Prerequisites and Technical Limits of AI in CI/CD: DevOps Foundations to Flaky-Test False Positives

ELI5
Before AI can help your ** AI in CI/CD Pipelines**, the pipeline must already be deterministic, version-controlled, and well-tested. AI adds probability to a system that demands certainty — and its sharpest failure is calling a real bug “flaky.”
A pipeline went green at 2 a.m. A test had failed, an AI classifier labeled the failure flaky, the runner retried it twice, and on the third pass it passed. The regression reached users by morning. Nothing in the tooling was broken — the model did exactly what its training distribution told it to do. That gap, between what the system did and what the team assumed it did, is where almost every disappointment with AI in delivery pipelines begins.
The Foundation AI Cannot Replace
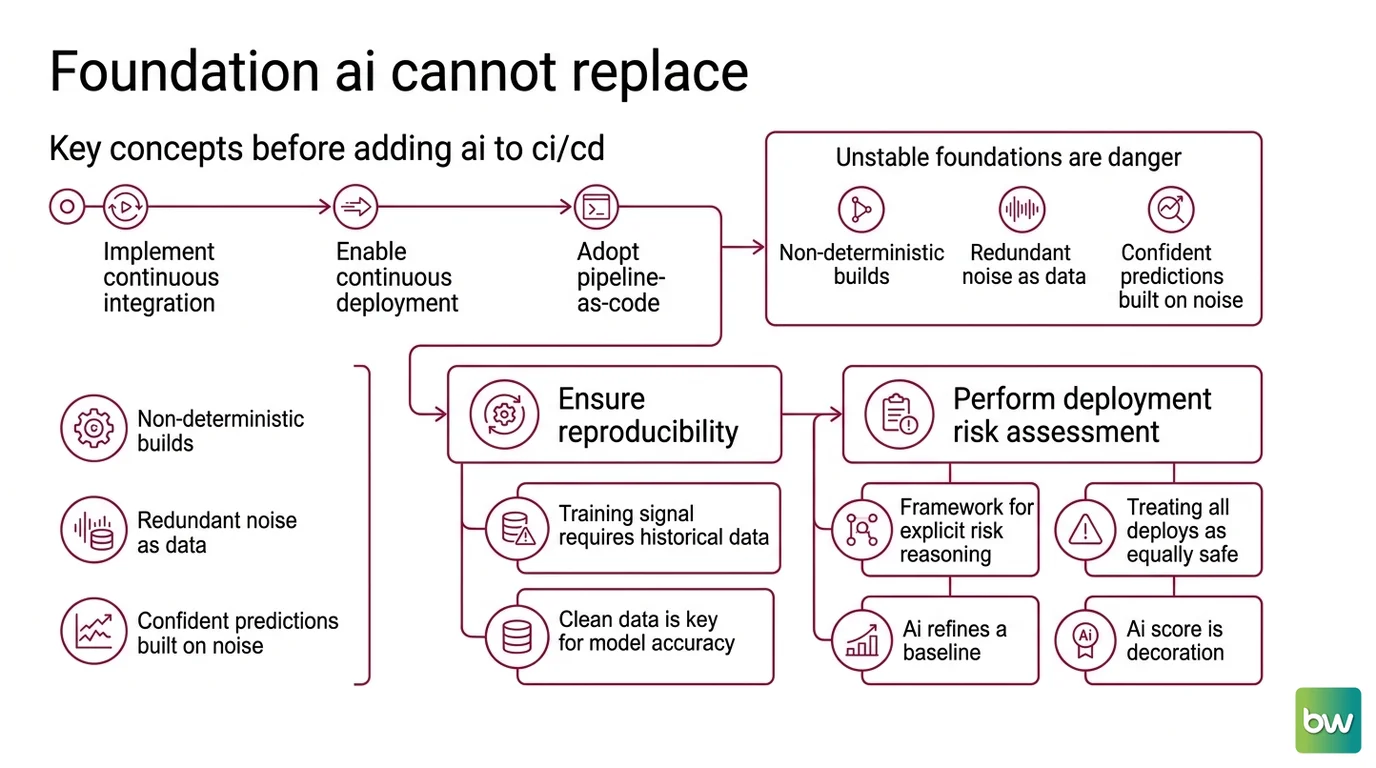
AI in a delivery pipeline is not a foundation. It is a layer that sits on top of one, and it inherits every weakness underneath it. Before any model can rank tests, diagnose a failed build, or propose a fix, the pipeline has to produce a signal that a statistical system can actually learn from — and most of the prerequisites have nothing to do with machine learning at all.
What do you need to understand about CI/CD and DevOps before adding AI?
Start with the mechanics that predate any model. Continuous Integration means every change is merged and verified against an automated build and test suite, continuously, rather than in a painful quarterly merge. Continuous Deployment extends that: a change that passes the gates is released without a manual hand-off. The discipline that makes both reproducible is Pipeline As Code — the pipeline definition lives in version control, reviewed and diffed like any other source file, so that the same input produces the same pipeline every time.
That last property — reproducibility — is the one AI quietly depends on.
A model that prioritizes tests or flags suspicious failures learns from historical pass/fail records. If your builds are non-deterministic, if the same commit produces green on Monday and red on Tuesday for reasons no one tracks, then the training signal is noise wearing the costume of data. The model will happily fit that noise and hand you confident predictions built on it.
There is a second prerequisite that is less about plumbing and more about judgment: Deployment Risk Assessment. Teams that already reason explicitly about which changes are risky — schema migrations, auth changes, anything touching money — have a framework AI can sharpen. Teams that treat every deploy as equally safe have nothing for the model to refine. AI scores risk against a baseline; if you have no baseline, the score is decoration.
Why determinism has to come before intelligence
Consider what a Code LLMs-powered assistant is actually doing when it reads a failed job log. It is conditioning its next-token predictions on the text you feed it and on patterns absorbed during training. It is not executing your build. It does not know, in any causal sense, why the compiler failed — it assigns high probability to explanations that resemble explanations seen during training.
Not intelligence. Conditional probability, well-dressed.
This matters because determinism is what lets you tell the difference between the two. When a build fails for a real, reproducible reason, an AI diagnosis can be checked: rerun the build, apply the proposed fix, watch the signal flip. When a build fails intermittently, the same diagnosis floats free of any ground truth — there is nothing stable to verify it against. The model’s confidence stays high either way. Only the pipeline’s determinism tells you whether that confidence means anything.
Where the Statistics Break
Once the foundation is solid, AI earns its place by doing things humans do slowly. It ranks tests by failure probability so the likely-broken ones run first. It summarizes a thousand-line log into three lines. It drafts a patch. The gains are real and, in Test Prioritization, sometimes large — documented cases show execution-time reductions in the range of 40 to 75 percent (DigitalOcean). But every one of those capabilities is a probabilistic estimate, and probabilistic systems fail in characteristic, predictable ways.
What are the technical limitations and failure modes of AI in CI/CD pipelines?
The first failure mode is the one from the 2 a.m. story: misclassification in Flaky Test Detection. A flaky test is one that produces a stochastic pass/fail result under equivalent code and environment, and some nondeterminism is genuinely unavoidable in complex distributed systems (Edge Delta). The problem is that a real regression and a flaky test can look identical on a single run — both are “a test that failed.” An AI classifier produces false positives, mislabeling a genuine regression as flaky, and false negatives, missing the subtle intermittent patterns it was supposed to catch. A single execution carries almost no information here; reliable flaky-test detection needs multiple pass/fail cycles, and the verdict degrades sharply without high-fidelity historical data (Semaphore).
Treat an AI flaky-test verdict as advisory, not authoritative.
The second failure mode is Hallucination in diagnosis. GitLab Duo’s Root Cause Analysis, for example, forwards segments of a job log to an AI gateway and runs a three-phase pass — summarize the log, analyze the failure, propose a fix — targeting syntax errors, compilation failures, and Docker build problems (GitLab Docs). The summary is often excellent. But the analysis is a generated narrative, not a trace of execution. When the true cause sits outside the forwarded log segment, the model does not return “insufficient information.” It returns its most probable explanation, fluent and wrong, because returning a confident answer is what its training rewarded.
Why the failure modes are structural, not bugs
It is tempting to read these as immaturity — problems that a better model or a bigger context window will erase. The reality of AI inside delivery pipelines is more stubborn than that. These failures come from the same mechanism that makes the tools useful: the model maps inputs to probable outputs without access to your system’s ground truth. A classifier that never produced a false positive on ambiguous single-run data would have to know something it cannot know from the data alone.
The same logic constrains Self Healing Pipelines — pipelines that detect a failure and apply an automated remediation. Self-healing works beautifully for the well-understood, repetitive failure: the transient network timeout, the known-flaky integration test, the cache that needs clearing. It becomes dangerous precisely when the failure is novel, because a confident automated fix applied to a misdiagnosed problem doesn’t heal the pipeline — it hides the symptom while the underlying defect advances downstream.
The agentic tools raise the same question at higher stakes. GitHub Copilot can act as an autonomous coding agent inside CI/CD: assigned an issue, it opens a pull request, runs tests, self-reviews, and triggers a security scan, with its CLI usable inside GitHub Actions (GitHub Changelog). That self-review is the part to watch — a model checking its own probabilistic output against the same priors that produced it is not an independent verifier. Routing also varies: current tooling tends to use a model picker that selects a model by task complexity rather than a single fixed model, so the behavior you validated last month may not be the behavior you get today.
What the Probability Predicts
Once you see these tools as probability estimators sitting on a deterministic base, their behavior stops being surprising and starts being predictable. The mechanism lets you forecast where they will help and where they will quietly hurt.
- If your historical build data is clean and high-fidelity, expect test prioritization to deliver its largest gains — the model has a real signal to rank against.
- If your builds are intermittently non-deterministic, expect an AI flaky-test classifier to launder that noise into false confidence, and expect occasional regressions to slip through as “flaky.”
- If you let an autonomous agent self-review and merge without an independent gate, expect its error rate to compound rather than cancel, because the reviewer shares the author’s priors.
- If you adopt a tool whose pricing or model routing is in flux, expect the behavior you validated to drift — re-verify after any platform change.
That last point is concrete right now. GitHub Copilot’s individual plans currently run at $10/month for Pro, $39/month for Pro+, with Business at $19/user/month, but flat-rate billing is being replaced by token-based “AI Credits” starting June 1, 2026, and some sign-up tiers were paused in late April 2026 (GitHub Docs). Budget and access assumptions baked into a pipeline before that change may not survive it. GitLab Duo’s pricing was not confirmed in this analysis, so treat any figure you find for it with the same caution.
Rule of thumb: AI belongs on the parts of the pipeline where you can cheaply verify its output, and stays advisory on the parts where you cannot.
When it breaks: The dominant failure is silent misclassification — an AI labeling a real regression as a flaky test (or a confident root-cause analysis pointing at the wrong cause), because a single run cannot distinguish a genuine fault from noise and the model rarely surfaces calibrated uncertainty about its own verdict. Keep a human gate on any verdict that can let a change reach users.
The Data Says
AI does not lower the bar for CI/CD discipline — it raises it. The tools deliver measurable speedups in test selection and log triage, but only on top of a deterministic, version-controlled pipeline with clean historical data. Their signature failure mode is structural, not incidental: they convert ambiguous, single-run evidence into confident verdicts, which is exactly the kind of confidence a delivery pipeline should never trust without verification.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors