Agent State Management: Threads, Checkpointers, Hard Limits
Table of Contents
ELI5
Agent state management is the plumbing that lets an LLM agent resume mid-task. Each step writes a structured snapshot of memory, plans, and tool results to a database. Before the next step runs, the agent reloads the snapshot. There is no “remembering” — only replay.
The first time an agent loses its place mid-conversation, the instinct is to blame the model. It forgot. It hallucinated context. It got distracted. None of that is what happened. The model is, as always, stateless — every request is a cold start. What forgot was the plumbing around the model, the layer most engineers never think about until it breaks under load.
That layer is Agent State Management, and almost everything written about it skips the part that matters in production: the contract between threads, checkpoints, and the database underneath.
The Anatomy of a Stateful Agent
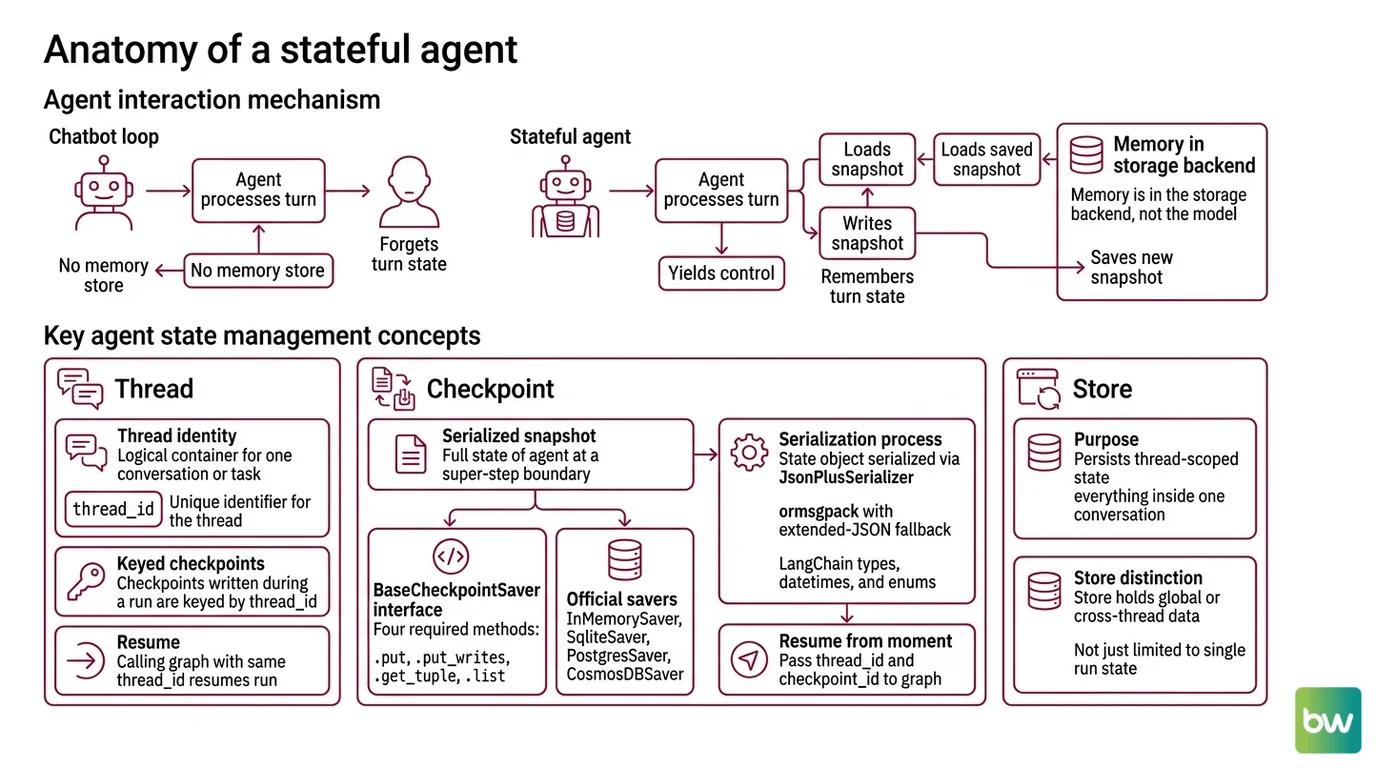
An agent that “remembers” is not remembering. It is loading a saved snapshot, running one step, and writing a new snapshot before yielding control. If you remove the snapshot store, the agent forgets every prior turn before the next token. Memory is not in the model. Memory is in the storage backend.
This is the mechanism that distinguishes a chatbot loop from a stateful agent — and it is what Agent Memory Systems are built on top of.
What do you need to know before working with agent state management?
Three concepts carry the entire abstraction: the thread, the checkpoint, and the store. Get these wrong and nothing else compiles into a working mental model.
A thread is the identity of one conversation, one task, one run. It is not a Unix thread, not a Python coroutine — just a logical container with a thread_id. Every checkpoint written during that run is keyed by it. When you call the graph again with the same thread_id, you are not starting a new run; you are resuming the previous one.
A checkpoint is a serialized snapshot of the agent’s full state at a single super-step boundary. The LangGraph reference defines the BaseCheckpointSaver interface around four required methods — .put, .put_writes, .get_tuple, .list, plus their async counterparts (LangChain Reference). Every official saver — InMemorySaver, SqliteSaver, PostgresSaver, the Azure CosmosDBSaver — implements that exact contract. The state object you write to it goes through JsonPlusSerializer, which uses ormsgpack with extended-JSON fallback for LangChain types, datetimes, and enums (LangChain Reference). To resume from a specific moment, you pass {"configurable": {"thread_id": ..., "checkpoint_id": ...}} to the graph.
The third primitive is the store, and the distinction matters more than the docs make it look. A checkpointer persists thread-scoped state — everything inside one conversation. A store persists cross-thread memories, indexed by namespaces like ("memories", user_id) (LangChain Docs). One thread cannot see another thread’s checkpoint. But both threads can read the same key in the store.
That asymmetry is the foundation of everything multi-user. If you wire user preferences into the thread state, every new conversation starts amnesiac. If you wire them into the store, the agent recognizes the user across sessions, devices, and tasks.
A few more pieces matter before you write a single line of agent code:
- Pre-existing graph fluency. Stateful agents are graphs of steps with conditional edges. You need to read a state machine before you can debug one.
- Async I/O literacy. The async checkpoint methods are not optional in production — synchronous Postgres saves serialize your throughput.
- A working understanding of Agent Planning And Reasoning, because checkpoint boundaries align with reasoning steps. If your plan is one giant step, you have one giant checkpoint and no replay granularity.
- Familiarity with Multi Agent Systems ergonomics, because once two graphs share a store, you have invented a coordination problem.
The interface looks small. The implications do not.
Where Stateful Agents Hit Their Ceiling
Understanding the contract is the easy part. Understanding what breaks it is what separates a demo from a system that survives a Tuesday afternoon traffic spike. The failure modes are not exotic — they are predictable consequences of writing serialized snapshots to a database after every super-step.
What are the technical limitations of agent state management at scale?
The first limit is structural. Checkpoints are blobs. They include the conversation history, intermediate tool outputs, planner scratchpads, and any object the user shoved into state. They grow monotonically unless you prune them. The LangGraph documentation does not publish a fixed maximum size — the limit is whatever your storage backend imposes.
For DynamoDB, AWS spelled this out: checkpoints under 350 KB are written inline as a DynamoDB item; at or above 350 KB they are offloaded to S3 with a pointer left behind, because the DynamoDB item-size limit is 400 KB (AWS Database Blog). That hybrid is elegant for durability and grim for latency — every read above the threshold becomes a network hop to object storage. A long-running coding agent that accumulates tool traces will cross 350 KB faster than you expect.
The second limit is concurrency, and the docs are unusually quiet here. Race-condition semantics for two graphs writing the same thread_id simultaneously are not formally specified by LangGraph. The application is responsible for ensuring it does not happen. If a user opens two tabs, retries a webhook, and your reverse proxy has no thread-level lock, you will eventually see two checkpoints overwrite each other in nondeterministic order. The state will be internally consistent. It will also be wrong.
The third limit is portability. There is no interchange format. State built against the LangGraph checkpoint schema cannot be loaded by CrewAI or AutoGen, and vice versa (Indium Tech Blog). A working comparison of Agent Frameworks Comparison reveals that “agent state” is, in practice, framework-state — not a portable artifact. If you need to migrate, you are reimplementing the orchestration layer, not just swapping a library.
The fourth limit is the one that should actually keep you up at night: deserialization. The default JsonPlusSerializer uses ormsgpack, and msgpack deserialization on untrusted bytes is a known attack surface. Two CVEs are open against LangGraph’s checkpoint loader. Both are real, both are recent, and both apply to anyone reading checkpoints written by an untrusted source — including, in some architectures, a checkpoint store an attacker can reach.
Security & compatibility notes:
- CVE-2025-68664 (CVSS 8.5, High): Remote code execution via crafted msgpack/json checkpoint payloads in
JsonPlusSerializer. Fixed inlanggraph≥ 3.0.0 and currentlanggraph-checkpointbuilds. Action: upgrade tolanggraph-checkpoint4.0.3 (April 27, 2026) or newer (PyPI).- CVE-2026-28277 (Warning): Unsafe msgpack deserialization in checkpoint loading. Mitigate by setting
LANGGRAPH_STRICT_MSGPACK=trueor passing an explicitallowed_msgpack_moduleslist toJsonPlusSerializer.- Naming: “MemGPT” is historical. The active project is Letta, which has rearchitected significantly around Context Repositories and Letta Code (Letta Blog). Articles still naming MemGPT as a current product are stale.
The CVE pattern is not unique to LangGraph; it is a structural consequence of serializing arbitrary Python types into a binary format and trusting whoever wrote the bytes. Treat your checkpoint store the way you treat your database: anything that can write to it can, eventually, run code in your process.
What This Predicts in Production
Once the mechanism is clear, the failure modes are no longer surprises. They are predictions.
- If your agent’s average checkpoint size grows linearly with conversation length, you should observe latency spikes after long sessions — and on DynamoDB, a step-function spike at the 350 KB boundary as items spill to S3.
- If two requests can hit the same
thread_idconcurrently, you should expect intermittent state corruption that passes type checks. The schema is satisfied; the semantics are not. - If you bind user identity to a thread instead of the cross-thread store, you should expect users to feel like the agent has dementia between sessions — because, structurally, it does.
- If you lift state from one framework to another by copying the JSON, you should expect that work to be slower than rewriting the orchestration. The state is not the abstraction. The graph is.
Letta took a different bet on the same problem. Its LLM-as-OS paradigm splits memory into in-context “core memory” (RAM-like) and out-of-context “archival/recall memory” (disk-like), with the agent itself managing tier movement via tool calls (Letta Docs). It is not a checkpoint replacement; it is a different decomposition of the same constraint. Both designs admit the same underlying truth — context is finite, persistence is external, and the agent is whatever code shuttles bytes between the two.
Rule of thumb: if a piece of information must survive across users, sessions, or graphs, it belongs in a store, not in thread state.
When it breaks: the dominant failure mode at scale is not lost data — it is silent state corruption when two writes collide on a single thread_id and the framework gives you no built-in lock. You learn this the hard way, in production, on a Sunday.
The Data Says
Stateful agents are not models with memory. They are stateless models wrapped in a serialization protocol — and the protocol’s seams are where production failures congregate. Threads, checkpoints, and stores are not implementation details to skim. They are the entire surface area on which reliability is decided.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors