Perplexity, BLEU, ROUGE, and ELO: The Core Metrics Behind LLM Evaluation Explained

Table of Contents
ELI5
Model evaluation metrics are different rulers for different properties. Perplexity measures how well a model predicts the next word, BLEU and ROUGE measure text overlap against a reference, and Elo captures which model humans prefer in blind comparisons.
A model scores 8.2 Perplexity and 0.34 BLEU. Another scores 11.7 perplexity and 0.41 BLEU. Which one is better? The question collapses under its own assumptions — these two numbers measure properties so fundamentally different that comparing them is like asking whether a bridge is heavier than it is long. The ruler shapes the answer. And in Model Evaluation, most arguments about which model “wins” are really arguments about which ruler to trust.
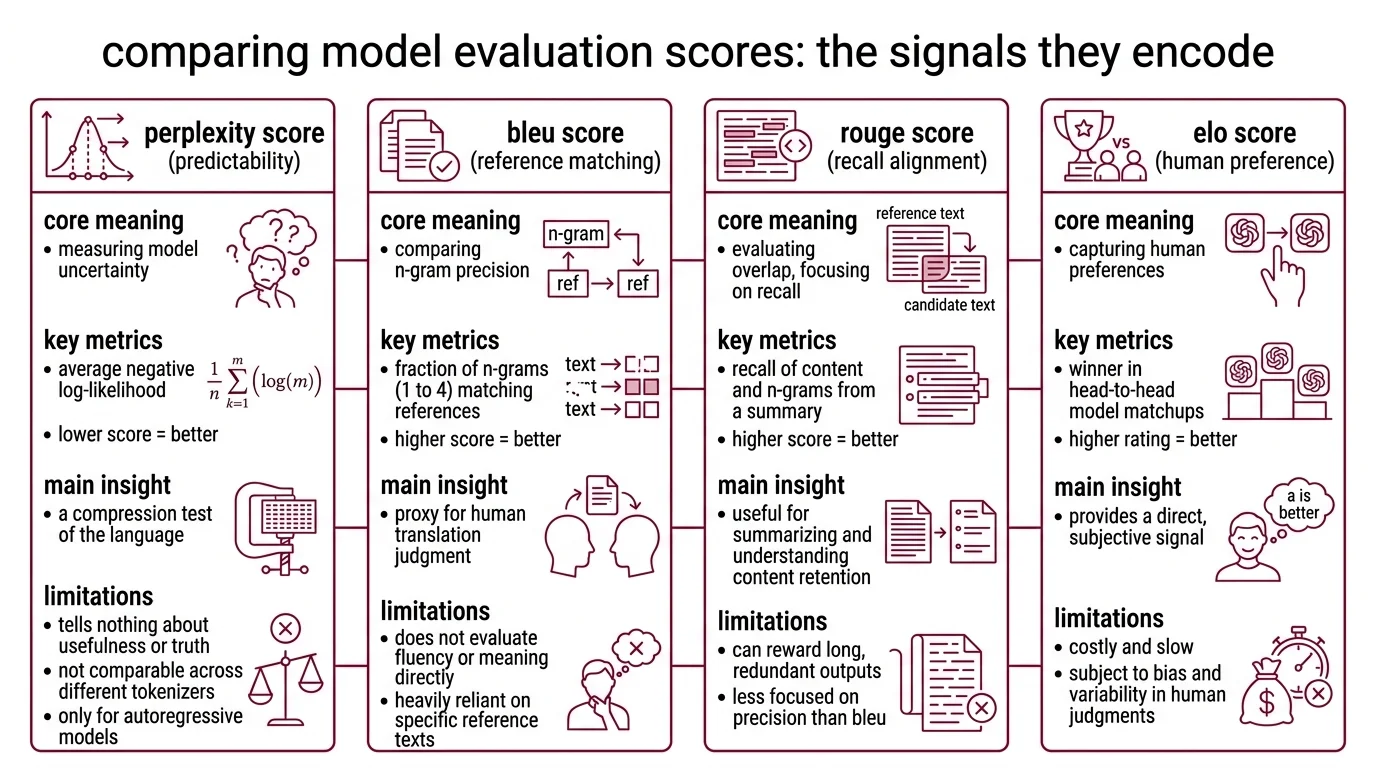
The Signal Each Score Encodes
Every evaluation metric carries an implicit definition of what “good language” means. Perplexity defines good as predictable. BLEU defines good as matching a reference. Elo defines good as preferred by a human. These are not competing answers to the same question — they are answers to different questions entirely.
What is the difference between perplexity BLEU ROUGE and ELO scores in model evaluation
Perplexity is the oldest instrument in this collection. Frederick Jelinek introduced it at IBM in 1977 for speech recognition, building on Shannon’s information theory from the 1940s. Mathematically, it is the exponentiated average negative log-likelihood of a token sequence (Hugging Face Docs) — a measure of how uncertain the model is about what comes next. A perplexity of 10 means the model is, on average, deciding among 10 equally likely continuations. Lower is better; the model is less confused.
Think of it as a compression test. A model that assigns high probability to the actual next token is, in information-theoretic terms, compressing the text efficiently. The lower the perplexity, the fewer bits per token the model needs to encode the sequence. Elegant, fast — and it says nothing about whether the compressed sequence is useful, truthful, or coherent for a human reader. Perplexity only applies to autoregressive language models; masked architectures like BERT don’t generate sequential predictions, so the calculation is undefined. And perplexity values are not comparable across models with different tokenizers or vocabulary sizes — a detail most leaderboards quietly ignore.
BLEU — Bilingual Evaluation Understudy — solved a different problem. When Papineni, Roukos, Ward, and Zhu published it in 2002, they needed a fast proxy for human translation judgment (ACL Anthology). BLEU compares n-gram precision: what fraction of unigrams, bigrams, trigrams, and 4-grams in the candidate output also appear in a reference translation. A brevity penalty discourages the model from gaming precision through very short outputs. The paper won the NAACL 2018 Test-of-Time Award — a measure of both its influence and its age.
ROUGE — Recall-Oriented Understudy for Gisting Evaluation — inverted BLEU’s lens when Chin-Yew Lin introduced it in 2004 for summarization (ACL Anthology). Where BLEU asks “how much of the candidate appears in the reference?”, ROUGE asks “how much of the reference appears in the candidate?” ROUGE-N measures n-gram recall. ROUGE-L uses the longest common subsequence. Variants like ROUGE-W and ROUGE-S add weighted and skip-bigram patterns. The asymmetry matters: BLEU penalizes hallucinated content; ROUGE penalizes missing content.
Not interchangeable. Complementary.
ELO Rating took the measurement problem in a completely different direction. Instead of comparing text against references, Chatbot Arena — created by LMSYS Org at UC Berkeley and rebranded to Arena AI in January 2026 — lets humans choose winners in blind head-to-head matchups. As of March 2026, the platform has collected over 5.4 million votes across 323 models (Arena AI). The rating system transitioned from classic online Elo to a Bradley-Terry model for more stable rankings and tighter confidence intervals (LMSYS Blog). The signal here is preference, not precision — and preference captures dimensions that n-gram counting is structurally blind to.
Choosing a Ruler for an Open-Ended Question
The distance between these metrics is not academic housekeeping. It determines which models get funded, which get selected for production, and which get quietly shelved. Choosing the wrong metric doesn’t produce a wrong answer — it produces a precise answer to a question you never asked.
What are the different types of LLM evaluation metrics and when to use each
The metrics fall into three families, and the family determines the use case.
Intrinsic metrics — perplexity is the canonical example — evaluate properties of the model itself, independent of any downstream task. Use perplexity when comparing language model architectures trained on the same corpus with the same tokenizer. It is fast, deterministic, and requires no human involvement. But it reveals nothing about task utility. A model with stellar perplexity can still produce irrelevant, harmful, or boring text — because predictability and usefulness are orthogonal properties.
Reference-based metrics — BLEU and ROUGE — evaluate output against a gold standard. Use BLEU for machine translation when reference translations exist. Use ROUGE for summarization when coverage of the source material matters. Both are cheap to compute and reproducible across runs. Both are completely indifferent to meaning. N-gram overlap does not encode semantic equivalence: two outputs with identical BLEU scores can differ wildly in quality because paraphrase, inference, and register are invisible to token-level matching. The field is shifting toward BERTScore and LLM As Judge approaches that capture these dimensions — a transition accelerated as libraries like Ragas begin deprecating legacy BLEU and ROUGE APIs.
Human-preference metrics — Elo and Arena ratings — measure what users actually choose. Use these when the task is open-ended: conversation, creative writing, code explanation — anywhere no single reference answer exists. The cost is scale; meaningful Elo ratings require thousands of pairwise comparisons. The benefit is ecological validity: the metric measures what you care about, not a proxy for it.
| Metric | Measures | Best For | Structurally Blind To |
|---|---|---|---|
| Perplexity | Prediction confidence | Architecture comparison (same tokenizer) | Task utility |
| BLEU | N-gram precision vs. reference | Machine translation | Semantic equivalence |
| ROUGE | N-gram recall vs. reference | Summarization | Semantic equivalence |
| Elo (Arena) | Human preference | Open-ended generation | Cost efficiency, edge-case coverage |
The Assumptions Baked Into Every Evaluation
Before trusting a score, you need to see what holds it up. Every metric carries silent prerequisites, and when those assumptions diverge from your use case, the number becomes noise dressed as signal.
What do you need to understand before evaluating large language models
Three prerequisites separate useful evaluation from leaderboard tourism.
First: tokenization shapes the score. Perplexity is mathematically sensitive to vocabulary size and tokenization granularity. A model with a larger vocabulary may report lower perplexity than one with a smaller vocabulary — not because it understands language better, but because its tokenizer produces fewer, more predictable chunks per sentence. Comparing perplexity across different tokenizers is a category error, and one that most published comparisons silently commit.
Second: Benchmark Contamination erodes everything. Fixed public benchmarks create perverse incentives — models trained on leaked or memorized test data score well on the benchmark and poorly on novel inputs. Dynamic benchmarks like LiveBench and LiveCodeBench use rolling question updates to resist this pressure, but contamination remains the largest quiet threat to benchmark credibility. If you cannot verify that benchmark data was excluded from training, the score tells you about memorization, not capability.
Third: the Confusion Matrix still has work to do. For classification tasks — sentiment detection, toxicity filtering, intent recognition — precision, recall, F1, and the full confusion matrix provide information that generative metrics structurally cannot. A model with smooth, fluent output and low perplexity can still systematically misclassify edge cases. Generative metrics and classification metrics answer different questions; substituting one for the other is a measurement design flaw, not a shortcut.
Where Scores Go Quiet
If you are choosing between models for translation, BLEU will rank candidates reliably — but only when reference translations represent the actual deployment domain. Formal-prose test sets produce BLEU rankings that transfer poorly to conversational or domain-specific use cases.
If you are choosing between models for open-ended conversation, Arena ratings offer the closest proxy for real user satisfaction. As of March 2026, Claude Opus 4-6 (thinking) holds the top position, followed by Claude Opus 4-6 and Gemini 3.1 Pro (Arena AI). But Elo scores fluctuate as new models enter and the vote pool shifts — these rankings are point-in-time snapshots, not permanent standings.
If you are comparing architectures during research, perplexity remains the fastest feedback loop — within the same tokenizer and vocabulary pair.
Rule of thumb: Match the metric to the deployment context. Intrinsic metrics for development loops, reference-based metrics where ground truth exists, preference metrics for open-ended generation.
When it breaks: Metrics fail when the evaluation setup diverges from deployment conditions. BLEU computed on news text does not predict performance on casual dialogue. Arena ratings collected from tech-savvy early adopters may not reflect mainstream user preferences. And every benchmark — static or dynamic — erodes in predictive value as models increasingly train against the evaluation distribution itself. The metric doesn’t lie. It just stops being the right question.
The Data Says
No single metric captures model quality — and the expectation that one should is the root of most evaluation failures. Perplexity measures internal confidence. BLEU and ROUGE measure surface overlap. Elo measures human preference. The field is shifting from static text-matching toward preference-based and task-specific evaluation, but the older metrics are not obsolete. They measure what they were designed to measure. The error is asking them to answer a question they were never built for.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors