Prerequisites for Agent Guardrails: Tool Use and Runtime Limits
Table of Contents
ELI5
Agent guardrails are runtime checkpoints wrapped around an agent’s inputs, outputs, and tool calls. Before adding them, you need the tool-use loop, the permission model, and the empirical fact that classifiers can be bypassed.
A 2025 paper demonstrated character-injection attacks reaching nearly perfect evasion rates against six well-known guardrail systems, including Microsoft Azure Prompt Shield and Meta Prompt Guard (arXiv 2504.11168). The systems were not misconfigured. They were working exactly as designed. The mystery is not why guardrails fail under attack — it is why anyone expected them to behave like walls in the first place.
The Loop You Are Actually Wrapping
A guardrail does not sit on top of a single model call. It sits inside a loop where the model proposes an action, an executor runs the action, and the result returns to the context for the next round. The shape of that loop is what determines where a checkpoint can live, what it can observe, and what it cannot.
Get the loop wrong and the guardrail you write will check the wrong surface — like installing a smoke detector in the wrong room.
What do you need to understand before implementing agent guardrails?
Three prerequisites, each at a different layer of the stack.
The tool-use loop. Agent Guardrails are not bolted onto a chat completion. They sit inside a generate-execute-feedback cycle. The model emits a structured tool call, the host application dispatches it, and the result returns as a new message in the context window. Anthropic splits this surface into client tools (your application executes them) and server tools (Anthropic’s infrastructure executes web_search, code_execution, web_fetch, and tool_search), per Claude API Docs. Where the execution happens determines where you can intervene; you cannot inspect what you do not host.
The identity and permission model. Every action an agent takes is, mechanically, an authorization decision. The Zero-Trust framing is right one: every agent should be a first-class authenticated identity with scoped, continuous authorization on every action. That sounds bureaucratic until you watch a single ambiguous prompt cascade into three tool calls, two of which hit production data. Claude Code defaults to cautious permissioning — it asks before modifying files or running commands, and auto mode delegates approvals to model-based classifiers. The default exists because the alternative is a confident probabilistic system holding an unlimited credential.
The hard limits of runtime enforcement. Guardrails are statistical classifiers and policy checks, not formal proofs. The OWASP Top 10 for LLM Applications (2025) expanded “Excessive Agency” to cover agentic architectures across three dimensions — too many tools, elevated permissions, decisions without oversight. The OWASP Top 10 for Agentic Applications (released December 2025) added Agent Goal Hijack as a first-class risk: an attacker alters the agent’s objectives via malicious content that exploits planning and reasoning. These are not bugs you can patch by tightening a regex.
Skip any one of these prerequisites and the rest of the article will read like instructions for installing a lock on a door that does not exist yet.
Where the Checkpoints Actually Plug In
Mature SDKs converge on the same three architectural surfaces, even when their vocabulary differs. This is not coincidence. It is what the loop allows.
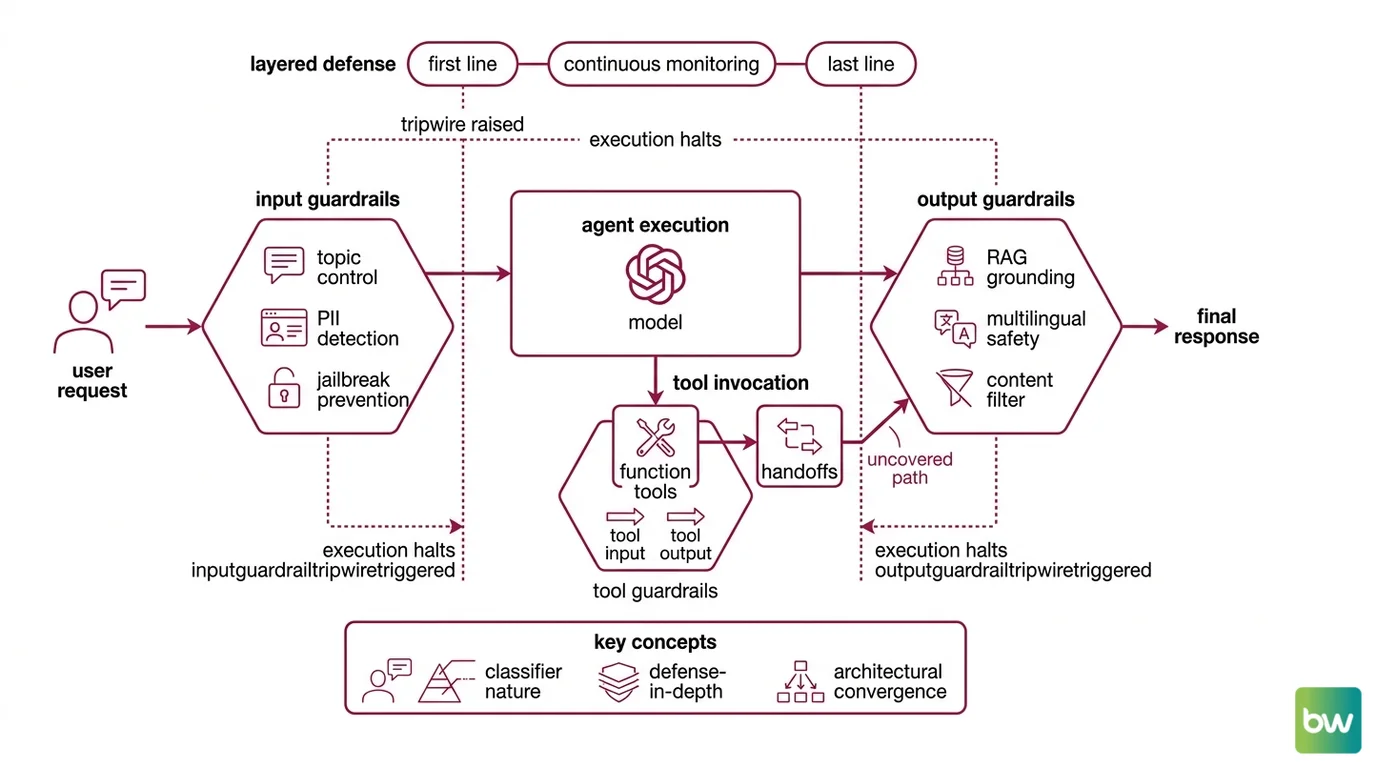
The OpenAI Agents SDK exposes input guardrails (run before the model sees the user’s request), output guardrails (run on the model’s final response), and tool guardrails on both the input to and the output of every function tool, per OpenAI Agents SDK Docs. When a guardrail decides something is wrong, it raises a tripwire — specifically an InputGuardrailTripwireTriggered or OutputGuardrailTripwireTriggered exception — and agent execution halts. The tripwire is the deterministic part. The classifier deciding whether to fire is not.
NVIDIA’s open-source NeMo Guardrails toolkit covers the same surfaces with a different idiom: topic control, PII detection, RAG grounding checks, jailbreak prevention, and multilingual content safety, integrated with LangChain, LangGraph, and LlamaIndex. The taxonomy is not arbitrary. Each item maps to a specific failure mode in the tool-use loop.
This is the defense-in-depth pattern: input guardrails as the first line, output guardrails as the last line, with information-flow control and monitoring running continuously between them. Each layer is necessarily probabilistic. Stack three probabilistic filters and you reduce risk; you do not eliminate it. The math is multiplicative, not magical.
A subtler observation hides in the OpenAI SDK: tool guardrails apply only to function tools, not to handoffs (OpenAI Agents SDK Docs). Handoffs run through a separate pipeline. If your defense relies entirely on tool guardrails, a handoff-mediated tool invocation is uncovered. The shape of the loop dictates the shape of the gap, and the gap is rarely advertised in the marketing diagram.
Why the Wall Is Actually a Filter
Here is the part that gets glossed over in vendor docs. A guardrail is a classifier. A classifier has a decision boundary. A decision boundary, by construction, has examples on both sides — including examples specifically engineered to land on the wrong side.
The empirical record is unambiguous on this point. A comparative evaluation found Qwen3Guard-8B at the top of its class with 85.3% accuracy, and every model degraded substantially on out-of-distribution prompts (arXiv 2604.24826). Benchmark accuracy does not generalize to novel attacks; the distribution shifts every time a determined adversary writes something the training data did not anticipate.
What are the technical limitations of agent guardrails?
Three structural limits you cannot patch around.
Limit one: the classifier itself is statistical. The arXiv 2504.11168 evasion study reached up to 100% success against six prominent systems, including Azure Prompt Shield and Meta Prompt Guard, using character injection combined with adversarial machine learning. That worst-case figure applies to specific attack-defense pairs, not to all guardrails on all inputs — but it falsifies the premise that input-side detection is sufficient by itself. The systems are not broken. They are doing exactly what classifiers do at their decision boundary.
Limit two: the detector’s input window is itself an attack surface. Detection models have limited input size and token support. The same paper notes that this constraint is itself exploitable — long-form attacks can stage payloads outside the window the classifier examines, then have them executed inside the agent’s larger context. The defense’s tunnel vision becomes a feature of the offense.
Limit three: most policies cannot be specified well enough to enforce deterministically. Symbolic guardrails — deterministic rule-based checks — can enforce roughly 74% of well-specified agent policy requirements, according to arXiv 2604.15579. The catch is in the next sentence of that paper: 85% of agent benchmarks lack concrete policies in the first place. You cannot deterministically enforce what you have not specified, and most teams are running agents whose intended behavior is described in slide decks, not in a checkable form.
The pattern is consistent across the literature. Where policies are crisp and small, deterministic checks dominate. Where policies are fuzzy or open-ended, you fall back on classifiers and inherit their decision boundary. There is no third option that lives in production today.
What This Geometry Predicts
Once you see guardrails as filters with measurable pore sizes, several behaviors stop being surprising:
- If you grant an agent broad tool access and rely on classifier-based input guardrails alone, you should expect novel-prompt evasion to track classifier accuracy on out-of-distribution data — which the literature reports as substantially worse than benchmark accuracy.
- If you grant an agent identity production-scope credentials by default, the failure mode is privilege amplification: a single mis-routed tool call walks through doors the model never had to argue for.
- If your only safety layer is the input guardrail, output corruption from a successful prompt injection is invisible until users see it. Defense-in-depth exists because each layer catches what the others miss.
- If you depend on the OpenAI Agents SDK’s tool guardrails for everything, handoff-mediated tool calls run uncovered. The fix is to attach input and output guardrails on the receiving agent, not to assume the parent’s tool checks transit the boundary.
Rule of thumb: Treat every guardrail as a probability gate, every permission as a contract you would sign in your own name, and Agent Evaluation And Testing as the only thing that tells you whether either is working in your specific environment.
When it breaks: Guardrails fail loudest when you treat statistical classifiers as deterministic gates — a single class of adversarial input can degrade detection accuracy from advertised benchmark to near-zero, and a permissive identity model turns that degradation into unbounded blast radius. The limit is not implementation quality; it is the probabilistic nature of the underlying classifier and the absence of formal specifications for the policies you want enforced.
Security & compatibility notes:
- Azure Prompt Shield / Meta Prompt Guard: Demonstrated evadable via character injection and adversarial ML, with up to 100% success against six prominent systems in controlled tests (arXiv 2504.11168). Action: do not rely on input-side classifiers as the only line of defense; layer output checks and information-flow controls.
- LLM classifier guardrails (general class): Substantial accuracy degradation on out-of-distribution prompts (arXiv 2604.24826). Action: include adversarial and novel-prompt cases in your evaluation set; do not project benchmark accuracy onto deployment.
- OpenAI Agents SDK — handoff coverage: Tool guardrails do not apply to handoff calls (OpenAI Agents SDK Docs). Action: add input and output guardrails on the handoff target agent.
The Data Says
Agent guardrails are useful, partial, and demonstrably evadable; the literature converges on defense-in-depth precisely because no single layer holds against a determined adversary. Get the tool-use loop, the permission model, and the limits clear before you write a single classifier — the architecture decisions made in those first two days set the upper bound on everything you can enforce later.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors