Prerequisites for AI-Assisted Refactoring: From AST Awareness to Test Coverage and Behavior Preservation
Table of Contents
ELI5
AI-assisted refactoring rewrites your code without changing what it does — in theory. In practice it only works if you give the tool four things: a behavior-preservation contract, structure awareness, automated tests, and guardrails against hallucinated APIs and context drift.
A developer asks an LLM to extract a helper method. The output compiles. The linter is silent. Three days later, an account-balance check returns the wrong value because the extracted method silently swapped the order of two arguments — and a test that would have caught it does not exist. The refactor preserved syntax. It did not preserve behavior. That gap is where AI-assisted refactoring lives or dies.
The Contract You Inherit From Martin Fowler
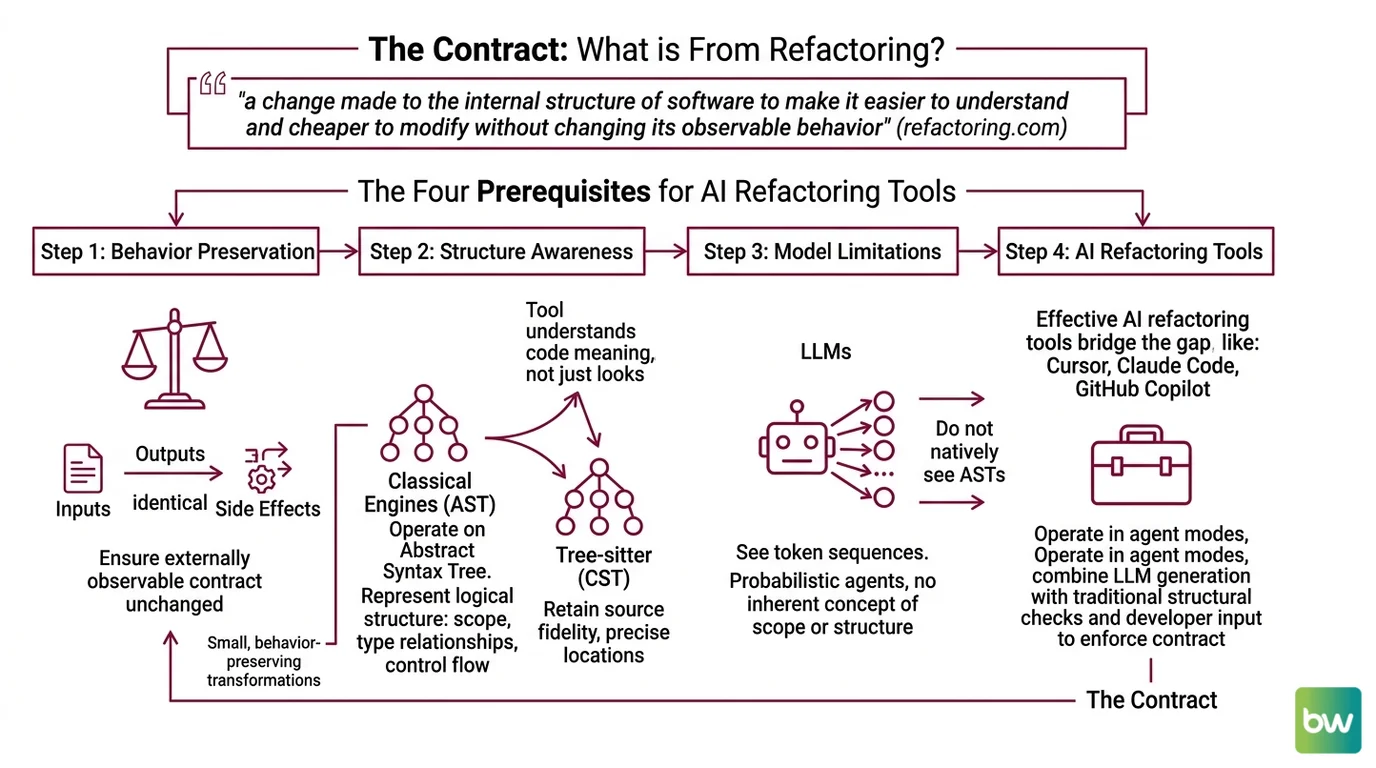
AI-Assisted Refactoring is not a new discipline. It is an old discipline operated by a probabilistic agent. The contract was written in 1999, refined in the 2018 second edition, and remains the canonical reference: refactoring is “a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior” (refactoring.com). Everything else in this article is downstream of that single sentence.
What do you need to know before using AI refactoring tools?
Four prerequisites, in roughly the order they tend to be skipped.
1. A working definition of behavior preservation. Fowler frames refactoring as “a series of small behavior-preserving transformations” — each one too small to break anything on its own (refactoring.com). The transformation may be syntactic (rename a variable) or structural (extract a class), but the externally observable contract — inputs, outputs, side effects — must be identical before and after. An LLM does not enforce this contract. You do, by deciding what counts as observable and writing tests that pin it down.
2. Structure awareness — what the tool actually sees. Classical refactoring engines like ReSharper, Roslyn, and Babel operate on the Abstract Syntax Tree. The AST strips formatting and whitespace and represents the logical structure: scope, type relationships, control flow (ScienceDirect topic page). Tree-sitter takes a related approach with concrete syntax trees that retain full source fidelity, including precise locations (Scannedinavian). Either way, the transformation respects what the code means, not just how it looks.
LLMs do not natively see ASTs. They see token sequences. A character-level model has no built-in concept of scope; it has statistical priors about what tokens usually follow what tokens. Effective AI refactoring tools — Cursor, Claude Code, and GitHub Copilot in agent mode, as of 2026 — close this gap by parsing the file, attaching the AST as context, and sometimes invoking static-analysis tools as sub-agents. If your tool does not do this, treat it as a glorified search-and-replace.
3. Automated tests as the verification layer. Fowler is explicit: a solid suite of automated tests is the prerequisite for refactoring, not a nice-to-have (Fowler’s refactoring book). The tests are the safety net. Without them, “behavior preservation” is a vibe.
This is the prerequisite most teams skip when they hand work to an LLM. The reasoning sounds rational — “the model will be careful” — but the model has no way to know what behavior matters. A test suite turns “preserve behavior” into a mechanical question: did all the green tests stay green? If yes, the refactor is safe to merge. If no, you have a bisect target. This is also why AI Test Generation sits next to refactoring in any honest workflow: refactoring without tests is gambling, and the model is happy to gamble on your behalf.
4. Explicit mitigation of LLM-specific failure modes. The first three prerequisites would have been sufficient in 1999. They are not sufficient now, because LLMs introduce three new failure modes that classical refactoring tools cannot produce: knowledge-conflicting hallucinations, context window degradation, and semantic drift. The next section dissects each one.
How AI Refactoring Breaks Code
Not a glitch. An emergent property of how LLMs process code.
These failures are not random bugs — they are predictable consequences of treating code as a token sequence and reasoning about it through attention over a finite context window. Understanding the mechanism is what separates “I’ll never trust AI for refactoring” from “I know exactly where to put the guardrails.”
Why does AI-assisted refactoring break code? Hallucinations, context limits, and semantic drift
Three mechanisms, three mitigations.
Knowledge-conflicting hallucinations. A hallucination in code generation is not just a made-up library — it is an invented API on a real library, or a misremembered method signature on a real class. Recent research distinguishes this category from “hallucinated objects” (entirely fictional symbols) and finds it the most damaging because the surrounding context looks plausible (arXiv 2601.19106). The same study reports deterministic AST analysis reaching 100% detection precision and a 77.0% auto-correction rate on this subset — meaning the fix exists, but only if the tool actually parses what it produced and cross-checks it against the language’s real symbol table. De-Hallucinator demonstrates a parallel path: iterative grounding through retrieved API references reduces hallucinations in code completion (arXiv 2401.01701).
The practical consequence is sharp. If your AI refactoring tool does not perform a static-analysis pass on its own output, you have to. This is also why AI Code Review cannot simply be another LLM pass — the review must include deterministic checks the generation step is structurally incapable of performing.
Context window degradation. The “lost-in-the-middle” effect describes a documented attention gap: relevant tokens placed in the middle of a long context are weighted less than tokens at the beginning or end. Combined with attention dilution and distractor interference, this causes accuracy drops of more than 30% when the critical information sits mid-window (Redis blog). The Redis analysis frames it as a 2025–2026 limitation that 200K+ token windows have not solved.
A refactor that touches three files and depends on a fourth file’s type definitions is a textbook setup for this failure. The model “knows” the type — the tokens are in context — but the relevant tokens are buried. The mitigation is structural, not statistical: provide the AST-relevant slice rather than the whole codebase. Cursor’s Composer mode and Claude Code’s agentic file reads exist partly to manage this trade-off — pull in only what attention can actually use.
A related figure from a 2026 vendor analysis attributes roughly 65% of enterprise AI failures to context drift or memory loss during multi-step reasoning (Zylos Research). Treat the exact number as a vendor estimate, not a settled industry statistic. The direction, however, is consistent across independent studies: context management is the dominant failure surface in agentic refactoring workflows, and it gets worse as the codebase gets larger.
Semantic drift. This is the subtlest failure and the hardest to detect. The Queen’s SEAL Lab survey on LLM-driven refactoring documents transformations that are “syntactically valid but semantically incorrect” or simply irrelevant to the surrounding context (Queen’s SEAL Lab survey). A method gets extracted but its preconditions are quietly dropped. A loop gets converted to a stream operation but the original short-circuit behavior is lost. A null check is “simplified” into a default that masks a real failure case.
The survey’s recommended mitigation has three components: grounding with retrieved API references, static-analysis integration (RefactoringMiner for refactoring detection, plus tools like CodeQL or SonarQube for behavior-checking rules), and iterative repair where the tool fixes its own output before presenting it. RefactoringMiner is actively developed — v3 supports Java, and RefactoringMiner++ extends to C++ as of FSE 2025 (RefactoringMiner GitHub). It is the closest thing to ground truth for “did a refactoring actually happen, and which kind?”
What These Mechanisms Predict
The four prerequisites and three failure modes generate concrete predictions for any developer about to hand work to an AI refactoring tool. If the predictions are not already covered by your workflow, expect the failure.
- If your test suite has gaps in the area being refactored, expect at least one silent behavior change to reach production.
- If the tool does not parse and validate its own output against the language’s real symbol table, expect hallucinated method calls on real classes.
- If the refactor spans more than two or three files and your tool dumps the whole codebase into context, expect the model to miss a constraint that sits in the middle of the window.
- If the refactor involves loops, exception flow, or null handling, expect semantic drift in at least one of those constructs and verify them explicitly.
Rule of thumb: Before accepting any AI refactor, run the green test suite, run a static analyzer over the diff, and read the changes in the same files you would have read for a junior PR. The model is not the senior reviewer. You are.
When it breaks: The most common failure is not a hallucinated API — it is a syntactically clean refactor that drops a precondition, a null check, or a side effect the test suite does not cover. The limitation is fundamental: without explicit behavior pins, the LLM optimizes for plausible code, not preserved code.
Refactoring rarely lives alone. It sits inside a workflow that also touches AI Code Completion for new code, AI-Assisted Debugging for tracking down what the refactor broke, and AI Code Review for the second pass. Each has its own failure modes; refactoring’s failure mode is uniquely silent — and that is what makes the prerequisites non-negotiable.
A Note on Today’s Tooling
As of 2026, the leading agentic refactoring tools are GitHub Copilot, Cursor (with Composer 2 agent mode), and Claude Code. Comparative benchmarks vary by source; one 2026 review reports Cursor averaging around 63 seconds per refactoring task versus Copilot’s roughly 90 seconds, with SWE-bench Verified scores fluctuating between about 52% and 56% across the same tools (Tech-Insider). Treat any specific number as a snapshot — these tools release weekly updates, and independent reviews have flagged quality regressions for Copilot on complex refactors through 2026 (NxCode).
The constant across tools is the prerequisite stack. The tool that does the AST pass, respects the context-window economics, and integrates static analysis will outperform the one that does not — regardless of which model is underneath.
The Data Says
Behavior preservation is the entire game; tests are how you mechanically verify it; AST awareness is how the tool earns the right to touch the code; and explicit mitigation of hallucinations, context degradation, and semantic drift is what separates AI refactoring from autocomplete with a worse blast radius. Skip any one of the four prerequisites and you are no longer refactoring — you are rewriting with extra steps and a probability distribution for a co-author.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors