Prerequisites for AI Code Review: RAG, Static Analysis, and the Hard Limits of LLM Bug Detection
Table of Contents
ELI5
AI code review is three systems pretending to be one: a retrieval layer that finds relevant code, a static analyzer that lists candidate bugs, and a language model that decides which findings to surface.
A junior reviewer opens a pull request, reads three files out of context, and announces with full confidence that the function is safe. That is what most AI code reviewers were before 2024 — a context-starved model guessing at a diff. The interesting part of AI Code Review in 2026 is not the model. It is everything stacked underneath it.
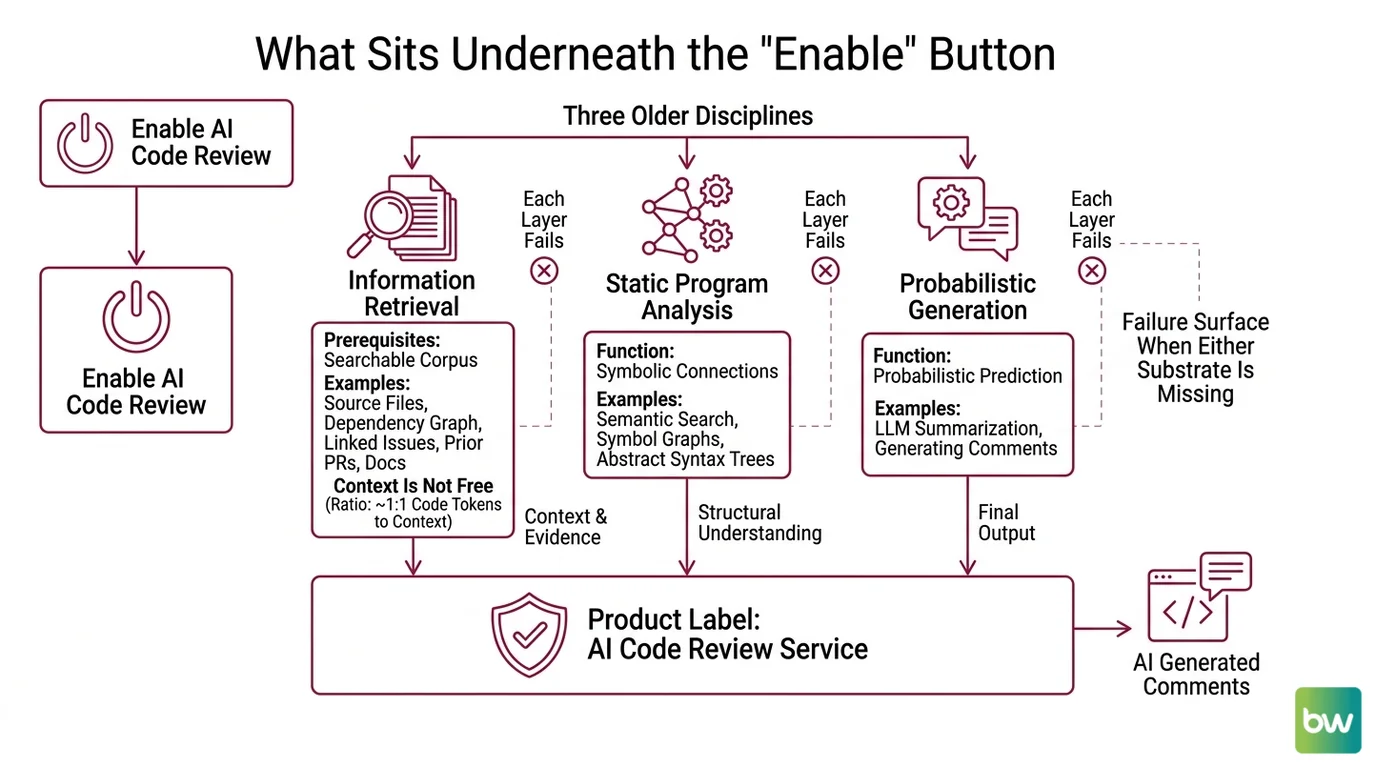
What Sits Underneath the “Enable” Button
You install a GitHub app, you tick a box, and the comments start appearing on pull requests. The illusion is that AI code review is a service. The reality is that it is an assembly of three older disciplines — information retrieval, static program analysis, and probabilistic generation — wearing one product label. Each layer fails in its own way. Each one has prerequisites that predate the model entirely.
The interesting articles about AI Code Completion talk about the language model. The interesting articles about code review talk about what the model is allowed to see and what it is told to ignore.
What do you need to understand before using AI code review tools?
Three substrates: retrieval, static analysis, and the model’s failure surface when either substrate is missing.
The first is retrieval. The seminal RAG paper from Lewis et al. introduced the architecture that underlies almost every grounded LLM system today — a parametric component (the language model) paired with a non-parametric component (a searchable corpus) so generation can be conditioned on retrieved evidence rather than memorized weights (the RAG paper). For code review, the corpus is your repository: source files, dependency graph, linked issues, prior pull requests, and sometimes the docs of every library you import.
This is the prerequisite the marketing pages skip. A model with a 200K context window is still operating blind on a four-million-line monorepo. The review only becomes useful when retrieval surfaces the right neighborhood of code — the callers of the changed function, the related test, the issue that motivated the diff. CodeRabbit publishes its target as a roughly one-to-one ratio of code tokens to context tokens — for every line of diff, an equivalent amount of grounding from the repo and its linked artifacts (CodeRabbit Blog). That is the number to internalize: context is not free, and most of the cost of a useful review is paid in retrieval.
The second substrate is static analysis. Decades older than any language model, SAST tools parse code, build control- and data-flow graphs, and pattern-match against rules. Semgrep matches at the AST level with rules written in syntax close to the target language; its Pro Engine adds cross-file and cross-function taint propagation, and the median CI scan completes in roughly ten seconds (Semgrep Docs). SonarQube tracks four orthogonal dimensions — reliability, security, maintainability, and test coverage — and still anchors most regulated-industry pipelines. The 2026 SAST landscape splits cleanly: legacy enterprise tools (SonarQube, Checkmarx, Veracode, Coverity, Fortify) run most compliance-bound programs, while a developer-first wave (Semgrep, Snyk Code, DeepSource, CodeQL, SonarQube Cloud) publishes per-developer pricing and runs cloud-first (Deepsource SAST roundup).
The third substrate is the model’s failure surface. Which is the part that needs a section of its own.
The Two Limit Walls: Hallucination and Coverage
A language model trained on most of public GitHub knows what plausible code looks like. That is the same thing as saying it knows how to produce convincing-but-wrong code.
The most-cited demonstration is the Stanford AI-assistant security study, in which participants using a Codex-based assistant produced significantly less secure code than the control group — and were simultaneously more confident their code was secure. The specific gap was sharp: thirty-six percent of participants with the assistant wrote SQL-injection-vulnerable solutions, versus seven percent without it (the Stanford AI-assistant security study). The study is about authoring, not review, but the asymmetry transfers. If an assistant inflates your confidence in code it suggested, it will inflate your confidence in code it inspected.
A second failure mode is harder to see because it lives in dependencies. A study across sixteen language models and 576,000 code samples found that nineteen-point-seven percent of recommended packages were fabricated — names the model invented that point to nothing on the registry. Worse, fifty-eight percent of those hallucinated names recur across queries, which means an attacker can register the fake name and wait for the next reviewer to suggest it (the package-hallucination study). Performance varied by model: GPT-4 Turbo hovered around four percent; CodeLlama 7B reached twenty-six percent. The mechanism is not malice. It is statistics: the model assigns high probability to package names that look like names in its training distribution, regardless of whether they exist.
What are the technical limitations of AI code review in 2026?
Four boundaries that recur across vendors:
- Hallucinated entities. Function names, package imports, API endpoints, configuration keys — anything with a sharp existence test will be hallucinated at a non-trivial rate. The fix is retrieval and external verification, not better prompting.
- Path-feasibility blindness. A model can read a function but rarely traces whether the dangerous line is actually reachable from any real call site. This is the gap LLM4PFA targets — its authors report filtering seventy-two to ninety-six percent of false positives from static-bug-detection candidates while missing only three of forty-five true positives (LLM4PFA paper). The productive split is unambiguous: static analysis enumerates suspects, the language model triages feasibility.
- Cross-repo invisibility. A change in one repository can break a contract in another, and pre-indexed vector RAG cannot follow the import. CodeRabbit’s response was to move past plain pre-indexed RAG and add a research agent that explores linked repositories in real time during the review (CodeRabbit Blog). Treat pure pre-indexed RAG as the foundation; agentic retrieval is what catches the multi-repo cases.
- Over-trust calibration. Vendor self-reports — Cursor’s claim that more than seventy percent of BugBot findings are resolved before merge across more than two million pull requests per month — measure developer behavior, not finding correctness (Cursor Docs). A flag is “resolved” when the developer clicks it away or rewrites the code. Whether the underlying bug was real is a separate question.
What the Model Catches and What It Cannot See
Stack the layers and the picture clarifies. Static analysis sees structure: it can prove a tainted input flows to a sink, but it cannot tell you whether that path is reachable in production. The language model sees plausibility: it can read the surrounding code, the issue tracker, and the changelog, and form a hypothesis about intent. Neither layer alone is sufficient.
The LLM4PFA result is worth dwelling on because it inverts the marketing narrative. The academic literature does not show language models replacing static analysis. It shows SAST proposes, LLM triages. The reduction in false positives is large; the loss in recall is minor. That is the productive division of labor — and it is the opposite of the framing most vendor pages choose.
This is what CodeRabbit and Cursor BugBot are doing under the hood, in slightly different shapes. CodeRabbit’s architecture targets context engineering: sandboxed repo clone, dependency graph rebuilt per review, indexed Jira and Linear issues for intent, historical pull requests for precedent, and real-time web queries for current docs (CodeRabbit Blog). Cursor BugBot runs eight parallel analysis passes per pull request with randomized diff ordering, then a majority-vote plus validator stage decides which findings reach the reviewer (Cursor Docs). One bets on retrieval breadth; the other bets on inference redundancy. Both accept the same prerequisite: the model alone is not enough.
A note on the names you may have read elsewhere. The original 2021 OpenAI Codex API was deprecated in 2023; describing today’s reviewers as “Codex-powered” in present tense is stale. Codeium itself rebranded to Windsurf and is now owned by Cognition. SonarQube’s AI feature, SonarSweep, was still in early access in 2026 and should not be treated as a mature, generally-available reviewer.
What This Predicts in Your CI Pipeline
The mechanism gives you predictions you can run against your own pipeline.
- If your reviewer comments on a small, in-context bug fix, expect signal. If it comments on a refactor that crosses repository boundaries, expect plausible-sounding noise unless the tool advertises agentic retrieval.
- If your reviewer suggests a new dependency, treat the import line as untrusted input. Verify the package exists, on the right registry, with a healthy publish history. The slopsquatting attack vector exists because hallucinated names cluster.
- If your reviewer agrees with you in a security-sensitive function, double-check. The Stanford effect — inflated confidence — applies in both directions.
- If your static analyzer fires a hundred warnings and the language model dismisses ninety, that is the LLM4PFA pattern working as designed. If the model dismisses all hundred, your prompt or your retrieval is broken.
Rule of thumb: treat AI code review as a triage layer on top of a static analyzer, not as a replacement for one.
When it breaks: the failure modes cluster around cross-repository contracts, fabricated dependency names, and security-sensitive code where the model’s confidence rises faster than its accuracy. None of these are fixed by a larger context window; they are fixed by retrieval design, registry verification, and a default-skeptical stance on agreement.
Compatibility notes (as of mid-2026):
- Plain vector-RAG for code review: Treat as legacy foundation, not as the destination. CodeRabbit has publicly moved to agentic exploration for cross-repo correctness; framing static RAG as the 2026 architecture is already stale.
- OpenAI Codex (2021 API): Deprecated since 2023. Do not describe current reviewers as “Codex-powered” in present tense.
- Codeium / Windsurf: Rebranded; owned by Cognition. References to “Codeium” as a company are stale.
- SonarSweep: Still early access in 2026; bolted onto legacy SonarQube architecture, not a mature standalone reviewer.
The Data Says
The architecture of an AI code reviewer in 2026 is the architecture of a retrieval system, a static analyzer, and a probabilistic triage step — in that order. The model is the last layer, not the first. Treat any vendor pitch that inverts the stack as a tell that the system will hallucinate confidently and miss what static analysis would have caught for free.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors