Prerequisites for AI Documentation Generation: From AST Parsing to Repo-Scale Context Windows and Hallucination Limits
Table of Contents
ELI5
** AI Documentation Generation** rests on three prerequisites: a parser that turns code into structure, a retrieval layer that fits inside a finite context window, and an honest accounting of what the model will invent. Skip one, and you ship confident fiction.
A docstring claims your function returns a Result<T, E>. It actually returns Option<T>. The model did not lie; it pattern-matched against a million other functions whose names looked like yours. Below the surface of every AI documentation generator sits a stack of mechanisms — parsing, chunking, retrieval, sampling — that determine whether the output describes your code or a statistical impression of it. Understanding that stack is the difference between a tool you can trust on a Friday afternoon and one that fabricates its way through your changelog.
What Sits Between Your Repo and the Language Model
The reader’s intuition is that an AI doc generator “reads” the code. It does not. It tokenizes, parses, embeds, retrieves, and samples — five distinct stages where information is reshaped, and each stage has a failure mode. Before you wire a generator into your CI, the constraints in those stages decide what is possible.
What do you need to understand before using AI documentation generators?
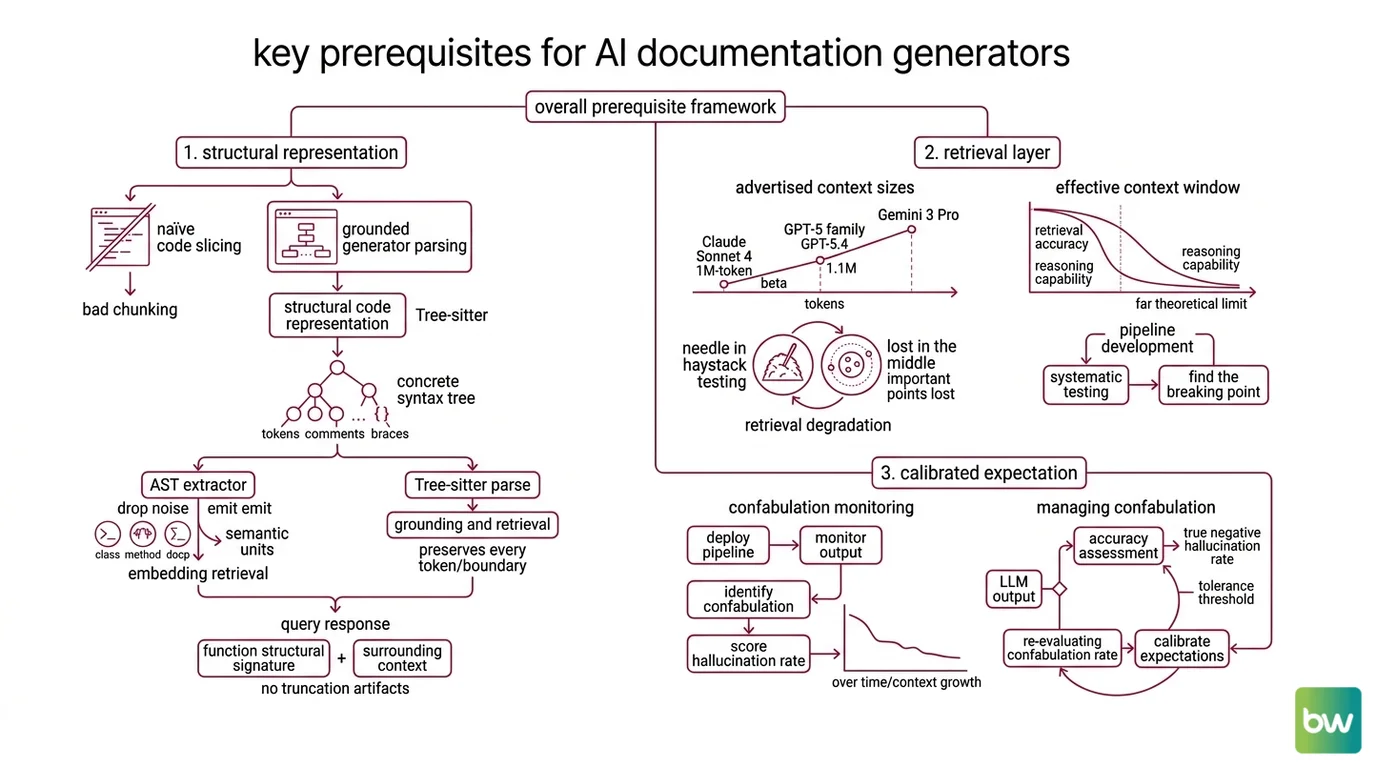
You need three things: a structural representation of your code that the model can chunk cleanly, a retrieval layer that fits inside the model’s effective context window, and a calibrated expectation of how often the model will confabulate.
The first is parsing. A naive doc generator slices source files by line count or character offset, which routinely cuts a function in half or staples a license header onto a class definition. A grounded generator parses first. Tree-sitter is the dominant choice here — an incremental parser that builds concrete syntax trees and re-parses on every keystroke at editor-grade speed, with battle-tested grammars across Go, Java, JavaScript, Kotlin, Python, Ruby, Rust, Swift, and a dozen more languages (Tree-sitter Docs). The output is a tree where every token, comment, and brace has a node — which means a downstream chunker can slice along the structure rather than across it.
But a syntax tree alone is not what the model sees. Most pipelines run the tree through an Abstract Syntax Tree extractor that drops formatting noise and emits semantic units: this is a class, this is a method, this is a docstring scope. The AST is what gets embedded for retrieval; the tree-sitter parse is what gets shown back to the model for grounding. The pairing matters — ASTs give clean semantic chunks for embeddings, while tree-sitter preserves every token and boundary for retrieval (Graphify). Combine them, and a query for “what does validate_payload do” can return both the function’s structural signature and the surrounding comments, imports, and call sites without truncation artifacts.
The second prerequisite is retrieval that fits the window. Advertised context sizes have ballooned: as of 2026, Claude Sonnet 4 ships a 1M-token beta window for tier-4 and custom-rate-limit orgs, the GPT-5 family crosses 1M tokens with GPT-5.4 (xhigh) reporting 1.1M, and Gemini 3 Pro advertises 2M tokens — roughly 1.5 million words (Claude5 Hub). On paper, you can pour an entire mid-sized repo into a single call. In practice, the effective window is much smaller, and treating advertised capacity as usable capacity is the most common failure I see.
The third prerequisite is a hallucination budget. Hallucination in code documentation is not random noise; it is structured invention. A USENIX Security 2025 study of sixteen models across 576,000 samples found roughly 19.7% of LLM-recommended packages do not exist. Open-source models hallucinate packages around 21.7% on average; proprietary models drop that to around 5.2% (Socket). You cannot prompt your way out of this; you can only design around it.
The Three Ceilings You Cannot Out-Prompt
Once parsing and retrieval are in place, three architectural ceilings remain. Each one is measurable, each one degrades the output in a different shape, and each one shows up in production within the first month.
What are the technical limitations of AI-generated documentation in 2026?
The first ceiling is the gap between advertised and effective context. Benchmark suites that test long-context behavior beyond simple lookup — RULER, NoLiMa, MRCR v2 — agree on a directional finding: frontier models reliably use only about 50–65% of their advertised window for multi-hop work, and models that claim 200K tokens often degrade sharply somewhere around the 130K mark (ofox.ai analysis). “Needle-in-a-haystack” tests, the once-canonical benchmark, have been superseded for serious evaluation, because they overstate real-world capability — they reward keyword overlap, not the latent associations a doc generator actually has to make (NoLiMa, Adobe Research).
The practical translation: if your generator dumps an entire 800K-token repo into a 1M-token call and asks “document the auth flow,” the model is statistically more likely to find the auth flow if it is in the first third of the context than the last third. Retrieval that selects the right 50K tokens beats brute-force loading the whole repo every time.
The second ceiling is the structure of code hallucinations themselves. The USENIX taxonomy breaks the fabrications into three rough groups: 38% conflations of two real packages mashed together, 13% typo variants of real names, and 51% pure fabrications. These are not random draws each call — 58% of hallucinated package names repeat across ten runs (Socket). The model has stable false beliefs. That is the dangerous part. A separate ACM Software Engineering analysis groups hallucinations differently — into Task Requirement Conflicts, Factual Knowledge Conflicts, and Project Context Conflicts — but the conclusion converges: documentation errors cluster around the same gaps for the same reasons, run after run.
The third ceiling is mitigation efficacy. Documentation Augmented Generation, where the model gets to read the real API reference before writing, improves low-frequency API performance by roughly 8.20%, and iterative retrieval-augmented approaches yield up to about 15% better exact-import match (ACM Software Engineering). These are real gains. They are also not the order-of-magnitude fix that marketing pages imply. Retrieval reduces hallucination; it does not abolish it.
What These Ceilings Predict in Practice
Treat the mechanisms as predictions, not trivia.
- If your generator loads files by line count instead of by AST node, expect docstrings to drift away from their functions over time, especially in files that get refactored frequently.
- If your generator relies on a 1M-token call rather than retrieval, expect coverage to be uneven — well-documented for code near the prompt boundary, vague or wrong for code deep in the middle.
- If your generator uses an open-source model without a curated allowlist of valid imports, expect roughly one in five package recommendations in generated examples to point at something that does not exist. The same fake names will tend to come back across runs.
- If your generator works well today on your hot paths and poorly on cold corners of the repo, retrieval is selecting well-trodden code and underweighting the rest. That asymmetry compounds: the rarely-visited modules stay rarely documented, which makes future retrieval even worse.
Rule of thumb: Parse before you prompt, retrieve before you generate, and verify every imported symbol against a real index before you commit.
When it breaks: AI documentation generators fail hardest at the intersection of cold code and long context — the parts of the repo that the model has never seen patterns for, embedded inside a payload where retrieval cannot prioritize them. There, the model produces docs that read fluently and describe a function that does not exist.
Documentation generation also touches every adjacent practice. AI Code Completion shares the same parsing stack and inherits the same hallucination shape. AI Code Review reads generated docs as ground truth, which laundered errors will propagate. AI Test Generation uses docstrings to seed test cases, which means a fabricated return type becomes a fabricated assertion. AI-Assisted Debugging and AI-Assisted Refactoring both lean on the same retrieved context, so any miscalibration above this layer leaks downstream.
Security & compatibility notes:
- tree-sitter 0.26.x: Deprecates ABI 13 and the
--buildflag ingenerate. Plugin authors and downstream toolchains should pin or update grammars before upgrading.- tree-sitter-ruby: CVE-2025-5889 and CVE-2025-59343 (moderate access-control issues) fixed in 0.23.1-2.1. Upgrade if you parse Ruby.
- Tool naming: CodiumAI is now Qodo. Articles or scripts referencing “CodiumAI” as a current product name are stale.
Why the Same Hallucination Keeps Coming Back
The repeatability finding is the most uncomfortable part of the picture. If hallucinations were uniformly random, you could average them out across runs and call the result a confidence signal. But when the majority of fabricated package names recur across repeated runs (Socket), averaging does nothing — the model has a stable bias in latent space, and every call falls into the same gravity well.
Not a glitch. An emergent property of the training distribution.
That stability is what makes “slopsquatting” — squatting on the package names AI tools repeatedly invent — viable as an attack class. The model is not rolling dice on each call; it is consistently retrieving the same wrong neighbor in embedding space. For a documentation generator, this means a single bad recommendation embedded in a code sample can be reproduced across hundreds of repos before anyone notices. Studies have shown that a significant share of AI-generated code contains exploitable security issues; the documentation layer is one of the cleanest delivery vectors for that risk.
The mitigation is not “ask the model to be careful.” The mitigation is to never let an unverified import survive into committed output. Doc generators that ship to production today — Mintlify, Swimm, DocuWriter.ai, Qodo (formerly CodiumAI) — differ less in how they prompt and more in how they verify (Mintlify Docs).
The Data Says
AI documentation generators are useful in direct proportion to how seriously you treat their three prerequisites: AST-aware parsing, retrieval-bounded context, and a calibrated hallucination budget. Open-source models invent imports at roughly four times the rate of proprietary ones, the same fabrications repeat across runs, and effective context tops out well below the advertised number. None of that disqualifies the tools — it determines where they belong in your stack.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors