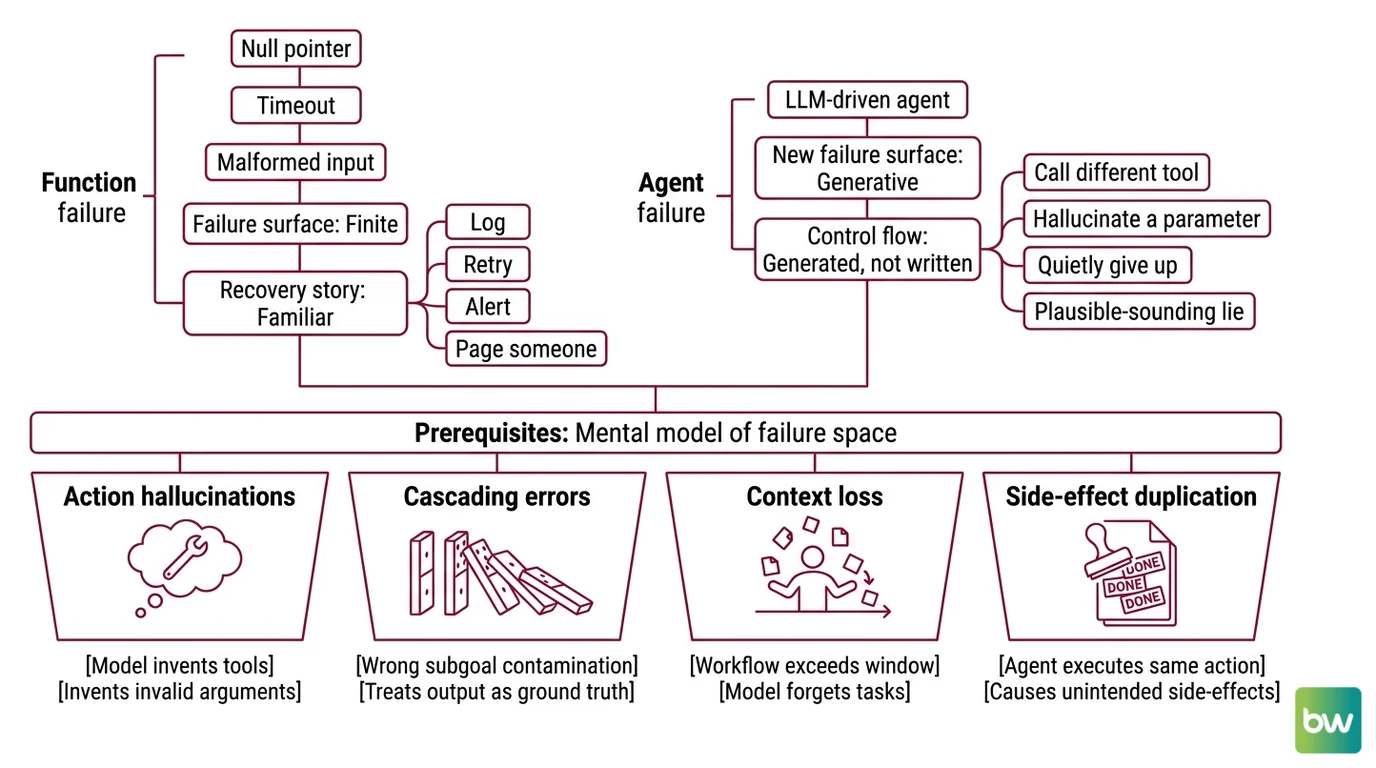
A traditional function fails for traditional reasons: a null pointer, a timeout, a malformed input. The failure surface is finite and the recovery story is familiar — log, retry, alert, page someone. An LLM-driven agent adds an entirely new failure surface on top of that, because its control flow is generated, not written. The agent doesn’t merely call a tool when it fails; it can decide to call a different tool, hallucinate a parameter, or quietly give up and produce a plausible-sounding lie.
The first prerequisite for resilience is naming what can go wrong.
What do you need to understand before designing agent error handling?
Before you write a single try/except block, you need a working mental model of the failure space. Recent surveys converge on a similar shape, even if the exact category names differ. A Microsoft whitepaper sorted agent failure modes into novel safety risks — memory poisoning, multi-agent jailbreaks — versus extensions of classical security issues (Microsoft Security Blog, April 2025). A later survey of hallucinations across the agent pipeline added planning errors, action errors, memory errors, and reflection errors to the classical “wrong fact” definition (arXiv Survey of Hallucinations in LLM-Based Agents). Different frameworks, same underlying observation: failure is no longer a single point.
For practical design work, the failure modes the agent will produce fall into four buckets:
- Action hallucinations — the model invents a tool that does not exist, or invents arguments that the tool will reject.
- Cascading errors — one wrong subgoal contaminates every downstream step, because the agent treats its own previous output as ground truth.
- Context loss — long-running workflows exceed the Agent Observability window, and the model forgets what it was supposed to do.
- Side-effect duplication — the agent (or its retry loop) executes the same external action more than once, because nothing in the system remembers it already ran.
The first three buckets are what Agent Evaluation And Testing suites probe. The fourth is what idempotency exists to solve. Each requires a different layer of the stack to respond — which is why “just add try/except” is the wrong shape of answer.
The mechanism that matters here is observability of intent. You need to know not only that an action failed, but which step in the agent’s plan failed, what state the world was in when it did, and whether the action partially succeeded before the failure. That requirement reshapes everything downstream.
The idempotency boundary
Idempotency is an old word from distributed systems. Its definition is unromantic: an operation is idempotent if performing it twice produces the same final state as performing it once. The canonical pattern made it concrete for HTTP APIs — the client generates a high-entropy random key (typically a V4 UUID) and sends it in an Idempotency-Key header on every mutating request (Stripe Docs). The server caches the response keyed by that string and returns the cached result on retry, provided the request body matches the original.
Keys are retained for at least 24 hours, and the server errors when a retry arrives with the same key but different parameters — a safeguard against silent state divergence (Stripe Engineering Blog).
So far, nothing about AI. The pattern predates LLMs by a decade. The reason it matters for agents is structural: it draws a line.
On one side of the line: the LLM — nondeterministic, probabilistic, capable of choosing a different action on every retry. On the other side: the executor — deterministic code that performs the side effect, deduplicates by key, and returns a consistent answer no matter how many times it’s called. Most agent idempotency problems dissolve at the moment you stop asking the LLM to manage state and instead ask deterministic code to mediate every action with side effects (Inngest Blog).
This is the part that most “agent in a loop” tutorials miss.
The idempotency key must not be generated by the LLM. If the model chooses the key, a retry that re-invokes the model produces a fresh key, the dedup cache misses, and the side effect fires twice. The key must come from the workflow context — a stable identifier tied to the step in the plan, not to the inference pass that produced the call. Once that boundary is drawn, the LLM is allowed to be probabilistic without poisoning the system around it.
There’s an uncomfortable consequence. Idempotency keys protect against duplicate side effects. They do not protect against the agent choosing a different action on retry. If the LLM decides on attempt one to issue a refund and on attempt two to send an apology email, the deduplication layer cannot save you — both actions go through, because they’re keyed differently. The real safeguard is the deterministic-execution boundary itself, not the key.
Durable execution: when workflows remember themselves
The third prerequisite is the hardest to internalize, because it inverts the default assumption of stateless code. Most application code is written as if the process will not crash mid-execution. Durable execution is a programming model where the runtime assumes the process will crash and persists enough state at every step that the workflow can resume from exactly where it left off — even on a different machine, hours later (Temporal).
The pattern is no longer experimental. The OpenAI Agents SDK + Temporal Python integration went generally available on March 23, 2026, packaging durable orchestration directly into the SDK that defines most production agent workflows (Temporal Blog). LangGraph ships its own checkpointing layer — MemorySaver, PostgresSaver, AsyncPostgresSaver — that snapshots graph state at every superstep and lets a graph resume after failure (LangChain Docs, as of LangGraph 1.x, May 2026). AWS added a “redrive” feature to Step Functions that restarts a failed execution from the failed state instead of from the beginning (AWS Blog).
The convergence matters. Three independent ecosystems — Temporal (workflow-first), LangGraph (graph-first), Step Functions (state-machine-first) — arrived at the same architectural claim: an agent that cannot persist its own progress is not production-ready.
Security & compatibility notes (LangGraph ecosystem, May 2026):
- LangGraph SQLite checkpointer & langgraph-checkpoint: SQL injection (CVE-2025-67644) and related flaws in earlier releases. Fix: upgrade
langgraph-checkpointto 4.0.0+; avoid the SQLite checkpointer for untrusted input.- LangGraph path traversal (CVE-2026-34070, CVSS 7.5): Exploitable via prompt templates. Fix: pin to a patched LangGraph 1.x release per current advisories.
- LangChain Core “LangGrinch” (CVE-2025-68664): Secrets exposure via serialization. Audit checkpoint storage for secrets before upgrading.
- langgraph-prebuilt 1.0.2: Breaking change adding a required
runtimeparameter toToolNode.afunc; customafuncoverrides may break across the 1.0.1 → 1.0.2 boundary.
What are the technical limits of retry, fallback, and self-correction in AI agents?
The temptation, once durable execution is in place, is to retry everything. The retry literature has a counter-argument worth absorbing.
For transient failures — network blips, rate limits, brief downstream outages — the canonical pattern is exponential backoff with jitter: each attempt doubles the wait time, with a random component added to prevent synchronized retry storms across many clients. LangGraph exposes this as a per-node RetryPolicy; Step Functions exposes it as a per-task Retry configuration with errors-to-catch, max attempts, backoff rate, and max delay.
For non-transient failures, retry is the wrong answer. If a downstream service is consistently returning errors — not flaky, just broken — repeated retries make the outage worse. The circuit breaker pattern fails fast in this regime: after a threshold of consecutive failures, the breaker opens, calls short-circuit immediately, and a half-open probe checks recovery before resuming full traffic.
The agent-specific limit is subtler. “Exactly-once execution” in durable systems refers to workflow and activity state — the orchestrator guarantees each step’s side effects happen once, even across retries. It does not guarantee that the LLM call produces the same output. A retry of a step that invokes the model can return a different action, a different argument, a different plan. Durability protects the boundary between the model and the world. It does not freeze the model in time.
This is where self-correction loops have their hard ceiling. An agent that retries its own plan after a failure can converge on a working answer — but it can also amplify a wrong assumption across attempts, because each retry sees the previous failure as evidence and updates accordingly. Agent Guardrails and Human In The Loop For Agents controls exist for exactly this regime: when self-correction is structurally unable to produce a correct answer, the system needs to fail loud and escalate, not keep guessing.
What the resilience stack predicts
If you build with these three prerequisites in place, the article makes a few testable predictions about how your agent will behave.
- If a step that produces a side effect retries successfully, the deduplication log should show exactly one external call per logical step — not zero, not two.
- If the workflow crashes mid-execution and resumes, the activity timeline should show a gap and a resumption at the same step, not a full replay from the start.
- If a downstream service has a sustained outage, the breaker should open before the agent’s plan exhausts its retry budget, and the failure should surface as a workflow-level error with the failed step identified.
- If self-correction produces a cluster of structurally similar errors in a row, the system should treat the cluster as a non-transient signal and break out of the loop, not keep guessing.
Rule of thumb: if your retry strategy assumes the LLM will make the same decision twice, you don’t have a retry strategy — you have a coin flip with extra steps.
When it breaks: the most common failure mode for “resilient” agents in production is not the absence of retries, but the absence of an idempotency boundary inside the retries. Side effects fire multiple times, the dedup layer that would have caught it lives one layer too deep, and the agent appears to be working — right up until a customer notices the duplicate charge.
The Data Says
Three independent ecosystems — Temporal’s workflow model, LangGraph’s checkpointer graphs, and AWS Step Functions’ redrive feature — converged on the same architectural claim: agents that cannot persist their own state are not production-ready. Beneath that convergence sits a much older idea from API design: the line between a probabilistic decision and a deterministic action is the only line that makes resilience tractable.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors