Prerequisites for Agentic Coding: Tool Use, Scaffolding, and the Plan-Execute-Verify Loop

Table of Contents
ELI5
Agentic coding is a language model wrapped in three things it cannot do alone: call tools, hold a loop, and verify its own output. The model writes the moves; the scaffolding actually plays the game.
Two teams run the same underlying model against the same SWE-bench task. One team’s agent fixes the bug on the second try; the other’s spins for forty minutes and proposes a patch that never compiles. Nothing about the weights changed. What differed sat outside the model entirely — in the runtime that turned a token stream into a sequence of file edits, test runs, and retry decisions.
This is the part of Agentic Coding that gets quietly skipped in product demos. The eye-catching part is the model — the demo voice that says “I’ll refactor the auth module.” The part that decides whether the refactor actually lands is something else: a host process holding a state machine, a list of available tool calls, and a verification step that the model itself does not control.
Before evaluating any agentic coding tool, three preconditions deserve to be understood as separate objects. They behave differently, they fail differently, and the marketing collapses them into one word — “agent” — that erases the seams where the engineering happens.
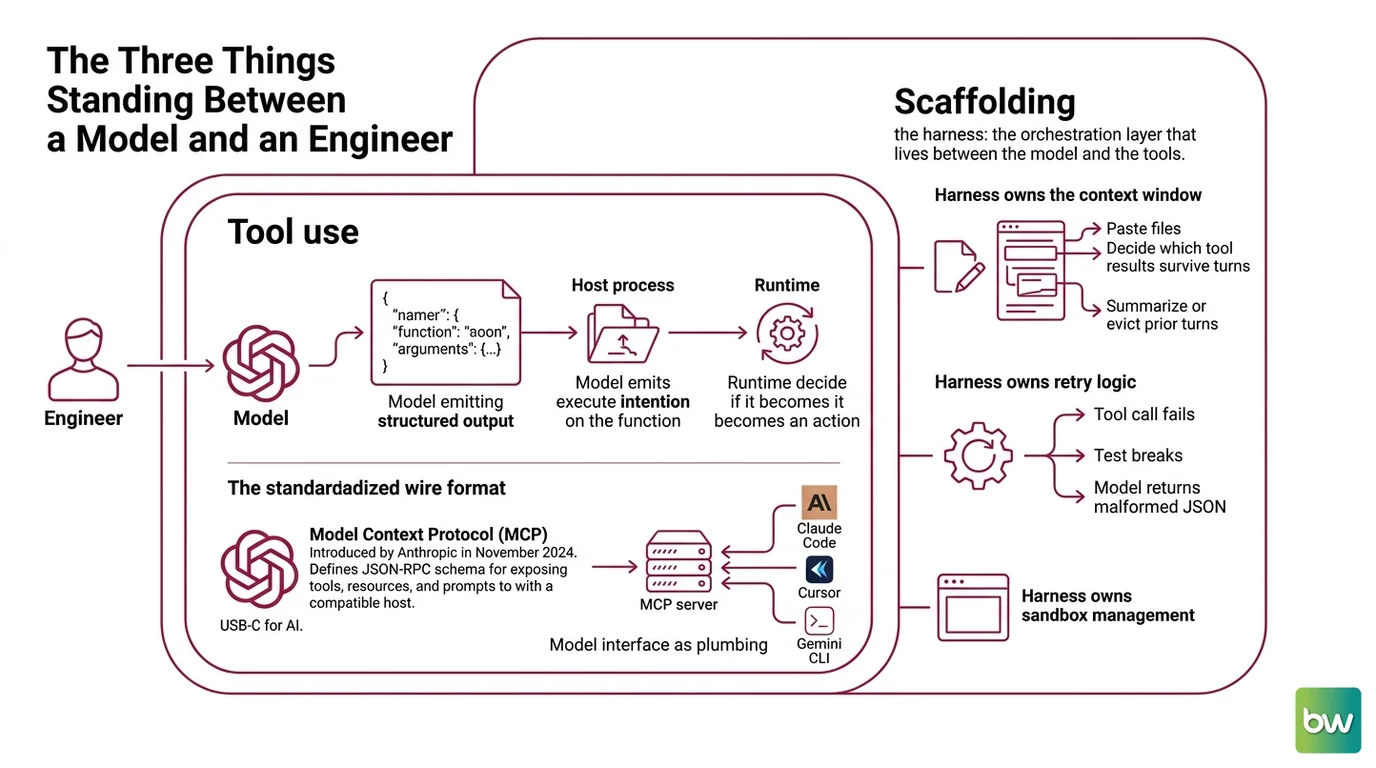
The Three Things Standing Between a Model and an Engineer
A LLM can describe a fix in natural language. It cannot, on its own, open a file, run a test, or know whether the test passed. Those capabilities live in a runtime that sits around the model and translates intent into observable effects. The agent, in any honest accounting, is the runtime — not the weights.
What do you need to understand before using agentic coding tools?
Three preconditions, layered from inside out.
- Tool use (function calling). The model emits structured output — typically a JSON object naming a function and its arguments — and a host process actually executes that function.
read_file("auth.py")is a string until something parses it, fetches the bytes, and feeds the result back into the next prompt. The model never touches the filesystem. It emits an intention; the runtime decides whether that intention becomes an action. OpenAI popularized this contract in mid-2023; by 2026 it is ubiquitous across frontier models and treated as a baseline capability rather than a feature.
The wire format that connects model to tools is itself standardizing. Model Context Protocol (MCP), introduced by Anthropic in November 2024, defines a JSON-RPC schema for exposing tools, resources, and prompts to any compatible host — the open standard for connecting AI apps to tools and data, described in the MCP Docs as “USB-C for AI.” When Claude Code, Cursor, and Gemini CLI all read from the same MCP server, the model interface stops being a per-vendor concern and becomes plumbing.
Scaffolding (the harness). This is the orchestration layer that lives between the model and the tools. The harness owns the context window: which files get pasted in, which tool results survive into the next turn, which prior turns get summarized or evicted. It owns retry logic: what to do when a tool call fails, when a test breaks, when the model returns malformed JSON. It owns sandboxing: which directories the agent can write to, which commands require approval, which network calls are blocked. The model has none of this. The model writes one turn at a time, and the harness decides whether that turn ever becomes a second turn.
Plan-Execute-Verify (PEV). The loop pattern that ties tool use and scaffolding into something that can finish a task. The model decomposes the goal into a plan, executes steps via tool calls, and then runs a verification step — usually tests, a typecheck, or a CI status — before deciding whether to iterate or stop. This is the lineal descendant of ReAct, introduced by Yao et al. in October 2022 (arXiv ReAct paper), which fused “reasoning” tokens with “act” tokens in a single trace. PEV adds the third move: verify. Without it, the agent confidently declares victory on broken code.
You will see all three in any working agent. You will see only the first in a demo that doesn’t make it past the first prompt.
Why the Same Model Scores So Far Apart on the Same Benchmark
The empirical observation that drives this section: identical underlying weights, swapped scaffolding, double-digit difference in SWE-bench Verified solve rate. Studies summarizing 2026 agentic coding trends show that the harness around the model can shift benchmark performance more than swapping the model itself (Hugging Face 2026 agentic coding trends). That fact is not intuitive. It deserves a mechanism.
How does scaffolding differ from the underlying LLM in coding agents?
The model is a stateless function. Given a context window, it produces a probability distribution over next tokens and samples one. Nothing persists between calls except whatever the host chooses to include in the next prompt. Coherent multi-step behavior is therefore not a property of the model; it is a property of how the host stitches successive calls together.
Scaffolding is everything that stitch involves.
| Concern | Owned by model | Owned by scaffolding |
|---|---|---|
| Token-level prediction | Yes | No |
| Which tools exist | No | Yes (registry + schemas) |
| When to call which tool | Mixed (model proposes, harness validates) | Validation layer |
| Context window contents | No | Yes (which files, prior turns, results) |
| Retry policy | No | Yes |
| Verification step | Sometimes proposes | Yes (runs tests, parses output) |
| Sandboxing and permissions | No | Yes |
| Parallel sub-agents | No | Yes (e.g., Cursor 3.0’s Agents Window) |
Read that table once more. Everything in the right column changes when you change tools — Claude Code, Cursor 3.0, Windsurf 2.0, Gemini CLI in Antigravity 2.0 — even if the underlying model is held constant. The harness is where the engineering lives.
The Plan-Execute-Verify loop is the canonical structure inside that harness. The pattern, described in current workflow guides (Blink Blog PEV workflow), looks like this:
- Plan. The model receives the task plus relevant context and emits a structured plan — usually a list of steps with the tool calls each step requires. The harness may inspect the plan, reject it, or surface it to a human for approval.
- Execute. The harness walks the plan. For each step, it calls the model to produce the next tool invocation, executes the tool, and appends the result to the conversation. The model never sees the tool’s runtime — only the serialized output the harness chooses to surface.
- Verify. The harness runs an external check — unit tests, a typecheck, a linter, a CI signal, a diff review. If verification fails, control loops back to plan or execute with the failure mode included in context. If verification passes, the loop terminates.
The reason this matters: each move is a different failure surface. A bad plan is a model failure. A tool that silently fails is a scaffolding failure. A test suite that’s too lenient is a verification failure. Collapsing all three into “the agent broke” hides which layer needs the fix. Earlier patterns like Chain-of-Thought prompting added reasoning tokens but stopped short of closing the loop with execution and verification — they improved the plan but never confirmed the result.
One subtlety that connects back to the table: the verification step is where autonomy actually ends. A loop that verifies against tests is bounded by the tests’ quality. A loop with no verification — just a model declaring “done” — is not really agentic; it is Vibe Coding with extra steps, and it produces patches that compile-but-don’t-work at a notably higher rate.
What the Loop Predicts When It Breaks
If the model is one layer and the scaffolding is another, the failure modes separate cleanly. That separation gives you something more useful than a benchmark score: it gives you predictions about what to expect from any agent before you’ve run it.
- If the harness lacks an explicit verify step, expect the agent to declare success on broken code. The model has no other signal that the work is finished.
- If the tool registry is incomplete — no
run_tests, noread_diff— expect the agent to hallucinate file contents from training data rather than read them. The capability gap forces a fallback to priors. - If context management is naive (full chat history, no summarization), expect coherence to collapse around the model’s effective context length, not its advertised one. SWE Bench runs that look fine in the first three tool calls and incoherent in the tenth usually trace to scaffolding choices, not model regressions.
- If the same agent uses a different model behind the same harness, expect quality to shift on the margin — but not by the order of magnitude that a harness change can produce.
These are not opinions. They follow from where the relevant state lives.
Rule of thumb: evaluate the harness as carefully as you evaluate the model. The unit under measurement is the loop, not the weights.
When it breaks: the dominant failure mode in 2026 agentic coding is the verification gap — the agent runs, edits, declares completion, and the proposed change either does not compile or breaks downstream tests the harness never executed. No frontier model fixes this. Only a stricter verify step does.
A Subtler Consequence
The three-layer structure also reframes a question that comes up around AI Code Migration projects: “Will the next model version make this agent obsolete?” Usually not, in the way the question implies. A new model improves the planning and execution layers — better tool selection, fewer malformed JSON arguments, sharper diffs. The verification layer barely moves, because verification is not a language modeling problem. It is a test infrastructure problem. Teams that invested in verifiable test suites and contracts get sustained gains from each model upgrade. Teams that invested only in prompts get diminishing returns, because the constraint sits in a layer the model never touched.
The Data Says
The model writes tokens; the harness writes outcomes. Across current agentic coding tools, swapping the scaffolding around a fixed model shifts benchmark performance more than swapping the model behind a fixed scaffolding (Hugging Face 2026 agentic coding trends). The unit of analysis is the loop, not the weights, and the layer that closes the loop — verification — remains the constraint.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors