What AI Technical-Debt Tools Actually Measure — and Where the Numbers Break
ELI5
AI technical-debt detection doesn’t measure debt directly. It counts proxies — complexity, rule violations, how often files change — then converts them into a score. Useful as a signal, unreliable as a verdict.
Here is a number that disagrees with itself. SonarQube’s own analysis of more than 137 million issues puts its false-positive rate at 3.2% (Sonar Blog) — below the five-percent line vendors like to advertise. An independent study of the same class of tool found that only about 18% of the warnings it flagged were true positives (arXiv empirical study). Same category of analysis. An order of magnitude apart. Both numbers are real, and the space between them is the most useful thing you can learn before trusting any AI-driven debt score.
The instinct is to treat technical debt like temperature: a property of the code that a good enough sensor reads off directly. It isn’t. The tool never sees debt. It sees patterns it has been told to correlate with debt, and then it does arithmetic on those patterns.
Not a measurement. An estimate wearing a measurement’s clothes.
The Three Engines Hiding Behind One Word
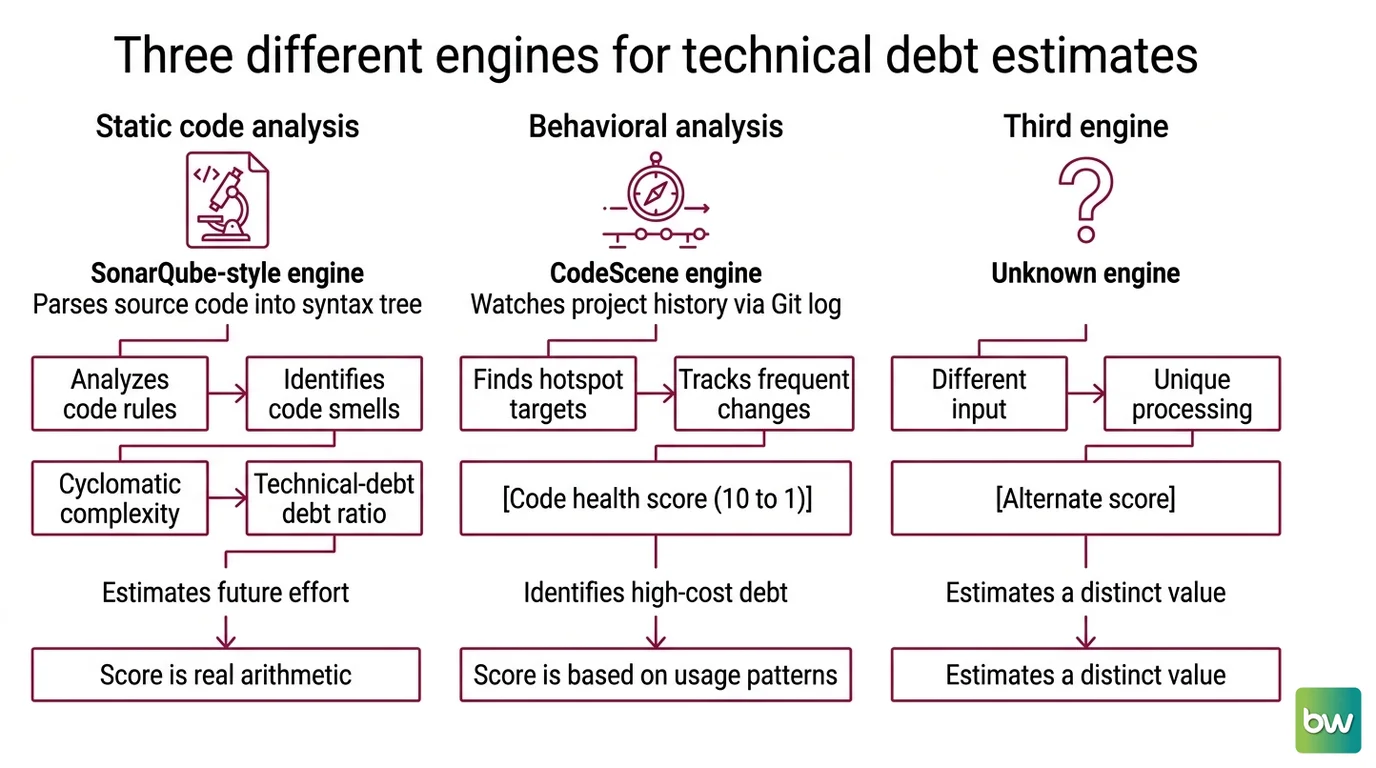
“AI for technical debt” is a single phrase covering at least three different machines, each with its own way of looking at your code and its own way of being wrong. Before the score on your dashboard means anything, you need to know which engine produced it — because they fail in completely different directions. AI For Technical Debt is best understood as a family of estimators, not a single instrument.
What concepts do you need to understand before using AI for technical debt?
Start with the oldest engine: SonarQube-style Static Code Analysis. It parses your source into a syntax tree and runs rules against it. When a function exceeds a complexity threshold, when a Code Smell pattern appears, when a rule is violated, it raises an issue. The headline metric here is Cyclomatic Complexity — a count of the independent paths through a function. More branches, more paths, more cognitive load to maintain. SonarQube then aggregates these into a maintainability rating (the metric formerly called the SQALE rating) and a technical-debt ratio, defined as estimated remediation effort divided by the cost to develop the same volume of code (SonarQube Docs). The score is real arithmetic. What it estimates is a guess about future effort.
The second engine ignores the code’s structure and watches its history instead. Codescene performs behavioral analysis: it reads your Git log to find Hotspot Analysis targets — files that are both complex and changed frequently — on the theory that complexity only hurts where people keep returning. It expresses the result as Code Health, a score from 10 (healthy) down to 1 (severe), built from complexity, cognitive load, and maintainability signals (CodeScene Blog). A thousand-line file nobody has touched in three years is cheap debt. A tangled file edited every week is expensive. Same complexity number, opposite priority.
The third engine is the newcomer, and the one most people now mean by “AI.” Large language models — Code LLMs — read a diff the way a reviewer would and comment in natural language. Tools like Codeant AI layer LLM review on top of churn metrics, complexity scores, and PR rework ratios (CodeAnt AI). This engine can reason about intent in a way the first two cannot. It can also invent problems that aren’t there, with total fluency.
Two terms you can’t skip
Two prerequisite ideas tie these engines together. The first is the Quality Gate: a pass/fail boundary applied to the metrics, the thing that actually blocks a merge. A gate is only as honest as the proxy underneath it. The second is Refactoring — the act of reducing debt without changing behavior. Every tool above exists to point at refactoring targets. None of them can tell you whether the target is worth your afternoon.
Why the Same Codebase Earns Three Different Verdicts
Run all three engines on one repository and you will often get three different rankings of what to fix first. This is not a bug in any of them. It is the direct consequence of measuring a proxy instead of the thing itself — and it is where the limits start to bite.
What are the limitations of AI-based technical debt detection?
The deepest limitation is structural: no tool can see the cost of debt, only its correlates. Technical debt is defined by future consequence — the interest you pay in slowed delivery and bugs later. A static analyzer reads the present. It cannot know that the “overly complex” function is a deliberately optimized hot path nobody should touch, or that the “clean” module is a landmine because its single maintainer just left. Context lives outside the syntax tree.
The second limitation is engine-specific, which is why keeping them separate matters. Rule-based static analysis fails toward noise: it flags patterns that are technically violations but locally harmless, and it does so consistently. Behavioral analysis depends entirely on history — point it at a freshly migrated repository with a shallow Git log and its hotspot map is blank, not because the debt is gone but because the evidence was rewritten. LLM-based review fails toward confident fabrication: it can flag a Hallucination as a defect, citing a vulnerability that the surrounding code already guards against.
The trust data tracks this discomfort. Roughly 84% of developers now use AI somewhere in their workflow, yet only about a third say they trust its accuracy (CodeAnt AI). That gap is not irrational. It is what calibration looks like when the tool is fluent but not reliable.
Can AI accurately measure technical debt or does it produce false positives?
This returns us to the number that disagreed with itself. SonarQube reports a 3.2% false-positive rate across its full feedback corpus (Sonar Blog). A 2021 empirical study, using a specific tool configuration and ruleset, found that only about 18% of flagged warnings were genuine — implying a false-positive rate far higher than any vendor figure (arXiv empirical study). Both can be true at once, and the reconciliation is the whole lesson.
The vendor number counts issues that users explicitly marked wrong, across every rule and every project, weighted toward the well-tuned rules most teams actually run. The academic number comes from a fixed ruleset applied uniformly to specific projects, including noisy rules a tuned setup would have silenced. The figure is methodology- and ruleset-dependent; it does not mean “the tool is 82% wrong” in general. It means precision is a property of your configuration, not a constant printed on the box.
The downstream evidence is blunter: developers fix fewer than 30% of the static-analysis alerts they receive (arXiv empirical study). When most of what a tool says gets ignored, the bottleneck was never detection. It was relevance — and relevance is exactly what a proxy cannot guarantee.
Reading the Score Without Trusting It
Once you accept that the number is an estimate, it becomes useful in a way it never was as a verdict. The skill is turning a proxy into a prediction you can test, rather than a grade you accept.
A few if/then rules fall straight out of the mechanism:
- If a static analyzer flags a complex function but Git shows nobody has touched it in a year, expect a false alarm — the complexity is dormant, not dangerous.
- If behavioral analysis ranks a file as a top hotspot, expect real friction there regardless of its raw complexity score; change frequency is the better signal of where debt actually costs you.
- If an LLM reviewer flags a vulnerability, expect roughly one in several of those flags to be confident fiction, and verify before you act.
- If you tighten a Quality Gate threshold, expect your false-positive count to rise faster than your true-positive count, because most rules saturate on noise first.
Rule of thumb: trust the tool to tell you where to look, never whether it’s worth fixing — that judgment needs context the syntax tree doesn’t contain.
There is a newer wrinkle worth flagging. SonarQube’s 2026 releases add AI Code Assurance, which routes AI-generated code through stricter quality gates, alongside an MCP server for agent integration (Sonar). The premise is that machine-written code carries a different debt profile than human-written code — a reasonable hypothesis, and one that quietly concedes the central point: the detector’s accuracy depends on what it is pointed at.
When it breaks: the failure mode is automation bias — a team wires a debt score into a blocking gate, stops reading the underlying issues, and starts refactoring whatever the proxy ranks highest. The metric improves; the codebase doesn’t, because the tool optimized the measurement, not the maintainability it was standing in for.
The Data Says
Technical debt is a consequence, not a quantity, and every AI tool that claims to measure it is really measuring a correlate — complexity, churn, or a model’s read of a diff. The honest question is never “how much debt do I have?” but “which proxy produced this number, and what does it systematically miss?” A 3.2% false-positive rate and an 18%-true-positive finding describe the same kind of tool under different configurations; the gap between them is your reminder that precision here is something you tune, not something you’re handed.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors