Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge

Table of Contents
ELI5
An LLM-as-a-judge is a language model scoring other models’ answers. It agrees with humans surprisingly often, but swap the order of the two answers and it frequently changes its mind. The judge is fast, not objective.
Hand a language model two answers and ask which one is better, and something unsettling happens: it agrees with human reviewers about as often as the humans agree with each other. On MT-Bench, GPT-4’s verdicts matched human preferences 85% of the time, edging past the 81% rate at which the human reviewers agreed among themselves (Zheng et al.). By that number alone, the machine looks not just adequate but faintly superhuman.
Now swap the two answers and ask again.
The same judge holds its verdict only about 65% of the time, which means it reverses itself on roughly one pair in three for no reason other than the better answer moving from the first slot to the second (Zheng et al.). A reviewer cannot be that aligned with humans and that inconsistent with itself unless something other than quality is steering the score. Untangling what that something is tells you exactly where LLM-as-a-Judge can be trusted and where it quietly falls apart.
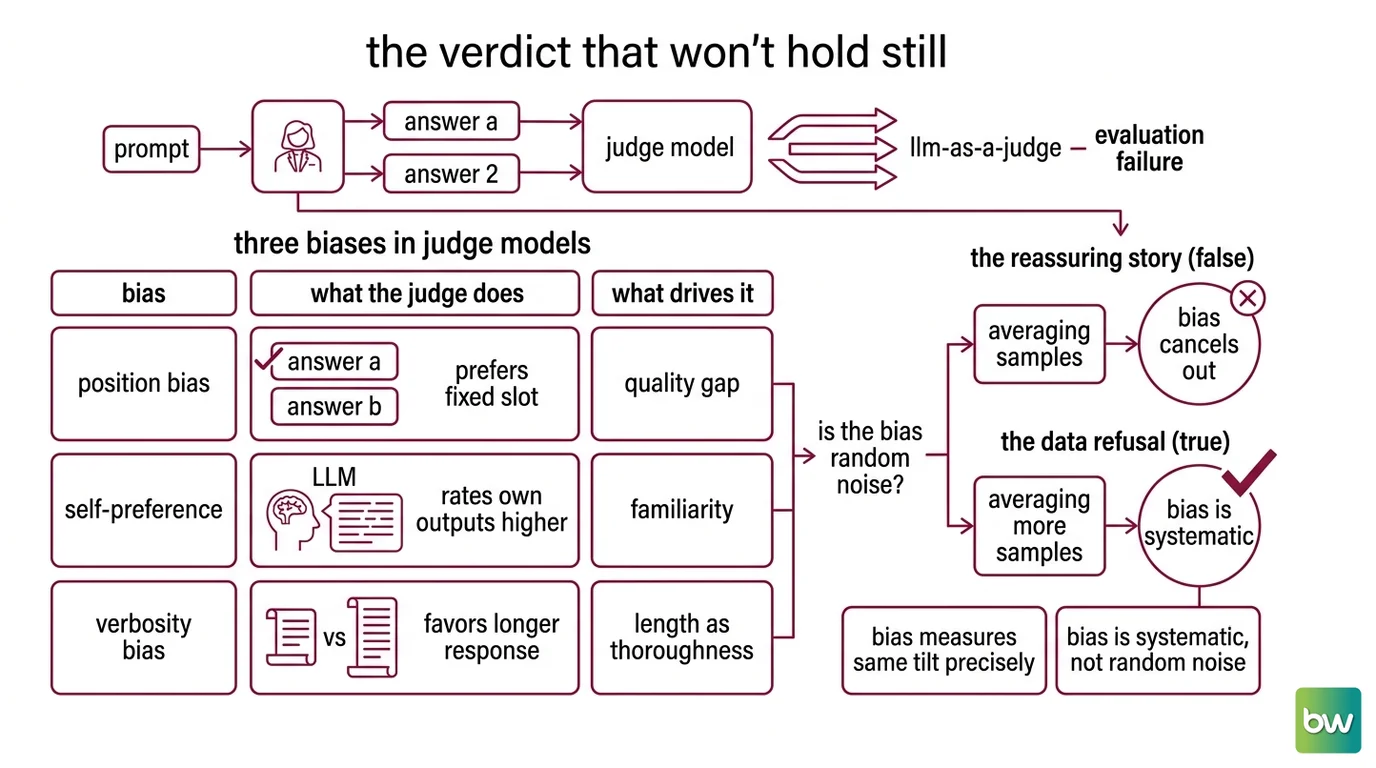
The Verdict That Won’t Hold Still
The order-swap collapse is the most visible failure, but it is one symptom of a family. Before you can correct any of them, it helps to see the whole set and notice what they share: each one is a preference the judge applies independently of which answer is actually better.
What are the technical limitations of LLM-as-a-judge?
Three biases show up across study after study. Position bias is the order effect already described: the judge favors whichever answer sits in a privileged slot. Self-preference is the tendency to score its own generations higher than a neutral grader would. Verbosity bias is the pull toward the longer answer, which the original MT-Bench analysis found travels together with self-enhancement (Zheng et al.).
| Bias | What the judge does | What drives it |
|---|---|---|
| Position bias | Prefers the answer in a fixed slot, usually the first | The quality gap between the two answers; strong when they are close, faint when far apart (Shi et al.) |
| Self-preference | Rates its own outputs above a neutral baseline | Familiarity: it over-scores text it finds easy to predict (Wataoka et al.) |
| Verbosity bias | Favors the longer response | Length reads as thoroughness; co-occurs with self-enhancement (Zheng et al.) |
The reassuring story would be that these are random noise that averages out over a large enough eval set. The data refuses that comfort. A systematic study spanning 15 judge models, 22 tasks, roughly 40 answer generators and more than 150,000 individual comparisons found that position bias varies sharply by judge and by task, and is driven mainly by the quality gap between the two answers rather than by chance (Shi et al.). The bias is systematic, not random noise, which means averaging more samples does not cancel it; it just measures the same tilt more precisely.
That distinction points the next question inward. If the bias is structural, it has to come from how the model assigns probability.
Why the Bias Lives in the Model’s Sense of Familiarity
A model does not “see” an answer and weigh its merits. It reads the text as a sequence of tokens and, at every position, holds a distribution over what should come next. That mechanical fact is enough to explain why a judge can prefer its own work without anything resembling ego.
Why do LLM judges show position bias and self-preference for their own outputs?
Start with self-preference, because its mechanism is the more surprising. Models can recognize their own outputs at a rate well above chance, and the strength of that self-recognition correlates linearly with how strongly they favor those outputs when judging (Panickssery et al.). The tempting reading is that the model is rooting for itself.
Not vanity. Familiarity.
The likely root cause is Perplexity, a measure of how surprised the model is by a piece of text. A judge systematically over-rates low-perplexity answers, the ones it finds easy to predict, whether or not it actually wrote them (Wataoka et al.). A model’s own generations are by construction low-perplexity to itself, so they ride the same effect that already favors fluent, familiar phrasing from anyone. Self-preference is not a separate quirk bolted on; it is the familiarity bias pointed at a mirror. The judge rewards predictability, not quality, and predictability and quality only sometimes coincide.
Position bias yields to the same kind of analysis. Because the judge processes the two answers in sequence inside a single context, the comparison is not symmetric: the tokens it reads first shape the conditional probabilities for everything that follows. When the two answers are close in quality, that asymmetry is large enough to decide the verdict; when one answer is clearly stronger, the quality signal swamps the position signal and the order stops mattering (Shi et al.). The bias is loudest exactly when the decision is hardest.
One caution about generality. The self-recognition results were measured on GPT-4 and Llama-2-era systems, not on every current frontier model (Panickssery et al.). Treat the linear link from self-recognition to self-preference as a demonstrated mechanism on those models, not a guaranteed constant across all judges.
How Far the Score Can Actually Carry
If the biases are structural, the useful question is not “are LLM judges reliable” but “reliable where.” The honest answer has a shape: reliability tracks how objective and well-covered the task is, and it degrades as the question moves toward expert territory.
How reliable is LLM-as-a-judge compared to human evaluation?
On structured, factual tasks the agreement can be excellent. One reliability study reported judge–human agreement reaching a Cohen’s kappa near 0.93 on a TriviaQA-style task, close to ceiling, the kind of number that makes automated grading look like a solved problem (Reliability-Aware Eval). But kappa figures like this are domain-specific snapshots, not a fixed property of the judge; the same framework found that on expert-knowledge tasks, LLM–human agreement fell to roughly 64–68%, beneath the 72–75% baseline at which the human experts agreed with each other (Reliability-Aware Eval). On the questions where expertise matters most, the judge slips below the people it was built to stand in for.
This is why careful teams hedge. Human Inter Annotator Agreement remains the reference standard, collected with labeling platforms such as Label Studio, and the strongest evaluation setups treat the LLM as one rater to be audited rather than the source of truth. It is also why objective benchmarks keep their value: SWE Bench Verified scores models on a human-validated set of 500 real GitHub issues by whether the proposed patch actually resolves the issue (SWE-bench). There is no judge to bias; the test is whether the code runs.
Even the famous head-to-head rankings have quietly moved away from naive scoring. The Chatbot Arena leaderboard, now LMArena, shifted its ratings from a classic ELO Rating update to a Bradley Terry Model fit over the full pairwise history, with ties counted as half-wins and bootstrap confidence intervals around each score (LMSYS Org). “Elo” survives as a colloquial label; the math underneath changed to something more defensible. Even the venues built on pairwise preference now wrap statistics around the noise instead of trusting any single comparison.
What This Predicts for Your Eval Pipeline
The mechanism turns into predictions you can check on your own data.
- If two candidate answers are close in quality, expect position to decide a meaningful share of verdicts; if they are far apart, the order effect mostly disappears.
- If the judge model also produced one of the candidates, expect a measurable tilt toward that candidate, growing with how confidently the judge can recognize its own style.
- If you grade expert-domain answers, expect agreement to drop below the human-expert baseline, the inverse of the cheerful headline number from open-domain chat.
Rule of thumb: Run every pairwise comparison in both orders and keep only the verdicts that survive the swap; a result that flips on reordering was never measuring quality.
When it breaks: The judge fails hardest exactly where you most want it to work. On close calls between strong answers, and on expert-domain questions, it is at once least self-consistent and least aligned with humans, so the rankings you lean on most are built on its shakiest ground.
The Data Says
An LLM judge is a fast, scalable approximation of human preference whose accuracy runs inverse to how much the judgment matters. It is most consistent on easy, objective calls and least consistent on the close, expert decisions that separate good models from great ones. Used as a cheap first-pass filter with order-swapping and self-grading controls, it earns its place; used as an unaudited oracle, it measures familiarity and calls it quality.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors