Prerequisites for AI-Assisted Debugging: Stack Traces, Context Windows, and Why Models Still Hallucinate Fixes

Table of Contents
ELI5
AI-assisted debugging suggests fixes by predicting likely tokens from your code and stack trace — not by running the program. It works when your bug resembles ones in training data, and fails when the fix it invents doesn’t exist.
GPT-5.5 sits at the top of SWE-bench Verified at 88.7% as of May 2026, with Claude Opus 4.7 trailing at 87.6% (Marc0 Leaderboard). Numbers like that suggest the debugging problem is mostly solved. Then you read a survey reporting that 43% of AI-generated code changes still need manual debugging in production, and that 88% of teams require two to three redeploy cycles to verify a fix (VentureBeat). The benchmark and the trenches disagree. The interesting question is why.
The Wrong Mental Model
Most developers approach AI-assisted debugging assuming the model parses their stack trace the way a debugger does — line numbers as line numbers, file paths as file paths, exception types as a thing to look up. It does not. The model sees a sequence of tokens. The structure you perceive as a stack trace exists for you, not for it.
That asymmetry shapes everything else about the prerequisites.
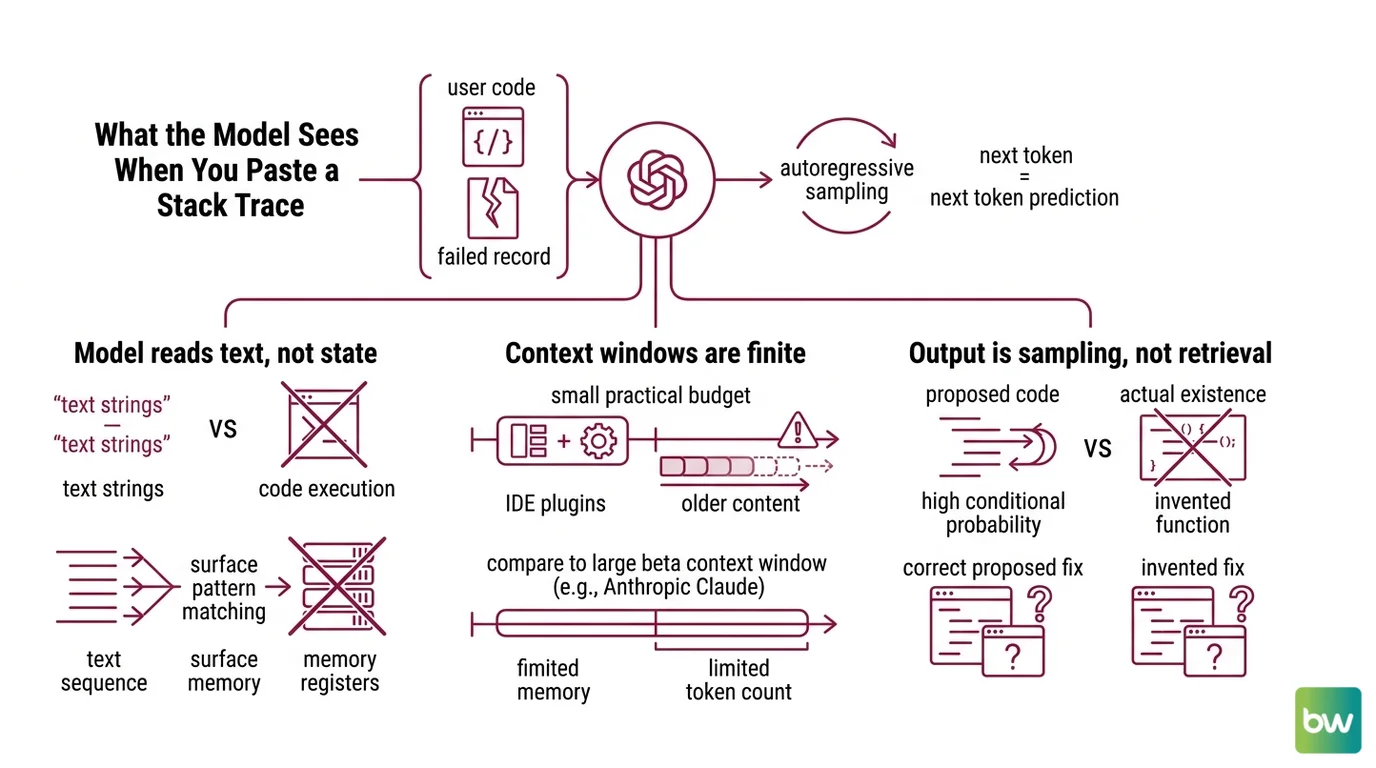
What the Model Actually Sees When You Paste a Stack Trace
A AI-Assisted Debugging session begins when you hand the model two things: your code, and a record of how it failed. From there, the model performs autoregressive sampling — predicting the next token, then the next, conditioned on what came before. There is no execution. There is no symbol table. The model never opens your file.
What do you need to understand before using AI-assisted debugging?
Four things. None of them are about prompting tricks.
The first is that the model reads text, not state. Your stack trace is a sequence of tokens to it. It does not know that line 47 corresponds to a specific instruction in memory. It cannot inspect the value of user_id at the moment of failure. It can only reason about your bug to the extent that the text contains enough surface pattern to match against training-data analogues.
AI Code Completion works for the same reason, and breaks at the same boundary.
The second is that context windows are finite working memory. Claude Opus 4.6 advertises a 1M-token beta context window on the Claude Platform (Anthropic Blog), but most developers debug inside an IDE plugin where the practical budget is much smaller. GitHub Copilot’s free chat tier exposes roughly 8K tokens (NxCode). When the relevant code, the stack trace, and the prior conversation exceed that budget, older content silently slides out of view. The model does not warn you. It just stops being able to see the function you were debugging.
The third is that output is sampling, not retrieval. When the model proposes from utils import retry_with_backoff, it is asserting that this import has high conditional probability given your codebase’s surface patterns. It is not asserting that the function exists. The same architecture that produces correct fixes produces invented ones, drawn from the same distribution. There is no internal flag that distinguishes the two.
The fourth is that the model has no concept of “I don’t know.” A code error and a code success look identical at the token level — both are syntactically valid sequences sampled from the model’s distribution. The model assigns probability, not truth. AI Code Review pipelines that wrap the same models do not change this; they only add a second sampling pass.
Where the Probabilistic Floor Bites
Frontier model hallucination rates in 2026 fall between 3.1% and 19.1% depending on task and model (Digital Applied). For code generation specifically, the directional estimate is 0.8% to 2.1% per generation, down from the 6–10% range observed in 2024. The improvement is real. The floor is not zero.
What are the technical limitations of AI-assisted debugging in 2026?
The dominant failure mode is not what most developers expect. It is not the model misunderstanding the bug — it is the model inventing the solution.
About 65% of code errors observed in 2026 benchmarks are invented symbols: function names, methods, imports, and APIs that look plausible but do not exist in the libraries the model claims to be calling (Digital Applied). The mechanism is the same one that produces correct completions — sampling from a distribution shaped by training data. Patterns from one library bleed into completions for another. A function named retry_with_jitter is statistically common across Python retry libraries, so the model offers it confidently, even when the specific library you imported does not export it.
The same mechanism produces something darker at the package level. A study of 576,000 Python and JavaScript samples across sixteen LLMs found that roughly 20% of recommended packages did not exist (SD Times). Worse, 43% of those fake names recurred when the same prompt was re-run, meaning attackers can predict and pre-register malicious squatter packages — a class of supply-chain attack now known as slopsquatting. The react-codeshift incident in January 2026 saw a malicious package spread to 237 repositories through AI agent skill files (Aikido).
Verification cost is the third constraint, and it tends to surprise teams who treat AI debugging as a productivity multiplier. In a six-week production test, Copilot’s acceptance rate for debugging tasks was 12% — compared with 76% for boilerplate completion (NxCode). The remaining suggestions either failed verification, introduced regressions, or solved the wrong problem.
Security & compatibility notes:
- Slopsquatting (BREAKING): AI-recommended package names are a live attack surface. The
react-codeshiftnpm incident (January 2026) propagated through 237 repositories via AI agent skill files. Action: pin dependencies, verify every AI-suggested install against the registry before adoption.- AI-generated CVE surge: 35 new CVEs were traced directly to AI-generated code in March 2026, up from 6 in January and 15 in February (Cloud Security Alliance). OWASP Top 10 vulnerabilities appear in roughly 45% of AI-generated samples (SQ Magazine). Treat AI fixes as code review input, not production-ready output.
- Copilot free tier context (WARNING): The ~8K-token context window on Copilot’s free chat tier is inadequate for multi-file debugging, and a single onboarding session can burn a fifth of the monthly request quota (NxCode). Plan for a paid tier or a higher-context tool when bugs span more than one file.
What the Mechanism Predicts About Your Next Debugging Session
Once you internalize that the model is sampling tokens from a probability distribution rather than reasoning about runtime state, the failure modes become predictable rather than mysterious.
- If your stack trace and relevant code exceed the model’s context window, expect it to confidently reference functions and variables that have already fallen out of view. The hallucination is not random; it is the model filling a gap with the most likely-looking content.
- If you accept a package import without verifying it against the registry, expect a small but nonzero chance of installing something that does not exist — or worse, something that does exist because an attacker pre-registered the predicted name.
- If you ask the model to debug code from a library released after its training cutoff, expect it to hallucinate the API by analogy to similar libraries. The wrongness will be subtle, and the error message will be misleading in a way that wastes more time than starting without the suggestion would have.
- Retrieval grounding — feeding the model verified documentation snippets at inference time — reduces citation hallucination by an estimated 75–90% compared with prompting alone (Digital Applied). It does not eliminate it.
Rule of thumb: Treat every AI-proposed fix as a hypothesis that needs the same verification you would give a junior engineer’s first pull request. The model is good at proposing fixes that look right. It is indifferent to whether they are right.
When it breaks: AI-assisted debugging fails most catastrophically when the bug lives in code, libraries, or runtime behavior absent from the model’s training distribution — there is no architectural mechanism that signals “I have not seen this before,” so the model produces an equally confident, equally fluent, equally plausible wrong answer.
The Quiet Shift the Tooling Is Making
Tool vendors have started bundling features that compensate for the architectural limits. GitHub added structured stack-trace root-cause analysis to Copilot Chat on github.com in April 2026 (GitHub Changelog), and AI Test Generation pipelines increasingly use the model to write regression tests for any fix it proposes — a verification loop instead of a trust gradient. Neither feature changes the underlying sampling mechanism. They change what surrounds it.
That is the pattern worth watching. Probabilistic models will not become deterministic. The infrastructure around them is what determines whether the floor of error costs you a debugging hour or a CVE.
Not magic. Plumbing.
The Data Says
AI-assisted debugging in May 2026 is good enough to be useful and unreliable enough to require verification at every step. The prerequisite is not a prompting trick — it is a working mental model of sampling, context windows, and the failure modes those two together produce. Tools that wrap their suggestions in verification loops are the ones worth integrating; tools that hand you raw text and leave the rest to optimism are the ones that turn into CVEs.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors