Agent Cost Optimization Prerequisites: Pricing, Latency, Caching Limits
Table of Contents
ELI5
Before tuning agent costs, learn three things: tokens are priced asymmetrically (output is far more expensive than input), latency comes from two different mechanics, and caches help only when their preconditions hold exactly.
An agent run is not one API call. It is a chain — sometimes dozens — where the next prompt is built from the last response, the tool outputs, and a slowly growing scratch of context. Most teams optimize this by trimming words, which feels productive until the bill arrives. The cost surface of an agent is shaped by mechanics most prompts never expose: a pricing asymmetry between input and output, two distinct latency regimes, and a caching layer that only works under conditions you usually violate without noticing.
The Token Bill Is Geometry, Not a Subscription
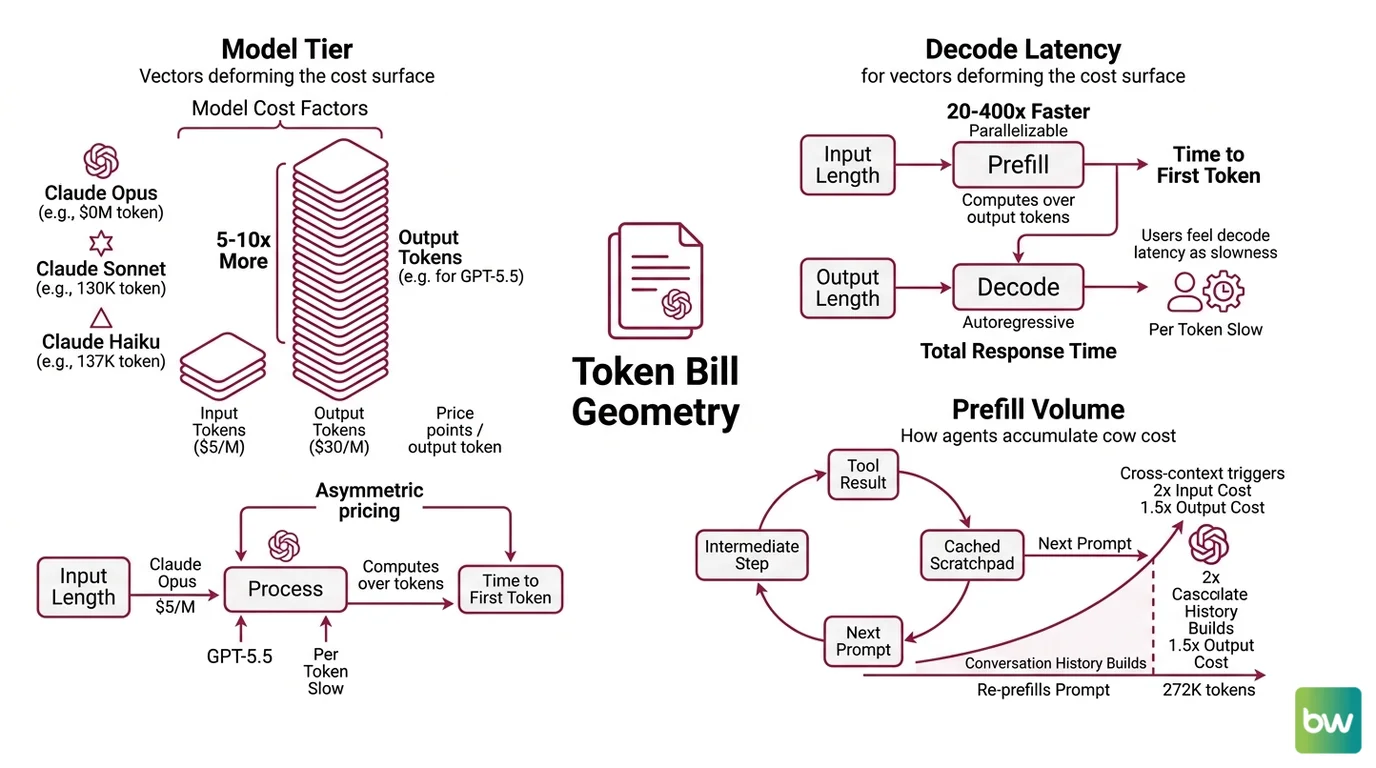
Treating model cost as a flat per-call expense is the most common mistake in Agent Cost Optimization. The number on the invoice is the product of three vectors: model tier, output share, and prefill volume. Move any one of them and the cost surface deforms.
What do you need to understand before optimizing agent costs?
Start with the price sheet, because the price sheet is not symmetric. Output tokens cost roughly 5–10x more than input tokens across the current frontier. Claude Opus 4.7 sits at $5 / $25 per million input/output tokens, Claude Sonnet 4.6 at $3 / $15, Claude Haiku 4.5 at $1 / $5 (Anthropic Docs). GPT-5.5 is $5 / $30 (OpenAI Pricing). A reasoning-heavy agent that emits long traces will burn output budget regardless of how clean its prompts look.
The second vector is decode latency. Prefill — the phase where the model reads your prompt and computes attention over every token — is parallelizable across the GPU. Decode, where the model emits the actual response one token at a time, is autoregressive and runs 20–400x slower per token than prefill (BentoML Inference Handbook). This is why time-to-first-token scales with input length while total response time scales with output length. An agent that retrieves a 30K-token document and produces a one-line answer pays prefill cost on the input but cheap decode on the output. An agent that produces a 4K-token plan pays the inverse — and decode latency is what users actually feel as slowness.
The third vector is prefill volume — and this is where agents accidentally light money on fire. Every tool result, every intermediate reasoning step, every cached scratchpad gets folded into the next prompt. By turn ten, the “input” might be 50K tokens of conversation history that the model re-prefills on every call. On GPT-5.5, crossing 272K input tokens triggers long-context billing of 2x input and 1.5x output for the entire session (OpenAI Pricing). A single accidental tool dump can re-price the rest of the agent loop.
The geometry, then, is not “make the prompt shorter.” It is: keep output disciplined, keep the prefix stable, and choose model tier per turn — small models for routing, mid models for reasoning, frontier models for the one step where reasoning matters most.
The Caching Layer That Looks Free Until It Isn’t
Caching is the lever everyone reaches for, and the promise is real — Anthropic cache reads cost 0.1x base input price (Anthropic Docs), and OpenAI reports up to 80% latency reduction on cached prefixes (OpenAI Docs). What the marketing pages do not surface is that caches fail silently. The request still completes. The bill just doesn’t go down.
What are the technical limitations of prompt caching and semantic caching for agents?
Prompt caching has hard preconditions. Anthropic requires a minimum of 4,096 tokens before Opus 4.5+ and Haiku 4.5 will cache anything; Sonnet 4.6 needs 2,048; older models needed only 1,024 (Anthropic Docs). Below the floor, your request runs normally and is silently not cached. OpenAI’s automatic caching has a 1,024-token minimum and matches in 128-token increments (OpenAI Docs). The cache also requires an exact-match prefix — a single timestamp, request ID, or tool-call UUID injected near the front of the prompt invalidates everything behind it. Agents that prepend volatile state to the system prompt break the cache on every turn while still paying the cache-write surcharge of 1.25x to 2x base input price.
Semantic caching tries to escape exact-match by storing embeddings of past prompts and returning past responses when a new prompt is similar enough. The trade-off is mathematical, not engineering. Below a similarity threshold of around 0.8, hit rates rise but false positives degrade output accuracy (arXiv 2411.05276 (Regmi et al.)); above 0.8, hits collapse to a few percent. Hit rate is also workload-dependent: code queries see 40–60% hit rates because syntax is repetitive, conversational queries see 5–15% because users phrase the same intent fifty different ways (arXiv 2509.17360 (Asteria)).
Worse, cache hits in agents are not benign. A recent study found cache-hit accuracy significantly below cache-miss accuracy — the false positives systematically degrade agent reliability (arXiv 2506.14852 (Agentic Plan Caching)). Long multi-turn histories amplify this: two unrelated sessions with similar conversational scaffolding can collide in embedding space, and the agent returns a plan built for a different user’s problem.
Not a glitch. An emergent property of similarity-based retrieval.
The mechanism is geometric. Embedding space compresses semantic meaning, but it also compresses noise. Two requests that look 0.87 similar to an embedding model can have different intents, different tool requirements, and different correct answers. The cache cannot tell the difference. It only knows which point in latent space is closer.
Compatibility notes for 2026:
- Anthropic prompt caching minimums shifted upward. Opus 4.5+ and Haiku 4.5 require 4,096 tokens; Sonnet 4.6 requires 2,048. Older code targeting 1,024 will silently skip caching on the newer models.
- Anthropic workspace isolation. As of Feb 5, 2026, caches are isolated per workspace on Claude API, AWS Bedrock, and Microsoft Foundry. Cross-workspace cache sharing no longer works — re-architect any pooled-key setup that relied on it.
- GPT-5.5 long-context billing. Prompts above 272K input tokens are billed at 2x input and 1.5x output for the entire session. Trivially triggered by accumulated tool dumps in long agent loops.
What the Geometry Predicts
The three mechanisms above are not independent. They compose, and the composition produces predictable failure modes that turn passive understanding into something operational.
- If output tokens dominate your bill, the lever is model routing, not prompt trimming. Reasoning happens during decode; cutting input by half changes nothing about the cost of a 4K-token response.
- If TTFT is your latency complaint, the lever is prefill volume and caching — not output speed.
- If your cache hit rate is unexpectedly low, look at what changes between calls. A timestamp, a session ID, a per-user tool-call sequence — anything volatile at the prefix kills the cache.
- If your semantic cache hit rate looks healthy but quality complaints rise, the false-positive trap is active. You need Agent Evaluation And Testing that compares cached responses against fresh generations, not just an aggregate quality metric.
You also need infrastructure the optimization quietly assumes. Without Agent Observability, you cannot see which calls hit the cache, which calls trigger long-context billing, or which tools amplify prefill. Without Agent Guardrails that cap tool-call depth, a runaway loop can multiply token cost before any human notices. Without Agent Error Handling And Recovery, retries on transient failures silently double cost — and uncached retries triple it. For decisions where wrong-but-fast is worse than slow-and-correct, leave Human In The Loop For Agents review in place; cache-driven speedups should not bypass the checkpoints that exist for accuracy reasons.
Rule of thumb: Cost shrinks when you change which model handles which turn, not when you tighten the wording of any single prompt.
When it breaks: Caching collapses when prefixes are unstable, when the cache minimum is not met, or when semantic similarity quietly substitutes a wrong answer for a right one. None of these failures appear in the response — only on the invoice or in the quality regression that nobody traces back to the cache.
The Data Says
The cost surface of an agent is shaped by three asymmetries: output tokens cost several times more than input, decode latency runs 20–400x slower per token than prefill, and caches return value only when their preconditions hold exactly. Prompts that ignore these asymmetries get expensive in ways the prompt itself cannot reveal.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors